- PRO Courses Guides New Tech Help Pro Expert Videos About wikiHow Pro Upgrade Sign In
- EDIT Edit this Article
- EXPLORE Tech Help Pro About Us Random Article Quizzes Request a New Article Community Dashboard This Or That Game Popular Categories Arts and Entertainment Artwork Books Movies Computers and Electronics Computers Phone Skills Technology Hacks Health Men's Health Mental Health Women's Health Relationships Dating Love Relationship Issues Hobbies and Crafts Crafts Drawing Games Education & Communication Communication Skills Personal Development Studying Personal Care and Style Fashion Hair Care Personal Hygiene Youth Personal Care School Stuff Dating All Categories Arts and Entertainment Finance and Business Home and Garden Relationship Quizzes Cars & Other Vehicles Food and Entertaining Personal Care and Style Sports and Fitness Computers and Electronics Health Pets and Animals Travel Education & Communication Hobbies and Crafts Philosophy and Religion Work World Family Life Holidays and Traditions Relationships Youth
- Browse Articles
- Learn Something New
- Quizzes Hot
- This Or That Game New
- Train Your Brain
- Explore More
- Support wikiHow
- About wikiHow
- Log in / Sign up
- Education and Communications
- College University and Postgraduate
- Academic Writing

How to Write a Title for a Compare and Contrast Essay
Last Updated: August 10, 2021 Fact Checked
This article was co-authored by Emily Listmann, MA . Emily Listmann is a private tutor in San Carlos, California. She has worked as a Social Studies Teacher, Curriculum Coordinator, and an SAT Prep Teacher. She received her MA in Education from the Stanford Graduate School of Education in 2014. This article has been fact-checked, ensuring the accuracy of any cited facts and confirming the authority of its sources. This article has been viewed 111,609 times.
The title is an important part of any essay. After all, it’s the first thing people read. When you write a title for your compare and contrast essay, it needs to let your reader know what subjects you want to compare and how you plan to compare them. Some essays need more formal, informative titles while others benefit from creative titles. No matter what, just remember to keep your title short, readable, and relevant to your writing.
Creating an Informative Title

- Informative titles like “The Benefit of Owning a Cat vs. a Dog”, for example, would be better for a classroom setting, while a creative title like “My Dog is Better than a Cat” would be better for a blog. [2] X Research source

- You only need to include the broad topics or themes you want to compare, such as dogs and cats. Don’t worry about putting individual points in your title. Those points will be addressed in the body of your essay.
- You may be comparing something to itself over time or space, like rock music in the 20th and 21st centuries, or Renaissance art in Italy and the Netherlands. If that’s the case, list the subject you want to compare, and places or timeframes that you are using for your comparison.

- Persuasive essay titles might use words like “benefit,” “better,” “advantages,” “should,” “will,” and other words that convey a sense that one subject has an advantage over the other.
- Informative titles might use words like “versus,” “compared,” or “difference”. These words don’t suggest that one subject is better or worse, they simply point out they are not the same.

- The end result should be a title that lets readers know what you want to compare and contrast, and how you plan on doing so in just a few words. If for example, you're comparing rock music across time, your title might be The Difference in Chord Progressions of 20th and 21st-century Rock Music .
[4] X Research source
Generating a Creative Title

- If, for example, you just want to compare white and milk chocolate, you are providing facts. Your goal will not be to make your audience think one particular chocolate is better. Your title, then, may be something like "Loco for Cocoa: The Differences Between Types of Chocolate."
- If, however, you want to tell your audience why milk chocolate is better, you are reinforcing a popular idea. If you want to explain why white chocolate is better, you are going against a popular idea. In that case, a better title might be "Milking it - Why White Chocolate is Totally the Best Chocolate."

- ”Do Hash Browns Stack up Against Fries as a Burger Side” creates a sense of tension between your subjects and challenges a popular opinion. It is a more engaging title for your readers than “Comparing Hash Browns and Fries as Burger Sides.”

- For example, if you want to write an essay comparing two works of art by Van Gogh, you may use a title like, “Look at Him Gogh: Comparing Floral Composition in Almond Blossoms and Poppy Flowers.”
Keeping Your Title Relevant and Readable

- Your essay is where you will make your arguments. Your title just needs to convey your subjects and establish that you plan to compare and contrast them in some way.

Expert Q&A
- If you're struggling to figure out a title, try writing your thesis at the top of a blank page, then brainstorming all the titles you can think of below. Go through slowly to see which ones fit your paper the best and which you like the most. Thanks Helpful 0 Not Helpful 1

You Might Also Like

- ↑ https://www.kibin.com/essay-writing-blog/how-to-write-good-essay-titles/
- ↑ http://www.schooleydesigns.com/compare-and-contrast-essay-title/
- ↑ http://www.editage.com/insights/3-basic-tips-on-writing-a-good-research-paper-title
- ↑ http://canuwrite.com/article_titles.php
- ↑ http://writing.umn.edu/sws/assets/pdf/quicktips/titles.pdf
- ↑ http://www.aacstudents.org/tips-for-essay-writing-asking-friends-to-help-you-out.php
About This Article

- Send fan mail to authors
Reader Success Stories
Dec 4, 2019
Did this article help you?
Jan 7, 2022
Jusi Tusilene
Jul 17, 2021
Mar 23, 2022

Featured Articles

Trending Articles

Watch Articles

- Terms of Use
- Privacy Policy
- Do Not Sell or Share My Info
- Not Selling Info
wikiHow Tech Help Pro:
Level up your tech skills and stay ahead of the curve
Comparative Research

Although not everyone would agree, comparing is not always bad. Comparing things can also give you a handful of benefits. For instance, there are times in our life where we feel lost. You may not be getting the job that you want or have the sexy body that you have been aiming for a long time now. Then, you happen to cross path with an old friend of yours, who happened to get the job that you always wanted. This scenario may put your self-esteem down, knowing that this friend got what you want, while you didn’t. Or you can choose to look at your friend as an example that your desire is actually attainable. Come up with a plan to achieve your personal development goal . Perhaps, ask for tips from this person or from the people who inspire you. According to the article posted in brit.co , licensed master social worker and therapist Kimberly Hershenson said that comparing yourself to someone successful can be an excellent self-motivation to work on your goals.
Aside from self-improvement, as a researcher, you should know that comparison is an essential method in scientific studies, such as experimental research and descriptive research . Through this method, you can uncover the relationship between two or more variables of your project in the form of comparative analysis .
What is Comparative Research?
Aiming to compare two or more variables of an experiment project, experts usually apply comparative research examples in social sciences to compare countries and cultures across a particular area or the entire world. Despite its proven effectiveness, you should keep it in mind that some states have different disciplines in sharing data. Thus, it would help if you consider the affecting factors in gathering specific information.
Quantitative and Qualitative Research Methods in Comparative Studies
In comparing variables, the statistical and mathematical data collection, and analysis that quantitative research methodology naturally uses to uncover the correlational connection of the variables, can be essential. Additionally, since quantitative research requires a specific research question, this method can help you can quickly come up with one particular comparative research question.
The goal of comparative research is drawing a solution out of the similarities and differences between the focused variables. Through non-experimental or qualitative research , you can include this type of research method in your comparative research design.
13+ Comparative Research Examples
Know more about comparative research by going over the following examples. You can download these zipped documents in PDF and MS Word formats.
1. Comparative Research Report Template

- Google Docs
Size: 113 KB
2. Business Comparative Research Template

Size: 69 KB
3. Comparative Market Research Template

Size: 172 KB
4. Comparative Research Strategies Example

5. Comparative Research in Anthropology Example

Size: 192 KB
6. Sample Comparative Research Example

Size: 516 KB
7. Comparative Area Research Example

8. Comparative Research on Women’s Emplyment Example

Size: 290 KB
9. Basic Comparative Research Example

Size: 19 KB
10. Comparative Research in Medical Treatments Example

11. Comparative Research in Education Example

Size: 455 KB
12. Formal Comparative Research Example

Size: 244 KB
13. Comparative Research Designs Example

Size: 259 KB
14. Casual Comparative Research in DOC

Best Practices in Writing an Essay for Comparative Research in Visual Arts
If you are going to write an essay for a comparative research examples paper, this section is for you. You must know that there are inevitable mistakes that students do in essay writing . To avoid those mistakes, follow the following pointers.
1. Compare the Artworks Not the Artists
One of the mistakes that students do when writing a comparative essay is comparing the artists instead of artworks. Unless your instructor asked you to write a biographical essay, focus your writing on the works of the artists that you choose.
2. Consult to Your Instructor
There is broad coverage of information that you can find on the internet for your project. Some students, however, prefer choosing the images randomly. In doing so, you may not create a successful comparative study. Therefore, we recommend you to discuss your selections with your teacher.
3. Avoid Redundancy
It is common for the students to repeat the ideas that they have listed in the comparison part. Keep it in mind that the spaces for this activity have limitations. Thus, it is crucial to reserve each space for more thoroughly debated ideas.
4. Be Minimal
Unless instructed, it would be practical if you only include a few items(artworks). In this way, you can focus on developing well-argued information for your study.
5. Master the Assessment Method and the Goals of the Project
We get it. You are doing this project because your instructor told you so. However, you can make your study more valuable by understanding the goals of doing the project. Know how you can apply this new learning. You should also know the criteria that your teachers use to assess your output. It will give you a chance to maximize the grade that you can get from this project.
Comparing things is one way to know what to improve in various aspects. Whether you are aiming to attain a personal goal or attempting to find a solution to a certain task, you can accomplish it by knowing how to conduct a comparative study. Use this content as a tool to expand your knowledge about this research methodology .
AI Generator
Text prompt
- Instructive
- Professional
10 Examples of Public speaking
20 Examples of Gas lighting
- Privacy Policy
Buy Me a Coffee
Home » Research Paper Title – Writing Guide and Example
Research Paper Title – Writing Guide and Example
Table of Contents

Research Paper Title
Research Paper Title is the name or heading that summarizes the main theme or topic of a research paper . It serves as the first point of contact between the reader and the paper, providing an initial impression of the content, purpose, and scope of the research . A well-crafted research paper title should be concise, informative, and engaging, accurately reflecting the key elements of the study while also capturing the reader’s attention and interest. The title should be clear and easy to understand, and it should accurately convey the main focus and scope of the research paper.
Examples of Research Paper Title
Here are some Good Examples of Research Paper Title:
- “Investigating the Relationship Between Sleep Duration and Academic Performance Among College Students”
- “The Impact of Artificial Intelligence on Employment: A Systematic Review”
- “The Effectiveness of Mindfulness-Based Interventions for Anxiety: A Meta-Analysis”
- “Exploring the Effects of Social Support on Mental Health in Patients with Chronic Illness”
- “Assessing the Effectiveness of Cognitive-Behavioral Therapy for Depression: A Randomized Controlled Trial”
- “The Impact of Social Media Influencers on Consumer Behavior: A Systematic Review”
- “Investigating the Link Between Personality Traits and Leadership Effectiveness”
- “The Effect of Parental Incarceration on Child Development: A Longitudinal Study”
- “Exploring the Relationship Between Cultural Intelligence and Cross-Cultural Adaptation: A Meta-Analysis”
- “Assessing the Effectiveness of Mindfulness-Based Stress Reduction for Chronic Pain Management”.
- “The Effects of Social Media on Mental Health: A Meta-Analysis”
- “The Impact of Climate Change on Global Crop Yields: A Longitudinal Study”
- “Exploring the Relationship between Parental Involvement and Academic Achievement in Elementary School Students”
- “The Ethics of Genetic Editing: A Review of Current Research and Implications for Society”
- “Understanding the Role of Gender in Leadership: A Comparative Study of Male and Female CEOs”
- “The Effect of Exercise on Cognitive Function in Older Adults: A Randomized Controlled Trial”
- “The Impacts of COVID-19 on Mental Health: A Cross-Cultural Comparison”
- “Assessing the Effectiveness of Online Learning Platforms: A Case Study of Coursera”
- “Exploring the Link between Employee Engagement and Organizational Performance”
- “The Effects of Income Inequality on Social Mobility: A Comparative Analysis of OECD Countries”
- “Exploring the Relationship Between Social Media Use and Mental Health in Adolescents”
- “The Impact of Climate Change on Crop Yield: A Case Study of Maize Production in Sub-Saharan Africa”
- “Examining the Effectiveness of Cognitive Behavioral Therapy for Anxiety Disorders: A Meta-Analysis”
- “An Analysis of the Relationship Between Employee Job Satisfaction and Organizational Commitment”
- “Assessing the Impacts of Wilderness Areas on Local Economies: A Case Study of Yellowstone National Park”
- “The Role of Parental Involvement in Early Childhood Education: A Review of the Literature”
- “Investigating the Effects of Technology on Learning in Higher Education”
- “The Use of Artificial Intelligence in Healthcare: Opportunities and Challenges”
- “A Study of the Relationship Between Personality Traits and Leadership Styles in Business Organizations”.
How to choose Research Paper Title
Choosing a research paper title is an important step in the research process. A good title can attract readers and convey the essence of your research in a concise and clear manner. Here are some tips on how to choose a research paper title:
- Be clear and concise: A good title should convey the main idea of your research in a clear and concise manner. Avoid using jargon or technical language that may be confusing to readers.
- Use keywords: Including keywords in your title can help readers find your paper when searching for related topics. Use specific, descriptive terms that accurately describe your research.
- Be descriptive: A descriptive title can help readers understand what your research is about. Use adjectives and adverbs to convey the main ideas of your research.
- Consider the audience : Think about the audience for your paper and choose a title that will appeal to them. If your paper is aimed at a specialized audience, you may want to use technical terms or jargon in your title.
- Avoid being too general or too specific : A title that is too general may not convey the specific focus of your research, while a title that is too specific may not be of interest to a broader audience. Strive for a title that accurately reflects the focus of your research without being too narrow or too broad.
- Make it interesting : A title that is interesting or provocative can capture the attention of readers and draw them into your research. Use humor, wordplay, or other creative techniques to make your title stand out.
- Seek feedback: Ask colleagues or advisors for feedback on your title. They may be able to offer suggestions or identify potential problems that you hadn’t considered.
Purpose of Research Paper Title
The research paper title serves several important purposes, including:
- Identifying the subject matter : The title of a research paper should clearly and accurately identify the topic or subject matter that the paper addresses. This helps readers quickly understand what the paper is about.
- Catching the reader’s attention : A well-crafted title can grab the reader’s attention and make them interested in reading the paper. This is particularly important in academic settings where there may be many papers on the same topic.
- Providing context: The title can provide important context for the research paper by indicating the specific area of study, the research methods used, or the key findings.
- Communicating the scope of the paper: A good title can give readers an idea of the scope and depth of the research paper. This can help them decide if the paper is relevant to their interests or research.
- Indicating the research question or hypothesis : The title can often indicate the research question or hypothesis that the paper addresses, which can help readers understand the focus of the research and the main argument or conclusion of the paper.
Advantages of Research Paper Title
The title of a research paper is an important component that can have several advantages, including:
- Capturing the reader’s attention : A well-crafted research paper title can grab the reader’s attention and encourage them to read further. A captivating title can also increase the visibility of the paper and attract more readers.
- Providing a clear indication of the paper’s focus: A well-written research paper title should clearly convey the main focus and purpose of the study. This helps potential readers quickly determine whether the paper is relevant to their interests.
- Improving discoverability: A descriptive title that includes relevant keywords can improve the discoverability of the research paper in search engines and academic databases, making it easier for other researchers to find and cite.
- Enhancing credibility : A clear and concise title can enhance the credibility of the research and the author. A title that accurately reflects the content of the paper can increase the confidence readers have in the research findings.
- Facilitating communication: A well-written research paper title can facilitate communication among researchers, enabling them to quickly and easily identify relevant studies and engage in discussions related to the topic.
- Making the paper easier to remember : An engaging and memorable research paper title can help readers remember the paper and its findings. This can be especially important in fields where researchers are constantly inundated with new information and need to quickly recall important studies.
- Setting expectations: A good research paper title can set expectations for the reader and help them understand what the paper will cover. This can be especially important for readers who are unfamiliar with the topic or the research area.
- Guiding research: A well-crafted research paper title can also guide future research by highlighting gaps in the current literature or suggesting new areas for investigation.
- Demonstrating creativity: A creative research paper title can demonstrate the author’s creativity and originality, which can be appealing to readers and other researchers.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Design – Types, Methods and Examples

Research Paper Introduction – Writing Guide and...

Research Paper Conclusion – Writing Guide and...
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Comparing and contrasting in an essay | Tips & examples
Comparing and Contrasting in an Essay | Tips & Examples
Published on August 6, 2020 by Jack Caulfield . Revised on July 23, 2023.
Comparing and contrasting is an important skill in academic writing . It involves taking two or more subjects and analyzing the differences and similarities between them.
Instantly correct all language mistakes in your text
Upload your document to correct all your mistakes in minutes

Table of contents
When should i compare and contrast, making effective comparisons, comparing and contrasting as a brainstorming tool, structuring your comparisons, other interesting articles, frequently asked questions about comparing and contrasting.
Many assignments will invite you to make comparisons quite explicitly, as in these prompts.
- Compare the treatment of the theme of beauty in the poetry of William Wordsworth and John Keats.
- Compare and contrast in-class and distance learning. What are the advantages and disadvantages of each approach?
Some other prompts may not directly ask you to compare and contrast, but present you with a topic where comparing and contrasting could be a good approach.
One way to approach this essay might be to contrast the situation before the Great Depression with the situation during it, to highlight how large a difference it made.
Comparing and contrasting is also used in all kinds of academic contexts where it’s not explicitly prompted. For example, a literature review involves comparing and contrasting different studies on your topic, and an argumentative essay may involve weighing up the pros and cons of different arguments.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

As the name suggests, comparing and contrasting is about identifying both similarities and differences. You might focus on contrasting quite different subjects or comparing subjects with a lot in common—but there must be some grounds for comparison in the first place.
For example, you might contrast French society before and after the French Revolution; you’d likely find many differences, but there would be a valid basis for comparison. However, if you contrasted pre-revolutionary France with Han-dynasty China, your reader might wonder why you chose to compare these two societies.
This is why it’s important to clarify the point of your comparisons by writing a focused thesis statement . Every element of an essay should serve your central argument in some way. Consider what you’re trying to accomplish with any comparisons you make, and be sure to make this clear to the reader.
Comparing and contrasting can be a useful tool to help organize your thoughts before you begin writing any type of academic text. You might use it to compare different theories and approaches you’ve encountered in your preliminary research, for example.
Let’s say your research involves the competing psychological approaches of behaviorism and cognitive psychology. You might make a table to summarize the key differences between them.
Or say you’re writing about the major global conflicts of the twentieth century. You might visualize the key similarities and differences in a Venn diagram.

These visualizations wouldn’t make it into your actual writing, so they don’t have to be very formal in terms of phrasing or presentation. The point of comparing and contrasting at this stage is to help you organize and shape your ideas to aid you in structuring your arguments.
When comparing and contrasting in an essay, there are two main ways to structure your comparisons: the alternating method and the block method.
The alternating method
In the alternating method, you structure your text according to what aspect you’re comparing. You cover both your subjects side by side in terms of a specific point of comparison. Your text is structured like this:
Mouse over the example paragraph below to see how this approach works.
One challenge teachers face is identifying and assisting students who are struggling without disrupting the rest of the class. In a traditional classroom environment, the teacher can easily identify when a student is struggling based on their demeanor in class or simply by regularly checking on students during exercises. They can then offer assistance quietly during the exercise or discuss it further after class. Meanwhile, in a Zoom-based class, the lack of physical presence makes it more difficult to pay attention to individual students’ responses and notice frustrations, and there is less flexibility to speak with students privately to offer assistance. In this case, therefore, the traditional classroom environment holds the advantage, although it appears likely that aiding students in a virtual classroom environment will become easier as the technology, and teachers’ familiarity with it, improves.
The block method
In the block method, you cover each of the overall subjects you’re comparing in a block. You say everything you have to say about your first subject, then discuss your second subject, making comparisons and contrasts back to the things you’ve already said about the first. Your text is structured like this:
- Point of comparison A
- Point of comparison B
The most commonly cited advantage of distance learning is the flexibility and accessibility it offers. Rather than being required to travel to a specific location every week (and to live near enough to feasibly do so), students can participate from anywhere with an internet connection. This allows not only for a wider geographical spread of students but for the possibility of studying while travelling. However, distance learning presents its own accessibility challenges; not all students have a stable internet connection and a computer or other device with which to participate in online classes, and less technologically literate students and teachers may struggle with the technical aspects of class participation. Furthermore, discomfort and distractions can hinder an individual student’s ability to engage with the class from home, creating divergent learning experiences for different students. Distance learning, then, seems to improve accessibility in some ways while representing a step backwards in others.
Note that these two methods can be combined; these two example paragraphs could both be part of the same essay, but it’s wise to use an essay outline to plan out which approach you’re taking in each paragraph.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
If you want to know more about AI tools , college essays , or fallacies make sure to check out some of our other articles with explanations and examples or go directly to our tools!
- Ad hominem fallacy
- Post hoc fallacy
- Appeal to authority fallacy
- False cause fallacy
- Sunk cost fallacy
College essays
- Choosing Essay Topic
- Write a College Essay
- Write a Diversity Essay
- College Essay Format & Structure
- Comparing and Contrasting in an Essay
(AI) Tools
- Grammar Checker
- Paraphrasing Tool
- Text Summarizer
- AI Detector
- Plagiarism Checker
- Citation Generator
Some essay prompts include the keywords “compare” and/or “contrast.” In these cases, an essay structured around comparing and contrasting is the appropriate response.
Comparing and contrasting is also a useful approach in all kinds of academic writing : You might compare different studies in a literature review , weigh up different arguments in an argumentative essay , or consider different theoretical approaches in a theoretical framework .
Your subjects might be very different or quite similar, but it’s important that there be meaningful grounds for comparison . You can probably describe many differences between a cat and a bicycle, but there isn’t really any connection between them to justify the comparison.
You’ll have to write a thesis statement explaining the central point you want to make in your essay , so be sure to know in advance what connects your subjects and makes them worth comparing.
Comparisons in essays are generally structured in one of two ways:
- The alternating method, where you compare your subjects side by side according to one specific aspect at a time.
- The block method, where you cover each subject separately in its entirety.
It’s also possible to combine both methods, for example by writing a full paragraph on each of your topics and then a final paragraph contrasting the two according to a specific metric.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Caulfield, J. (2023, July 23). Comparing and Contrasting in an Essay | Tips & Examples. Scribbr. Retrieved April 9, 2024, from https://www.scribbr.com/academic-essay/compare-and-contrast/
Is this article helpful?

Jack Caulfield
Other students also liked, how to write an expository essay, how to write an argumentative essay | examples & tips, academic paragraph structure | step-by-step guide & examples, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”

How to Write a Comparison Essay
- Introduction
- Essay Outline
- Expressions For Comparison Essays
- Sample Comparison 1
- Sample Comparison 2
- Guides & Handouts Home
- Writing Centre Home
Some comparison essays have ordinary titles (ex. "Two Hunters of the Savannah" or "A Comparison between Two Appalachian Dulcimers".) It may be preferable, however, if your title reflects yourattitude to the things being compared (ex. "The Zing of Irish Spring or the Love of Gentle Dove" or "the Advantages of Swimming over Running").
- << Previous: Essay Outline
- Next: Expressions For Comparison Essays >>
- Last Updated: Aug 19, 2019 3:34 PM
- URL: https://langara.libguides.com/writing-centre/comparison-essay
- Cookies & Privacy
- GETTING STARTED
- Introduction
- FUNDAMENTALS
- Acknowledgements
- Research questions & hypotheses
- Concepts, constructs & variables
- Research limitations
- Getting started
- Sampling Strategy
- Research Quality
- Research Ethics
- Data Analysis
Structure of comparative research questions
There are five steps required to construct a comparative research question: (1) choose your starting phrase; (2) identify and name the dependent variable; (3) identify the groups you are interested in; (4) identify the appropriate adjoining text; and (5) write out the comparative research question. Each of these steps is discussed in turn:
Choose your starting phrase
Identify and name the dependent variable
Identify the groups you are interested in
Identify the appropriate adjoining text
Write out the comparative research question
FIRST Choose your starting phrase
Comparative research questions typically start with one of two phrases:
Some of these starting phrases are highlighted in blue text in the examples below:
What is the difference in the daily calorific intake of American men and women?
What is the difference in the weekly photo uploads on Facebook between British male and female university students?
What are the differences in perceptions towards Internet banking security between adolescents and pensioners?
What are the differences in attitudes towards music piracy when pirated music is freely distributed or purchased?
SECOND Identify and name the dependent variable
All comparative research questions have a dependent variable . You need to identify what this is. However, how the dependent variable is written out in a research question and what you call it are often two different things. In the examples below, we have illustrated the name of the dependent variable and highlighted how it would be written out in the blue text .
The first three examples highlight that while the name of the dependent variable is the same, namely daily calorific intake, the way that this dependent variable is written out differs in each case.
THIRD Identify the groups you are interested in
All comparative research questions have at least two groups . You need to identify these groups. In the examples below, we have identified the groups in the green text .
What is the difference in the daily calorific intake of American men and women ?
What is the difference in the weekly photo uploads on Facebook between British male and female university students ?
What are the differences in perceptions towards Internet banking security between adolescents and pensioners ?
What are the differences in attitudes towards music piracy when pirated music is freely distributed or purchased ?
It is often easy to identify groups because they reflect different types of people (e.g., men and women, adolescents and pensioners), as highlighted by the first three examples. However, sometimes the two groups you are interested in reflect two different conditions, as highlighted by the final example. In this final example, the two conditions (i.e., groups) are pirated music that is freely distributed and pirated music that is purchased. So we are interested in how the attitudes towards music piracy differ when pirated music is freely distributed as opposed to when pirated music in purchased.
FOURTH Identify the appropriate adjoining text
Before you write out the groups you are interested in comparing, you typically need to include some adjoining text. Typically, this adjoining text includes the words between or amongst , but other words may be more appropriate, as highlighted by the examples in red text below:
FIFTH Write out the comparative research question
Once you have these details - (1) the starting phrase, (2) the name of the dependent variable, (3) the name of the groups you are interested in comparing, and (4) any potential adjoining words - you can write out the comparative research question in full. The example comparative research questions discussed above are written out in full below:
In the section that follows, the structure of relationship-based research questions is discussed.
Structure of relationship-based research questions
There are six steps required to construct a relationship-based research question: (1) choose your starting phrase; (2) identify the independent variable(s); (3) identify the dependent variable(s); (4) identify the group(s); (5) identify the appropriate adjoining text; and (6) write out the relationship-based research question. Each of these steps is discussed in turn.
Identify the independent variable(s)
Identify the dependent variable(s)
Identify the group(s)
Write out the relationship-based research question
Relationship-based research questions typically start with one or two phrases:
What is the relationship between gender and attitudes towards music piracy amongst adolescents?
What is the relationship between study time and exam scores amongst university students?
What is the relationship of career prospects, salary and benefits, and physical working conditions on job satisfaction between managers and non-managers?
SECOND Name the independent variable(s)
All relationship-based research questions have at least one independent variable . You need to identify what this is. In the examples that follow, the independent variable(s) is highlighted in the purple text .
What is the relationship of career prospects , salary and benefits , and physical working conditions on job satisfaction between managers and non-managers?
When doing a dissertation at the undergraduate and master's level, it is likely that your research question will only have one or two independent variables, but this is not always the case.
THIRD Name the dependent variable(s)
All relationship-based research questions also have at least one dependent variable . You also need to identify what this is. At the undergraduate and master's level, it is likely that your research question will only have one dependent variable. In the examples that follow, the dependent variable is highlighted in the blue text .
FOURTH Name of the group(s)
All relationship-based research questions have at least one group , but can have multiple groups . You need to identify this group(s). In the examples below, we have identified the group(s) in the green text .
What is the relationship between gender and attitudes towards music piracy amongst adolescents ?
What is the relationship between study time and exam scores amongst university students ?
What is the relationship of career prospects, salary and benefits, and physical working conditions on job satisfaction between managers and non-managers ?
FIFTH Identify the appropriate adjoining text
Before you write out the groups you are interested in comparing, you typically need to include some adjoining text (i.e., usually the words between or amongst):
Some examples are highlighted in red text below:
SIXTH Write out the relationship-based research question
Once you have these details ? (1) the starting phrase, (2) the name of the dependent variable, (3) the name of the independent variable, (4) the name of the group(s) you are interested in, and (5) any potential adjoining words ? you can write out the relationship-based research question in full. The example relationship-based research questions discussed above are written out in full below:
STEP FOUR Write out the problem or issues you are trying to address in the form of a complete research question
In the previous section, we illustrated how to write out the three types of research question (i.e., descriptive, comparative and relationship-based research questions). Whilst these rules should help you when writing out your research question(s), the main thing you should keep in mind is whether your research question(s) flow and are easy to read .
- USC Libraries
- Research Guides
Organizing Your Social Sciences Research Paper
- Choosing a Title
- Purpose of Guide
- Design Flaws to Avoid
- Independent and Dependent Variables
- Glossary of Research Terms
- Reading Research Effectively
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Applying Critical Thinking
- Making an Outline
- Paragraph Development
- Research Process Video Series
- Executive Summary
- The C.A.R.S. Model
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tiertiary Sources
- Scholarly vs. Popular Publications
- Qualitative Methods
- Quantitative Methods
- Insiderness
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Writing Concisely
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Generative AI and Writing
- USC Libraries Tutorials and Other Guides
- Bibliography
The title summarizes the main idea or ideas of your study. A good title contains the fewest possible words needed to adequately describe the content and/or purpose of your research paper.
Importance of Choosing a Good Title
The title is the part of a paper that is read the most, and it is usually read first . It is, therefore, the most important element that defines the research study. With this in mind, avoid the following when creating a title:
- If the title is too long, this usually indicates there are too many unnecessary words. Avoid language, such as, "A Study to Investigate the...," or "An Examination of the...." These phrases are obvious and generally superfluous unless they are necessary to covey the scope, intent, or type of a study.
- On the other hand, a title which is too short often uses words which are too broad and, thus, does not tell the reader what is being studied. For example, a paper with the title, "African Politics" is so non-specific the title could be the title of a book and so ambiguous that it could refer to anything associated with politics in Africa. A good title should provide information about the focus and/or scope of your research study.
- In academic writing, catchy phrases or non-specific language may be used, but only if it's within the context of the study [e.g., "Fair and Impartial Jury--Catch as Catch Can"]. However, in most cases, you should avoid including words or phrases that do not help the reader understand the purpose of your paper.
- Academic writing is a serious and deliberate endeavor. Avoid using humorous or clever journalistic styles of phrasing when creating the title to your paper. Journalistic headlines often use emotional adjectives [e.g., incredible, amazing, effortless] to highlight a problem experienced by the reader or use "trigger words" or interrogative words like how, what, when, or why to persuade people to read the article or click on a link. These approaches are viewed as counter-productive in academic writing. A reader does not need clever or humorous titles to catch their attention because the act of reading research is assumed to be deliberate based on a desire to learn and improve understanding of the problem. In addition, a humorous title can merely detract from the seriousness and authority of your research.
- Unlike everywhere else in a college-level social sciences research paper [except when using direct quotes in the text], titles do not have to adhere to rigid grammatical or stylistic standards. For example, it could be appropriate to begin a title with a coordinating conjunction [i.e., and, but, or, nor, for, so, yet] if it makes sense to do so and does not detract from the purpose of the study [e.g., "Yet Another Look at Mutual Fund Tournaments"] or beginning the title with an inflected form of a verb such as those ending in -ing [e.g., "Assessing the Political Landscape: Structure, Cognition, and Power in Organizations"].
Appiah, Kingsley Richard et al. “Structural Organisation of Research Article Titles: A Comparative Study of Titles of Business, Gynaecology and Law.” Advances in Language and Literary Studies 10 (2019); Hartley James. “To Attract or to Inform: What are Titles for?” Journal of Technical Writing and Communication 35 (2005): 203-213; Jaakkola, Maarit. “Journalistic Writing and Style.” In Oxford Research Encyclopedia of Communication . Jon F. Nussbaum, editor. (New York: Oxford University Press, 2018): https://oxfordre.com/communication.
Structure and Writing Style
The following parameters can be used to help you formulate a suitable research paper title:
- The purpose of the research
- The scope of the research
- The narrative tone of the paper [typically defined by the type of the research]
- The methods used to study the problem
The initial aim of a title is to capture the reader’s attention and to highlight the research problem under investigation.
Create a Working Title Typically, the final title you submit to your professor is created after the research is complete so that the title accurately captures what has been done . The working title should be developed early in the research process because it can help anchor the focus of the study in much the same way the research problem does. Referring back to the working title can help you reorient yourself back to the main purpose of the study if you find yourself drifting off on a tangent while writing. The Final Title Effective titles in research papers have several characteristics that reflect general principles of academic writing.
- Indicate accurately the subject and scope of the study,
- Rarely use abbreviations or acronyms unless they are commonly known,
- Use words that create a positive impression and stimulate reader interest,
- Use current nomenclature from the field of study,
- Identify key variables, both dependent and independent,
- Reveal how the paper will be organized,
- Suggest a relationship between variables which supports the major hypothesis,
- Is limited to 5 to 15 substantive words,
- Does not include redundant phrasing, such as, "A Study of," "An Analysis of" or similar constructions,
- Takes the form of a question or declarative statement,
- If you use a quote as part of the title, the source of the quote is cited [usually using an asterisk and footnote],
- Use correct grammar and capitalization with all first words and last words capitalized, including the first word of a subtitle. All nouns, pronouns, verbs, adjectives, and adverbs that appear between the first and last words of the title are also capitalized, and
- Rarely uses an exclamation mark at the end of the title.
The Subtitle Subtitles are frequently used in social sciences research papers because it helps the reader understand the scope of the study in relation to how it was designed to address the research problem. Think about what type of subtitle listed below reflects the overall approach to your study and whether you believe a subtitle is needed to emphasize the investigative parameters of your research.
1. Explains or provides additional context , e.g., "Linguistic Ethnography and the Study of Welfare Institutions as a Flow of Social Practices: The Case of Residential Child Care Institutions as Paradoxical Institutions." [Palomares, Manuel and David Poveda. Text & Talk: An Interdisciplinary Journal of Language, Discourse and Communication Studies 30 (January 2010): 193-212]
2. Adds substance to a literary, provocative, or imaginative title or quote , e.g., "Listen to What I Say, Not How I Vote": Congressional Support for the President in Washington and at Home." [Grose, Christian R. and Keesha M. Middlemass. Social Science Quarterly 91 (March 2010): 143-167]
3. Qualifies the geographic scope of the research , e.g., "The Geopolitics of the Eastern Border of the European Union: The Case of Romania-Moldova-Ukraine." [Marcu, Silvia. Geopolitics 14 (August 2009): 409-432]
4. Qualifies the temporal scope of the research , e.g., "A Comparison of the Progressive Era and the Depression Years: Societal Influences on Predictions of the Future of the Library, 1895-1940." [Grossman, Hal B. Libraries & the Cultural Record 46 (2011): 102-128]
5. Focuses on investigating the ideas, theories, or work of a particular individual , e.g., "A Deliberative Conception of Politics: How Francesco Saverio Merlino Related Anarchy and Democracy." [La Torre, Massimo. Sociologia del Diritto 28 (January 2001): 75 - 98]
6. Identifies the methodology used , e.g. "Student Activism of the 1960s Revisited: A Multivariate Analysis Research Note." [Aron, William S. Social Forces 52 (March 1974): 408-414]
7. Defines the overarching technique for analyzing the research problem , e.g., "Explaining Territorial Change in Federal Democracies: A Comparative Historical Institutionalist Approach." [ Tillin, Louise. Political Studies 63 (August 2015): 626-641.
With these examples in mind, think about what type of subtitle reflects the overall approach to your study. This will help the reader understand the scope of the study in relation to how it was designed to address the research problem.
Anstey, A. “Writing Style: What's in a Title?” British Journal of Dermatology 170 (May 2014): 1003-1004; Balch, Tucker. How to Compose a Title for Your Research Paper. Augmented Trader blog. School of Interactive Computing, Georgia Tech University; Bavdekar, Sandeep B. “Formulating the Right Title for a Research Article.” Journal of Association of Physicians of India 64 (February 2016); Choosing the Proper Research Paper Titles. AplusReports.com, 2007-2012; Eva, Kevin W. “Titles, Abstracts, and Authors.” In How to Write a Paper . George M. Hall, editor. 5th edition. (Oxford: John Wiley and Sons, 2013), pp. 33-41; Hartley James. “To Attract or to Inform: What are Titles for?” Journal of Technical Writing and Communication 35 (2005): 203-213; General Format. The Writing Lab and The OWL. Purdue University; Kerkut G.A. “Choosing a Title for a Paper.” Comparative Biochemistry and Physiology Part A: Physiology 74 (1983): 1; “Tempting Titles.” In Stylish Academic Writing . Helen Sword, editor. (Cambridge, MA: Harvard University Press, 2012), pp. 63-75; Nundy, Samiran, et al. “How to Choose a Title?” In How to Practice Academic Medicine and Publish from Developing Countries? A Practical Guide . Edited by Samiran Nundy, Atul Kakar, and Zulfiqar A. Bhutta. (Springer Singapore, 2022), pp. 185-192.
- << Previous: Applying Critical Thinking
- Next: Making an Outline >>
- Last Updated: Apr 11, 2024 10:59 AM
- URL: https://libguides.usc.edu/writingguide

Global Encyclopedia of Public Administration, Public Policy, and Governance pp 1–7 Cite as
Comparative Studies
- Mario Coccia 2 , 3 &
- Igor Benati 3
- Living reference work entry
- First Online: 09 February 2018
3314 Accesses
11 Citations
Comparative analysis ; Comparative approach
Comparative is a concept that derives from the verb “to compare” (the etymology is Latin comparare , derivation of par = equal, with prefix com- , it is a systematic comparison). Comparative studies are investigations to analyze and evaluate, with quantitative and qualitative methods, a phenomenon and/or facts among different areas, subjects, and/or objects to detect similarities and/or differences.
Introduction: Why Comparative Studies Are Important in Scientific Research
Natural sciences apply the method of controlled experimentation to test theories, whereas social and human sciences apply, in general, different approaches to support hypotheses. Comparative method is a process of analysing differences and/or similarities betwee two or more objects and/or subjects. Comparative studies are based on research techniques and strategies for drawing inferences about causation and/or association of factors that are similar or...
This is a preview of subscription content, log in via an institution .
Benati I, Coccia M (2017) General trends and causes of high compensation of government managers in the OECD countries. Int J Public Adm. doi: https://doi.org/10.1080/01900692.2017.1318399
Benati I, Coccia M (2018) Rewards in Bureaucracy and Politics. In Global Encyclopedia of Public Administration, Public Policy, and Governance –section Bureaucracy (edited by Ali Farazmand) Chapter No: 3417-1, https://doi.org/10.1007/978-3-319-31816-5_3417-1 , Springer International Publishing AG
Coccia M, Rolfo S (2007) How research policy changes can affect the organization and productivity of public research institutes. Journal of Comparative Policy Analysis, Research and Practice, 9(3): 215–233. https://doi.org/10.1080/13876980701494624
Coccia M, Rolfo S (2013) Human Resource Management and Organizational Behavior of Public Research Institutions. International Journal of Public Administration, 36(4): 256–268, https://doi.org/10.1080/01900692.2012.756889
Cooksey RW (2007) Illustrating statistical procedures. Tilde University Press, Prahran
Google Scholar
Gomm R, Hammersley M, Foster P (eds) (2000) Case study method. SAGE Publications, London
Hague R, Harrop M (2004) Comparative government and politics. Palgrave Macmillan, New York
Levine CH, Peters BG, Thompson FJ (1990) Public administration: challenges, choices, consequences. Scott Foresman and Company, Glenview
Peters BG (1998) Comparative politics-theory and method. Macmillan Press, London
Peters BG, Pierre J (2016) Comparative governance: rediscovering the functional dimension of governing. Cambridge University Press, Cambridge
Download references
Author information
Authors and affiliations.
Arizona State University, Tempe, AZ, USA
Mario Coccia
CNR – National Research Council of Italy, Torino, Italy
Mario Coccia & Igor Benati
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Igor Benati .
Editor information
Editors and affiliations.
Florida Atlantic University, Boca Raton, Florida, USA
Ali Farazmand
Rights and permissions
Reprints and permissions
Copyright information
© 2018 Springer International Publishing AG
About this entry
Cite this entry.
Coccia, M., Benati, I. (2018). Comparative Studies. In: Farazmand, A. (eds) Global Encyclopedia of Public Administration, Public Policy, and Governance. Springer, Cham. https://doi.org/10.1007/978-3-319-31816-5_1197-1
Download citation
DOI : https://doi.org/10.1007/978-3-319-31816-5_1197-1
Received : 31 January 2018
Accepted : 03 February 2018
Published : 09 February 2018
Publisher Name : Springer, Cham
Print ISBN : 978-3-319-31816-5
Online ISBN : 978-3-319-31816-5
eBook Packages : Springer Reference Economics and Finance Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
- Publish with us
Policies and ethics
- Find a journal
- Track your research

On Evaluating Curricular Effectiveness: Judging the Quality of K-12 Mathematics Evaluations (2004)
Chapter: 5 comparative studies, 5 comparative studies.
It is deceptively simple to imagine that a curriculum’s effectiveness could be easily determined by a single well-designed study. Such a study would randomly assign students to two treatment groups, one using the experimental materials and the other using a widely established comparative program. The students would be taught the entire curriculum, and a test administered at the end of instruction would provide unequivocal results that would permit one to identify the more effective treatment.
The truth is that conducting definitive comparative studies is not simple, and many factors make such an approach difficult. Student placement and curricular choice are decisions that involve multiple groups of decision makers, accrue over time, and are subject to day-to-day conditions of instability, including student mobility, parent preference, teacher assignment, administrator and school board decisions, and the impact of standardized testing. This complex set of institutional policies, school contexts, and individual personalities makes comparative studies, even quasi-experimental approaches, challenging, and thus demands an honest and feasible assessment of what can be expected of evaluation studies (Usiskin, 1997; Kilpatrick, 2002; Schoenfeld, 2002; Shafer, in press).
Comparative evaluation study is an evolving methodology, and our purpose in conducting this review was to evaluate and learn from the efforts undertaken so far and advise on future efforts. We stipulated the use of comparative studies as follows:
A comparative study was defined as a study in which two (or more) curricular treatments were investigated over a substantial period of time (at least one semester, and more typically an entire school year) and a comparison of various curricular outcomes was examined using statistical tests. A statistical test was required to ensure the robustness of the results relative to the study’s design.
We read and reviewed a set of 95 comparative studies. In this report we describe that database, analyze its results, and draw conclusions about the quality of the evaluation database both as a whole and separated into evaluations supported by the National Science Foundation and commercially generated evaluations. In addition to describing and analyzing this database, we also provide advice to those who might wish to fund or conduct future comparative evaluations of mathematics curricular effectiveness. We have concluded that the process of conducting such evaluations is in its adolescence and could benefit from careful synthesis and advice in order to increase its rigor, feasibility, and credibility. In addition, we took an interdisciplinary approach to the task, noting that various committee members brought different expertise and priorities to the consideration of what constitutes the most essential qualities of rigorous and valid experimental or quasi-experimental design in evaluation. This interdisciplinary approach has led to some interesting observations and innovations in our methodology of evaluation study review.
This chapter is organized as follows:
Study counts disaggregated by program and program type.
Seven critical decision points and identification of at least minimally methodologically adequate studies.
Definition and illustration of each decision point.
A summary of results by student achievement in relation to program types (NSF-supported, University of Chicago School Mathematics Project (UCSMP), and commercially generated) in relation to their reported outcome measures.
A list of alternative hypotheses on effectiveness.
Filters based on the critical decision points.
An analysis of results by subpopulations.
An analysis of results by content strand.
An analysis of interactions among content, equity, and grade levels.
Discussion and summary statements.
In this report, we describe our methodology for review and synthesis so that others might scrutinize our approach and offer criticism on the basis of
our methodology and its connection to the results stated and conclusions drawn. In the spirit of scientific, fair, and open investigation, we welcome others to undertake similar or contrasting approaches and compare and discuss the results. Our work was limited by the short timeline set by the funding agencies resulting from the urgency of the task. Although we made multiple efforts to collect comparative studies, we apologize to any curriculum evaluators if comparative studies were unintentionally omitted from our database.
Of these 95 comparative studies, 65 were studies of NSF-supported curricula, 27 were studies of commercially generated materials, and 3 included two curricula each from one of these two categories. To avoid the problem of double coding, two studies, White et al. (1995) and Zahrt (2001), were coded within studies of NSF-supported curricula because more of the classes studied used the NSF-supported curriculum. These studies were not used in later analyses because they did not meet the requirements for the at least minimally methodologically adequate studies, as described below. The other, Peters (1992), compared two commercially generated curricula, and was coded in that category under the primary program of focus. Therefore, of the 95 comparative studies, 67 studies were coded as NSF-supported curricula and 28 were coded as commercially generated materials.
The 11 evaluation studies of the UCSMP secondary program that we reviewed, not including White et al. and Zahrt as previously mentioned, benefit from the maturity of the program, while demonstrating an orientation to both establishing effectiveness and improving a product line. For these reasons, at times we will present the summary of UCSMP’s data separately.
The Saxon materials also present a somewhat different profile from the other commercially generated materials because many of the evaluations of these materials were conducted in the 1980s and the materials were originally developed with a rather atypical program theory. Saxon (1981) designed its algebra materials to combine distributed practice with incremental development. We selected the Saxon materials as a middle grades commercially generated program, and limited its review to middle school studies from 1989 onward when the first National Council of Teachers of Mathematics (NCTM) Standards (NCTM, 1989) were released. This eliminated concerns that the materials or the conditions of educational practice have been altered during the intervening time period. The Saxon materials explicitly do not draw from the NCTM Standards nor did they receive support from the NSF; thus they truly represent a commercial venture. As a result, we categorized the Saxon studies within the group of studies of commercial materials.
At times in this report, we describe characteristics of the database by
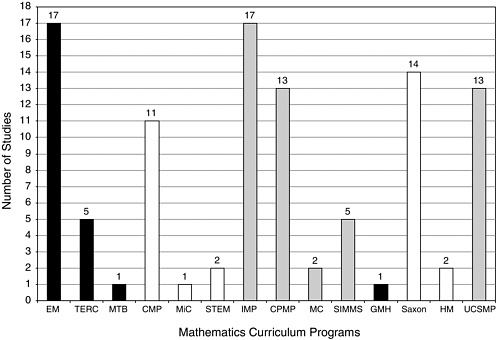
FIGURE 5-1 The distribution of comparative studies across programs. Programs are coded by grade band: black bars = elementary, white bars = middle grades, and gray bars = secondary. In this figure, there are six studies that involved two programs and one study that involved three programs.
NOTE: Five programs (MathScape, MMAP, MMOW/ARISE, Addison-Wesley, and Harcourt) are not shown above since no comparative studies were reviewed.
particular curricular program evaluations, in which case all 19 programs are listed separately. At other times, when we seek to inform ourselves on policy-related issues of funding and evaluating curricular materials, we use the NSF-supported, commercially generated, and UCSMP distinctions. We remind the reader of the artificial aspects of this distinction because at the present time, 18 of the 19 curricula are published commercially. In order to track the question of historical inception and policy implications, a distinction is drawn between the three categories. Figure 5-1 shows the distribution of comparative studies across the 14 programs.
The first result the committee wishes to report is the uneven distribution of studies across the curricula programs. There were 67 coded studies of the NSF curricula, 11 studies of UCSMP, and 17 studies of the commercial publishers. The 14 evaluation studies conducted on the Saxon materials compose the bulk of these 17-non-UCSMP and non-NSF-supported curricular evaluation studies. As these results suggest, we know more about the
evaluations of the NSF-supported curricula and UCSMP than about the evaluations of the commercial programs. We suggest that three factors account for this uneven distribution of studies. First, evaluations have been funded by the NSF both as a part of the original call, and as follow-up to the work in the case of three supplemental awards to two of the curricula programs. Second, most NSF-supported programs and UCSMP were developed at university sites where there is access to the resources of graduate students and research staff. Finally, there was some reported reluctance on the part of commercial companies to release studies that could affect perceptions of competitive advantage. As Figure 5-1 shows, there were quite a few comparative studies of Everyday Mathematics (EM), Connected Mathematics Project (CMP), Contemporary Mathematics in Context (Core-Plus Mathematics Project [CPMP]), Interactive Mathematics Program (IMP), UCSMP, and Saxon.
In the programs with many studies, we note that a significant number of studies were generated by a core set of authors. In some cases, the evaluation reports follow a relatively uniform structure applied to single schools, generating multiple studies or following cohorts over years. Others use a standardized evaluation approach to evaluate sequential courses. Any reports duplicating exactly the same sample, outcome measures, or forms of analysis were eliminated. For example, one study of Mathematics Trailblazers (Carter et al., 2002) reanalyzed the data from the larger ARC Implementation Center study (Sconiers et al., 2002), so it was not included separately. Synthesis studies referencing a variety of evaluation reports are summarized in Chapter 6 , but relevant individual studies that were referenced in them were sought out and included in this comparative review.
Other less formal comparative studies are conducted regularly at the school or district level, but such studies were not included in this review unless we could obtain formal reports of their results, and the studies met the criteria outlined for inclusion in our database. In our conclusions, we address the issue of how to collect such data more systematically at the district or state level in order to subject the data to the standards of scholarly peer review and make it more systematically and fairly a part of the national database on curricular effectiveness.
A standard for evaluation of any social program requires that an impact assessment is warranted only if two conditions are met: (1) the curricular program is clearly specified, and (2) the intervention is well implemented. Absent this assurance, one must have a means of ensuring or measuring treatment integrity in order to make causal inferences. Rossi et al. (1999, p. 238) warned that:
two prerequisites [must exist] for assessing the impact of an intervention. First, the program’s objectives must be sufficiently well articulated to make
it possible to specify credible measures of the expected outcomes, or the evaluator must be able to establish such a set of measurable outcomes. Second, the intervention should be sufficiently well implemented that there is no question that its critical elements have been delivered to appropriate targets. It would be a waste of time, effort, and resources to attempt to estimate the impact of a program that lacks measurable outcomes or that has not been properly implemented. An important implication of this last consideration is that interventions should be evaluated for impact only when they have been in place long enough to have ironed out implementation problems.
These same conditions apply to evaluation of mathematics curricula. The comparative studies in this report varied in the quality of documentation of these two conditions; however, all addressed them to some degree or another. Initially by reviewing the studies, we were able to identify one general design template, which consisted of seven critical decision points and determined that it could be used to develop a framework for conducting our meta-analysis. The seven critical decision points we identified initially were:
Choice of type of design: experimental or quasi-experimental;
For those studies that do not use random assignment: what methods of establishing comparability of groups were built into the design—this includes student characteristics, teacher characteristics, and the extent to which professional development was involved as part of the definition of a curriculum;
Definition of the appropriate unit of analysis (students, classes, teachers, schools, or districts);
Inclusion of an examination of implementation components;
Definition of the outcome measures and disaggregated results by program;
The choice of statistical tests, including statistical significance levels and effect size; and
Recognition of limitations to generalizability resulting from design choices.
These are critical decisions that affect the quality of an evaluation. We further identified a subset of these evaluation studies that met a set of minimum conditions that we termed at least minimally methodologically adequate studies. Such studies are those with the greatest likelihood of shedding light on the effectiveness of these programs. To be classified as at least minimally methodologically adequate, and therefore to be considered for further analysis, each evaluation study was required to:
Include quantifiably measurable outcomes such as test scores, responses to specified cognitive tasks of mathematical reasoning, performance evaluations, grades, and subsequent course taking; and
Provide adequate information to judge the comparability of samples. In addition, a study must have included at least one of the following additional design elements:
A report of implementation fidelity or professional development activity;
Results disaggregated by content strands or by performance by student subgroups; and/or
Multiple outcome measures or precise theoretical analysis of a measured construct, such as number sense, proof, or proportional reasoning.
Using this rubric, the committee identified a subset of 63 comparative studies to classify as at least minimally methodologically adequate and to analyze in depth to inform the conduct of future evaluations. There are those who would argue that any threat to the validity of a study discredits the findings, thus claiming that until we know everything, we know nothing. Others would claim that from the myriad of studies, examining patterns of effects and patterns of variation, one can learn a great deal, perhaps tentatively, about programs and their possible effects. More importantly, we can learn about methodologies and how to concentrate and focus to increase the likelihood of learning more quickly. As Lipsey (1997, p. 22) wrote:
In the long run, our most useful and informative contribution to program managers and policy makers and even to the evaluation profession itself may be the consolidation of our piecemeal knowledge into broader pictures of the program and policy spaces at issue, rather than individual studies of particular programs.
We do not wish to imply that we devalue studies of student affect or conceptions of mathematics, but decided that unless these indicators were connected to direct indicators of student learning, we would eliminate them from further study. As a result of this sorting, we eliminated 19 studies of NSF-supported curricula and 13 studies of commercially generated curricula. Of these, 4 were eliminated for their sole focus on affect or conceptions, 3 were eliminated for their comparative focus on outcomes other than achievement, such as teacher-related variables, and 19 were eliminated for their failure to meet the minimum additional characteristics specified in the criteria above. In addition, six others were excluded from the studies of commercial materials because they were not conducted within the grade-
level band specified by the committee for the selection of that program. From this point onward, all references can be assumed to refer to at least minimally methodologically adequate unless a study is referenced for illustration, in which case we label it with “EX” to indicate that it is excluded in the summary analyses. Studies labeled “EX” are occasionally referenced because they can provide useful information on certain aspects of curricular evaluation, but not on the overall effectiveness.
The at least minimally methodologically adequate studies reported on a variety of grade levels. Figure 5-2 shows the different grade levels of the studies. At times, the choice of grade levels was dictated by the years in which high-stakes tests were given. Most of the studies reported on multiple grade levels, as shown in Figure 5-2 .
Using the seven critical design elements of at least minimally methodologically adequate studies as a design template, we describe the overall database and discuss the array of choices on critical decision points with examples. Following that, we report on the results on the at least minimally methodologically adequate studies by program type. To do so, the results of each study were coded as either statistically significant or not. Those studies
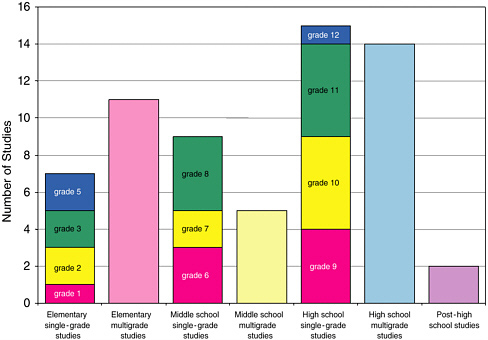
FIGURE 5-2 Single-grade studies by grade and multigrade studies by grade band.
that contained statistically significant results were assigned a percentage of outcomes that are positive (in favor of the treatment curriculum) based on the number of statistically significant comparisons reported relative to the total number of comparisons reported, and a percentage of outcomes that are negative (in favor of the comparative curriculum). The remaining were coded as the percentage of outcomes that are non significant. Then, using seven critical decision points as filters, we identified and examined more closely sets of studies that exhibited the strongest designs, and would therefore be most likely to increase our confidence in the validity of the evaluation. In this last section, we consider alternative hypotheses that could explain the results.
The committee emphasizes that we did not directly evaluate the materials. We present no analysis of results aggregated across studies by naming individual curricular programs because we did not consider the magnitude or rigor of the database for individual programs substantial enough to do so. Nevertheless, there are studies that provide compelling data concerning the effectiveness of the program in a particular context. Furthermore, we do report on individual studies and their results to highlight issues of approach and methodology and to remain within our primary charge, which was to evaluate the evaluations, we do not summarize results of the individual programs.
DESCRIPTION OF COMPARATIVE STUDIES DATABASE ON CRITICAL DECISION POINTS
An experimental or quasi-experimental design.
We separated the studies into experimental and quasiexperimental, and found that 100 percent of the studies were quasiexperimental (Campbell and Stanley, 1966; Cook and Campbell, 1979; and Rossi et al., 1999). 1 Within the quasi-experimental studies, we identified three subcategories of comparative study. In the first case, we identified a study as cross-curricular comparative if it compared the results of curriculum A with curriculum B. A few studies in this category also compared two samples within the curriculum to each other and specified different conditions such as high and low implementation quality.
A second category of a quasi-experimental study involved comparisons that could shed light on effectiveness involving time series studies. These studies compared the performance of a sample of students in a curriculum
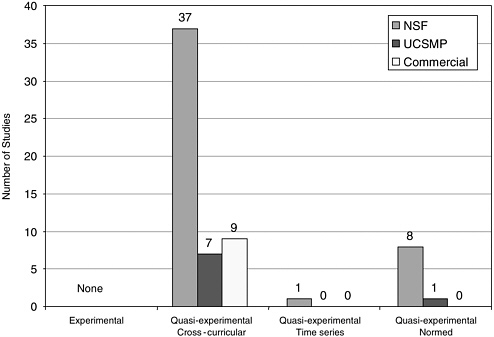
FIGURE 5-3 The number of comparative studies in each category.
under investigation across time, such as in a longitudinal study of the same students over time. A third category of comparative study involved a comparison to some form of externally normed results, such as populations taking state, national, or international tests or prior research assessment from a published study or studies. We categorized these studies and divided them into NSF, UCSMP, and commercial and labeled them by the categories above ( Figure 5-3 ).
In nearly all studies in the comparative group, the titles of experimental curricula were explicitly identified. The only exception to this was the ARC Implementation Center study (Sconiers et al., 2002), where three NSF-supported elementary curricula were examined, but in the results, their effects were pooled. In contrast, in the majority of the cases, the comparison curriculum is referred to simply as “traditional.” In only 22 cases were comparisons made between two identified curricula. Many others surveyed the array of curricula at comparison schools and reported on the most frequently used, but did not identify a single curriculum. This design strategy is used often because other factors were used in selecting comparison groups, and the additional requirement of a single identified curriculum in
these sites would often make it difficult to match. Studies were categorized into specified (including a single or multiple identified curricula) and nonspecified curricula. In the 63 studies, the central group was compared to an NSF-supported curriculum (1), an unnamed traditional curriculum (41), a named traditional curriculum (19), and one of the six commercial curricula (2). To our knowledge, any systematic impact of such a decision on results has not been studied, but we express concern that when a specified curriculum is compared to an unspecified content which is a set of many informal curriculum, the comparison may favor the coherency and consistency of the single curricula, and we consider this possibility subsequently under alternative hypotheses. We believe that a quality study should at least report the array of curricula that comprise the comparative group and include a measure of the frequency of use of each, but a well-defined alternative is more desirable.
If a study was both longitudinal and comparative, then it was coded as comparative. When studies only examined performances of a group over time, such as in some longitudinal studies, it was coded as quasi-experimental normed. In longitudinal studies, the problems created by student mobility were evident. In one study, Carroll (2001), a five-year longitudinal study of Everyday Mathematics, the sample size began with 500 students, 24 classrooms, and 11 schools. By 2nd grade, the longitudinal sample was 343. By 3rd grade, the number of classes increased to 29 while the number of original students decreased to 236 students. At the completion of the study, approximately 170 of the original students were still in the sample. This high rate of attrition from the study suggests that mobility is a major challenge in curricular evaluation, and that the effects of curricular change on mobile students needs to be studied as a potential threat to the validity of the comparison. It is also a challenge in curriculum implementation because students coming into a program do not experience its cumulative, developmental effect.
Longitudinal studies also have unique challenges associated with outcome measures, a study by Romberg et al. (in press) (EX) discussed one approach to this problem. In this study, an external assessment system and a problem-solving assessment system were used. In the External Assessment System, items from the National Assessment of Educational Progress (NAEP) and Third International Mathematics and Science Survey (TIMSS) were balanced across four strands (number, geometry, algebra, probability and statistics), and 20 items of moderate difficulty, called anchor items, were repeated on each grade-specific assessment (p. 8). Because the analyses of the results are currently under way, the evaluators could not provide us with final results of this study, so it is coded as EX.
However, such longitudinal studies can provide substantial evidence of the effects of a curricular program because they may be more sensitive to an
TABLE 5-1 Scores in Percentage Correct by Everyday Mathematics Students and Various Comparison Groups Over a Five-Year Longitudinal Study
accumulation of modest effects and/or can reveal whether the rates of learning change over time within curricular change.
The longitudinal study by Carroll (2001) showed that the effects of curricula may often accrue over time, but measurements of achievement present challenges to drawing such conclusions as the content and grade level change. A variety of measures were used over time to demonstrate growth in relation to comparison groups. The author chose a set of measures used previously in studies involving two Asian samples and an American sample to provide a contrast to the students in EM over time. For 3rd and 4th grades, where the data from the comparison group were not available, the authors selected items from the NAEP to bridge the gap. Table 5-1 summarizes the scores of the different comparative groups over five years. Scores are reported as the mean percentage correct for a series of tests on number computation, number concepts and applications, geometry, measurement, and data analysis.
It is difficult to compare performances on different tests over different groups over time against a single longitudinal group from EM, and it is not possible to determine whether the students’ performance is increasing or whether the changes in the tests at each grade level are producing the results; thus the results from longitudinal studies lacking a control group or use of sophisticated methodological analysis may be suspect and should be interpreted with caution.
In the Hirsch and Schoen (2002) study, based on a sample of 1,457 students, scores on Ability to Do Quantitative Thinking (ITED-Q) a subset of the Iowa Tests of Education Development, students in Core-Plus showed increasing performance over national norms over the three-year time period. The authors describe the content of the ITED-Q test and point out
that “although very little symbolic algebra is required, the ITED-Q is quite demanding for the full range of high school students” (p. 3). They further point out that “[t]his 3-year pattern is consistent, on average, in rural, urban, and suburban schools, for males and females, for various minority groups, and for students for whom English was not their first language” (p. 4). In this case, one sees that studies over time are important as results over shorter periods may mask cumulative effects of consistent and coherent treatments and such studies could also show increases that do not persist when subject to longer trajectories. One approach to longitudinal studies was used by Webb and Dowling in their studies of the Interactive Mathematics Program (Webb and Dowling, 1995a, 1995b, 1995c). These researchers conducted transcript analyses as a means to examine student persistence and success in subsequent course taking.
The third category of quasi-experimental comparative studies measured student outcomes on a particular curricular program and simply compared them to performance on national tests or international tests. When these tests were of good quality and were representative of a genuine sample of a relevant population, such as NAEP reports or TIMSS results, the reports often provided one a reasonable indicator of the effects of the program if combined with a careful description of the sample. Also, sometimes the national tests or state tests used were norm-referenced tests producing national percentiles or grade-level equivalents. The normed studies were considered of weaker quality in establishing effectiveness, but were still considered valid as examples of comparing samples to populations.
For Studies That Do Not Use Random Assignment: What Methods of Establishing Comparability Across Groups Were Built into the Design
The most fundamental question in an evaluation study is whether the treatment has had an effect on the chosen criterion variable. In our context, the treatment is the curriculum materials, and in some cases, related professional development, and the outcome of interest is academic learning. To establish if there is a treatment effect, one must logically rule out as many other explanations as possible for the differences in the outcome variable. There is a long tradition on how this is best done, and the principle from a design point of view is to assure that there are no differences between the treatment conditions (especially in these evaluations, often there are only the new curriculum materials to be evaluated and a control group) either at the outset of the study or during the conduct of the study.
To ensure the first condition, the ideal procedure is the random assignment of the appropriate units to the treatment conditions. The second condition requires that the treatment is administered reliably during the length of the study, and is assured through the careful observation and
control of the situation. Without randomization, there are a host of possible confounding variables that could differ among the treatment conditions and that are related themselves to the outcome variables. Put another way, the treatment effect is a parameter that the study is set up to estimate. Statistically, an estimate that is unbiased is desired. The goal is that its expected value over repeated samplings is equal to the true value of the parameter. Without randomization at the onset of a study, there is no way to assure this property of unbiasness. The variables that differ across treatment conditions and are related to the outcomes are confounding variables, which bias the estimation process.
Only one study we reviewed, Peters (1992), used randomization in the assignment of students to treatments, but that occurred because the study was limited to one teacher teaching two sections and included substantial qualitative methods, so we coded it as quasi-experimental. Others report partially assigning teachers randomly to treatment conditions (Thompson, et al., 2001; Thompson et al., 2003). Two primary reasons seem to account for a lack of use of pure experimental design. To justify the conduct and expense of a randomized field trial, the program must be described adequately and there must be relative assurance that its implementation has occurred over the duration of the experiment (Peterson et al., 1999). Additionally, one must be sure that the outcome measures are appropriate for the range of performances in the groups and valid relative to the curricula under investigation. Seldom can such conditions be assured for all students and teachers and over the duration of a year or more.
A second reason is that random assignment of classrooms to curricular treatment groups typically is not permitted or encouraged under normal school conditions. As one evaluator wrote, “Building or district administrators typically identified teachers who would be in the study and in only a few cases was random assignment of teachers to UCSMP Algebra or comparison classes possible. School scheduling and teacher preference were more important factors to administrators and at the risk of losing potential sites, we did not insist on randomization” (Mathison et al., 1989, p. 11).
The Joint Committee on Standards for Educational Evaluation (1994, p. 165) committee of evaluations recognized the likelihood of limitations on randomization, writing:
The groups being compared are seldom formed by random assignment. Rather, they tend to be natural groupings that are likely to differ in various ways. Analytical methods may be used to adjust for these initial differences, but these methods are based upon a number of assumptions. As it is often difficult to check such assumptions, it is advisable, when time and resources permit, to use several different methods of analysis to determine whether a replicable pattern of results is obtained.
Does the dearth of pure experimentation render the results of the studies reviewed worthless? Bias is not an “either-or” proposition, but it is a quantity of varying degrees. Through careful measurement of the most salient potential confounding variables, precise theoretical description of constructs, and use of these methods of statistical analysis, it is possible to reduce the amount of bias in the estimated treatment effect. Identification of the most likely confounding variables and their measurement and subsequent adjustments can greatly reduce bias and help estimate an effect that is likely to be more reflective of the true value. The theoretical fully specified model is an alternative to randomization by including relevant variables and thus allowing the unbiased estimation of the parameter. The only problem is realizing when the model is fully specified.
We recognized that we can never have enough knowledge to assure a fully specified model, especially in the complex and unstable conditions of schools. However, a key issue in determining the degree of confidence we have in these evaluations is to examine how they have identified, measured, or controlled for such confounding variables. In the next sections, we report on the methods of the evaluators in identifying and adjusting for such potential confounding variables.
One method to eliminate confounding variables is to examine the extent to which the samples investigated are equated either by sample selection or by methods of statistical adjustments. For individual students, there is a large literature suggesting the importance of social class to achievement. In addition, prior achievement of students must be considered. In the comparative studies, investigators first identified participation of districts, schools, or classes that could provide sufficient duration of use of curricular materials (typically two years or more), availability of target classes, or adequate levels of use of program materials. Establishing comparability was a secondary concern.
These two major factors were generally used in establishing the comparability of the sample:
Student population characteristics, such as demographic characteristics of students in terms of race/ethnicity, economic levels, or location type (urban, suburban, or rural).
Performance-level characteristics such as performance on prior tests, pretest performance, percentage passing standardized tests, or related measures (e.g., problem solving, reading).
In general, four methods of comparing groups were used in the studies we examined, and they permit different degrees of confidence in their results. In the first type, a matching class, school, or district was identified.
Studies were coded as this type if specified characteristics were used to select the schools systematically. In some of these studies, the methodology was relatively complex as correlates of performance on the outcome measures were found empirically and matches were created on that basis (Schneider, 2000; Riordan and Noyce, 2001; and Sconiers et al., 2002). For example, in the Sconiers et al. study, where the total sample of more than 100,000 students was drawn from five states and three elementary curricula are reviewed (Everyday Mathematics, Math Trailblazers [MT], and Investigations [IN], a highly systematic method was developed. After defining eligibility as a “reform school,” evaluators conducted separate regression analyses for the five states at each tested grade level to identify the strongest predictors of average school mathematics score. They reported, “reading score and low-income variables … consistently accounted for the greatest percentage of total variance. These variables were given the greatest weight in the matching process. Other variables—such as percent white, school mobility rate, and percent with limited English proficiency (LEP)—accounted for little of the total variance but were typically significant. These variables were given less weight in the matching process” (Sconiers et al., 2002, p. 10). To further provide a fair and complete comparison, adjustments were made based on regression analysis of the scores to minimize bias prior to calculating the difference in scores and reporting effect sizes. In their results the evaluators report, “The combined state-grade effect sizes for math and total are virtually identical and correspond to a percentile change of about 4 percent favoring the reform students” (p. 12).
A second type of matching procedure was used in the UCSMP evaluations. For example, in an evaluation centered on geometry learning, evaluators advertised in NCTM and UCSMP publications, and set conditions for participation from schools using their program in terms of length of use and grade level. After selecting schools with heterogeneous grouping and no tracking, the researchers used a match-pair design where they selected classes from the same school on the basis of mathematics ability. They used a pretest to determine this, and because the pretest consisted of two parts, they adjusted their significance level using the Bonferroni method. 2 Pairs were discarded if the differences in means and variance were significant for all students or for those students completing all measures, or if class sizes became too variable. In the algebra study, there were 20 pairs as a result of the matching, and because they were comparing three experimental conditions—first edition, second edition, and comparison classes—in the com-
parison study relevant to this review, their matching procedure identified 8 pairs. When possible, teachers were assigned randomly to treatment conditions. Most results are presented with the eight identified pairs and an accumulated set of means. The outcomes of this particular study are described below in a discussion of outcome measures (Thompson et al., 2003).
A third method was to measure factors such as prior performance or socio-economic status (SES) based on pretesting, and then to use analysis of covariance or multiple regression in the subsequent analysis to factor in the variance associated with these factors. These studies were coded as “control.” A number of studies of the Saxon curricula used this method. For example, Rentschler (1995) conducted a study of Saxon 76 compared to Silver Burdett with 7th graders in West Virginia. He reported that the groups differed significantly in that the control classes had 65 percent of the students on free and reduced-price lunch programs compared to 55 percent in the experimental conditions. He used scores on California Test of Basic Skills mathematics computation and mathematics concepts and applications as his pretest scores and found significant differences in favor of the experimental group. His posttest scores showed the Saxon experimental group outperformed the control group on both computation and concepts and applications. Using analysis of covariance, the computation difference in favor of the experimental group was statistically significant; however, the difference in concepts and applications was adjusted to show no significant difference at the p < .05 level.
A fourth method was noted in studies that used less rigorous methods of selection of sample and comparison of prior achievement or similar demographics. These studies were coded as “compare.” Typically, there was no explicit procedure to decide if the comparison was good enough. In some of the studies, it appeared that the comparison was not used as a means of selection, but rather as a more informal device to convince the reader of the plausibility of the equivalence of the groups. Clearly, the studies that used a more precise method of selection were more likely to produce results on which one’s confidence in the conclusions is greater.
Definition of Unit of Analysis
A major decision in forming an evaluation design is the unit of analysis. The unit of selection or randomization used to assign elements to treatment and control groups is closely linked to the unit of analysis. As noted in the National Research Council (NRC) report (1992, p. 21):
If one carries out the assignment of treatments at the level of schools, then that is the level that can be justified for causal analysis. To analyze the results at the student level is to introduce a new, nonrandomized level into
the study, and it raises the same issues as does the nonrandomized observational study…. The implications … are twofold. First, it is advisable to use randomization at the level at which units are most naturally manipulated. Second, when the unit of observation is at a “lower” level of aggregation than the unit of randomization, then for many purposes the data need to be aggregated in some appropriate fashion to provide a measure that can be analyzed at the level of assignment. Such aggregation may be as simple as a summary statistic or as complex as a context-specific model for association among lower-level observations.
In many studies, inadequate attention was paid to the fact that the unit of selection would later become the unit of analysis. The unit of analysis, for most curriculum evaluators, needs to be at least the classroom, if not the school or even the district. The units must be independently responding units because instruction is a group process. Students are not independent, the classroom—even if the teachers work together in a school on instruction—is not entirely independent, so the school is the unit. Care needed to be taken to ensure that an adequate numbers of units would be available to have sufficient statistical power to detect important differences.
A curriculum is experienced by students in a group, and this implies that individual student responses and what they learn are correlated. As a result, the appropriate unit of assignment and analysis must at least be defined at the classroom or teacher level. Other researchers (Bryk et al., 1993) suggest that the unit might be better selected at an even higher level of aggregation. The school itself provides a culture in which the curriculum is enacted as it is influenced by the policies and assignments of the principal, by the professional interactions and governance exhibited by the teachers as a group, and by the community in which the school resides. This would imply that the school might be the appropriate unit of analysis. Even further, to the extent that such decisions about curriculum are made at the district level and supported through resources and professional development at that level, the appropriate unit could arguably be the district. On a more practical level, we found that arguments can be made for a variety of decisions on the selection of units, and what is most essential is to make a clear argument for one’s choice, to use the same unit in the analysis as in the sample selection process, and to recognize the potential limits to generalization that result from one’s decisions.
We would argue in all cases that reports of how sites are selected must be explicit in the evaluation report. For example, one set of evaluation studies selected sites by advertisements in a journal distributed by the program and in NCTM journals (UCSMP) (Thompson et al., 2001; Thompson et al., 2003). The samples in their studies tended to be affluent suburban populations and predominantly white populations. Other conditions of inclusion, such as frequency of use also might have influenced this outcome,
but it is important that over a set of studies on effectiveness, all populations of students be adequately sampled. When a study is not randomized, adjustments for these confounding variables should be included. In our analysis of equity, we report on the concerns about representativeness of the overall samples and their impact on the generalizability of the results.
Implementation Components
The complexity of doing research on curricular materials introduces a number of possible confounding variables. Due to the documented complexity of curricular implementation, most comparative study evaluators attempt to monitor implementation in some fashion. A valuable outcome of a well-conducted evaluation is to determine not only if the experimental curriculum could ideally have a positive impact on learning, but whether it can survive or thrive in the conditions of schooling that are so variable across sites. It is essential to know what the treatment was, whether it occurred, and if so, to what degree of intensity, fidelity, duration, and quality. In our model in Chapter 3 , these factors were referred to as “implementation components.” Measuring implementation can be costly for large-scale comparative studies; however, many researchers have shown that variation in implementation is a key factor in determining effectiveness. In coding the comparative studies, we identified three types of components that help to document the character of the treatment: implementation fidelity, professional development treatments, and attention to teacher effects.
Implementation Fidelity
Implementation fidelity is a measure of the basic extent of use of the curricular materials. It does not address issues of instructional quality. In some studies, implementation fidelity is synonymous with “opportunity to learn.” In examining implementation fidelity, a variety of data were reported, including, most frequently, the extent of coverage of the curricular material, the consistency of the instructional approach to content in relation to the program’s theory, reports of pedagogical techniques, and the length of use of the curricula at the sample sites. Other less frequently used approaches documented the calendar of curricular coverage, requested teacher feedback by textbook chapter, conducted student surveys, and gauged homework policies, use of technology, and other particular program elements. Interviews with teachers and students, classroom surveys, and observations were the most frequently used data-gathering techniques. Classroom observations were conducted infrequently in these studies, except in cases when comparative studies were combined with case studies, typically with small numbers of schools and classes where observations
were conducted for long or frequent time periods. In our analysis, we coded only the presence or absence of one or more of these methods.
If the extent of implementation was used in interpreting the results, then we classified the study as having adjusted for implementation differences. Across all 63 at least minimally methodologically adequate studies, 44 percent reported some type of implementation fidelity measure, 3 percent reported and adjusted for it in interpreting their outcome measures, and 53 percent recorded no information on this issue. Differences among studies, by study type (NSF, UCSMP, and commercially generated), showed variation on this issue, with 46 percent of NSF reporting or adjusting for implementation, 75 percent of UCSMP, and only 11 percent of the other studies of commercial materials doing so. Of the commercial, non-UCSMP studies included, only one reported on implementation. Possibly, the evaluators for the NSF and UCSMP Secondary programs recognized more clearly that their programs demanded significant changes in practice that could affect their outcomes and could pose challenges to the teachers assigned to them.
A study by Abrams (1989) (EX) 3 on the use of Saxon algebra by ninth graders showed that concerns for implementation fidelity extend to all curricula, even those like Saxon whose methods may seem more likely to be consistent with common practice. Abrams wrote, “It was not the intent of this study to determine the effectiveness of the Saxon text when used as Saxon suggests, but rather to determine the effect of the text as it is being used in the classroom situations. However, one aspect of the research was to identify how the text is being taught, and how closely teachers adhere to its content and the recommended presentation” (p. 7). Her findings showed that for the 9 teachers and 300 students, treatment effects favoring the traditional group (using Dolciani’s Algebra I textbook, Houghton Mifflin, 1980) were found on the algebra test, the algebra knowledge/skills subtest, and the problem-solving test for this population of teachers (fixed effect). No differences were found between the groups on an algebra understanding/applications subtest, overall attitude toward mathematics, mathematical self-confidence, anxiety about mathematics, or enjoyment of mathematics. She suggests that the lack of differences might be due to the ways in which teachers supplement materials, change test conditions, emphasize
and deemphasize topics, use their own tests, vary the proportion of time spent on development and practice, use calculators and group work, and basically adapt the materials to their own interpretation and method. Many of these practices conflict directly with the recommendations of the authors of the materials.
A study by Briars and Resnick (2000) (EX) in Pittsburgh schools directly confronted issues relevant to professional development and implementation. Evaluators contrasted the performance of students of teachers with high and low implementation quality, and showed the results on two contrasting outcome measures, Iowa Test of Basic Skills (ITBS) and Balanced Assessment. Strong implementers were defined as those who used all of the EM components and provided student-centered instruction by giving students opportunities to explore mathematical ideas, solve problems, and explain their reasoning. Weak implementers were either not using EM or using it so little that the overall instruction in the classrooms was “hardly distinguishable from traditional mathematics instruction” (p. 8). Assignment was based on observations of student behavior in classes, the presence or absence of manipulatives, teacher questionnaires about the programs, and students’ knowledge of classroom routines associated with the program.
From the identification of strong- and weak-implementing teachers, strong- and weak-implementation schools were identified as those with strong- or weak-implementing teachers in 3rd and 4th grades over two consecutive years. The performance of students with 2 years of EM experience in these settings composed the comparative samples. Three pairs of strong- and weak-implementation schools with similar demographics in terms of free and reduced-price lunch (range 76 to 93 percent), student living with only one parent (range 57 to 82 percent), mobility (range 8 to 16 percent), and ethnicity (range 43 to 98 percent African American) were identified. These students’ 1st-grade ITBS scores indicated similarity in prior performance levels. Finally, evaluators predicted that if the effects were due to the curricular implementation and accompanying professional development, the effects on scores should be seen in 1998, after full implementation. Figure 5-4 shows that on the 1998 New Standards exams, placement in strong- and weak-implementation schools strongly affected students’ scores. Over three years, performance in the district on skills, concepts, and problem solving rose, confirming the evaluator’s predictions.
An article by McCaffrey et al. (2001) examining the interactions among instructional practices, curriculum, and student achievement illustrates the point that distinctions are often inadequately linked to measurement tools in their treatment of the terms traditional and reform teaching. In this study, researchers conducted an exploratory factor analysis that led them to create two scales for instructional practice: Reform Practices and Tradi-
FIGURE 5-4 Percentage of students who met or exceeded the standard. Districtwide grade 4 New Standards Mathematics Reference Examination (NSMRE) performance for 1996, 1997, and 1998 by level of Everyday Mathematics implementation. Percentage of students who achieved the standard. Error bars denote the 99 percent confidence interval for each data point.
SOURCE: Re-created from Briars and Resnick (2000, pp. 19-20).
tional Practices. The reform scale measured the frequency, by means of teacher report, of teacher and student behaviors associated with reform instruction and assessment practices, such as using small-group work, explaining reasoning, representing and using data, writing reflections, or performing tasks in groups. The traditional scale focused on explanations to whole classes, the use of worksheets, practice, and short-answer assessments. There was a –0.32 correlation between scores for integrated curriculum teachers. There was a 0.27 correlation between scores for traditional
curriculum teachers. This shows that it is overly simplistic to think that reform and traditional practices are oppositional. The relationship among a variety of instructional practices is rather more complex as they interact with curriculum and various student populations.
Professional Development
Professional development and teacher effects were separated in our analysis from implementation fidelity. We recognized that professional development could be viewed by the readers of this report in two ways. As indicated in our model, professional development can be considered a program element or component or it can be viewed as part of the implementation process. When viewed as a program element, professional development resources are considered mandatory along with program materials. In relation to evaluation, proponents of considering professional development as a mandatory program element argue that curricular innovations, which involve the introduction of new topics, new types of assessment, or new ways of teaching, must make provision for adequate training, just as with the introduction of any new technology.
For others, the inclusion of professional development in the program elements without a concomitant inclusion of equal amounts of professional development relevant to a comparative treatment interjects a priori disproportionate treatments and biases the results. We hoped for an array of evaluation studies that might shed some empirical light on this dispute, and hence separated professional development from treatment fidelity, coding whether or not studies reported on the amount of professional development provided for the treatment and/or comparison groups. A study was coded as positive if it either reported on the professional development provided on the experimental group or reported the data on both treatments. Across all 63 at least minimally methodologically adequate studies, 27 percent reported some type of professional development measure, 1.5 percent reported and adjusted for it in interpreting their outcome measures, and 71.5 percent recorded no information on the issue.
A study by Collins (2002) (EX) 4 illustrates the critical and controversial role of professional development in evaluation. Collins studied the use of Connected Math over three years, in three middle schools in threat of being classified as low performing in the Massachusetts accountability system. A comparison was made between one school (School A) that engaged
substantively in professional development opportunities accompanying the program and two that did not (Schools B and C). In the CMP school reports (School A) totals between 100 and 136 hours of professional development were recorded for all seven teachers in grades 6 through 8. In School B, 66 hours were reported for two teachers and in School C, 150 hours were reported for eight teachers over three years. Results showed significant differences in the subsequent performance by students at the school with higher participation in professional development (School A) and it became a districtwide top performer; the other two schools remained at risk for low performance. No controls for teacher effects were possible, but the results do suggest the centrality of professional development for successful implementation or possibly suggest that the results were due to professional development rather than curriculum materials. The fact that these two interpretations cannot be separated is a problem when professional development is given to one and not the other. The effect could be due to textbook or professional development or an interaction between the two. Research designs should be adjusted to consider these issues when different conditions of professional development are provided.
Teacher Effects
These studies make it obvious that there are potential confounding factors of teacher effects. Many evaluation studies devoted inadequate attention to the variable of teacher quality. A few studies (Goodrow, 1998; Riordan and Noyce, 2001; Thompson et al., 2001; and Thompson et al., 2003) reported on teacher characteristics such as certification, length of service, experience with curricula, or degrees completed. Those studies that matched classrooms and reported by matched results rather than aggregated results sought ways to acknowledge the large variations among teacher performance and its impact on student outcomes. We coded any effort to report on possible teacher effects as one indicator of quality. Across all 63 at least minimally methodologically adequate studies, 16 percent reported some type of teacher effect measure, 3 percent reported and adjusted for it in interpreting their outcome measures, and 81 percent recorded no information on this issue.
One can see that the potential confounding factors of teacher effects, in terms of the provision of professional development or the measure of teacher effects, are not adequately considered in most evaluation designs. Some studies mention and give a subjective judgment as to the nature of the problem, but this is descriptive at the most. Hardly any of the studies actually do anything analytical, and because these are such important potential confounding variables, this presents a serious challenge to the efficacy of these studies. Figure 5-5 shows how attention to these factors varies
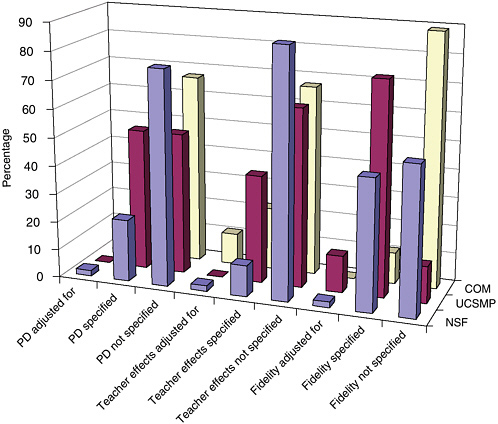
FIGURE 5-5 Treatment of implementation components by program type.
NOTE: PD = professional development.
across program categories among NSF-supported, UCSMP, and studies of commercial materials. In general, evaluations of NSF-supported studies were the most likely to measure these variables; UCSMP had the most standardized use of methods to do so across studies; and commercial material evaluators seldom reported on issues of implementation fidelity.
Identification of a Set of Outcome Measures and Forms of Disaggregation
Using the selected student outcomes identified in the program theory, one must conduct an impact assessment that refers to the design and measurement of student outcomes. In addition to selecting what outcomes should be measured within one’s program theory, one must determine how these outcomes are measured, when those measures are collected, and what
purpose they serve from the perspective of the participants. In the case of curricular evaluation, there are significant issues involved in how these measures are reported. To provide insight into the level of curricular validity, many evaluators prefer to report results by topic, content strand, or item cluster. These reports often present the level of specificity of outcome needed to inform curriculum designers, especially when efforts are made to document patterns of errors, distribution of results across multiple choices, or analyses of student methods. In these cases, whole test scores may mask essential differences in impact among curricula at the level of content topics, reporting only average performance.
On the other hand, many large-scale assessments depend on methods of test equating that rely on whole test scores and make comparative interpretations of different test administrations by content strands of questionable reliability. Furthermore, there are questions such as whether to present only gain scores effect sizes, how to link pretests and posttests, and how to determine the relative curricular sensitivity of various outcome measures.
The findings of comparative studies are reported in terms of the outcome measure(s) collected. To describe the nature of the database with regard to outcome measures and to facilitate our analyses of the studies, we classified each of the included studies on four outcome measure dimensions:
Total score reported;
Disaggregation of content strands, subtest, performance level, SES, or gender;
Outcome measure that was specific to curriculum; and
Use of multiple outcome measures.
Most studies reported a total score, but we did find studies that reported only subtest scores or only scores on an item-by-item basis. For example, in the Ben-Chaim et al. (1998) evaluation study of Connected Math, the authors were interested in students’ proportional reasoning proficiency as a result of use of this curriculum. They asked students from eight seventh-grade classes of CMP and six seventh-grade classes from the control group to solve a variety of tasks categorized as rate and density problems. The authors provide precise descriptions of the cognitive challenges in the items; however, they do not explain if the problems written up were representative of performance on a larger set of items. A special rating form was developed to code responses in three major categories (correct answer, incorrect answer, and no response), with subcategories indicating the quality of the work that accompanied the response. No reports on reliability of coding were given. Performance on standardized tests indicated that control students’ scores were slightly higher than CMP at the beginning of the
year and lower at the end. Twenty-five percent of the experimental group members were interviewed about their approaches to the problems. The CMP students outperformed the control students (53 percent versus 28 percent) overall in providing the correct answers and support work, and 27 percent of the control group gave an incorrect answer or showed incorrect thinking compared to 13 percent of the CMP group. An item-level analysis permitted the researchers to evaluate the actual strategies used by the students. They reported, for example, that 82 percent of CMP students used a “strategy focused on package price, unit price, or a combination of the two; those effective strategies were used by only 56 of 91 control students (62 percent)” (p. 264).
The use of item or content strand-level comparative reports had the advantage that they permitted the evaluators to assess student learning strategies specific to a curriculum’s program theory. For example, at times, evaluators wanted to gauge the effectiveness of using problems different from those on typical standardized tests. In this case, problems were drawn from familiar circumstances but carefully designed to create significant cognitive challenges, and assess how well the informal strategies approach in CMP works in comparison to traditional instruction. The disadvantages of such an approach include the use of only a small number of items and the concerns for reliability in scoring. These studies seem to represent a method of creating hybrid research models that build on the detailed analyses possible using case studies, but still reporting on samples that provide comparative data. It possibly reflects the concerns of some mathematicians and mathematics educators that the effectiveness of materials needs to be evaluated relative to very specific, research-based issues on learning and that these are often inadequately measured by multiple-choice tests. However, a decision not to report total scores led to a trade-off in the reliability and representativeness of the reported data, which must be addressed to increase the objectivity of the reports.
Second, we coded whether outcome data were disaggregated in some way. Disaggregation involved reporting data on dimensions such as content strand, subtest, test item, ethnic group, performance level, SES, and gender. We found disaggregated results particularly helpful in understanding the findings of studies that found main effects, and also in examining patterns across studies. We report the results of the studies’ disaggregation by content strand in our reports of effects. We report the results of the studies’ disaggregation by subgroup in our discussions of generalizability.
Third, we coded whether a study used an outcome measure that the evaluator reported as being sensitive to a particular treatment—this is a subcategory of what was defined in our framework as “curricular validity of measures.” In such studies, the rationale was that readily available measures such as state-mandated tests, norm-referenced standardized tests, and
college entrance examinations do not measure some of the aims of the program under study. A frequently cited instance of this was that “off the shelf” instruments do not measure well students’ ability to apply their mathematical knowledge to problems embedded in complex settings. Thus, some studies constructed a collection of tasks that assessed this ability and collected data on it (Ben-Chaim et al., 1998; Huntley et al., 2000).
Finally, we recorded whether a study used multiple outcome measures. Some studies used a variety of achievement measures and other studies reported on achievement accompanied by measures such as subsequent course taking or various types of affective measures. For example, Carroll (2001, p. 47) reported results on a norm-referenced standardized achievement test as well as a collection of tasks developed in other studies.
A study by Huntley et al. (2000) illustrates how a variety of these techniques were combined in their outcome measures. They developed three assessments. The first emphasized contextualized problem solving based on items from the American Mathematical Association of Two-Year Colleges and others; the second assessment was on context-free symbolic manipulation and a third part requiring collaborative problem solving. To link these measures to the overall evaluation, they articulated an explicit model of cognition based on how one links an applied situation to mathematical activity through processes of formulation and interpretation. Their assessment strategy permitted them to investigate algebraic reasoning as an ability to use algebraic ideas and techniques to (1) mathematize quantitative problem situations, (2) use algebraic principles and procedures to solve equations, and (3) interpret results of reasoning and calculations.
In presenting their data comparing performance on Core-Plus and traditional curriculum, they presented both main effects and comparisons on subscales. Their design of outcome measures permitted them to examine differences in performance with and without context and to conclude with statements such as “This result illustrates that CPMP students perform better than control students when setting up models and solving algebraic problems presented in meaningful contexts while having access to calculators, but CPMP students do not perform as well on formal symbol-manipulation tasks without access to context cues or calculators” (p. 349). The authors go on to present data on the relationship between knowing how to plan or interpret solutions and knowing how to carry them out. The correlations between these variables were weak but significantly different (0.26 for control groups and 0.35 for Core-Plus). The advantage of using multiple measures carefully tied to program theory is that they can permit one to test fine content distinctions that are likely to be the level of adjustments necessary to fine tune and improve curricular programs.
Another interesting approach to the use of outcome measures is found in the UCSMP studies. In many of these studies, evaluators collected infor-
TABLE 5-2 Mean Percentage Correct on the Subject Tests
mation from teachers’ reports and chapter reviews as to whether topics for items on the posttests were taught, calling this an “opportunity to learn” measure. The authors reported results from three types of analyses: (1) total test scores, (2) fair test scores (scores reported by program but only on items on topics taught), and (3) conservative test scores (scores on common items taught in both). Table 5-2 reports on the variations across the multiple- choice test scores for the Geometry study (Thompson et al., 2003) on a standardized test, High School Subject Tests-Geometry Form B , and the UCSMP-constructed Geometry test, and for the Advanced Algebra Study on the UCSMP-constructed Advanced Algebra test (Thompson et al., 2001). The table shows the mean scores for UCSMP classes and comparison classes. In each cell, mean percentage correct is reported first by whole test, then by fair test, and then by conservative test.
The authors explicitly compare the items from the standard Geometry test with the items from the UCSMP test and indicate overlap and difference. They constructed their own test because, in their view, the standard test was not adequately balanced among skills, properties, and real-world uses. The UCSMP test included items on transformations, representations, and applications that were lacking in the national test. Only five items were taught by all teachers; hence in the case of the UCSMP geometry test, there is no report on a conservative test. In the Advanced Algebra evaluation, only a UCSMP-constructed test was viewed as appropriate to cover the treatment of the prior material and alignment to the goals of the new course. These data sets demonstrate the challenge of selecting appropriate outcome measures, the sensitivity of the results to those decisions, and the importance of full disclosure of decision-making processes in order to permit readers to assess the implications of the choices. The methodology utilized sought to ensure that the material in the course was covered adequately by treatment teachers while finding ways to make comparisons that reflected content coverage.
Only one study reported on its outcomes using embedded assessment items employed over the course of the year. In a study of Saxon and UCSMP, Peters (1992) (EX) studied the use of these materials with two classrooms taught by the same teacher. In this small study, he randomly assigned students to treatment groups and then measured their performance on four unit tests composed of items common to both curricula and their progress on the Orleans-Hanna Algebraic Prognosis Test.
Peters’ study showed no significant difference in placement scores between Saxon and UCSMP on the posttest, but did show differences on the embedded assessment. Figure 5-6 (Peters, 1992, p. 75) shows an interesting display of the differences on a “continuum” that shows both the direction and magnitude of the differences and provides a level of concept specificity missing in many reports. This figure and a display ( Figure 5-7 ) in a study by Senk (1991, p. 18) of students’ mean scores on Curriculum A versus Curriculum B with a 10 percent range of differences marked represent two excellent means to communicate the kinds of detailed content outcome information that promises to be informative to curriculum writers, publishers, and school decision makers. In Figure 5-7 , 16 items listed by number were taken from the Second International Mathematics Study. The Functions, Statistics, and Trigonometry sample averaged 41 percent correct on these items whereas the U.S. precalculus sample averaged 38 percent. As shown in the figure, differences of 10 percent or less fall inside the banded area and greater than 10 percent fall outside, producing a display that makes it easy for readers and designers to identify the relative curricular strengths and weaknesses of topics.
While we value detailed outcome measure information, we also recognize the importance of examining curricular impact on students’ standardized test performance. Many developers, but not all, are explicit in rejecting standardized tests as adequate measures of the outcomes of their programs, claiming that these tests focus on skills and manipulations, that they are overly reliant on multiple-choice questions, and that they are often poorly aligned to new content emphases such as probability and statistics, transformations, use of contextual problems and functions, and process skills, such as problem solving, representation, or use of calculators. However, national and state tests are being revised to include more content on these topics and to draw on more advanced reasoning. Furthermore, these high-stakes tests are of major importance in school systems, determining graduation, passing standards, school ratings, and so forth. For this reason, if a curricular program demonstrated positive impact on such measures, we referred to that in Chapter 3 as establishing “curricular alignment with systemic factors.” Adequate performance on these measures is of paramount importance to the survival of reform (to large groups of parents and

FIGURE 5-6 Continuum of criterion score averages for studied programs.
SOURCE: Peters (1992, p. 75).
school administrators). These examples demonstrate how careful attention to outcomes measures is an essential element of valid evaluation.
In Table 5-3 , we document the number of studies using a variety of types of outcome measures that we used to code the data, and also report on the types of tests used across the studies.
FIGURE 5-7 Achievement (percentage correct) on Second International Mathematics Study (SIMS) items by U.S. precalculus students and functions, statistics, and trigonometry (FST) students.
SOURCE: Re-created from Senk (1991, p. 18).
TABLE 5-3 Number of Studies Using a Variety of Outcome Measures by Program Type
A Choice of Statistical Tests, Including Statistical Significance and Effect Size
In our first review of the studies, we coded what methods of statistical evaluation were used by different evaluators. Most common were t-tests; less frequently one found Analysis of Variance (ANOVA), Analysis of Co-
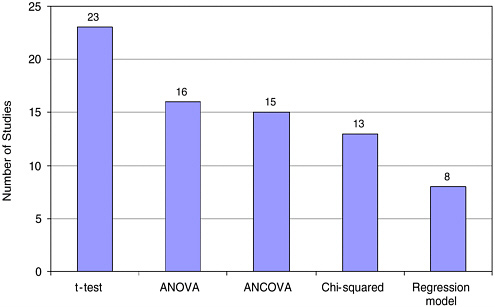
FIGURE 5-8 Statistical tests most frequently used.
variance (ANCOVA), and chi-square tests. In a few cases, results were reported using multiple regression or hierarchical linear modeling. Some used multiple tests; hence the total exceeds 63 ( Figure 5-8 ).
One of the difficult aspects of doing curriculum evaluations concerns using the appropriate unit both in terms of the unit to be randomly assigned in an experimental study and the unit to be used in statistical analysis in either an experimental or quasi-experimental study.
For our purposes, we made the decision that unless the study concerned an intact student population such as the freshman at a single university, where a student comparison was the correct unit, we believed that for statistical tests, the unit should be at least at the classroom level. Judgments were made for each study as to whether the appropriate unit was utilized. This question is an important one because statistical significance is related to sample size, and as a result, studies that inappropriately use the student as the unit of analysis could be concluding significant differences where they are not present. For example, if achievement differences between two curricula are tested in 16 classrooms with 400 students, it will always be easier to show significant differences using scores from those 400 students than using 16 classroom means.
Fifty-seven studies used students as the unit of analysis in at least one test of significance. Three of these were coded as correct because they involved whole populations. In all, 10 studies were coded as using the
TABLE 5-4 Performance on Applied Algebra Problems with Use of Calculators, Part 1
TABLE 5-5 Reanalysis of Algebra Performance Data
correct unit of analysis; hence, 7 studies used teachers or classes, or schools. For some studies where multiple tests were conducted, a judgment was made as to whether the primary conclusions drawn treated the unit of analysis adequately. For example, Huntley et al. (2000) compared the performance of CPMP students with students in a traditional course on a measure of ability to formulate and use algebraic models to answer various questions about relationships among variables. The analysis used students as the unit of analysis and showed a significant difference, as shown in Table 5-4 .
To examine the robustness of this result, we reanalyzed the data using an independent sample t-test and a matched pairs t-test with class means as the unit of analysis in both tests ( Table 5-5 ). As can be seen from the analyses, in neither statistical test was the difference between groups found to be significantly different (p < .05), thus emphasizing the importance of using the correct unit in analyzing the data.
Reanalysis of student-level data using class means will not always result
TABLE 5-6 Mean Percentage Correct on Entire Multiple-Choice Posttest: Second Edition and Non-UCSMP
in a change in finding. Furthermore, using class means as the unit of analysis does not suggest that significant differences will not be found. For example, a study by Thompson et al. (2001) compared the performance of UCSMP students with the performance of students in a more traditional program across several measures of achievement. They found significant differences between UCSMP students and the non-UCSMP students on several measures. Table 5-6 shows results of an analysis of a multiple-choice algebraic posttest using class means as the unit of analysis. Significant differences were found in five of eight separate classroom comparisons, as shown in the table. They also found a significant difference using a matched-pairs t-test on class means.
The lesson to be learned from these reanalyses is that the choice of unit of analysis and the way the data are aggregated can impact study findings in important ways including the extent to which these findings can be generalized. Thus it is imperative that evaluators pay close attention to such considerations as the unit of analysis and the way data are aggregated in the design, implementation, and analysis of their studies.
Second, effect size has become a relatively common and standard way of gauging the practical significance of the findings. Statistical significance only indicates whether the main-level differences between two curricula are large enough to not be due to chance, assuming they come from the same population. When statistical differences are found, the question remains as to whether such differences are large enough to consider. Because any innovation has its costs, the question becomes one of cost-effectiveness: Are the differences in student achievement large enough to warrant the costs of change? Quantifying the practical effect once statistical significance is established is one way to address this issue. There is a statistical literature for doing this, and for the purposes of this review, the committee simply noted whether these studies have estimated such an effect. However, the committee further noted that in conducting meta-analyses across these studies, effect size was likely to be of little value. These studies used an enormous variety of outcome measures, and even using effect size as a means to standardize units across studies is not sensible when the measures in each
study address such a variety of topics, forms of reasoning, content levels, and assessment strategies.
We note very few studies drew upon the advances in methodologies employed in modeling, which include causal modeling, hierarchical linear modeling (Bryk and Raudenbush, 1992; Bryk et al., 1993), and selection bias modeling (Heckman and Hotz, 1989). Although developing detailed specifications for these approaches is beyond the scope of this review, we wish to emphasize that these methodological advances should be considered within future evaluation designs.
Results and Limitations to Generalizability Resulting from Design Constraints
One also must consider what generalizations can be drawn from the results (Campbell and Stanley, 1966; Caporaso and Roos, 1973; and Boruch, 1997). Generalization is a matter of external validity in that it determines to what populations the study results are likely to apply. In designing an evaluation study, one must carefully consider, in the selection of units of analysis, how various characteristics of those units will affect the generalizability of the study. It is common for evaluators to conflate issues of representativeness for the purpose of generalizability (external validity) and comparativeness (the selection of or adjustment for comparative groups [internal validity]). Not all studies must be representative of the population served by mathematics curricula to be internally valid. But, to be generalizable beyond restricted communities, representativeness must be obtained by the random selection of the basic units. Clearly specifying such limitations to generalizability is critical. Furthermore, on the basis of equity considerations, one must be sure that if overall effectiveness is claimed, that the studies have been conducted and analyzed with reference of all relevant subgroups.
Thus, depending on the design of a study, its results may be limited in generalizability to other populations and circumstances. We identified four typical kinds of limitations on the generalizability of studies and coded them to determine, on the whole, how generalizable the results across studies might be.
First, there were studies whose designs were limited by the ability or performance level of the students in the samples. It was not unusual to find that when new curricula were implemented at the secondary level, schools kept in place systems of tracking that assigned the top students to traditional college-bound curriculum sequences. As a result, studies either used comparative groups who were matched demographically but less skilled than the population as a whole, in relation to prior learning, or their results compared samples of less well-prepared students to samples of students
with stronger preparations. Alternatively, some studies reported on the effects of curricula reform on gifted and talented students or on college-attending students. In these cases, the study results would also limit the generalizability of the results to similar populations. Reports using limited samples of students’ ability and prior performance levels were coded as a limitation to the generalizability of the study.
For example, Wasman (2000) conducted a study of one school (six teachers) and examined the students’ development of algebraic reasoning after one (n=100) and two years (n=73) in CMP. In this school, the top 25 percent of the students are counseled to take a more traditional algebra course, so her experimental sample, which was 61 percent white, 35 percent African American, 3 percent Asian, and 1 percent Hispanic, consisted of the lower 75 percent of the students. She reported on the student performance on the Iowa Algebraic Aptitude Test (IAAT) (1992), in the subcategories of interpreting information, translating symbols, finding relationships, and using symbols. Results for Forms 1 and 2 of the test, for the experimental and norm group, are shown in Table 5-7 for 8th graders.
In our coding of outcomes, this study was coded as showing no significant differences, although arguably its results demonstrate a positive set of
TABLE 5-7 Comparing Iowa Algebraic Aptitude Test (IAAT) Mean Scores of the Connected Mathematics Project Forms 1 and 2 to the Normative Group (8th Graders)
outcomes as the treatment group was weaker than the control group. Had the researcher used a prior achievement measure and a different statistical technique, significance might have been demonstrated, although potential teacher effects confound interpretations of results.
A second limitation to generalizability was when comparative studies resided entirely at curriculum pilot site locations, where such sites were developed as a means to conduct formative evaluations of the materials with close contact and advice from teachers. Typically, pilot sites have unusual levels of teacher support, whether it is in the form of daily technical support in the use of materials or technology or increased quantities of professional development. These sites are often selected for study because they have established cooperative agreements with the program developers and other sources of data, such as classroom observations, are already available. We coded whether the study was conducted at a pilot site to signal potential limitations in generalizability of the findings.
Third, studies were also coded as being of limited generalizability if they failed to disaggregate their data by socioeconomic class, race, gender, or some other potentially significant sources of restriction on the claims. We recorded the categories in which disaggregation occurred and compiled their frequency across the studies. Because of the need to open the pipeline to advanced study in mathematics by members of underrepresented groups, we were particularly concerned about gauging the extent to which evaluators factored such variables into their analysis of results and not just in terms of the selection of the sample.
Of the 46 included studies of NSF-supported curricula, 19 disaggregated their data by student subgroup. Nine of 17 studies of commercial materials disaggregated their data. Figure 5-9 shows the number of studies that disaggregated outcomes by race or ethnicity, SES, gender, LEP, special education status, or prior achievement. Studies using multiple categories of disaggregation were counted multiple times by program category.
The last category of restricted generalization occurred in studies of limited sample size. Although such studies may have provided more indepth observations of implementation and reports on professional development factors, the smaller numbers of classrooms and students in the study would limit the extent of generalization that could be drawn from it. Figure 5-10 shows the distribution of sizes of the samples in terms of numbers of students by study type.
Summary of Results by Student Achievement Among Program Types
We present the results of the studies as a means to further investigate their methodological implications. To this end, for each study, we counted across outcome measures the number of findings that were positive, nega-
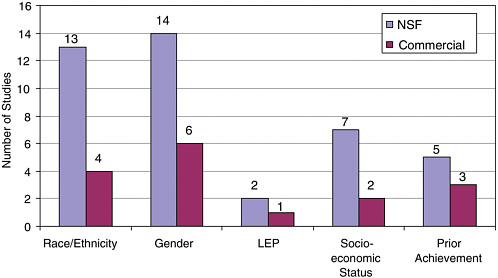
FIGURE 5-9 Disaggregation of subpopulations.
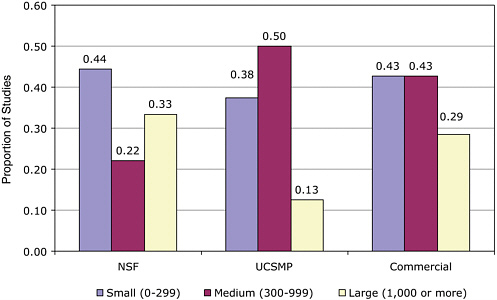
FIGURE 5-10 Proportion of studies by sample size and program.
tive, or indeterminate (no significant difference) and then calculated the proportion of each. We represented the calculation of each study as a triplet (a, b, c) where a indicates the proportion of the results that were positive and statistically significantly stronger than the comparison program, b indicates the proportion that were negative and statistically significantly weaker than the comparison program, and c indicates the proportion that showed no significant difference between the treatment and the comparative group. For studies with a single outcome measure, without disaggregation by content strand, the triplet is always composed of two zeros and a single one. For studies with multiple measures or disaggregation by content strand, the triplet is typically a set of three decimal values that sum to one. For example, a study with one outcome measure in favor of the experimental treatment would be coded (1, 0, 0), while one with multiple measures and mixed results more strongly in favor of the comparative curriculum might be listed as (.20, .50, .30). This triplet would mean that for 20 percent of the comparisons examined, the evaluators reported statistically significant positive results, for 50 percent of the comparisons the results were statistically significant in favor of the comparison group, and for 30 percent of the comparisons no significant difference were found. Overall, the mean score on these distributions was (.54, .07, .40), indicating that across all the studies, 54 percent of the comparisons favored the treatment, 7 percent favored the comparison group, and 40 percent showed no significant difference. Table 5-8 shows the comparison by curricular program types. We present the results by individual program types, because each program type relies on a similar program theory and hence could lead to patterns of results that would be lost in combining the data. If the studies of commercial materials are all grouped together to include UCSMP, their pattern of results is (.38, .11, .51). Again we emphasize that due to our call for increased methodological rigor and the use of multiple methods, this result is not sufficient to establish the curricular effectiveness of these programs as a whole with adequate certainty.
We caution readers that these results are summaries of the results presented across a set of evaluations that meet only the standard of at least
TABLE 5-8 Comparison by Curricular Program Types
minimally methodologically adequate . Calculations of statistical significance of each program’s results were reported by the evaluators; we have made no adjustments for weaknesses in the evaluations such as inappropriate use of units of analysis in calculating statistical significance. Evaluations that consistently used the correct unit of analysis, such as UCSMP, could have fewer reports of significant results as a consequence. Furthermore, these results are not weighted by study size. Within any study, the results pay no attention to comparative effect size or to the established credibility of an outcome measure. Similarly, these results do not take into account differences in the populations sampled, an important consideration in generalizing the results. For example, using the same set of studies as an example, UCSMP studies used volunteer samples who responded to advertisements in their newsletters, resulting in samples with disproportionately Caucasian subjects from wealthier schools compared to national samples. As a result, we would suggest that these results are useful only as baseline data for future evaluation efforts. Our purpose in calculating these results is to permit us to create filters from the critical decision points and test how the results change as one applies more rigorous standards.
Given that none of the studies adequately addressed all of the critical criteria, we do not offer these results as definitive, only suggestive—a hypothesis for further study. In effect, given the limitations of time and support, and the urgency of providing advice related to policy, we offer this filtering approach as an informal meta-analytic technique sufficient to permit us to address our primary task, namely, evaluating the quality of the evaluation studies.
This approach reflects the committee’s view that to deeply understand and improve methodology, it is necessary to scrutinize the results and to determine what inferences they provide about the conduct of future evaluations. Analogous to debates on consequential validity in testing, we argue that to strengthen methodology, one must consider what current methodologies are able (or not able) to produce across an entire series of studies. The remainder of the chapter is focused on considering in detail what claims are made by these studies, and how robust those claims are when subjected to challenge by alternative hypothesis, filtering by tests of increasing rigor, and examining results and patterns across the studies.
Alternative Hypotheses on Effectiveness
In the spirit of scientific rigor, the committee sought to consider rival hypotheses that could explain the data. Given the weaknesses in the designs generally, often these alternative hypotheses cannot be dismissed. However, we believed that only after examining the configuration of results and
alternative hypotheses can the next generation of evaluations be better informed and better designed. We began by generating alternative hypotheses to explain the positive directionality of the results in favor of experimental groups. Alternative hypotheses included the following:
The teachers in the experimental groups tended to be self-selecting early adopters, and thus able to achieve effects not likely in regular populations.
Changes in student outcomes reflect the effects of professional development instruction, or level of classroom support (in pilot sites), and thus inflate the predictions of effectiveness of curricular programs.
Hawthorne effect (Franke and Kaul, 1978) occurs when treatments are compared to everyday practices, due to motivational factors that influence experimental participants.
The consistent difference is due to the coherence and consistency of a single curricular program when compared to multiple programs.
The significance level is only achieved by the use of the wrong unit of analysis to test for significance.
Supplemental materials or new teaching techniques produce the results and not the experimental curricula.
Significant results reflect inadequate outcome measures that focus on a restricted set of activities.
The results are due to evaluator bias because too few evaluators are independent of the program developers.
At the same time, one could argue that the results actually underestimate the performance of these materials and are conservative measures, and their alternative hypotheses also deserve consideration:
Many standardized tests are not sensitive to these curricular approaches, and by eliminating studies focusing on affect, we eliminated a key indicator of the appeal of these curricula to students.
Poor implementation or increased demands on teachers’ knowledge dampens the effects.
Often in the experimental treatment, top-performing students are missing as they are advised to take traditional sequences, rendering the samples unequal.
Materials are not well aligned with universities and colleges because tests for placement and success in early courses focus extensively on algebraic manipulation.
Program implementation has been undercut by negative publicity and the fears of parents concerning change.
There are also a number of possible hypotheses that may be affecting the results in either direction, and we list a few of these:
Examining the role of the teacher in curricular decision making is an important element in effective implementation, and design mandates of evaluation design make this impossible (and the positives and negatives or single- versus dual-track curriculum as in Lundin, 2001).
Local tests that are sensitive to the curricular effects typically are not mandatory and hence may lead to unpredictable performance by students.
Different types and extent of professional development may affect outcomes differentially.
Persistence or attrition may affect the mean scores and are often not considered in the comparative analyses.
One could also generate reasons why the curricular programs produced results showing no significance when one program or the other is actually more effective. This could include high degrees of variability in the results, samples that used the correct unit of analysis but did not obtain consistent participation across enough cases, implementation that did not show enough fidelity to the measures, or outcome measures insensitive to the results. Again, subsequent designs should be better informed by these findings to improve the likelihood that they will produce less ambiguous results and replication of studies could also give more confidence in the findings.
It is beyond the scope of this report to consider each of these alternative hypotheses separately and to seek confirmation or refutation of them. However, in the next section, we describe a set of analyses carried out by the committee that permits us to examine and consider the impact of various critical evaluation design decisions on the patterns of outcomes across sets of studies. A number of analyses shed some light on various alternative hypotheses and may inform the conduct of future evaluations.
Filtering Studies by Critical Decision Points to Increase Rigor
In examining the comparative studies, we identified seven critical decision points that we believed would directly affect the rigor and efficacy of the study design. These decision points were used to create a set of 16 filters. These are listed as the following questions:
Was there a report on comparability relative to SES?
Was there a report on comparability of samples relative to prior knowledge?
Was there a report on treatment fidelity?
Was professional development reported on?
Was the comparative curriculum specified?
Was there any attempt to report on teacher effects?
Was a total test score reported?
Was total test score(s) disaggregated by content strand?
Did the outcome measures match the curriculum?
Were multiple tests used?
Was the appropriate unit of analysis used in their statistical tests?
Did they estimate effect size for the study?
Was the generalizability of their findings limited by use of a restricted range of ability levels?
Was the generalizability of their findings limited by use of pilot sites for their study?
Was the generalizability of their findings limited by not disaggregating their results by subgroup?
Was the generalizability of their findings limited by use of small sample size?
The studies were coded to indicate if they reported having addressed these considerations. In some cases, the decision points were coded dichotomously as present or absent in the studies, and in other cases, the decision points were coded trichotomously, as description presented, absent, or statistically adjusted for in the results. For example, a study may or may not report on the comparability of the samples in terms of race, ethnicity, or socioeconomic status. If a report on SES was given, the study was coded as “present” on this decision; if a report was missing, it was coded as “absent”; and if SES status or ethnicity was used in the analysis to actually adjust outcomes, it was coded as “adjusted for.” For each coding, the table that follows reports the number of studies that met that condition, and then reports on the mean percentage of statistically significant results, and results showing no significant difference for that set of studies. A significance test is run to see if the application of the filter produces changes in the probability that are significantly different. 5
In the cases in which studies are coded into three distinct categories—present, absent, and adjusted for—a second set of filters is applied. First, the studies coded as present or adjusted for are combined and compared to those coded as absent; this is what we refer to as a weak test of the rigor of the study. Second, the studies coded as present or absent are combined and compared to those coded as adjusted for. This is what we refer to as a strong test. For dichotomous codings, there can be as few as three compari-
sons, and for trichotomous codings, there can be nine comparisons with accompanying tests of significance. Trichotomous codes were used for adjustments for SES and prior knowledge, examining treatment fidelity, professional development, teacher effects, and reports on effect sizes. All others were dichotomous.
NSF Studies and the Filters
For example, there were 11 studies of NSF-supported curricula that simply reported on the issues of SES in creating equivalent samples for comparison, and for this subset the mean probabilities of getting positive, negative, or results showing no significant difference were (.47, .10, .43). If no report of SES was supplied (n= 21), those probabilities become (.57, .07, .37), indicating an increase in positive results and a decrease in results showing no significant difference. When an adjustment is made in outcomes based on differences in SES (n=14), the probabilities change to (.72, .00, .28), showing a higher likelihood of positive outcomes. The probabilities that result from filtering should always be compared back to the overall results of (.59, .06, .35) (see Table 5-8 ) so as to permit one to judge the effects of more rigorous methodological constraints. This suggests that a simple report on SES without adjustment is least likely to produce positive outcomes; that is, no report produces the outcomes next most likely to be positive and studies that adjusted for SES tend to have a higher proportion of their comparisons producing positive results.
The second method of applying the filter (the weak test for rigor) for the treatment of the adjustment of SES groups compares the probabilities when a report is either given or adjusted for compared to when no report is offered. The combined percentage of a positive outcome of a study in which SES is reported or adjusted for is (.61, .05, .34), while the percentage for no report remains as reported previously at (.57, .07, .37). A final filter compares the probabilities of the studies in which SES is adjusted for with those that either report it only or do not report it at all. Here we compare the percentage of (.72, .00, .28) to (.53, .08, .37) in what we call a strong test. In each case we compared the probability produced by the whole group to those of the filtered studies and conducted a test of the differences to determine if they were significant. These differences were not significant. These findings indicate that to date, with this set of studies, there is no statistically significant difference in results when one reports or adjusts for changes in SES. It appears that by adjusting for SES, one sees increases in the positive results, and this result deserves a closer examination for its implications should it prove to hold up over larger sets of studies.
We ran tests that report the impact of the filters on the number of studies, the percentage of studies, and the effects described as probabilities
for each of the three study categories, NSF-supported and commercially generated with UCSMP included. We claim that when a pattern of probabilities of results does not change after filtering, one can have more confidence in that pattern. When the pattern of results changes, there is a need for an explanatory hypothesis, and that hypothesis can shed light on experimental design. We propose that this “filtering process” constitutes a test of the robustness of the outcome measures subjected to increasing degrees of rigor by using filtering.
Results of Filtering on Evaluations of NSF-Supported Curricula
For the NSF-supported curricular programs, out of 15 filters, 5 produced a probability that differed significantly at the p<.1 level. The five filters were for treatment fidelity, specification of control group, choosing the appropriate statistical unit, generalizability for ability, and generalizability based on disaggregation by subgroup. For each filter, there were from three to nine comparisons, as we examined how the probabilities of outcomes change as tests were more stringent and across the categories of positive results, negative results, and results with no significant differences. Out of a total of 72 possible tests, only 11 produced a probability that differed significantly at the p < .1 level. With 85 percent of the comparisons showing no significant difference after filtering, we suggest the results of the studies were relatively robust in relation to these tests. At the same time, when rigor is increased for the five filters just listed, the results become generally more ambiguous and signal the need for further research with more careful designs.
Studies of Commercial Materials and the Filters
To ensure enough studies to conduct the analysis (n=17), our filtering analysis of the commercially generated studies included UCSMP (n=8). In this case, there were six filters that produced a probability that differed significantly at the p < .1 level. These were treatment fidelity, disaggregation by content, use of multiple tests, use of effect size, generalizability by ability, and generalizability by sample size. In this case, because there were no studies in some possible categories, there were a total of 57 comparisons, and 9 displayed significant differences in the probabilities after filtering at the p < .1 level. With 84 percent of the comparisons showing no significant difference after filtering, we suggest the results of the studies were relatively robust in relation to these tests. Table 5-9 shows the cases in which significant differences were recorded.
Impact of Treatment Fidelity on Probabilities
A few of these differences are worthy of comment. In the cases of both the NSF-supported and commercially generated curricula evaluation studies, studies that reported treatment fidelity differed significantly from those that did not. In the case of the studies of NSF-supported curricula, it appeared that a report or adjustment on treatment fidelity led to proportions with less positive effects and more results showing no significant differences. We hypothesize that this is partly because larger studies often do not examine actual classroom practices, but can obtain significance more easily due to large sample sizes.
In the studies of commercial materials, the presence or absence of measures of treatment fidelity worked differently. Studies reporting on or adjusting for treatment fidelity tended to have significantly higher probabilities in favor of experimental treatment, less positive effects in fewer of the comparative treatments, and more likelihood of results with no significant differences. We hypothesize, and confirm with a separate analysis, that this is because UCSMP frequently reported on treatment fidelity in their designs while study of Saxon typically did not, and the change represents the preponderance of these different curricular treatments in the studies of commercially generated materials.
Impact of Identification of Curricular Program on Probabilities
The significant differences reported under specificity of curricular comparison also merit discussion for studies of NSF-supported curricula. When the comparison group is not specified, a higher percentage of mean scores in favor of the experimental curricula is reported. In the studies of commercial materials, a failure to name specific curricular comparisons also produced a higher percentage of positive outcomes for the treatment, but the difference was not statistically significant. This suggests the possibility that when a specified curriculum is compared to an unspecified curriculum, reports of impact may be inflated. This finding may suggest that in studies of effectiveness, specifying comparative treatments would provide more rigorous tests of experimental approaches.
When studies of commercial materials disaggregate their results of content strands or use multiple measures, their reports of positive outcomes increase, the negative outcomes decrease, and in one case, the results show no significant differences. Percentage of significant difference was only recorded in one comparison within each one of these filters.
TABLE 5-9 Cases of Significant Differences
Impact of Units of Analysis on Probabilities 6
For the evaluations of the NSF-supported materials, a significant difference was reported on the outcomes for the studies that used the correct unit of analysis compared to those that did not. The percentage for those with the correct unit were (.30, .40, .30) compared to (.63, .01, .36) for those that used the incorrect result. These results suggest that our prediction that using the correct unit of analysis would decrease the percentage of positive outcomes is likely to be correct. It also suggests that the most serious threat to the apparent conclusions of these studies comes from selecting an incorrect unit of analysis. It causes a decrease in favorable results, making the results more ambiguous, but never reverses the direction of the effect. This is a concern that merits major attention in the conduct of further studies.
For the commercially generated studies, most of the ones coded with the correct unit of analysis were UCSMP studies. Because of the small number of studies involved, we could not break out from the overall filtering of studies of commercial materials, but report this issue to assist readers in interpreting the relative patterns of results.
Impact of Generalizability on Probabilities
Both types of studies yielded significant differences for some of the comparisons coded as restrictions to generalizability. Investigating these is important in order to understand the effects of these curricular programs on different subpopulations of students. In the case of the studies of commercially generated materials, significantly different results occurred in the categories of ability and sample size. In the studies of NSF-supported materials, the significant differences occurred in ability and disaggregation by subgroups.
In relation to generalizability, the studies of NSF-supported curricula reported significantly more positive results in favor of the treatment when they included all students. Because studies coded as “limited by ability” were restricted either by focusing only on higher achieving students or on lower achieving students, we sorted these two groups. For higher performing students (n=3), the probabilities of effects were (.11, .67, .22). For lower
performing students (n=2), the probabilities were (.39, .025, .59). The first two comparisons are significantly different at p < .05. These findings are based on only a total of five studies, but they suggest that these programs may be serving the weaker ability students more effectively than the stronger ability students, serving both less well than they serve whole heterogeneous groups. For the studies of commercial materials, there were only three studies that were restricted to limited populations. The results for those three studies were (.23, .41, .32) and for all students (n=14) were (.42, .53, .09). These studies were significantly different at p = .004. All three studies included UCSMP and one also included Saxon and was limited by serving primarily high-performing students. This means both categories of programs are showing weaker results when used with high-ability students.
Finally, the studies on NSF-supported materials were disaggregated by subgroups for 28 studies. A complete analysis of this set follows, but the studies that did not report results disaggregated by subgroup generated probabilities of results of (.48, .09, .43) whereas those that did disaggregate their results reported (.76, 0, .24). These gains in positive effects came from significant losses in reporting no significant differences. Studies of commercial materials also reported a small decrease in likelihood of negative effects for the comparison program when disaggregation by subgroup is reported offset by increases in positive results and results with no significant differences, although these comparisons were not significantly different. A further analysis of this topic follows.
Overall, these results suggest that increased rigor seems to lead in general to less strong outcomes, but never reports of completely contrary results. These results also suggest that in recommending design considerations to evaluators, there should be careful attention to having evaluators include measures of treatment fidelity, considering the impact on all students as well as one particular subgroup; using the correct unit of analysis; and using multiple tests that are also disaggregated by content strand.
Further Analyses
We conducted four further analyses: (1) an analysis of the outcome probabilities by test type; (2) content strands analysis; (3) equity analysis; and (4) an analysis of the interactions of content and equity by grade band. Careful attention to the issues of content strand, equity, and interaction is essential for the advancement of curricular evaluation. Content strand analysis provides the detail that is often lost by reporting overall scores; equity analysis can provide essential information on what subgroups are adequately served by the innovations, and analysis by content and grade level can shed light on the controversies that evolve over time.
Analysis by Test Type
Different studies used varied combinations of outcome measures. Because of the importance of outcome measures on test results, we chose to examine whether the probabilities for the studies changed significantly across different types of outcome measures (national test, local test). The most frequent use of tests across all studies was a combination of national and local tests (n=18 studies), a local test (n=16), and national tests (n=17). Other uses of test combinations were used by three studies or less. The percentages of various outcomes by test type in comparison to all studies are described in Table 5-10 .
These data ( Table 5-11 ) suggest that national tests tend to produce less positive results, and with the resulting gains falling into results showing no significant differences, suggesting that national tests demonstrate less curricular sensitivity and specificity.
TABLE 5-10 Percentage of Outcomes by Test Type
TABLE 5-11 Percentage of Outcomes by Test Type and Program Type
TABLE 5-12 Number of Studies That Disaggregated by Content Strand
Content Strand
Curricular effectiveness is not an all-or-nothing proposition. A curriculum may be effective in some topics and less effective in others. For this reason, it is useful for evaluators to include an analysis of curricular strands and to report on the performance of students on those strands. To examine this issue, we conducted an analysis of the studies that reported their results by content strand. Thirty-eight studies did this; the breakdown is shown in Table 5-12 by type of curricular program and grade band.
To examine the evaluations of these content strands, we began by listing all of the content strands reported across studies as well as the frequency of report by the number of studies at each grade band. These results are shown in Figure 5-11 , which is broken down by content strand, grade level, and program type.
Although there are numerous content strands, some of them were reported on infrequently. To allow the analysis to focus on the key results from these studies, we separated out the most frequently reported on strands, which we call the “major content strands.” We defined these as strands that were examined in at least 10 percent of the studies. The major content strands are marked with an asterisk in the Figure 5-11 . When we conduct analyses across curricular program types or grade levels, we use these to facilitate comparisons.
A second phase of our analysis was to examine the performance of students by content strand in the treatment group in comparison to the control groups. Our analysis was conducted across the major content strands at the level of NSF-supported versus commercially generated, initially by all studies and then by grade band. It appeared that such analysis permitted some patterns to emerge that might prove helpful to future evaluators in considering the overall effectiveness of each approach. To do this, we then coded the number of times any particular strand was measured across all studies that disaggregated by content strand. Then, we coded the proportion of times that this strand was reported as favoring the experimental treatment, favoring the comparative curricula, or showing no significant difference. These data are presented across the major content strands for the NSF-supported curricula ( Figure 5-12 ) and the commercially generated curricula, ( Figure 5-13 ) (except in the case of the elemen-
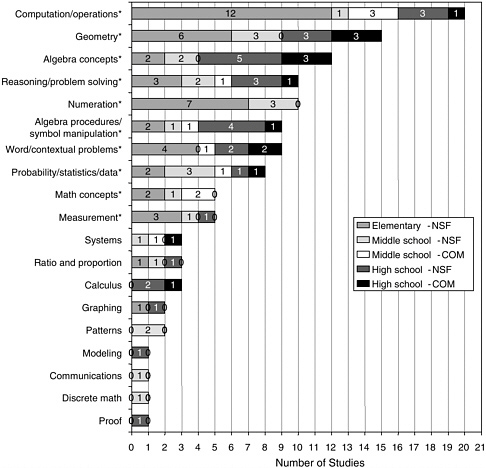
FIGURE 5-11 Study counts for all content strands.
tary curricula where no data were available) in the forms of percentages, with the frequencies listed in the bars.
The presentation of results by strands must be accompanied by the same restrictions as stated previously. These results are based on studies identified as at least minimally methodologically adequate. The quality of the outcome measures in measuring the content strands has not been examined. Their results are coded in relation to the comparison group in the study and are indicated as statistically in favor of the program, as in favor of the comparative program, or as showing no significant differences. The results are combined across studies with no weighting by study size. Their results should be viewed as a means for the identification of topics for potential future study. It is completely possible that a refinement of methodologies may affect the future patterns of results, so the results are to be viewed as tentative and suggestive.
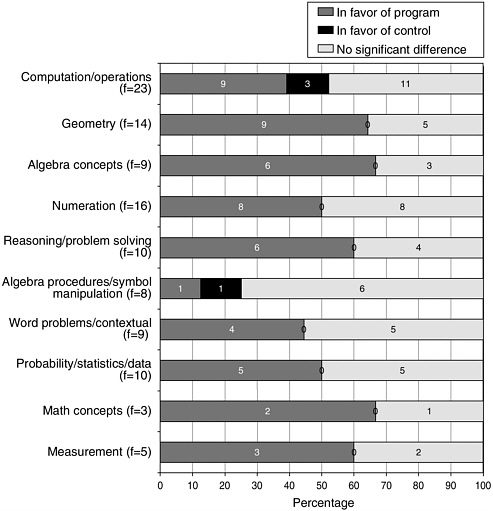
FIGURE 5-12 Major content strand result: All NSF (n=27).
According to these tentative results, future evaluations should examine whether the NSF-supported programs produce sufficient competency among students in the areas of algebraic manipulation and computation. In computation, approximately 40 percent of the results were in favor of the treatment group, no significant differences were reported in approximately 50 percent of the results, and results in favor of the comparison were revealed 10 percent of the time. Interpreting that final proportion of no significant difference is essential. Some would argue that because computation has not been emphasized, findings of no significant differences are acceptable. Others would suggest that such findings indicate weakness, because the development of the materials and accompanying professional development yielded no significant difference in key areas.
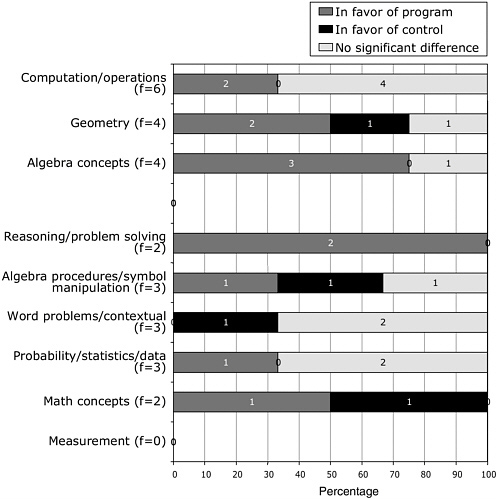
FIGURE 5-13 Major content strand result: All commercial (n=8).
From Figure 5-13 of findings from studies of commercially generated curricula, it appears that mixed results are commonly reported. Thus, in evaluations of commercial materials, lack of significant differences in computations/operations, word problems, and probability and statistics suggest that careful attention should be given to measuring these outcomes in future evaluations.
Overall, the grade band results for the NSF-supported programs—while consistent with the aggregated results—provide more detail. At the elementary level, evaluations of NSF-supported curricula (n=12) report better performance in mathematics concepts, geometry, and reasoning and problem solving, and some weaknesses in computation. No content strand analysis for commercially generated materials was possible. Evaluations
(n=6) at middle grades of NSF-supported curricula showed strength in measurement, geometry, and probability and statistics and some weaknesses in computation. In the studies of commercial materials, evaluations (n=4) reported favorable results in reasoning and problem solving and some unfavorable results in algebraic procedures, contextual problems, and mathematics concepts. Finally, at the high school level, the evaluations (n=9) by content strand for the NSF-supported curricula showed strong favorable results in algebra concepts, reasoning/problem solving, word problems, probability and statistics, and measurement. Results in favor of the control were reported in 25 percent of the algebra procedures and 33 percent of computation measures.
For the studies of commercial materials (n=4), only the geometry results favor the control group 25 percent of the time, with 50 percent having favorable results. Algebra concepts, reasoning, and probability and statistics also produced favorable results.
Equity Analysis of Comparative Studies
When the goal of providing a standards-based curriculum to all students was proposed, most people could recognize its merits: the replacement of dull, repetitive, largely dead-end courses with courses that would lead all students to be able, if desired and earned, to pursue careers in mathematics-reliant fields. It was clear that the NSF-supported projects, a stated goal of which was to provide standards-based courses to all students, called for curricula that would address the problem of too few students persisting in the study of mathematics. For example, as stated in the NSF Request for Proposals (RFP):
Rather than prematurely tracking students by curricular objectives, secondary school mathematics should provide for all students a common core of mainstream mathematics differentiated instructionally by level of abstraction and formalism, depth of treatment and pace (National Science Foundation, 1991, p. 1). In the elementary level solicitation, a similar statement on causes for all students was made (National Science Foundation, 1988, pp. 4-5).
Some, but not enough attention has been paid to the education of students who fall below the average of the class. On the other hand, because the above average students sometimes do not receive a demanding education, it may be incorrectly assumed they are easy to teach (National Science Foundation, 1989, p. 2).
Likewise, with increasing numbers of students in urban schools, and increased demographic diversity, the challenges of equity are equally significant for commercial publishers, who feel increasing pressures to demonstrate the effectiveness of their products in various contexts.
The problem was clearly identified: poorer performance by certain subgroups of students (minorities—non-Asian, LEP students, sometimes females) and a resulting lack of representation of such groups in mathematics-reliant fields. In addition, a secondary problem was acknowledged: Highly talented American students were not being provided adequate challenge and stimulation in comparison with their international counterparts. We relied on the concept of equity in examining the evaluation. Equity was contrasted to equality, where one assumed all students should be treated exactly the same (Secada et al., 1995). Equity was defined as providing opportunities and eliminating barriers so that the membership in a subgroup does not subject one to undue and systematically diminished possibility of success in pursuing mathematical study. Appropriate treatment therefore varies according to the needs of and obstacles facing any subgroup.
Applying the principles of equity to evaluate the progress of curricular programs is a conceptually thorny challenge. What is challenging is how to evaluate curricular programs on their progress toward equity in meeting the needs of a diverse student body. Consider how the following questions provide one with a variety of perspectives on the effectiveness of curricular reform regarding equity:
Does one expect all students to improve performance, thus raising the bar, but possibly not to decrease the gap between traditionally well-served and under-served students?
Does one focus on reducing the gap and devote less attention to overall gains, thus closing the gap but possibly not raising the bar?
Or, does one seek evidence that progress is made on both challenges—seeking progress for all students and arguably faster progress for those most at risk?
Evaluating each of the first two questions independently seems relatively straightforward. When one opts for a combination of these two, the potential for tensions between the two becomes more evident. For example, how can one differentiate between the case in which the gap is closed because talented students are being underchallenged from the case in which the gap is closed because the low-performing students improved their progress at an increased rate? Many believe that nearly all mathematics curricula in this country are insufficiently challenging and rigorous. Therefore achieving modest gains across all ability levels with evidence of accelerated progress by at-risk students may still be criticized for failure to stimulate the top performing student group adequately. Evaluating curricula with regard to this aspect therefore requires judgment and careful methodological attention.
Depending on one’s view of equity, different implications for the collection of data follow. These considerations made examination of the quality of the evaluations as they treated questions of equity challenging for the committee members. Hence we spell out our assumptions as precisely as possible:
Evaluation studies should include representative samples of student demographics, which may require particular attention to the inclusion of underrepresented minority students from lower socioeconomic groups, females, and special needs populations (LEP, learning disabled, gifted and talented students) in the samples. This may require one to solicit participation by particular schools or districts, rather than to follow the patterns of commercial implementation, which may lead to an unrepresentative sample in aggregate.
Analysis of results should always consider the impact of the program on the entire spectrum of the sample to determine whether the overall gains are distributed fairly among differing student groups, and not achieved as improvements in the mean(s) of an identifiable subpopulation(s) alone.
Analysis should examine whether any group of students is systematically less well served by curricular implementation, causing losses or weakening the rate of gains. For example, this could occur if one neglected the continued development of programs for gifted and talented students in mathematics in order to implement programs focused on improving access for underserved youth, or if one improved programs solely for one group of language learners, ignoring the needs of others, or if one’s study systematically failed to report high attrition affecting rates of participation of success or failure.
Analyses should examine whether gaps in scores between significantly disadvantaged or underperforming subgroups and advantaged subgroups are decreasing both in relation to eliminating the development of gaps in the first place and in relation to accelerating improvement for underserved youth relative to their advantaged peers at the upper grades.
In reviewing the outcomes of the studies, the committee reports first on what kinds of attention to these issues were apparent in the database, and second on what kinds of results were produced. Some of the studies used multiple methods to provide readers with information on these issues. In our report on the evaluations, we both provide descriptive information on the approaches used and summarize the results of those studies. Developing more effective methods to monitor the achievement of these objectives may need to go beyond what is reported in this study.
Among the 63 at least minimally methodologically adequate studies, 26 reported on the effects of their programs on subgroups of students. The
TABLE 5-13 Most Common Subgroups Used in the Analyses and the Number of Studies That Reported on That Variable
other 37 reported on the effects of the curricular intervention on means of whole groups and their standard deviations, but did not report on their data in terms of the impact on subpopulations. Of those 26 evaluations, 19 studies were on NSF-supported programs and 7 were on commercially generated materials. Table 5-13 reports the most common subgroups used in the analyses and the number of studies that reported on that variable. Because many studies used multiple categories for disaggregation (ethnicity, SES, and gender), the number of reports is more than double the number of studies. For this reason, we report the study results in terms of the “frequency of reports on a particular subgroup” and distinguish this from what we refer to as “study counts.” The advantage of this approach is that it permits reporting on studies that investigated multiple ways to disaggregate their data. The disadvantage is that in a sense, studies undertaking multiple disaggregations become overrepresented in the data set as a result. A similar distinction and approach were used in our treatment of disaggregation by content strands.
It is apparent from these data that the evaluators of NSF-supported curricula documented more equity-based outcomes, as they reported 43 of the 56 comparisons. However, the same percentage of the NSF-supported evaluations disaggregated their results by subgroup, as did commercially generated evaluations (41 percent in both cases). This is an area where evaluations of curricula could benefit greatly from standardization of ex-
pectation and methodology. Given the importance of the topic of equity, it should be standard practice to include such analyses in evaluation studies.
In summarizing these 26 studies, the first consideration was whether representative samples of students were evaluated. As we have learned from medical studies, if conclusions on effectiveness are drawn without careful attention to representativeness of the sample relative to the whole population, then the generalizations drawn from the results can be seriously flawed. In Chapter 2 we reported that across the studies, approximately 81 percent of the comparative studies and 73 percent of the case studies reported data on school location (urban, suburban, rural, or state/region), with suburban students being the largest percentage in both study types. The proportions of students studied indicated a tendency to undersample urban and rural populations and oversample suburban schools. With a high concentration of minorities and lower SES students in these areas, there are some concerns about the representativeness of the work.
A second consideration was to see whether the achievement effects of curricular interventions were achieved evenly among the various subgroups. Studies answered this question in different ways. Most commonly, evaluators reported on the performance of various subgroups in the treatment conditions as compared to those same subgroups in the comparative condition. They reported outcome scores or gains from pretest to posttest. We refer to these as “between” comparisons.
Other studies reported on the differences among subgroups within an experimental treatment, describing how well one group does in comparison with another group. Again, these reports were done in relation either to outcome measures or to gains from pretest to posttest. Often these reports contained a time element, reporting on how the internal achievement patterns changed over time as a curricular program was used. We refer to these as “within” comparisons.
Some studies reported both between and within comparisons. Others did not report findings by comparing mean scores or gains, but rather created regression equations that predicted the outcomes and examined whether demographic characteristics are related to performance. Six studies (all on NSF-supported curricula) used this approach with variables related to subpopulations. Twelve studies used ANCOVA or Multiple Analysis of Variance (MANOVA) to study disaggregation by subgroup, and two reported on comparative effect sizes. In the studies using statistical tests other than t-tests or Chi-squares, two were evaluations of commercially generated materials and the rest were of NSF-supported materials.
Of the studies that reported on gender (n=19), the NSF-supported ones (n=13) reported five cases in which the females outperformed their counterparts in the controls and one case in which the female-male gap decreased within the experimental treatments across grades. In most cases, the studies
present a mixed picture with some bright spots, with the majority showing no significant difference. One study reported significant improvements for African-American females.
In relation to race, 15 of 16 reports on African Americans showed positive effects in favor of the treatment group for NSF-supported curricula. Two studies reported decreases in the gaps between African Americans and whites or Asians. One of the two evaluations of African Americans, performance reported for the commercially generated materials, showed significant positive results, as mentioned previously.
For Hispanic students, 12 of 15 reports of the NSF-supported materials were significantly positive, with the other 3 showing no significant difference. One study reported a decrease in the gaps in favor of the experimental group. No evaluations of commercially generated materials were reported on Hispanic populations. Other reports on ethnic groups occurred too seldom to generalize.
Students from lower socioeconomic groups fared well, according to reported evaluations of NSF-supported materials (n=8), in that experimental groups outperformed control groups in all but one case. The one study of commercially generated materials that included SES as a variable reported no significant difference. For students with limited English proficiency, of the two evaluations of NSF-supported materials, one reported significantly more positive results for the experimental treatment. Likewise, one study of commercially generated materials yielded a positive result at the elementary level.
We also examined the data for ability differences and found reports by quartiles for a few evaluation studies. In these cases, the evaluations showed results across quartiles in favor of the NSF-supported materials. In one case using the same program, the lower quartiles showed the most improvement, and in the other, the gains were in the middle and upper groups for the Iowa Test of Basic Skills and evenly distributed for the informal assessment.
Summary Statements
After reviewing these studies, the committee observed that examining differences by gender, race, SES, and performance levels should be examined as a regular part of any review of effectiveness. We would recommend that all comparative studies report on both “between” and “within” comparisons so that the audience of an evaluation can simply and easily consider the level of improvement, its distribution across subgroups, and the impact of curricular implementation on any gaps in performance. Each of the major categories—gender, race/ethnicity, SES, and achievement level—contributes a significant and contrasting view of curricular impact. Further-
more, more sophisticated accounts would begin to permit, across studies, finer distinctions to emerge, such as the effect of a program on young African-American women or on first generation Asian students.
In addition, the committee encourages further study and deliberation on the use of more complex approaches to the examination of equity issues. This is particularly important due to the overlaps among these categories, where poverty can show itself as its own variable but also may be highly correlated to prior performance. Hence, the use of one variable can mask differences that should be more directly attributable to another. The committee recommends that a group of measurement and equity specialists confer on the most effective design to advance on these questions.
Finally, it is imperative that evaluation studies systematically include demographically representative student populations and distinguish evaluations that follow the commercial patterns of use from those that seek to establish effectiveness with a diverse student population. Along these lines, it is also important that studies report on the impact data on all substantial ethnic groups, including whites. Many studies, perhaps because whites were the majority population, failed to report on this ethnic group in their analyses. As we saw in one study, where Asian students were from poor homes and first generation, any subgroup can be an at-risk population in some setting, and because gains in means may not necessarily be assumed to translate to gains for all subgroups or necessarily for the majority subgroup. More complete and thorough descriptions and configurations of characteristics of the subgroups being served at any location—with careful attention to interactions—is needed in evaluations.
Interactions Among Content and Equity, by Grade Band
By examining disaggregation by content strand by grade levels, along with disaggregation by diverse subpopulations, the committee began to discover grade band patterns of performance that should be useful in the conduct of future evaluations. Examining each of these issues in isolation can mask some of the overall effects of curricular use. Two examples of such analysis are provided. The first example examines all the evaluations of NSF-supported curricula from the elementary level. The second examines the set of evaluations of NSF-supported curricula at the high school level, and cannot be carried out on evaluations of commercially generated programs because they lack disaggregation by student subgroup.
Example One
At the elementary level, the findings of the review of evaluations of data on effectiveness of NSF-supported curricula report consistent patterns of
benefits to students. Across the studies, it appears that positive results are enhanced when accompanied by adequate professional development and the use of pedagogical methods consistent with those indicated by the curricula. The benefits are most consistently evidenced in the broadening topics of geometry, measurement, probability, and statistics, and in applied problem solving and reasoning. It is important to consider whether the outcome measures in these areas demonstrate a depth of understanding. In early understanding of fractions and algebra, there is some evidence of improvement. Weaknesses are sometimes reported in the areas of computational skills, especially in the routinization of multiplication and division. These assertions are tentative due to the possible flaws in designs but quite consistent across studies, and future evaluations should seek to replicate, modify, or discredit these results.
The way to most efficiently and effectively link informal reasoning and formal algorithms and procedures is an open question. Further research is needed to determine how to most effectively link the gains and flexibility associated with student-generated reasoning to the automaticity and generalizability often associated with mastery of standard algorithms.
The data from these evaluations at the elementary level generally present credible evidence of increased success in engaging minority students and students in poverty based on reported gains that are modestly higher for these students than for the comparative groups. What is less well documented in the studies is the extent to which the curricula counteract the tendencies to see gaps emerge and result in long-term persistence in performance by gender and minority group membership as they move up the grades. However, the evaluations do indicate that these curricula can help, and almost never do harm. Finally, on the question of adequate challenge for advanced and talented students, the data are equivocal. More attention to this issue is needed.
Example Two
The data at the high school level produced the most conflicting results, and in conducting future evaluations, evaluators will need to examine this level more closely. We identify the high school as the crucible for curricular change for three reasons: (1) the transition to postsecondary education puts considerable pressure on these curricula; (2) the criteria outlined in the NSF RFP specify significant changes from traditional practice; and (3) high school freshmen arrive from a myriad of middle school curricular experiences. For the NSF-supported curricula, the RFP required that the programs provide a core curriculum “drawn from statistics/probability, algebra/functions, geometry/trigonometry, and discrete mathematics” (NSF, 1991, p. 2) and use “a full range of tools, including graphing calculators
and computers” (NSF, 1991, p. 2). The NSF RFP also specified the inclusion of “situations from the natural and social sciences and from other parts of the school curriculum as contexts for developing and using mathematics” (NSF, 1991, p. 1). It was during the fourth year that “course options should focus on special mathematical needs of individual students, accommodating not only the curricular demands of the college-bound but also specialized applications supportive of the workplace aspirations of employment-bound students” (NSF, 1991, p. 2). Because this set of requirements comprises a significant departure from conventional practice, the implementation of the high school curricula should be studied in particular detail.
We report on a Systemic Initiative for Montana Mathematics and Science (SIMMS) study by Souhrada (2001) and Brown et al. (1990), in which students were permitted to select traditional, reform, and mixed tracks. It became apparent that the students were quite aware of the choices they faced, as illustrated in the following quote:
The advantage of the traditional courses is that you learn—just math. It’s not applied. You get a lot of math. You may not know where to use it, but you learn a lot…. An advantage in SIMMS is that the kids in SIMMS tell me that they really understand the math. They understand where it comes from and where it is used.
This quote succinctly captures the tensions reported as experienced by students. It suggests that student perceptions are an important source of evidence in conducting evaluations. As we examined these curricular evaluations across the grades, we paid particular attention to the specificity of the outcome measures in relation to curricular objectives. Overall, a review of these studies would lead one to draw the following tentative summary conclusions:
There is some evidence of discontinuity in the articulation between high school and college, resulting from the organization and emphasis of the new curricula. This discontinuity can emerge in scores on college admission tests, placement tests, and first semester grades where nonreform students have shown some advantage on typical college achievement measures.
The most significant areas of disadvantage seem to be in students’ facility with algebraic manipulation, and with formalization, mathematical structure, and proof when isolated from context and denied technological supports. There is some evidence of weakness in computation and numeration, perhaps due to reliance on calculators and varied policies regarding their use at colleges (Kahan, 1999; Huntley et al., 2000).
There is also consistent evidence that the new curricula present
strengths in areas of solving applied problems, the use of technology, new areas of content development such as probability and statistics and functions-based reasoning in the use of graphs, using data in tables, and producing equations to describe situations (Huntley et al., 2000; Hirsch and Schoen, 2002).
Despite early performance on standard outcome measures at the high school level showing equivalent or better performance by reform students (Austin et al., 1997; Merlino and Wolff, 2001), the common standardized outcome measures (Preliminary Scholastic Assessment Test [PSAT] scores or national tests) are too imprecise to determine with more specificity the comparisons between the NSF-supported and comparison approaches, while program-generated measures lack evidence of external validity and objectivity. There is an urgent need for a set of measures that would provide detailed information on specific concepts and conceptual development over time and may require use as embedded as well as summative assessment tools to provide precise enough data on curricular effectiveness.
The data also report some progress in strengthening the performance of underrepresented groups in mathematics relative to their counterparts in the comparative programs (Schoen et al., 1998; Hirsch and Schoen, 2002).
This reported pattern of results should be viewed as very tentative, as there are only a few studies in each of these areas, and most do not adequately control for competing factors, such as the nature of the course received in college. Difficulties in the transition may also be the result of a lack of alignment of measures, especially as placement exams often emphasize algebraic proficiencies. These results are presented only for the purpose of stimulating further evaluation efforts. They further emphasize the need to be certain that such designs examine the level of mathematical reasoning of students, particularly in relation to their knowledge of understanding of the role of proofs and definitions and their facility with algebraic manipulation as we as carefully document the competencies taught in the curricular materials. In our framework, gauging the ease of transition to college study is an issue of examining curricular alignment with systemic factors, and needs to be considered along with those tests that demonstrate a curricular validity of measures. Furthermore, the results raising concerns about college success need replication before secure conclusions are drawn.
Also, it is important that subsequent evaluations also examine curricular effects on students’ interest in mathematics and willingness to persist in its study. Walker (1999) reported that there may be some systematic differences in these behaviors among different curricula and that interest and persistence may help students across a variety of subgroups to survive entry-level hurdles, especially if technical facility with symbol manipulation
can be improved. In the context of declines in advanced study in mathematics by American students (Hawkins, 2003), evaluation of curricular impact on students’ interest, beliefs, persistence, and success are needed.
The committee takes the position that ultimately the question of the impact of different curricula on performance at the collegiate level should be resolved by whether students are adequately prepared to pursue careers in mathematical sciences, broadly defined, and to reason quantitatively about societal and technological issues. It would be a mistake to focus evaluation efforts solely or primarily on performance on entry-level courses, which can clearly function as filters and may overly emphasize procedural competence, but do not necessarily represent what concepts and skills lead to excellence and success in the field.
These tentative patterns of findings indicate that at the high school level, it is necessary to conduct individual evaluations that examine the transition to college carefully in order to gauge the level of success in preparing students for college entry and the successful negotiation of majors. Equally, it is imperative to examine the impact of high school curricula on other possible student trajectories, such as obtaining high school diplomas, moving into worlds of work or through transitional programs leading to technical training, two-year colleges, and so on.
These two analyses of programs by grade-level band, content strand, and equity represent a methodological innovation that could strengthen the empirical database on curricula significantly and provide the level of detail really needed by curriculum designers to improve their programs. In addition, it appears that one could characterize the NSF programs (and not the commercial programs as a group) as representing a particular approach to curriculum, as discussed in Chapter 3 . It is an approach that integrates content strands; relies heavily on the use of situations, applications, and modeling; encourages the use of technology; and has a significant dose of mathematical inquiry. One could ask the question of whether this approach as a whole is “effective.” It is beyond the charge and scope of this report, but is a worthy target of investigation if one uses proper care in design, execution, and analysis. Likewise other approaches to curricular change should be investigated at the aggregate level, using careful and rigorous design.
The committee believes that a diversity of curricular approaches is a strength in an educational system that maintains local and state control of curricular decision making. While “scientifically established as effective” should be an increasingly important consideration in curricular choice, local cultural differences, needs, values, and goals will also properly influence curricular choice. A diverse set of effective curricula would be ideal. Finally, the committee emphasizes once again the importance of basing the studies on measures with established curricular validity and avoiding cor-
ruption of indicators as a result of inappropriate amounts of teaching to the test, so as to be certain that the outcomes are the product of genuine student learning.
CONCLUSIONS FROM THE COMPARATIVE STUDIES
In summary, the committee reviewed a total of 95 comparative studies. There were more NSF-supported program evaluations than commercial ones, and the commercial ones were primarily on Saxon or UCSMP materials. Of the 19 curricular programs reviewed, 23 percent of the NSF-supported and 33 percent of the commercially generated materials selected had programs with no comparative reviews. This finding is particularly disturbing in light of the legislative mandate in No Child Left Behind (U.S. Department of Education, 2001) for scientifically based curricular programs and materials to be used in the schools. It suggests that more explicit protocols for the conduct of evaluation of programs that include comparative studies need to be required and utilized.
Sixty-nine percent of NSF-supported and 61 percent of commercially generated program evaluations met basic conditions to be classified as at least minimally methodologically adequate studies for the evaluation of effectiveness. These studies were ones that met the criteria of including measures of student outcomes on mathematical achievement, reporting a method of establishing comparability among samples and reporting on implementation elements, disaggregating by content strand, or using precise, theoretical analyses of the construct or multiple measures.
Most of these studies had both strengths and weaknesses in their quasi-experimental designs. The committee reviewed the studies and found that evaluators had developed a number of features that merit inclusions in future work. At the same time, many had internal threats to validity that suggest a need for clearer guidelines for the conduct of comparative evaluations.
Many of the strengths and innovations came from the evaluators’ understanding of the program theories behind the curricula, their knowledge of the complexity of practice, and their commitment to measuring valid and significant mathematical ideas. Many of the weaknesses came from inadequate attention to experimental design, insufficient evidence of the independence of evaluators in some studies, and instability and lack of cooperation in interfacing with the conditions of everyday practice.
The committee identified 10 elements of comparative studies needed to establish a basis for determining the effectiveness of a curriculum. We recognize that not all studies will be able to implement successfully all elements, and those experimental design variations will be based largely on study size and location. The list of elements begins with the seven elements
corresponding to the seven critical decisions and adds three additional elements that emerged as a result of our review:
A better balance needs to be achieved between experimental and quasi-experimental studies. The virtual absence of large-scale experimental studies does not provide a way to determine whether the use of quasi-experimental approaches is being systematically biased in unseen ways.
If a quasi-experimental design is selected, it is necessary to establish comparability. When quasi-experimentation is used, it “pertains to studies in which the model to describe effects of secondary variables is not known but assumed” (NRC, 1992, p. 18). This will lead to weaker and potentially suspect causal claims, which should be acknowledged in the evaluation report, but may be necessary in relation to feasibility (Joint Committee on Standards for Educational Evaluation, 1994). In general, to date, studies have assumed prior achievement measures, ethnicity, gender, and SES, are acceptable variables on which to match samples or on which to make statistical adjustments. But there are often other variables in need of such control in such evaluations including opportunity to learn, teacher effectiveness, and implementation (see #4 below).
The selection of a unit of analysis is of critical importance to the design. To the extent possible, it is useful to randomly assign the unit for the different curricula. The number of units of analysis necessary for the study to establish statistical significance depends not on the number of students, but on this unit of analysis. It appears that classrooms and schools are the most likely units of analysis. In addition, the development of increasingly sophisticated means of conducting studies that recognize that the level of the educational system in which experimentation occurs affects research designs.
It is essential to examine the implementation components through a set of variables that include the extent to which the materials are implemented, teaching methods, the use of supplemental materials, professional development resources, teacher background variables, and teacher effects. Gathering these data to gauge the level of implementation fidelity is essential for evaluators to ensure adequate implementation. Studies could also include nested designs to support analysis of variation by implementation components.
Outcome data should include a variety of measures of the highest quality. These measures should vary by question type (open ended, multiple choice), by type of test (international, national, local) and by relation of testing to everyday practice (formative, summative, high stakes), and ensure curricular validity of measures and assess curricular alignment with systemic factors. The use of comparisons among total tests, fair tests, and
conservative tests, as done in the evaluations of UCSMP, permits one to gain insight into teacher effects and to contrast test results by items included. Tests should also include content strands to aid disaggregation, at a level of major content strands (see Figure 5-11 ) and content-specific items relevant to the experimental curricula.
Statistical analysis should be conducted on the appropriate unit of analysis and should include more sophisticated methods of analysis such as ANOVA, ANCOVA, MACOVA, linear regression, and multiple regression analysis as appropriate.
Reports should include clear statements of the limitations to generalization of the study. These should include indications of limitations in populations sampled, sample size, unique population inclusions or exclusions, and levels of use or attrition. Data should also be disaggregated by gender, race/ethnicity, SES, and performance levels to permit readers to see comparative gains across subgroups both between and within studies.
It is useful to report effect sizes. It is also useful to present item-level data across treatment program and show when performances between the two groups are within the 10 percent confidence interval of each other. These two extremes document how crucial it is for curricula developers to garner both precise and generalizable information to inform their revisions.
Careful attention should also be given to the selection of samples of populations for participation. These samples should be representative of the populations to whom one wants to generalize the results. Studies should be clear if they are generalizing to groups who have already selected the materials (prior users) or to populations who might be interested in using the materials (demographically representative).
The control group should use an identified comparative curriculum or curricula to avoid comparisons to unstructured instruction.
In addition to these prototypical decisions to be made in the conduct of comparative studies, the committee suggests that it would be ideal for future studies to consider some of the overall effects of these curricula and to test more directly and rigorously some of the findings and alternative hypotheses. Toward this end, the committee reported the tentative findings of these studies by program type. Although these results are subject to revision, based on the potential weaknesses in design of many of the studies summarized, the form of analysis demonstrated in this chapter provides clear guidance about the kinds of knowledge claims and the level of detail that we need to be able to judge effectiveness. Until we are able to achieve an array of comparative studies that provide valid and reliable information on these issues, we will be vulnerable to decision making based excessively on opinion, limited experience, and preconceptions.
This book reviews the evaluation research literature that has accumulated around 19 K-12 mathematics curricula and breaks new ground in framing an ambitious and rigorous approach to curriculum evaluation that has relevance beyond mathematics. The committee that produced this book consisted of mathematicians, mathematics educators, and methodologists who began with the following charge:
- Evaluate the quality of the evaluations of the thirteen National Science Foundation (NSF)-supported and six commercially generated mathematics curriculum materials;
- Determine whether the available data are sufficient for evaluating the efficacy of these materials, and if not;
- Develop recommendations about the design of a project that could result in the generation of more reliable and valid data for evaluating such materials.
The committee collected, reviewed, and classified almost 700 studies, solicited expert testimony during two workshops, developed an evaluation framework, established dimensions/criteria for three methodologies (content analyses, comparative studies, and case studies), drew conclusions on the corpus of studies, and made recommendations for future research.
READ FREE ONLINE
Welcome to OpenBook!
You're looking at OpenBook, NAP.edu's online reading room since 1999. Based on feedback from you, our users, we've made some improvements that make it easier than ever to read thousands of publications on our website.
Do you want to take a quick tour of the OpenBook's features?
Show this book's table of contents , where you can jump to any chapter by name.
...or use these buttons to go back to the previous chapter or skip to the next one.
Jump up to the previous page or down to the next one. Also, you can type in a page number and press Enter to go directly to that page in the book.
Switch between the Original Pages , where you can read the report as it appeared in print, and Text Pages for the web version, where you can highlight and search the text.
To search the entire text of this book, type in your search term here and press Enter .
Share a link to this book page on your preferred social network or via email.
View our suggested citation for this chapter.
Ready to take your reading offline? Click here to buy this book in print or download it as a free PDF, if available.
Get Email Updates
Do you enjoy reading reports from the Academies online for free ? Sign up for email notifications and we'll let you know about new publications in your areas of interest when they're released.

An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Lau F, Kuziemsky C, editors. Handbook of eHealth Evaluation: An Evidence-based Approach [Internet]. Victoria (BC): University of Victoria; 2017 Feb 27.

Handbook of eHealth Evaluation: An Evidence-based Approach [Internet].
Chapter 10 methods for comparative studies.
Francis Lau and Anne Holbrook .
10.1. Introduction
In eHealth evaluation, comparative studies aim to find out whether group differences in eHealth system adoption make a difference in important outcomes. These groups may differ in their composition, the type of system in use, and the setting where they work over a given time duration. The comparisons are to determine whether significant differences exist for some predefined measures between these groups, while controlling for as many of the conditions as possible such as the composition, system, setting and duration.
According to the typology by Friedman and Wyatt (2006) , comparative studies take on an objective view where events such as the use and effect of an eHealth system can be defined, measured and compared through a set of variables to prove or disprove a hypothesis. For comparative studies, the design options are experimental versus observational and prospective versus retrospective. The quality of eHealth comparative studies depends on such aspects of methodological design as the choice of variables, sample size, sources of bias, confounders, and adherence to quality and reporting guidelines.
In this chapter we focus on experimental studies as one type of comparative study and their methodological considerations that have been reported in the eHealth literature. Also included are three case examples to show how these studies are done.
10.2. Types of Comparative Studies
Experimental studies are one type of comparative study where a sample of participants is identified and assigned to different conditions for a given time duration, then compared for differences. An example is a hospital with two care units where one is assigned a cpoe system to process medication orders electronically while the other continues its usual practice without a cpoe . The participants in the unit assigned to the cpoe are called the intervention group and those assigned to usual practice are the control group. The comparison can be performance or outcome focused, such as the ratio of correct orders processed or the occurrence of adverse drug events in the two groups during the given time period. Experimental studies can take on a randomized or non-randomized design. These are described below.
10.2.1. Randomized Experiments
In a randomized design, the participants are randomly assigned to two or more groups using a known randomization technique such as a random number table. The design is prospective in nature since the groups are assigned concurrently, after which the intervention is applied then measured and compared. Three types of experimental designs seen in eHealth evaluation are described below ( Friedman & Wyatt, 2006 ; Zwarenstein & Treweek, 2009 ).
Randomized controlled trials ( rct s) – In rct s participants are randomly assigned to an intervention or a control group. The randomization can occur at the patient, provider or organization level, which is known as the unit of allocation. For instance, at the patient level one can randomly assign half of the patients to receive emr reminders while the other half do not. At the provider level, one can assign half of the providers to receive the reminders while the other half continues with their usual practice. At the organization level, such as a multisite hospital, one can randomly assign emr reminders to some of the sites but not others. Cluster randomized controlled trials ( crct s) – In crct s, clusters of participants are randomized rather than by individual participant since they are found in naturally occurring groups such as living in the same communities. For instance, clinics in one city may be randomized as a cluster to receive emr reminders while clinics in another city continue their usual practice. Pragmatic trials – Unlike rct s that seek to find out if an intervention such as a cpoe system works under ideal conditions, pragmatic trials are designed to find out if the intervention works under usual conditions. The goal is to make the design and findings relevant to and practical for decision-makers to apply in usual settings. As such, pragmatic trials have few criteria for selecting study participants, flexibility in implementing the intervention, usual practice as the comparator, the same compliance and follow-up intensity as usual practice, and outcomes that are relevant to decision-makers.
10.2.2. Non-randomized Experiments
Non-randomized design is used when it is neither feasible nor ethical to randomize participants into groups for comparison. It is sometimes referred to as a quasi-experimental design. The design can involve the use of prospective or retrospective data from the same or different participants as the control group. Three types of non-randomized designs are described below ( Harris et al., 2006 ).
Intervention group only with pretest and post-test design – This design involves only one group where a pretest or baseline measure is taken as the control period, the intervention is implemented, and a post-test measure is taken as the intervention period for comparison. For example, one can compare the rates of medication errors before and after the implementation of a cpoe system in a hospital. To increase study quality, one can add a second pretest period to decrease the probability that the pretest and post-test difference is due to chance, such as an unusually low medication error rate in the first pretest period. Other ways to increase study quality include adding an unrelated outcome such as patient case-mix that should not be affected, removing the intervention to see if the difference remains, and removing then re-implementing the intervention to see if the differences vary accordingly. Intervention and control groups with post-test design – This design involves two groups where the intervention is implemented in one group and compared with a second group without the intervention, based on a post-test measure from both groups. For example, one can implement a cpoe system in one care unit as the intervention group with a second unit as the control group and compare the post-test medication error rates in both units over six months. To increase study quality, one can add one or more pretest periods to both groups, or implement the intervention to the control group at a later time to measure for similar but delayed effects. Interrupted time series ( its ) design – In its design, multiple measures are taken from one group in equal time intervals, interrupted by the implementation of the intervention. The multiple pretest and post-test measures decrease the probability that the differences detected are due to chance or unrelated effects. An example is to take six consecutive monthly medication error rates as the pretest measures, implement the cpoe system, then take another six consecutive monthly medication error rates as the post-test measures for comparison in error rate differences over 12 months. To increase study quality, one may add a concurrent control group for comparison to be more convinced that the intervention produced the change.
10.3. Methodological Considerations
The quality of comparative studies is dependent on their internal and external validity. Internal validity refers to the extent to which conclusions can be drawn correctly from the study setting, participants, intervention, measures, analysis and interpretations. External validity refers to the extent to which the conclusions can be generalized to other settings. The major factors that influence validity are described below.
10.3.1. Choice of Variables
Variables are specific measurable features that can influence validity. In comparative studies, the choice of dependent and independent variables and whether they are categorical and/or continuous in values can affect the type of questions, study design and analysis to be considered. These are described below ( Friedman & Wyatt, 2006 ).
Dependent variables – This refers to outcomes of interest; they are also known as outcome variables. An example is the rate of medication errors as an outcome in determining whether cpoe can improve patient safety. Independent variables – This refers to variables that can explain the measured values of the dependent variables. For instance, the characteristics of the setting, participants and intervention can influence the effects of cpoe . Categorical variables – This refers to variables with measured values in discrete categories or levels. Examples are the type of providers (e.g., nurses, physicians and pharmacists), the presence or absence of a disease, and pain scale (e.g., 0 to 10 in increments of 1). Categorical variables are analyzed using non-parametric methods such as chi-square and odds ratio. Continuous variables – This refers to variables that can take on infinite values within an interval limited only by the desired precision. Examples are blood pressure, heart rate and body temperature. Continuous variables are analyzed using parametric methods such as t -test, analysis of variance or multiple regression.
10.3.2. Sample Size
Sample size is the number of participants to include in a study. It can refer to patients, providers or organizations depending on how the unit of allocation is defined. There are four parts to calculating sample size. They are described below ( Noordzij et al., 2010 ).
Significance level – This refers to the probability that a positive finding is due to chance alone. It is usually set at 0.05, which means having a less than 5% chance of drawing a false positive conclusion. Power – This refers to the ability to detect the true effect based on a sample from the population. It is usually set at 0.8, which means having at least an 80% chance of drawing a correct conclusion. Effect size – This refers to the minimal clinically relevant difference that can be detected between comparison groups. For continuous variables, the effect is a numerical value such as a 10-kilogram weight difference between two groups. For categorical variables, it is a percentage such as a 10% difference in medication error rates. Variability – This refers to the population variance of the outcome of interest, which is often unknown and is estimated by way of standard deviation ( sd ) from pilot or previous studies for continuous outcome.
Sample Size Equations for Comparing Two Groups with Continuous and Categorical Outcome Variables.
An example of sample size calculation for an rct to examine the effect of cds on improving systolic blood pressure of hypertensive patients is provided in the Appendix. Refer to the Biomath website from Columbia University (n.d.) for a simple Web-based sample size / power calculator.
10.3.3. Sources of Bias
There are five common sources of biases in comparative studies. They are selection, performance, detection, attrition and reporting biases ( Higgins & Green, 2011 ). These biases, and the ways to minimize them, are described below ( Vervloet et al., 2012 ).
Selection or allocation bias – This refers to differences between the composition of comparison groups in terms of the response to the intervention. An example is having sicker or older patients in the control group than those in the intervention group when evaluating the effect of emr reminders. To reduce selection bias, one can apply randomization and concealment when assigning participants to groups and ensure their compositions are comparable at baseline. Performance bias – This refers to differences between groups in the care they received, aside from the intervention being evaluated. An example is the different ways by which reminders are triggered and used within and across groups such as electronic, paper and phone reminders for patients and providers. To reduce performance bias, one may standardize the intervention and blind participants from knowing whether an intervention was received and which intervention was received. Detection or measurement bias – This refers to differences between groups in how outcomes are determined. An example is where outcome assessors pay more attention to outcomes of patients known to be in the intervention group. To reduce detection bias, one may blind assessors from participants when measuring outcomes and ensure the same timing for assessment across groups. Attrition bias – This refers to differences between groups in ways that participants are withdrawn from the study. An example is the low rate of participant response in the intervention group despite having received reminders for follow-up care. To reduce attrition bias, one needs to acknowledge the dropout rate and analyze data according to an intent-to-treat principle (i.e., include data from those who dropped out in the analysis). Reporting bias – This refers to differences between reported and unreported findings. Examples include biases in publication, time lag, citation, language and outcome reporting depending on the nature and direction of the results. To reduce reporting bias, one may make the study protocol available with all pre-specified outcomes and report all expected outcomes in published results.
10.3.4. Confounders
Confounders are factors other than the intervention of interest that can distort the effect because they are associated with both the intervention and the outcome. For instance, in a study to demonstrate whether the adoption of a medication order entry system led to lower medication costs, there can be a number of potential confounders that can affect the outcome. These may include severity of illness of the patients, provider knowledge and experience with the system, and hospital policy on prescribing medications ( Harris et al., 2006 ). Another example is the evaluation of the effect of an antibiotic reminder system on the rate of post-operative deep venous thromboses ( dvt s). The confounders can be general improvements in clinical practice during the study such as prescribing patterns and post-operative care that are not related to the reminders ( Friedman & Wyatt, 2006 ).
To control for confounding effects, one may consider the use of matching, stratification and modelling. Matching involves the selection of similar groups with respect to their composition and behaviours. Stratification involves the division of participants into subgroups by selected variables, such as comorbidity index to control for severity of illness. Modelling involves the use of statistical techniques such as multiple regression to adjust for the effects of specific variables such as age, sex and/or severity of illness ( Higgins & Green, 2011 ).
10.3.5. Guidelines on Quality and Reporting
There are guidelines on the quality and reporting of comparative studies. The grade (Grading of Recommendations Assessment, Development and Evaluation) guidelines provide explicit criteria for rating the quality of studies in randomized trials and observational studies ( Guyatt et al., 2011 ). The extended consort (Consolidated Standards of Reporting Trials) Statements for non-pharmacologic trials ( Boutron, Moher, Altman, Schulz, & Ravaud, 2008 ), pragmatic trials ( Zwarestein et al., 2008 ), and eHealth interventions ( Baker et al., 2010 ) provide reporting guidelines for randomized trials.
The grade guidelines offer a system of rating quality of evidence in systematic reviews and guidelines. In this approach, to support estimates of intervention effects rct s start as high-quality evidence and observational studies as low-quality evidence. For each outcome in a study, five factors may rate down the quality of evidence. The final quality of evidence for each outcome would fall into one of high, moderate, low, and very low quality. These factors are listed below (for more details on the rating system, refer to Guyatt et al., 2011 ).
Design limitations – For rct s they cover the lack of allocation concealment, lack of blinding, large loss to follow-up, trial stopped early or selective outcome reporting. Inconsistency of results – Variations in outcomes due to unexplained heterogeneity. An example is the unexpected variation of effects across subgroups of patients by severity of illness in the use of preventive care reminders. Indirectness of evidence – Reliance on indirect comparisons due to restrictions in study populations, intervention, comparator or outcomes. An example is the 30-day readmission rate as a surrogate outcome for quality of computer-supported emergency care in hospitals. Imprecision of results – Studies with small sample size and few events typically would have wide confidence intervals and are considered of low quality. Publication bias – The selective reporting of results at the individual study level is already covered under design limitations, but is included here for completeness as it is relevant when rating quality of evidence across studies in systematic reviews.
The original consort Statement has 22 checklist items for reporting rct s. For non-pharmacologic trials extensions have been made to 11 items. For pragmatic trials extensions have been made to eight items. These items are listed below. For further details, readers can refer to Boutron and colleagues (2008) and the consort website ( consort , n.d.).
Title and abstract – one item on the means of randomization used. Introduction – one item on background, rationale, and problem addressed by the intervention. Methods – 10 items on participants, interventions, objectives, outcomes, sample size, randomization (sequence generation, allocation concealment, implementation), blinding (masking), and statistical methods. Results – seven items on participant flow, recruitment, baseline data, numbers analyzed, outcomes and estimation, ancillary analyses, adverse events. Discussion – three items on interpretation, generalizability, overall evidence.
The consort Statement for eHealth interventions describes the relevance of the consort recommendations to the design and reporting of eHealth studies with an emphasis on Internet-based interventions for direct use by patients, such as online health information resources, decision aides and phr s. Of particular importance is the need to clearly define the intervention components, their role in the overall care process, target population, implementation process, primary and secondary outcomes, denominators for outcome analyses, and real world potential (for details refer to Baker et al., 2010 ).
10.4. Case Examples
10.4.1. pragmatic rct in vascular risk decision support.
Holbrook and colleagues (2011) conducted a pragmatic rct to examine the effects of a cds intervention on vascular care and outcomes for older adults. The study is summarized below.
Setting – Community-based primary care practices with emr s in one Canadian province. Participants – English-speaking patients 55 years of age or older with diagnosed vascular disease, no cognitive impairment and not living in a nursing home, who had a provider visit in the past 12 months. Intervention – A Web-based individualized vascular tracking and advice cds system for eight top vascular risk factors and two diabetic risk factors, for use by both providers and patients and their families. Providers and staff could update the patient’s profile at any time and the cds algorithm ran nightly to update recommendations and colour highlighting used in the tracker interface. Intervention patients had Web access to the tracker, a print version mailed to them prior to the visit, and telephone support on advice. Design – Pragmatic, one-year, two-arm, multicentre rct , with randomization upon patient consent by phone, using an allocation-concealed online program. Randomization was by patient with stratification by provider using a block size of six. Trained reviewers examined emr data and conducted patient telephone interviews to collect risk factors, vascular history, and vascular events. Providers completed questionnaires on the intervention at study end. Patients had final 12-month lab checks on urine albumin, low-density lipoprotein cholesterol, and A1c levels. Outcomes – Primary outcome was based on change in process composite score ( pcs ) computed as the sum of frequency-weighted process score for each of the eight main risk factors with a maximum score of 27. The process was considered met if a risk factor had been checked. pcs was measured at baseline and study end with the difference as the individual primary outcome scores. The main secondary outcome was a clinical composite score ( ccs ) based on the same eight risk factors compared in two ways: a comparison of the mean number of clinical variables on target and the percentage of patients with improvement between the two groups. Other secondary outcomes were actual vascular event rates, individual pcs and ccs components, ratings of usability, continuity of care, patient ability to manage vascular risk, and quality of life using the EuroQol five dimensions questionnaire ( eq-5D) . Analysis – 1,100 patients were needed to achieve 90% power in detecting a one-point pcs difference between groups with a standard deviation of five points, two-tailed t -test for mean difference at 5% significance level, and a withdrawal rate of 10%. The pcs , ccs and eq-5D scores were analyzed using a generalized estimating equation accounting for clustering within providers. Descriptive statistics and χ2 tests or exact tests were done with other outcomes. Findings – 1,102 patients and 49 providers enrolled in the study. The intervention group with 545 patients had significant pcs improvement with a difference of 4.70 ( p < .001) on a 27-point scale. The intervention group also had significantly higher odds of rating improvements in their continuity of care (4.178, p < .001) and ability to improve their vascular health (3.07, p < .001). There was no significant change in vascular events, clinical variables and quality of life. Overall the cds intervention led to reduced vascular risks but not to improved clinical outcomes in a one-year follow-up.
10.4.2. Non-randomized Experiment in Antibiotic Prescribing in Primary Care
Mainous, Lambourne, and Nietert (2013) conducted a prospective non-randomized trial to examine the impact of a cds system on antibiotic prescribing for acute respiratory infections ( ari s) in primary care. The study is summarized below.
Setting – A primary care research network in the United States whose members use a common emr and pool data quarterly for quality improvement and research studies. Participants – An intervention group with nine practices across nine states, and a control group with 61 practices. Intervention – Point-of-care cds tool as customizable progress note templates based on existing emr features. cds recommendations reflect Centre for Disease Control and Prevention ( cdc ) guidelines based on a patient’s predominant presenting symptoms and age. cds was used to assist in ari diagnosis, prompt antibiotic use, record diagnosis and treatment decisions, and access printable patient and provider education resources from the cdc . Design – The intervention group received a multi-method intervention to facilitate provider cds adoption that included quarterly audit and feedback, best practice dissemination meetings, academic detailing site visits, performance review and cds training. The control group did not receive information on the intervention, the cds or education. Baseline data collection was for three months with follow-up of 15 months after cds implementation. Outcomes – The outcomes were frequency of inappropriate prescribing during an ari episode, broad-spectrum antibiotic use and diagnostic shift. Inappropriate prescribing was computed by dividing the number of ari episodes with diagnoses in the inappropriate category that had an antibiotic prescription by the total number of ari episodes with diagnosis for which antibiotics are inappropriate. Broad-spectrum antibiotic use was computed by all ari episodes with a broad-spectrum antibiotic prescription by the total number of ari episodes with an antibiotic prescription. Antibiotic drift was computed in two ways: dividing the number of ari episodes with diagnoses where antibiotics are appropriate by the total number of ari episodes with an antibiotic prescription; and dividing the number of ari episodes where antibiotics were inappropriate by the total number of ari episodes. Process measure included frequency of cds template use and whether the outcome measures differed by cds usage. Analysis – Outcomes were measured quarterly for each practice, weighted by the number of ari episodes during the quarter to assign greater weight to practices with greater numbers of relevant episodes and to periods with greater numbers of relevant episodes. Weighted means and 95% ci s were computed separately for adult and pediatric (less than 18 years of age) patients for each time period for both groups. Baseline means in outcome measures were compared between the two groups using weighted independent-sample t -tests. Linear mixed models were used to compare changes over the 18-month period. The models included time, intervention status, and were adjusted for practice characteristics such as specialty, size, region and baseline ari s. Random practice effects were included to account for clustering of repeated measures on practices over time. P -values of less than 0.05 were considered significant. Findings – For adult patients, inappropriate prescribing in ari episodes declined more among the intervention group (-0.6%) than the control group (4.2%)( p = 0.03), and prescribing of broad-spectrum antibiotics declined by 16.6% in the intervention group versus an increase of 1.1% in the control group ( p < 0.0001). For pediatric patients, there was a similar decline of 19.7% in the intervention group versus an increase of 0.9% in the control group ( p < 0.0001). In summary, the cds had a modest effect in reducing inappropriate prescribing for adults, but had a substantial effect in reducing the prescribing of broad-spectrum antibiotics in adult and pediatric patients.
10.4.3. Interrupted Time Series on EHR Impact in Nursing Care
Dowding, Turley, and Garrido (2012) conducted a prospective its study to examine the impact of ehr implementation on nursing care processes and outcomes. The study is summarized below.
Setting – Kaiser Permanente ( kp ) as a large not-for-profit integrated healthcare organization in the United States. Participants – 29 kp hospitals in the northern and southern regions of California. Intervention – An integrated ehr system implemented at all hospitals with cpoe , nursing documentation and risk assessment tools. The nursing component for risk assessment documentation of pressure ulcers and falls was consistent across hospitals and developed by clinical nurses and informaticists by consensus. Design – its design with monthly data on pressure ulcers and quarterly data on fall rates and risk collected over seven years between 2003 and 2009. All data were collected at the unit level for each hospital. Outcomes – Process measures were the proportion of patients with a fall risk assessment done and the proportion with a hospital-acquired pressure ulcer ( hapu ) risk assessment done within 24 hours of admission. Outcome measures were fall and hapu rates as part of the unit-level nursing care process and nursing sensitive outcome data collected routinely for all California hospitals. Fall rate was defined as the number of unplanned descents to the floor per 1,000 patient days, and hapu rate was the percentage of patients with stages i-IV or unstageable ulcer on the day of data collection. Analysis – Fall and hapu risk data were synchronized using the month in which the ehr was implemented at each hospital as time zero and aggregated across hospitals for each time period. Multivariate regression analysis was used to examine the effect of time, region and ehr . Findings – The ehr was associated with significant increase in document rates for hapu risk (2.21; 95% CI 0.67 to 3.75) and non-significant increase for fall risk (0.36; -3.58 to 4.30). The ehr was associated with 13% decrease in hapu rates (-0.76; -1.37 to -0.16) but no change in fall rates (-0.091; -0.29 to 011). Hospital region was a significant predictor of variation for hapu (0.72; 0.30 to 1.14) and fall rates (0.57; 0.41 to 0.72). During the study period, hapu rates decreased significantly (-0.16; -0.20 to -0.13) but not fall rates (0.0052; -0.01 to 0.02). In summary, ehr implementation was associated with a reduction in the number of hapu s but not patient falls, and changes over time and hospital region also affected outcomes.
10.5. Summary
In this chapter we introduced randomized and non-randomized experimental designs as two types of comparative studies used in eHealth evaluation. Randomization is the highest quality design as it reduces bias, but it is not always feasible. The methodological issues addressed include choice of variables, sample size, sources of biases, confounders, and adherence to reporting guidelines. Three case examples were included to show how eHealth comparative studies are done.
- Baker T. B., Gustafson D. H., Shaw B., Hawkins R., Pingree S., Roberts L., Strecher V. Relevance of consort reporting criteria for research on eHealth interventions. Patient Education and Counselling. 2010; 81 (suppl. 7):77–86. [ PMC free article : PMC2993846 ] [ PubMed : 20843621 ]
- Columbia University. (n.d.). Statistics: sample size / power calculation. Biomath (Division of Biomathematics/Biostatistics), Department of Pediatrics. New York: Columbia University Medical Centre. Retrieved from http://www .biomath.info/power/index.htm .
- Boutron I., Moher D., Altman D. G., Schulz K. F., Ravaud P. consort Group. Extending the consort statement to randomized trials of nonpharmacologic treatment: Explanation and elaboration. Annals of Internal Medicine. 2008; 148 (4):295–309. [ PubMed : 18283207 ]
- Cochrane Collaboration. Cochrane handbook. London: Author; (n.d.) Retrieved from http://handbook .cochrane.org/
- consort Group. (n.d.). The consort statement . Retrieved from http://www .consort-statement.org/
- Dowding D. W., Turley M., Garrido T. The impact of an electronic health record on nurse sensitive patient outcomes: an interrupted time series analysis. Journal of the American Medical Informatics Association. 2012; 19 (4):615–620. [ PMC free article : PMC3384108 ] [ PubMed : 22174327 ]
- Friedman C. P., Wyatt J.C. Evaluation methods in biomedical informatics. 2nd ed. New York: Springer Science + Business Media, Inc; 2006.
- Guyatt G., Oxman A. D., Akl E. A., Kunz R., Vist G., Brozek J. et al. Schunemann H. J. grade guidelines: 1. Introduction – grade evidence profiles and summary of findings tables. Journal of Clinical Epidemiology. 2011; 64 (4):383–394. [ PubMed : 21195583 ]
- Harris A. D., McGregor J. C., Perencevich E. N., Furuno J. P., Zhu J., Peterson D. E., Finkelstein J. The use and interpretation of quasi-experimental studies in medical informatics. Journal of the American Medical Informatics Association. 2006; 13 (1):16–23. [ PMC free article : PMC1380192 ] [ PubMed : 16221933 ]
- The Cochrane Collaboration. Cochrane handbook for systematic reviews of interventions. Higgins J. P. T., Green S., editors. London: 2011. (Version 5.1.0, updated March 2011) Retrieved from http://handbook .cochrane.org/
- Holbrook A., Pullenayegum E., Thabane L., Troyan S., Foster G., Keshavjee K. et al. Curnew G. Shared electronic vascular risk decision support in primary care. Computerization of medical practices for the enhancement of therapeutic effectiveness (compete III) randomized trial. Archives of Internal Medicine. 2011; 171 (19):1736–1744. [ PubMed : 22025430 ]
- Mainous III A. G., Lambourne C. A., Nietert P.J. Impact of a clinical decision support system on antibiotic prescribing for acute respiratory infections in primary care: quasi-experimental trial. Journal of the American Medical Informatics Association. 2013; 20 (2):317–324. [ PMC free article : PMC3638170 ] [ PubMed : 22759620 ]
- Noordzij M., Tripepi G., Dekker F. W., Zoccali C., Tanck M. W., Jager K.J. Sample size calculations: basic principles and common pitfalls. Nephrology Dialysis Transplantation. 2010; 25 (5):1388–1393. Retrieved from http://ndt .oxfordjournals .org/content/early/2010/01/12/ndt .gfp732.short . [ PubMed : 20067907 ]
- Vervloet M., Linn A. J., van Weert J. C. M., de Bakker D. H., Bouvy M. L., van Dijk L. The effectiveness of interventions using electronic reminders to improve adherence to chronic medication: A systematic review of the literature. Journal of the American Medical Informatics Association. 2012; 19 (5):696–704. [ PMC free article : PMC3422829 ] [ PubMed : 22534082 ]
- Zwarenstein M., Treweek S., Gagnier J. J., Altman D. G., Tunis S., Haynes B., Oxman A. D., Moher D. for the consort and Pragmatic Trials in Healthcare (Practihc) groups. Improving the reporting of pragmatic trials: an extension of the consort statement. British Medical Journal. 2008; 337 :a2390. [ PMC free article : PMC3266844 ] [ PubMed : 19001484 ] [ CrossRef ]
- Zwarenstein M., Treweek S. What kind of randomized trials do we need? Canadian Medical Association Journal. 2009; 180 (10):998–1000. [ PMC free article : PMC2679816 ] [ PubMed : 19372438 ]
Appendix. Example of Sample Size Calculation
This is an example of sample size calculation for an rct that examines the effect of a cds system on reducing systolic blood pressure in hypertensive patients. The case is adapted from the example described in the publication by Noordzij et al. (2010) .
(a) Systolic blood pressure as a continuous outcome measured in mmHg
Based on similar studies in the literature with similar patients, the systolic blood pressure values from the comparison groups are expected to be normally distributed with a standard deviation of 20 mmHg. The evaluator wishes to detect a clinically relevant difference of 15 mmHg in systolic blood pressure as an outcome between the intervention group with cds and the control group without cds . Assuming a significance level or alpha of 0.05 for 2-tailed t -test and power of 0.80, the corresponding multipliers 1 are 1.96 and 0.842, respectively. Using the sample size equation for continuous outcome below we can calculate the sample size needed for the above study.
n = 2[(a+b)2σ2]/(μ1-μ2)2 where
n = sample size for each group
μ1 = population mean of systolic blood pressures in intervention group
μ2 = population mean of systolic blood pressures in control group
μ1- μ2 = desired difference in mean systolic blood pressures between groups
σ = population variance
a = multiplier for significance level (or alpha)
b = multiplier for power (or 1-beta)
Providing the values in the equation would give the sample size (n) of 28 samples per group as the result
n = 2[(1.96+0.842)2(202)]/152 or 28 samples per group
(b) Systolic blood pressure as a categorical outcome measured as below or above 140 mmHg (i.e., hypertension yes/no)
In this example a systolic blood pressure from a sample that is above 140 mmHg is considered an event of the patient with hypertension. Based on published literature the proportion of patients in the general population with hypertension is 30%. The evaluator wishes to detect a clinically relevant difference of 10% in systolic blood pressure as an outcome between the intervention group with cds and the control group without cds . This means the expected proportion of patients with hypertension is 20% (p1 = 0.2) in the intervention group and 30% (p2 = 0.3) in the control group. Assuming a significance level or alpha of 0.05 for 2-tailed t -test and power of 0.80 the corresponding multipliers are 1.96 and 0.842, respectively. Using the sample size equation for categorical outcome below, we can calculate the sample size needed for the above study.
n = [(a+b)2(p1q1+p2q2)]/χ2
p1 = proportion of patients with hypertension in intervention group
q1 = proportion of patients without hypertension in intervention group (or 1-p1)
p2 = proportion of patients with hypertension in control group
q2 = proportion of patients without hypertension in control group (or 1-p2)
χ = desired difference in proportion of hypertensive patients between two groups
Providing the values in the equation would give the sample size (n) of 291 samples per group as the result
n = [(1.96+0.842)2((0.2)(0.8)+(0.3)(0.7))]/(0.1)2 or 291 samples per group
From Table 3 on p. 1392 of Noordzij et al. (2010).
This publication is licensed under a Creative Commons License, Attribution-Noncommercial 4.0 International License (CC BY-NC 4.0): see https://creativecommons.org/licenses/by-nc/4.0/
- Cite this Page Lau F, Holbrook A. Chapter 10 Methods for Comparative Studies. In: Lau F, Kuziemsky C, editors. Handbook of eHealth Evaluation: An Evidence-based Approach [Internet]. Victoria (BC): University of Victoria; 2017 Feb 27.
- PDF version of this title (4.5M)
- Disable Glossary Links
In this Page
- Introduction
- Types of Comparative Studies
- Methodological Considerations
- Case Examples
- Example of Sample Size Calculation
Related information
- PMC PubMed Central citations
- PubMed Links to PubMed
Recent Activity
- Chapter 10 Methods for Comparative Studies - Handbook of eHealth Evaluation: An ... Chapter 10 Methods for Comparative Studies - Handbook of eHealth Evaluation: An Evidence-based Approach
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers
- Utility Menu
GA4 Tracking Code
Gen ed writes, writing across the disciplines at harvard college.
- Comparative Analysis
What It Is and Why It's Useful
Comparative analysis asks writers to make an argument about the relationship between two or more texts. Beyond that, there's a lot of variation, but three overarching kinds of comparative analysis stand out:
- Coordinate (A ↔ B): In this kind of analysis, two (or more) texts are being read against each other in terms of a shared element, e.g., a memoir and a novel, both by Jesmyn Ward; two sets of data for the same experiment; a few op-ed responses to the same event; two YA books written in Chicago in the 2000s; a film adaption of a play; etc.
- Subordinate (A → B) or (B → A ): Using a theoretical text (as a "lens") to explain a case study or work of art (e.g., how Anthony Jack's The Privileged Poor can help explain divergent experiences among students at elite four-year private colleges who are coming from similar socio-economic backgrounds) or using a work of art or case study (i.e., as a "test" of) a theory's usefulness or limitations (e.g., using coverage of recent incidents of gun violence or legislation un the U.S. to confirm or question the currency of Carol Anderson's The Second ).
- Hybrid [A → (B ↔ C)] or [(B ↔ C) → A] , i.e., using coordinate and subordinate analysis together. For example, using Jack to compare or contrast the experiences of students at elite four-year institutions with students at state universities and/or community colleges; or looking at gun culture in other countries and/or other timeframes to contextualize or generalize Anderson's main points about the role of the Second Amendment in U.S. history.
"In the wild," these three kinds of comparative analysis represent increasingly complex—and scholarly—modes of comparison. Students can of course compare two poems in terms of imagery or two data sets in terms of methods, but in each case the analysis will eventually be richer if the students have had a chance to encounter other people's ideas about how imagery or methods work. At that point, we're getting into a hybrid kind of reading (or even into research essays), especially if we start introducing different approaches to imagery or methods that are themselves being compared along with a couple (or few) poems or data sets.
Why It's Useful
In the context of a particular course, each kind of comparative analysis has its place and can be a useful step up from single-source analysis. Intellectually, comparative analysis helps overcome the "n of 1" problem that can face single-source analysis. That is, a writer drawing broad conclusions about the influence of the Iranian New Wave based on one film is relying entirely—and almost certainly too much—on that film to support those findings. In the context of even just one more film, though, the analysis is suddenly more likely to arrive at one of the best features of any comparative approach: both films will be more richly experienced than they would have been in isolation, and the themes or questions in terms of which they're being explored (here the general question of the influence of the Iranian New Wave) will arrive at conclusions that are less at-risk of oversimplification.
For scholars working in comparative fields or through comparative approaches, these features of comparative analysis animate their work. To borrow from a stock example in Western epistemology, our concept of "green" isn't based on a single encounter with something we intuit or are told is "green." Not at all. Our concept of "green" is derived from a complex set of experiences of what others say is green or what's labeled green or what seems to be something that's neither blue nor yellow but kind of both, etc. Comparative analysis essays offer us the chance to engage with that process—even if only enough to help us see where a more in-depth exploration with a higher and/or more diverse "n" might lead—and in that sense, from the standpoint of the subject matter students are exploring through writing as well the complexity of the genre of writing they're using to explore it—comparative analysis forms a bridge of sorts between single-source analysis and research essays.
Typical learning objectives for single-sources essays: formulate analytical questions and an arguable thesis, establish stakes of an argument, summarize sources accurately, choose evidence effectively, analyze evidence effectively, define key terms, organize argument logically, acknowledge and respond to counterargument, cite sources properly, and present ideas in clear prose.
Common types of comparative analysis essays and related types: two works in the same genre, two works from the same period (but in different places or in different cultures), a work adapted into a different genre or medium, two theories treating the same topic; a theory and a case study or other object, etc.
How to Teach It: Framing + Practice
Framing multi-source writing assignments (comparative analysis, research essays, multi-modal projects) is likely to overlap a great deal with "Why It's Useful" (see above), because the range of reasons why we might use these kinds of writing in academic or non-academic settings is itself the reason why they so often appear later in courses. In many courses, they're the best vehicles for exploring the complex questions that arise once we've been introduced to the course's main themes, core content, leading protagonists, and central debates.
For comparative analysis in particular, it's helpful to frame assignment's process and how it will help students successfully navigate the challenges and pitfalls presented by the genre. Ideally, this will mean students have time to identify what each text seems to be doing, take note of apparent points of connection between different texts, and start to imagine how those points of connection (or the absence thereof)
- complicates or upends their own expectations or assumptions about the texts
- complicates or refutes the expectations or assumptions about the texts presented by a scholar
- confirms and/or nuances expectations and assumptions they themselves hold or scholars have presented
- presents entirely unforeseen ways of understanding the texts
—and all with implications for the texts themselves or for the axes along which the comparative analysis took place. If students know that this is where their ideas will be heading, they'll be ready to develop those ideas and engage with the challenges that comparative analysis presents in terms of structure (See "Tips" and "Common Pitfalls" below for more on these elements of framing).
Like single-source analyses, comparative essays have several moving parts, and giving students practice here means adapting the sample sequence laid out at the " Formative Writing Assignments " page. Three areas that have already been mentioned above are worth noting:
- Gathering evidence : Depending on what your assignment is asking students to compare (or in terms of what), students will benefit greatly from structured opportunities to create inventories or data sets of the motifs, examples, trajectories, etc., shared (or not shared) by the texts they'll be comparing. See the sample exercises below for a basic example of what this might look like.
- Why it Matters: Moving beyond "x is like y but also different" or even "x is more like y than we might think at first" is what moves an essay from being "compare/contrast" to being a comparative analysis . It's also a move that can be hard to make and that will often evolve over the course of an assignment. A great way to get feedback from students about where they're at on this front? Ask them to start considering early on why their argument "matters" to different kinds of imagined audiences (while they're just gathering evidence) and again as they develop their thesis and again as they're drafting their essays. ( Cover letters , for example, are a great place to ask writers to imagine how a reader might be affected by reading an their argument.)
- Structure: Having two texts on stage at the same time can suddenly feel a lot more complicated for any writer who's used to having just one at a time. Giving students a sense of what the most common patterns (AAA / BBB, ABABAB, etc.) are likely to be can help them imagine, even if provisionally, how their argument might unfold over a series of pages. See "Tips" and "Common Pitfalls" below for more information on this front.
Sample Exercises and Links to Other Resources
- Common Pitfalls
- Advice on Timing
- Try to keep students from thinking of a proposed thesis as a commitment. Instead, help them see it as more of a hypothesis that has emerged out of readings and discussion and analytical questions and that they'll now test through an experiment, namely, writing their essay. When students see writing as part of the process of inquiry—rather than just the result—and when that process is committed to acknowledging and adapting itself to evidence, it makes writing assignments more scientific, more ethical, and more authentic.
- Have students create an inventory of touch points between the two texts early in the process.
- Ask students to make the case—early on and at points throughout the process—for the significance of the claim they're making about the relationship between the texts they're comparing.
- For coordinate kinds of comparative analysis, a common pitfall is tied to thesis and evidence. Basically, it's a thesis that tells the reader that there are "similarities and differences" between two texts, without telling the reader why it matters that these two texts have or don't have these particular features in common. This kind of thesis is stuck at the level of description or positivism, and it's not uncommon when a writer is grappling with the complexity that can in fact accompany the "taking inventory" stage of comparative analysis. The solution is to make the "taking inventory" stage part of the process of the assignment. When this stage comes before students have formulated a thesis, that formulation is then able to emerge out of a comparative data set, rather than the data set emerging in terms of their thesis (which can lead to confirmation bias, or frequency illusion, or—just for the sake of streamlining the process of gathering evidence—cherry picking).
- For subordinate kinds of comparative analysis , a common pitfall is tied to how much weight is given to each source. Having students apply a theory (in a "lens" essay) or weigh the pros and cons of a theory against case studies (in a "test a theory") essay can be a great way to help them explore the assumptions, implications, and real-world usefulness of theoretical approaches. The pitfall of these approaches is that they can quickly lead to the same biases we saw here above. Making sure that students know they should engage with counterevidence and counterargument, and that "lens" / "test a theory" approaches often balance each other out in any real-world application of theory is a good way to get out in front of this pitfall.
- For any kind of comparative analysis, a common pitfall is structure. Every comparative analysis asks writers to move back and forth between texts, and that can pose a number of challenges, including: what pattern the back and forth should follow and how to use transitions and other signposting to make sure readers can follow the overarching argument as the back and forth is taking place. Here's some advice from an experienced writing instructor to students about how to think about these considerations:
a quick note on STRUCTURE
Most of us have encountered the question of whether to adopt what we might term the “A→A→A→B→B→B” structure or the “A→B→A→B→A→B” structure. Do we make all of our points about text A before moving on to text B? Or do we go back and forth between A and B as the essay proceeds? As always, the answers to our questions about structure depend on our goals in the essay as a whole. In a “similarities in spite of differences” essay, for instance, readers will need to encounter the differences between A and B before we offer them the similarities (A d →B d →A s →B s ). If, rather than subordinating differences to similarities you are subordinating text A to text B (using A as a point of comparison that reveals B’s originality, say), you may be well served by the “A→A→A→B→B→B” structure.
Ultimately, you need to ask yourself how many “A→B” moves you have in you. Is each one identical? If so, you may wish to make the transition from A to B only once (“A→A→A→B→B→B”), because if each “A→B” move is identical, the “A→B→A→B→A→B” structure will appear to involve nothing more than directionless oscillation and repetition. If each is increasingly complex, however—if each AB pair yields a new and progressively more complex idea about your subject—you may be well served by the “A→B→A→B→A→B” structure, because in this case it will be visible to readers as a progressively developing argument.
As we discussed in "Advice on Timing" at the page on single-source analysis, that timeline itself roughly follows the "Sample Sequence of Formative Assignments for a 'Typical' Essay" outlined under " Formative Writing Assignments, " and it spans about 5–6 steps or 2–4 weeks.
Comparative analysis assignments have a lot of the same DNA as single-source essays, but they potentially bring more reading into play and ask students to engage in more complicated acts of analysis and synthesis during the drafting stages. With that in mind, closer to 4 weeks is probably a good baseline for many single-source analysis assignments. For sections that meet once per week, the timeline will either probably need to expand—ideally—a little past the 4-week side of things, or some of the steps will need to be combined or done asynchronously.
What It Can Build Up To
Comparative analyses can build up to other kinds of writing in a number of ways. For example:
- They can build toward other kinds of comparative analysis, e.g., student can be asked to choose an additional source to complicate their conclusions from a previous analysis, or they can be asked to revisit an analysis using a different axis of comparison, such as race instead of class. (These approaches are akin to moving from a coordinate or subordinate analysis to more of a hybrid approach.)
- They can scaffold up to research essays, which in many instances are an extension of a "hybrid comparative analysis."
- Like single-source analysis, in a course where students will take a "deep dive" into a source or topic for their capstone, they can allow students to "try on" a theoretical approach or genre or time period to see if it's indeed something they want to research more fully.
- DIY Guides for Analytical Writing Assignments

- Types of Assignments
- Unpacking the Elements of Writing Prompts
- Formative Writing Assignments
- Single-Source Analysis
- Research Essays
- Multi-Modal or Creative Projects
- Giving Feedback to Students
Assignment Decoder
All Formats
Table of Contents
Comparative research ideas and examples, comparative research proposal ideas and examples, comparative research analysis ideas and examples, comparative market research ideas and examples, comparative case study research ideas and examples, comparative research essay ideas and examples, business comparative research ideas and examples, comparative research study ideas and examples, small business comparative research ideas and examples, comparative research outline ideas and examples, comparative research strategy ideas and examples, comparative research ideas faqs, comparative research ideas.
Comparative research is not merely some simple formula you can use to identify the similarities and dissimilarities of two variables but also to fully analyze and draw conclusions out of it. With unique conceptual frameworks, characteristics, subjects, and overall research design to work with, expect plentiful comparative research ideas to take inspiration from.

What are examples of variables in comparative research?
What are the parts of comparative research, how many variables are compared in comparative research, is comparative research simple, is causal-comparative research experimental, what do you call a study that observes groups of people, what are the two main types of research, how many slides work best for a comparative study presentation, how long should a comparative study be conducted, what are the three kinds of experimental research designs, more in documents, comparative case study research template, comparative research proposal template, college research template, research template, project research template, sales retargeting research template, sales customer behavior research template, email marketing research on open rates by industry template, recruitment roi research hr template, biography research template.
- How To Create a Schedule in Microsoft Word [Template + Example]
- How To Create a Schedule in Google Docs [Template + Example]
- How To Create a Quotation in Google Docs [Template + Example]
- How To Create a Quotation in Microsoft Word [Template + Example]
- How To Make a Plan in Google Docs [Template + Example]
- How To Make a Plan in Microsoft Word [Template + Example]
- How To Make/Create an Inventory in Google Docs [Templates + Examples]
- How To Create Meeting Minutes in Microsoft Word [Template + Example]
- How To Create Meeting Minutes in Google Docs [Template + Example]
- How To Make/Create an Estimate in Microsoft Word [Templates + Examples] 2023
- How To Make/Create an Estimate in Google Docs [Templates + Examples] 2023
- How To Make/Create a Manual in Google Docs [Templates + Examples] 2023
- How To Make/Create a Manual in Microsoft Word [Templates + Examples] 2023
- How To Make/Create a Statement in Google Docs [Templates + Examples] 2023
- How To Make/Create a Statement in Microsoft Word [Templates + Examples] 2023
File Formats
Word templates, google docs templates, excel templates, powerpoint templates, google sheets templates, google slides templates, pdf templates, publisher templates, psd templates, indesign templates, illustrator templates, pages templates, keynote templates, numbers templates, outlook templates.
- Contact sales (+234) 08132546417
- Have a questions? [email protected]
- Latest Projects
Project Materials
A step-by-step guide to writing a comparative analysis.

Click Here to Download Now.
Do You Have New or Fresh Topic? Send Us Your Topic
How to write a comparative analysis.
Writing a comparative review in a research paper is not as difficult as many people might tend to think. With some tips, it is possible to write an outstanding comparative review. There are steps that must be utilized to attain this result. They are as detailed in this article.
Within the literary, academic, and journalistic world, analysis allows exposing ideas and arguments in front of a context, making it an important material for discussion within the professional work.
Within this genre, we can find a comparative analysis. For some authors, the comparative essay is defined as the text where two opposing positions are proposed or where two theses are verified. Through this comparison, the author intends to make the reader reflect on a specific topic. It consists of giving a written opinion about two positions, which are compared between them to conclude. Do you know how to write a comparative essay? In this article, we will explain step by step how to do it.
So, let’s see the guidelines that you must follow to achieve a good comparative analysis .
How to write a good comparative analysis
The structure.
In general, the approach is developed in the first paragraph or at the beginning of the work. Its objective is to propose the author’s position regarding a specific subject. Generally, this approach specifies the objective to be achieved. You must be clear about what topic you are going to deal with, what you want to explain, and what the perspectives will be to use in your comparative analysis, and you must also define who you write for.
As it is a comparative text, it begins with a general observation that can serve as a context for both approaches, then begins by establishing the arguments in each of the two cases. Do not forget to compare both objects of study according to each argument or idea to develop.
Let it be the reader himself who finds or defines his position in this essay and choose one of the two alternatives.
In this entry, there are two possibilities of approach: one deductive and the other inductive. The deductive method raises the issue, and you use your analysis of the variables leading, guiding the reader to draw their conclusions or fix a position on the issue. While the inductive method starts with argument, developing each of the variables until reaching the topic’s approach or problem. The two ways of approaching the subject are viable. Choose the one that is easiest for you to work with.
At the end of this section, your audience should:
- First of all, have a clear understanding of what topics you will cover in your essay, what you want to explain, and under what positions or perspectives you will do it. It begins with a general observation that establishes the similarity between the two subjects and then moves the essay’s focus to the concrete.
- The reader should understand which points will be examined and which points will not be examined in the comparison. At the end of the introduction, state your preference, or describe the two subjects’ meaning.
- Your readers should be able to describe the ideas you are going to treat. Make a detailed exposition of its characteristics, history, consequences, and development that you consider appropriate. Your comparative analysis should expose the characteristics of the second position on which you want to speak as much as in the first one.
Development of body
Generally, in the body of the essay, the author presents all the arguments that support his thesis, which gives him a reflective and justifying body of the author’s initial statement. Depending on the length of the work, which can range from two to 15 pages, each paragraph or before a title corresponds to an argument’s development.
After speaking on the subject, the author must close the essay, must conclude, must show the findings of his work, and/or show the conclusions he reached. You must write a final closing paragraph, as a conclusion, in which you expose a confrontation between the two positions. Try to create a fight between them so that the reader gets involved. The conclusion should give a brief and general summary of the most important similarities and differences. It should end with a personal statement, an opinion, and the “what then?” – what is important about the two things being compared.
Readers should be left feeling that all the different threads of this essay have been put together coherently, that they have learned something – and they must be sure that this is the end – that they do not look around for pages missing. And finally, your assessment must explain what position you stand in solidarity and why you prefer it to the other.
Examples of how to write a comparative analysis
Paragraph 1: Messi’s preferred position / Ronaldo’s preferred position.
Paragraph 2: Messi’s play style / Ronaldo’s play style.
Paragraph 3: Messi aerial game / Ronaldo aerial game.
Paragraph 1: Messi teamwork .
Paragraph 2: Ronaldo’s teamwork.
Paragraph 3: Messi stopped the ball.
Paragraph 4: Ronaldo’s stopped the ball.
Paragraph 5: Messi’s achievements.
Paragraph 6: Ronaldo’s achievements.
Few Important Rules for Comparative analysis
Even if the exercise sounds simple, there are a few rules that should be followed to help your audience as best as possible make the best decision.
1. Clearly state your position
The first question is, “Why are you doing a comparison analysis”? To highlight your view or ideas over another, or simply to compare two (or more) solutions that do not belong to you? It is imperative that you clearly state your position to your reader, so does your credibility.
Be honest and state, for example:
- The idea you are trying to espouse
- The framework you are using
- The reason why you are doing this comparison, the objective
In addition to the above, you must be consistent with the exposition of your ideas.
2. Stay objective
Even if you include your personal ideology in your comparison, stay as objective as possible. Your readers will not appreciate it when you point out all the disadvantages of one idea while you display the advantages of the other. Your comparison will turn into advertising. You have to raise weak points and strong points on both sides.
These analyses are always subjective, so you have to clarify which position convinces you the most.
3. Think about audience’ expectations
The research paper is intended for your readers, which means that you must take their expectations into account when writing your review. Put aside your desire to sell your desired idea, and take your readers’ perspective:
- What information are they interested in?
- What are their criteria?
- What do they want to know?
- What do they want from the product or service?
Again, it is about being objective in all your statements.
Do You Have New or Fresh Topic? Send Us Your Topic
4. Organize information
For your readers to want to read your comparative analysis, it is important to structure your comments. The idea is to make it easy for your readers to navigate your paper and get them to find the information that interests them quickly.
5. End with a conclusion
You’ve tried to be as objective as possible throughout your comparison, and now is the time to let go like we have mentioned many times in this post. In your conclusion, you can go directly to your readers and give your opinion. With a few tips, you can also encourage them to go towards one or the other idea.
Note: If time is not an issue, the best way to review the essay is to leave it for one day. Go for a walk, eat something, have fun, and forget. Then it’s time to go back to the text, find problems, and fix them. This must be done separately, that is, first find all the problems you can without correcting them. Although the idea of doing it at the same time is tempting, it is smarter to do it separately. It is effective and fast.
Tips on Comparative analysis
Be concise or accurate in your analysis and dissertation of the topic.
Sometimes the authors believe that the more elaborate the language and the more extensive the writing, the better the writers or essayists. On the contrary, a good essay refers to the exact analysis of a topic, where the reader can dynamically advance the work and understand the author’s position.
Use only the arguments necessary for the explanation of the topic, do not talk too much. You run the risk of redundant or repetitive, which makes the text-heavy both when reading it and understanding it.
Write in Short Sentences
Just as we recommend that you do not redound in your texts, we also encourage you to write with short sentences. They give dynamism to the text. Communication is direct. The reader advances in the text and understands much more.
Include Reflections in Your Text
Supporting your approach with reflections or quotes from authors makes your essay more important. Above all, use those arguments that justify or give strength to your position regarding one thesis or the other.
Text Revision
Since comparative analysis can tend to be a subjective work, you must let it “sit” for a day or a few hours and read it again. This exercise will allow you to make corrections. Modify those aspects that are not clear enough for you. And you can improve it, in a few words. Once you do this exercise, just like this, you can submit it.
Not What You Were Looking For? Send Us Your Topic
INSTRUCTIONS AFTER PAYMENT
- 1.Your Full name
- 2. Your Active Email Address
- 3. Your Phone Number
- 4. Amount Paid
- 5. Project Topic
- 6. Location you made payment from
» Send the above details to our email; [email protected] or to our support phone number; (+234) 0813 2546 417 . As soon as details are sent and payment is confirmed, your project will be delivered to you within minutes.
Latest Updates
An investigation into the effect of teachers motivation on the academic achievement of students, effect of globalization on nigeria small and medium scale industry, effect of training and development on employees productivity in the milling industry, leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
This site uses Akismet to reduce spam. Learn how your comment data is processed .
Advertisements
- Hire A Writer
- Plagiarism Research Clinic
- International Students
- Project Categories
- WHY HIRE A PREMIUM RESEARCHER?
- UPGRADE PLAN
- PROFESSIONAL PLAN
- STANDARD PLAN
- MBA MSC STANDARD PLAN
- MBA MSC PROFESSIONAL PLAN
3. Comparative Research Methods
This chapter examines the ‘art of comparing’ by showing how to relate a theoretically guided research question to a properly founded research answer by developing an adequate research design. It first considers the role of variables in comparative research, before discussing the meaning of ‘cases’ and case selection. It then looks at the ‘core’ of the comparative research method: the use of the logic of comparative inquiry to analyse the relationships between variables (representing theory), and the information contained in the cases (the data). Two logics are distinguished: Method of Difference and Method of Agreement. The chapter concludes with an assessment of some problems common to the use of comparative methods.
- Related Documents
3. Comparative research methods
This chapter examines the ‘art of comparing’ by showing how to relate a theoretically guided research question to a properly founded research answer by developing an adequate research design. It first considers the role of variables in comparative research before discussing the meaning of ‘cases’ and case selection. It then looks at the ‘core’ of the comparative research method: the use of the logic of comparative inquiry to analyse the relationships between variables (representing theory) and the information contained in the cases (the data). Two logics are distinguished: Method of Difference and Method of Agreement. The chapter concludes with an assessment of some problems common to the use of comparative methods.
Rethinking Comparison
Qualitative comparative methods – and specifically controlled qualitative comparisons – are central to the study of politics. They are not the only kind of comparison, though, that can help us better understand political processes and outcomes. Yet there are few guides for how to conduct non-controlled comparative research. This volume brings together chapters from more than a dozen leading methods scholars from across the discipline of political science, including positivist and interpretivist scholars, qualitative methodologists, mixed-methods researchers, ethnographers, historians, and statisticians. Their work revolutionizes qualitative research design by diversifying the repertoire of comparative methods available to students of politics, offering readers clear suggestions for what kinds of comparisons might be possible, why they are useful, and how to execute them. By systematically thinking through how we engage in qualitative comparisons and the kinds of insights those comparisons produce, these collected essays create new possibilities to advance what we know about politics.
PERAN PEMUDA RELAWAN DEMOKRASI DALAM MENINGKATKAN PARTISIPASI POLITIK MASYARAKAT PADA PEMILIHAN UMUM LEGISLATIF TAHUN 2014 DAN IMPLIKASINYA TERHADAP KETAHANAN POLITIK WILAYAH (STUDI PADA RELAWAN DEMOKRASI BANYUMAS, JAWA TENGAH)
This research was going to described the role of Banyumas Democracy Volunteer ( Relawan Demokrasi Banyumas) in increasing political public partitipation in Banyumas’s legislative election 2014 and its implication to Banyumas’s political resilience. This research used qualitative research design as a research method. Data were collected by in depth review, observation and documentation. This research used purpossive sampling technique with stakeholder sampling variant to pick informants. The research showed that Banyumas Democracy Volunteer had a positive role in developing political resilience in Banyumas. Their role was gave political education and election education to voters in Banyumas. In the other words, Banyumas Democracy Volunteer had a vital role in developing ideal political resilience in Banyumas.Keywords: Banyumas Democracy Volunteer, Democracy, Election, Political Resilience of Region.
Ezer Kenegdo: Eksistensi Perempuan dan Perannya dalam Keluarga
AbstractPurpose of this study was to describe the meaning of ezer kenegdo and to know position and role of women in the family. The research method used is qualitative research methods (library research). The term of “ ezer kenegdo” refer to a helper but her position withoutsuperiority and inferiority. “The patner model” between men and women is uderstood in relation to one another as the same function, where differences are complementary and mutually beneficial in all walks of life and human endeavors.Keywords: Ezer Kenegdo; Women; Family.AbstrakTujuan penulisan artikel ini adalah untuk mendeskripsikan pengertian ezer kenegdo dan mengetahui kedudukan dan peran perempuan dalam keluarga. Metode yang digunakan adalah metode kualitatif library research. Ungkapan “ezer kenegdo” menunjuk pada seorang penolong namun kedudukannya adalah setara tanpa ada superioritas dan inferioritas. “Model kepatneran” antara laki-laki dan perempuan dipahami dengan hubungan satu dengan yang lain sebagai fungsi yang sama, yang mana perbedaan adalah saling melengkapi dan saling menguntungkan dalam semua lapisan kehidupan dan usaha manusia.Kata Kunci: Ezer Kenegdo, Prerempuan, Keluarga.
Commentary on ‘Opportunities and Challenges of Engaged Indigenous Scholarship’ (Van de Ven, Meyer, & Jing, 2018)
The mission ofManagement and Organization Review, founded in 2005, is to publish research about Chinese management and organizations, foreign organizations operating in China, or Chinese firms operating globally. The aspiration is to develop knowledge that is unique to China as well as universal knowledge that may transcend China. Articulated in the first editorial published in the inaugural issue of MOR (2005) and further elaborated in a second editorial (Tsui, 2006), the question of contextualization is framed, discussing the role of context in the choices of the research question, theory, measurement, and research design. The idea of ‘engaged indigenous research’ by Van de Ven, Meyer, and Jing (2018) describes the highest level of contextualization, with the local context serving as the primary factor guiding all the decisions of a research project. Tsui (2007: 1353) refers to it as ‘deep contextualization’.
PERAN DINAS KESEHATAN DALAM MENANGGULANGI GIZI BURUK ANAK DI KECAMATAN NGAMPRAH KABUPATEN BANDUNG BARAT
The title of this research is "The Role of the Health Office in Tackling Child Malnutrition in Ngamprah District, West Bandung Regency". The problem in this research is not yet optimal implementation of the Health Office in Overcoming Malnutrition in Children in Ngamprah District, West Bandung Regency. The research method that researchers use is descriptive research methods with a qualitative approach. The technique of determining the informants used was purposive sampling technique. The results showed that in carrying out its duties and functions, the health office, the Health Office had implemented a sufficiently optimal role seen from the six indicators of success in overcoming malnutrition, namely: All Posyandu carry out weighing operations at least once a month All toddlers are weighed, All cases of malnutrition are referred to the Puskemas Nursing or Home Sick, all cases of malnutrition are treated at the health center. Nursing or hospitalization is handled according to the management of malnutrition. All post-treatment malnourished toddlers receive assistance.
Jazz jem sessions in the aspect of listener perception
The purpose of the article is to identify the characteristic features ofjazz jam sessions as creative and concert events. The research methods arebased on the use of a number of empirical approaches. The historicalmethod has characterized the periodization of the emergence andpopularity of jam session as an artistic phenomenon. The use of themethod of comparison of jazz jam sessions and jazz concert made itpossible to determine the characteristic features of jams. An appeal toaxiological research methods has identified the most strikingimprovisational solos of leading jazz artists. Of particular importance inthe context of the article are the methods of analysis and synthesis,observation and generalization. It is important to pay attention to the use ofa structural-functional scientific-research method that indicates theeffectiveness of technological and execution processes on jams. Scientificinnovation. The article is about discovering the peculiarities of the jamsession phenomenon and defining the role of interaction between theaudience of improviser listeners and musicians throughout the jams. Theprocesses of development of jazz concerts and improvisations at jamsessions are revealed. Conclusions. The scientific research providedconfirms the fact that system of interactions between musicians amongthemselves and the audience, as well as improvisation of the performers atthe jam sessions is immense and infinite. That is why modern jazz singersand the audience will always strive for its development and understanding.This way is worth starting with repeated listening to improvisation, in theimmediate presence of the jam sessions (both participant and listener).
THE ROLE OF TECHNOLOGY INFORMATION SYSTEMS AND APPLICATION OF SAK ETAP ON DEVELOPMENT MODEL FINANCIAL POSITION REPORT
Bina Siswa SMA Plus Cisarua addressing in Jl. colonel canal masturi no. 64. At the time of document making, record-keeping of transaction relating to account real or financial position report account especially, Bina Siswa SMA Plus Cisarua has applied computer that is by using the application of Microsoft Office Word 2007 and Microsoft Excel 2007, in practice of control to relative financial position report account unable to be added with the duration process performed within financial statement making. For the problems then writer takes title: “The Role Of Technology Information Systems And Aplication Of SAK ETAP On Development Model Financial Position Report”. Research type which writer applies is research type academy, data type which writer applies is qualitative data and quantitative data, research design type which writer applies is research design deskriptif-analistis, research method which writer applies is descriptive research method, survey and eksperiment, data collecting technique which writer applies is field researcher what consisted of interview and observation library research, system development method which writer applies is methodologies orienting at process, data and output. System development structure applied is Iterasi. Design of information system applied is context diagram, data flow diagram, and flowchart. Design of this financial position report accounting information system according to statement of financial accounting standard SAK ETAP and output consisted of information of accumulated fixed assets, receivable list, transaction summary of cash, transaction summary of bank and financial position report.
Dilema Hakim Pengadilan Agama dalam Menyelesaikan Perkara Hukum Keluarga Melalui Mediasi
This article aims to determine the role of judges in resolving family law cases through mediation in the Religious Courts, where judges have the position as state officials as regulated in Law Number 43 of 1999 concerning Basic Personnel, can also be a mediator in the judiciary. as regulated in Supreme Court Regulation Number 1 of 2016 concerning Mediation Procedures where judges have the responsibility to seek peace at every level of the trial and are also involved in mediation procedures. The research method used in this article uses normative legal research methods. Whereas until now judges still have a very important role in resolving family law cases in the Religious Courts due to the fact that there are still many negotiating processes with mediation assisted by judges, even though on the one hand the number of non-judge mediators is available, although in each region it is not evenly distributed in terms of number and capacity. non-judge mediator.
Anime affection on human IQ and behavior in Saudi Arabia
The present study attempted to determine the effects of watching anime and understanding if watching anime could affect the mental and social aspects of kids or other group of ages, and also to decide that the teenagers and children should watch anime or not. The research design used in this study is the descriptive research method and observational where in data and facts from direct observations and online questionnaires were used to answer the research question. The finding of this study suggested that anime viewers has higher level of general knowledge comparing with the non- anime viewers and as well as higher IQ level significantly in a specific group, besides anime can be used to spread a background about any culture and plays a role in increase the economy.
Export Citation Format
Share document.
- AI Content Shield
- AI KW Research
- AI Assistant
- SEO Optimizer
- AI KW Clustering
- Customer reviews
- The NLO Revolution
- Press Center
- Help Center
- Content Resources
- Facebook Group
An Effective Guide to Comparative Research Questions
Table of Contents
Comparative research questions are a type of quantitative research question. It aims to gather information on the differences between two or more research objects based on different variables.
These kinds of questions assist the researcher in identifying distinctive characteristics that distinguish one research subject from another.
A systematic investigation is built around research questions. Therefore, asking the right quantitative questions is key to gathering relevant and valuable information that will positively impact your work.
This article discusses the types of quantitative research questions with a particular focus on comparative questions.
What Are Quantitative Research Questions?
Quantitative research questions are unbiased queries that offer thorough information regarding a study topic . You can statistically analyze numerical data yielded from quantitative research questions.
This type of research question aids in understanding the research issue by examining trends and patterns. The data collected can be generalized to the overall population and help make informed decisions.

Types of Quantitative Research Questions
Quantitative research questions can be divided into three types which are explained below:
Descriptive Research Questions
Researchers use descriptive research questions to collect numerical data about the traits and characteristics of study subjects. These questions mainly look for responses that bring into light the characteristic pattern of the existing research subjects.
However, note that the descriptive questions are not concerned with the causes of the observed traits and features. Instead, they focus on the “what,” i.e., explaining the topic of the research without taking into account its reasons.
Examples of Descriptive research questions:
- How often do you use our keto diet app?
- What price range are you ready to accept for this product?
Comparative Research Questions
Comparative research questions seek to identify differences between two or more distinct groups based on one or more dependent variables. These research questions aim to identify features that differ one research subject from another while emphasizing their apparent similarities.
In market research surveys, asking comparative questions can reveal how your product or service compares to its competitors. It can also help you determine your product’s benefits and drawbacks to gain a competitive edge.
The steps in formulating comparative questions are as follows:
- Choose the right starting phrase
- Specify the dependent variable
- Choose the groups that interest you
- Identify the relevant adjoining text
- Compose the comparative research question
Relationship-Based Research Questions
A relationship-based research question refers to the nature of the association between research subjects of the same category. These kinds of research question assist you in learning more about the type of relationship between two study variables.
Because they aim to distinctly define the connection between two variables, relationship-based research questions are also known as correlational research questions.
Examples of Comparative Research Questions
- What is the difference between men’s and women’s daily caloric intake in London?
- What is the difference in the shopping attitude of millennial adults and those born in 1980?
- What is the difference in time spent on video games between people of the age group 15-17 and 18-21?
- What is the difference in political views of Mexicans and Americans in the US?
- What are the differences between Snapchat usage of American male and female university students?
- What is the difference in views towards the security of online banking between the youth and the seniors?
- What is the difference in attitude between Gen-Z and Millennial toward rock music?
- What are the differences between online and offline classes?
- What are the differences between on-site and remote work?
- What is the difference between weekly Facebook photo uploads between American male and female college students?
- What are the differences between an Android and an Apple phone?
Comparative research questions are a great way to identify the difference between two study subjects of the same group.
Asking the right questions will help you gain effective and insightful data to conduct your research better . This article discusses the various aspects of quantitative research questions and their types to help you make data-driven and informed decisions when needed.

Abir Ghenaiet
Abir is a data analyst and researcher. Among her interests are artificial intelligence, machine learning, and natural language processing. As a humanitarian and educator, she actively supports women in tech and promotes diversity.
Explore All Engaging Questions Tool Articles
Consider these fun questions about spring.
Spring is a season in the Earth’s yearly cycle after Winter and before Summer. It is the time life and…
- Engaging Questions Tool
Fun Spouse Game Questions For Couples
Answering spouse game questions together can be fun. It’ll help begin conversations and further explore preferences, history, and interests. The…
Best Snap Game Questions to Play on Snapchat
Are you out to get a fun way to connect with your friends on Snapchat? Look no further than snap…
How to Prepare for Short Response Questions in Tests
When it comes to acing tests, there are a few things that will help you more than anything else. Good…
Top 20 Reflective Questions for Students
As students, we are constantly learning new things. Every day, we are presented with further information and ideas we need…
Random History Questions For History Games
A great icebreaker game is playing trivia even though you don’t know the answer. It is always fun to guess…

Blog abour Writing Research Papers
College Students

How to Write a Comparative Research Paper
If you’re trying to figure out how to write a comparative research paper, you’ve come to the right place. Here, you’ll learn about the Structure of such an essay, the Grounds for comparison, and how to find the points of comparison. After you know what makes a good comparative essay, you’ll be ready to begin writing! Keep reading for some helpful tips! You’ll be on your way to writing an outstanding paper in no time.
Structure of a comparative research paper
A good comparative research paper has a clear structure. The first paragraph starts with a topic sentence, the middle paragraph presents the information, and the last paragraph draws a low-level conclusion. While it may seem like the conclusion paragraph should make the most general point, the essay’s final paragraph should be specific and make a point. For most papers, a structure is the key to a good paper.
Regardless of the purpose, an effective comparative essay must have a logical organization. The comparisons should flow from one point to the next without confusing the reader. For example, a comparative essay on French and Russian revolutions would compare innovations in new technology, military strategy, and the administrative system. There are other ways to structure a comparative essay. To write an effective essay, follow the suggested structure.
Grounds for comparison in a comparative essay
Comparative essays require the writer to compare two items or axes. While it is possible to compare more than two items, the comparison has to be interesting and compelling. In order to succeed at this, you should make sure that your subjects differ enough from one another to make the comparison worthwhile. Here are some tips to help you create a compelling comparative essay. The purpose of a comparative essay is to show the reader something about the world around us that is interesting and different.
While writing a comparative essay, the most important thing to remember is to keep the flow of your writing logical. Do not make random comparisons between items. They will end up confusing the reader and losing their interest in the essay. To keep your essay organized, you can use two different formats: comparative and non-comparative essays. Each of them has different advantages and disadvantages and can be compared.
The proper use of tables and graphs is essential to the overall impact of a comparative research paper. Tables and graphs are crucial to the presentation of research results because they summarize data collected by a researcher. Properly prepared tables and graphs enable researchers to present a wide range of information about many individuals and groups, making their findings more appealing and easy to understand. Tables and graphs are essential tools of the scientific research process, and authors of research papers must master the art of table and graph creation. Listed below are some guidelines for table preparation.
Use descriptive titles for each table and graph. Repetition in tables and figures can hinder communication. Make sure to include only those that highlight the most important findings in each category. Do not repeat exact values. This defeats the purpose of the table. Use descriptive titles instead. Make sure to leave plenty of room between columns and graphs. Avoid overlapping columns, too. Moreover, use subheadings to make the information more accessible.
Finding points of comparison in a comparative essay
There are many different ways to find points of comparison in a comparative essay, and it is important to follow a systematic approach to comparing things. Once you have decided which two subjects you’ll be comparing, you must carefully select your parameters and items to evaluate. Be sure to address each one of these combinations in turn to ensure that the comparative essay makes a valid comparison. The following tips will help you to write a more effective comparative essay.
Identifying the subjects of comparison in a comparative essay is critical to the overall success of the paper. The best comparative essays are based on two axes that are related in some way, whether they’re different in size, form, or function. Once you’ve defined your points of comparison, you can then begin developing your argument. A good comparison should include one or two aspects of each subject, rather than comparing the two topics comprehensively. However, research is not necessary for every assignment. Historical events, science-related topics, and social issues may require research, while comparative essays about literature are less likely to need it.
Developing a thesis
Developing a thesis for a comparativa research paper involves the process of determining which topic or topics to discuss. The paper should follow the order of the questions and present the student’s best thinking on the subject matter. The student should base the paper response on research and course material to ensure that it is clear and reflects their own thought process. The paper will get more complex and sophisticated as the paper progresses.
When composing a comparative essay, the thesis must express the writer’s perspective on the topic. To do this, the introduction of the essay should include a thesis statement. This statement sums up the comparison between two different objects and presents the writer’s point of view. For example, a greenhouse rose purchased from a florist is likely to be more appealing than a rose from a garden. The writer will then prove his thesis in the body of the paper.
You might also like

How Long to Write a Research Paper?

How Long Does It Take To Write A Research Paper?

How Do I Write a Reflection Paper?
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.

How to Write a Competitive Title Analysis

The following post has been excerpted and adapted from The Author Training Manual by Nina Amir, recently released by Writer’s Digest Books.
If you’re embarking on a nonfiction book project, your analysis of the competitive landscape is critical, whether you self-publish or traditionally publish. You need to understand and be able to explain how your book stacks up against all the others.
If you pitch your book to editors and agents, one component of your book proposal [ see Jane’s 101 post on book proposals ] is the competitive title analysis. The goal is to evaluate how unique and necessary your book is in the marketplace, or how to make it so.
Where in a bookstore will you find your book shelved? (Examples: Religion, History, Business, Self-Help.) If you don’t know, ask a bookstore clerk or a librarian. Tell them about your book, and ask where it would be located or how it would be categorized. Then focus your competitive title search on this particular category.
Look for competing titles in bricks-and-mortar bookstores, libraries, online bookstores, and online community sites—including Amazon, Barnes & Noble, LibraryThing, Goodreads, Redroom, BookDepository.com, and NetGalley. Don’t forget to Google your topic and see what comes up as well.
Come up with a list of 10–15 books you consider competitive or complementary to yours—books that cover the same type of information or that tell the same type of story. Then narrow the list down to 5–10 that are closest in subject matter or storyline. List these by bestseller status or by date of publication. Keep track of the following data:
- title and subtitle
- copyright year
- number of pages
- format (paperback, hardcover, etc—along with notes about any special packaging)
If you have trouble discerning whether a title belongs on this list, consider the following criteria:
- If a reader buys your book instead of another book, that other book is your competition.
- If a reader is interested in buying your book, what other books might he buy to gain different information? These are complementary titles.
You can also go to Amazon and look at the section on a particular book’s page that says: “Customers Who Bought This Item Also Bought.” These may be complementary or competing books.
For each competitive title, study the table of contents, the promises they make on their back covers, the introductions and forewords, the author’s bio, special features (quotations, a workbook element, case studies, tips, or tools), the style or tone, and so on.
Consider these factors about the competing books you have identified:
- How it is different from the book you want to write?
- How it is similar to the book you want to write?
- Is the scope of the book different? How so?
- Does it have different benefits? What are they?
- What are its pros and cons?
- How would you improve it?
- What do you like about it? Dislike?
- What promises does the author make to readers? What promises does the author fail to make that he could or should (or that you can)?
- What are the author’s credentials (or lack of credentials)?
Also study the reviews of bestselling books in your category. You can learn a lot about a book by what others say about it—and what readers think is good, bad, or missing. Look at your project and ask yourself how you can make sure your book improves on these issues—or addresses the issues in a positive manner.
In your final competitive title analysis, describe each competing book’s standout qualities, and the ways in which it is similar to your idea or how it helps readers. Then add a brief paragraph about how your book is unique or different in comparison. Don’t forget to include the basic data (publisher, copyright year, format, etc).
Compare your credentials to that of the authors of the competing books you have identified. Visit their website and social media accounts. Then consider these questions:
- How do you differ from them, or how are you similar to them?
- Will it help you or hurt you to have different qualifications or similar ones?
- Do you have the experience to join the ranks of these other authors?
- What do you need to do or be to compete with them?
- What would you have to do to make yourself stand out from the other authors?
- Do you need a larger platform? In what way?
- Do you need to write a series? Why or why not?
Based on your research, you may realize you need to make changes to your concept, such as offering a different perspective or providing more comprehensive or more timely information than other competing titles. Whether pitching to a publisher or not, your book should seek to fill a clearly identified need (or gap) in the market and have a unique selling proposition that other titles cannot match.

Nina Amir is an Amazon bestselling author of such books as How to Blog a Book and The Author Training Manual . She is known as the Inspiration-to-Creation Coach because she helps writers and other creative people combine their passion and purpose so they move from idea to inspired action. This helps them positively and meaningfully impact the world—with their words or other creations.
Nina is an international speaker, award-winning journalist, and multi-site blogger as well as the founder of National Nonfiction Writing Month and the Nonfiction Writers’ University. She also is one of three hundred elite Certified High Performance Coaches working around the world.

This site uses Akismet to reduce spam. Learn how your comment data is processed .

[…] Steven de Polo / Flickr The following post has been excerpted and adapted from The Author Training Manual by Nina Amir, recently released by Writer’s Digest Books. […]
[…] To learn to write a competitive title analysis, click here. […]
[…] How to Write a Competitive Book Analysis from Jane Friedman: If you’re embarking on a nonfiction book project, your analysis of the competitive landscape is critical, whether you self-publish or traditionally publish. You need to understand and be able to explain how your book stacks up against all the others. […]
[…] How to Write a Competitive Title Analysis by Nina Amir […]
[…] https://janefriedman.com/2014/05/20/competitive-title-analysis/ […]
[…] How to Write a Competitive Title Analysis by Nina Amir […]
[…] "How to Write a Competitive Title Analysis" by Nina Amir (click here) […]

Thank you for including this link in your course, “Introduction to Writing Book Proposal”. It offered a wealth of information! Nina, thank you for sharing your knowledge and wisdom. I will be working on your recommendations!
404 Not found
IMAGES
VIDEO
COMMENTS
2. List what you want to compare. An informative title should tell your reader exactly what you are comparing in your essay. List the subjects you want to compare so that you can make sure they are included in your title. You only need to include the broad topics or themes you want to compare, such as dogs and cats.
Best Practices in Writing an Essay for Comparative Research in Visual Arts. If you are going to write an essay for a comparative research examples paper, this section is for you. You must know that there are inevitable mistakes that students do in essay writing. To avoid those mistakes, follow the following pointers. 1.
To write a good compare-and-contrast paper, you must take your raw data—the similarities and differences you've observed —and make them cohere into a meaningful argument. Here are the five elements required. Frame of Reference. This is the context within which you place the two things you plan to compare and contrast; it is the umbrella ...
Research Paper Title. Research Paper Title is the name or heading that summarizes the main theme or topic of a research paper.It serves as the first point of contact between the reader and the paper, providing an initial impression of the content, purpose, and scope of the research.A well-crafted research paper title should be concise, informative, and engaging, accurately reflecting the key ...
Making effective comparisons. As the name suggests, comparing and contrasting is about identifying both similarities and differences. You might focus on contrasting quite different subjects or comparing subjects with a lot in common—but there must be some grounds for comparison in the first place. For example, you might contrast French ...
How to Write a Comparison Essay. Some comparison essays have ordinary titles (ex. "Two Hunters of the Savannah" or "A Comparison between Two Appalachian Dulcimers".) It may be preferable, however, if your title reflects yourattitude to the things being compared (ex. "The Zing of Irish Spring or the Love of Gentle Dove" or "the Advantages of ...
Structure of comparative research questions. There are five steps required to construct a comparative research question: (1) choose your starting phrase; (2) identify and name the dependent variable; (3) identify the groups you are interested in; (4) identify the appropriate adjoining text; and (5) write out the comparative research question. Each of these steps is discussed in turn:
The initial aim of a title is to capture the reader's attention and to highlight the research problem under investigation. Create a Working Title Typically, the final title you submit to your professor is created after the research is complete so that the title accurately captures what has been done. The working title should be developed ...
How to Write a Comparative Analysis with Examples. Writing a comparative analysis in a research paper is not as difficult as many people might tend to think. With some tips, it is possible to write an outstanding comparative review. ... Depending on the length of the work, which can range from two to 15 pages, each paragraph or before a title ...
Comparative studies in public administration and political research can be arranged along a continuum that runs from the macro-to the micro-level of analysis (cf., Levine et al. 1990).. At the macrolevel: Comparative analysis focuses on fundamental questions of government, of the public sector, etc. between and within countries by using aggregate data.
Suggested Citation:"5 Comparative Studies." National Research Council. 2004. On Evaluating Curricular Effectiveness: Judging the Quality of K-12 Mathematics Evaluations. Washington, DC: The National Academies Press. doi: 10.17226/11025. ... In nearly all studies in the comparative group, the titles of experimental curricula were explicitly ...
Comparative research is a research methodology in the social sciences exemplified in cross-cultural or comparative studies that aims to make comparisons across different countries or cultures.A major problem in comparative research is that the data sets in different countries may define categories differently (for example by using different definitions of poverty) or may not use the same ...
What makes a study comparative is not the particular techniques employed but the theoretical orientation and the sources of data. All the tools of the social scientist, including historical analysis, fieldwork, surveys, and aggregate data analysis, can be used to achieve the goals of comparative research. So, there is plenty of room for the ...
In eHealth evaluation, comparative studies aim to find out whether group differences in eHealth system adoption make a difference in important outcomes. These groups may differ in their composition, the type of system in use, and the setting where they work over a given time duration. The comparisons are to determine whether significant differences exist for some predefined measures between ...
Comparative analysis asks writers to make an argument about the relationship between two or more texts. Beyond that, there's a lot of variation, but three overarching kinds of comparative analysis stand out: Subordinate (A → B) or (B → A): Using a theoretical text (as a "lens") to explain a case study or work of art (e.g., how Anthony Jack ...
Comparative Research Ideas and Examples. Comparative research is a transformative methodology you can apply to either qualitative or quantitative research.An example of a comparative research title would have endless possibilities such as the difference between the poverty levels of countries, the salary between men and women, or even the religious aspects between communities.
Send Us Your Topic. 4. Organize information. For your readers to want to read your comparative analysis, it is important to structure your comments. The idea is to make it easy for your readers to navigate your paper and get them to find the information that interests them quickly. 5.
The chapter concludes with an assessment of some problems common to the use of comparative methods. 3. Comparative research methods. This chapter examines the 'art of comparing' by showing how to relate a theoretically guided research question to a properly founded research answer by developing an adequate research design.
This step-by-step process involves research, reading, and a critical market assessment. 1. Identify the genre, even the sub-genre, of books you will be searching for in your analysis. If you are writing a self-help book, you won't start searching in fiction or memoir. Non-fiction is the genre and more specifically the sub-genre is "self ...
The steps in formulating comparative questions are as follows: Choose the right starting phrase. Specify the dependent variable. Choose the groups that interest you. Identify the relevant adjoining text. Compose the comparative research question.
A good comparative research paper has a clear structure. The first paragraph starts with a topic sentence, the middle paragraph presents the information, and the last paragraph draws a low-level conclusion. While it may seem like the conclusion paragraph should make the most general point, the essay's final paragraph should be specific and ...
Then add a brief paragraph about how your book is unique or different in comparison. Don't forget to include the basic data (publisher, copyright year, format, etc). 4. Closely study the competing authors. Compare your credentials to that of the authors of the competing books you have identified.
Best How in Writing an Essay for Comparative Research to Visual Crafts. If you become going to write an essay forward a compares research examples journal, this section is for you. Your should know that there are inevitable mistakes ensure students do in essay writing.Go avoid which mistakes, follow the following pointers.