Jump to navigation

Cochrane Training
Chapter 14: completing ‘summary of findings’ tables and grading the certainty of the evidence.
Holger J Schünemann, Julian PT Higgins, Gunn E Vist, Paul Glasziou, Elie A Akl, Nicole Skoetz, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group (formerly Applicability and Recommendations Methods Group) and the Cochrane Statistical Methods Group
Key Points:
- A ‘Summary of findings’ table for a given comparison of interventions provides key information concerning the magnitudes of relative and absolute effects of the interventions examined, the amount of available evidence and the certainty (or quality) of available evidence.
- ‘Summary of findings’ tables include a row for each important outcome (up to a maximum of seven). Accepted formats of ‘Summary of findings’ tables and interactive ‘Summary of findings’ tables can be produced using GRADE’s software GRADEpro GDT.
- Cochrane has adopted the GRADE approach (Grading of Recommendations Assessment, Development and Evaluation) for assessing certainty (or quality) of a body of evidence.
- The GRADE approach specifies four levels of the certainty for a body of evidence for a given outcome: high, moderate, low and very low.
- GRADE assessments of certainty are determined through consideration of five domains: risk of bias, inconsistency, indirectness, imprecision and publication bias. For evidence from non-randomized studies and rarely randomized studies, assessments can then be upgraded through consideration of three further domains.
Cite this chapter as: Schünemann HJ, Higgins JPT, Vist GE, Glasziou P, Akl EA, Skoetz N, Guyatt GH. Chapter 14: Completing ‘Summary of findings’ tables and grading the certainty of the evidence. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.4 (updated August 2023). Cochrane, 2023. Available from www.training.cochrane.org/handbook .
14.1 ‘Summary of findings’ tables
14.1.1 introduction to ‘summary of findings’ tables.
‘Summary of findings’ tables present the main findings of a review in a transparent, structured and simple tabular format. In particular, they provide key information concerning the certainty or quality of evidence (i.e. the confidence or certainty in the range of an effect estimate or an association), the magnitude of effect of the interventions examined, and the sum of available data on the main outcomes. Cochrane Reviews should incorporate ‘Summary of findings’ tables during planning and publication, and should have at least one key ‘Summary of findings’ table representing the most important comparisons. Some reviews may include more than one ‘Summary of findings’ table, for example if the review addresses more than one major comparison, or includes substantially different populations that require separate tables (e.g. because the effects differ or it is important to show results separately). In the Cochrane Database of Systematic Reviews (CDSR), all ‘Summary of findings’ tables for a review appear at the beginning, before the Background section.
14.1.2 Selecting outcomes for ‘Summary of findings’ tables
Planning for the ‘Summary of findings’ table starts early in the systematic review, with the selection of the outcomes to be included in: (i) the review; and (ii) the ‘Summary of findings’ table. This is a crucial step, and one that review authors need to address carefully.
To ensure production of optimally useful information, Cochrane Reviews begin by developing a review question and by listing all main outcomes that are important to patients and other decision makers (see Chapter 2 and Chapter 3 ). The GRADE approach to assessing the certainty of the evidence (see Section 14.2 ) defines and operationalizes a rating process that helps separate outcomes into those that are critical, important or not important for decision making. Consultation and feedback on the review protocol, including from consumers and other decision makers, can enhance this process.
Critical outcomes are likely to include clearly important endpoints; typical examples include mortality and major morbidity (such as strokes and myocardial infarction). However, they may also represent frequent minor and rare major side effects, symptoms, quality of life, burdens associated with treatment, and resource issues (costs). Burdens represent the impact of healthcare workload on patient function and well-being, and include the demands of adhering to an intervention that patients or caregivers (e.g. family) may dislike, such as having to undergo more frequent tests, or the restrictions on lifestyle that certain interventions require (Spencer-Bonilla et al 2017).
Frequently, when formulating questions that include all patient-important outcomes for decision making, review authors will confront reports of studies that have not included all these outcomes. This is particularly true for adverse outcomes. For instance, randomized trials might contribute evidence on intended effects, and on frequent, relatively minor side effects, but not report on rare adverse outcomes such as suicide attempts. Chapter 19 discusses strategies for addressing adverse effects. To obtain data for all important outcomes it may be necessary to examine the results of non-randomized studies (see Chapter 24 ). Cochrane, in collaboration with others, has developed guidance for review authors to support their decision about when to look for and include non-randomized studies (Schünemann et al 2013).
If a review includes only randomized trials, these trials may not address all important outcomes and it may therefore not be possible to address these outcomes within the constraints of the review. Review authors should acknowledge these limitations and make them transparent to readers. Review authors are encouraged to include non-randomized studies to examine rare or long-term adverse effects that may not adequately be studied in randomized trials. This raises the possibility that harm outcomes may come from studies in which participants differ from those in studies used in the analysis of benefit. Review authors will then need to consider how much such differences are likely to impact on the findings, and this will influence the certainty of evidence because of concerns about indirectness related to the population (see Section 14.2.2 ).
Non-randomized studies can provide important information not only when randomized trials do not report on an outcome or randomized trials suffer from indirectness, but also when the evidence from randomized trials is rated as very low and non-randomized studies provide evidence of higher certainty. Further discussion of these issues appears also in Chapter 24 .
14.1.3 General template for ‘Summary of findings’ tables
Several alternative standard versions of ‘Summary of findings’ tables have been developed to ensure consistency and ease of use across reviews, inclusion of the most important information needed by decision makers, and optimal presentation (see examples at Figures 14.1.a and 14.1.b ). These formats are supported by research that focused on improved understanding of the information they intend to convey (Carrasco-Labra et al 2016, Langendam et al 2016, Santesso et al 2016). They are available through GRADE’s official software package developed to support the GRADE approach: GRADEpro GDT (www.gradepro.org).
Standard Cochrane ‘Summary of findings’ tables include the following elements using one of the accepted formats. Further guidance on each of these is provided in Section 14.1.6 .
- A brief description of the population and setting addressed by the available evidence (which may be slightly different to or narrower than those defined by the review question).
- A brief description of the comparison addressed in the ‘Summary of findings’ table, including both the experimental and comparison interventions.
- A list of the most critical and/or important health outcomes, both desirable and undesirable, limited to seven or fewer outcomes.
- A measure of the typical burden of each outcomes (e.g. illustrative risk, or illustrative mean, on comparator intervention).
- The absolute and relative magnitude of effect measured for each (if both are appropriate).
- The numbers of participants and studies contributing to the analysis of each outcomes.
- A GRADE assessment of the overall certainty of the body of evidence for each outcome (which may vary by outcome).
- Space for comments.
- Explanations (formerly known as footnotes).
Ideally, ‘Summary of findings’ tables are supported by more detailed tables (known as ‘evidence profiles’) to which the review may be linked, which provide more detailed explanations. Evidence profiles include the same important health outcomes, and provide greater detail than ‘Summary of findings’ tables of both of the individual considerations feeding into the grading of certainty and of the results of the studies (Guyatt et al 2011a). They ensure that a structured approach is used to rating the certainty of evidence. Although they are rarely published in Cochrane Reviews, evidence profiles are often used, for example, by guideline developers in considering the certainty of the evidence to support guideline recommendations. Review authors will find it easier to develop the ‘Summary of findings’ table by completing the rating of the certainty of evidence in the evidence profile first in GRADEpro GDT. They can then automatically convert this to one of the ‘Summary of findings’ formats in GRADEpro GDT, including an interactive ‘Summary of findings’ for publication.
As a measure of the magnitude of effect for dichotomous outcomes, the ‘Summary of findings’ table should provide a relative measure of effect (e.g. risk ratio, odds ratio, hazard) and measures of absolute risk. For other types of data, an absolute measure alone (such as a difference in means for continuous data) might be sufficient. It is important that the magnitude of effect is presented in a meaningful way, which may require some transformation of the result of a meta-analysis (see also Chapter 15, Section 15.4 and Section 15.5 ). Reviews with more than one main comparison should include a separate ‘Summary of findings’ table for each comparison.
Figure 14.1.a provides an example of a ‘Summary of findings’ table. Figure 15.1.b provides an alternative format that may further facilitate users’ understanding and interpretation of the review’s findings. Evidence evaluating different formats suggests that the ‘Summary of findings’ table should include a risk difference as a measure of the absolute effect and authors should preferably use a format that includes a risk difference .
A detailed description of the contents of a ‘Summary of findings’ table appears in Section 14.1.6 .
Figure 14.1.a Example of a ‘Summary of findings’ table
Summary of findings (for interactive version click here )
a All the stockings in the nine studies included in this review were below-knee compression stockings. In four studies the compression strength was 20 mmHg to 30 mmHg at the ankle. It was 10 mmHg to 20 mmHg in the other four studies. Stockings come in different sizes. If a stocking is too tight around the knee it can prevent essential venous return causing the blood to pool around the knee. Compression stockings should be fitted properly. A stocking that is too tight could cut into the skin on a long flight and potentially cause ulceration and increased risk of DVT. Some stockings can be slightly thicker than normal leg covering and can be potentially restrictive with tight foot wear. It is a good idea to wear stockings around the house prior to travel to ensure a good, comfortable fit. Participants put their stockings on two to three hours before the flight in most of the studies. The availability and cost of stockings can vary.
b Two studies recruited high risk participants defined as those with previous episodes of DVT, coagulation disorders, severe obesity, limited mobility due to bone or joint problems, neoplastic disease within the previous two years, large varicose veins or, in one of the studies, participants taller than 190 cm and heavier than 90 kg. The incidence for the seven studies that excluded high risk participants was 1.45% and the incidence for the two studies that recruited high-risk participants (with at least one risk factor) was 2.43%. We have used 10 and 30 per 1000 to express different risk strata, respectively.
c The confidence interval crosses no difference and does not rule out a small increase.
d The measurement of oedema was not validated (indirectness of the outcome) or blinded to the intervention (risk of bias).
e If there are very few or no events and the number of participants is large, judgement about the certainty of evidence (particularly judgements about imprecision) may be based on the absolute effect. Here the certainty rating may be considered ‘high’ if the outcome was appropriately assessed and the event, in fact, did not occur in 2821 studied participants.
f None of the other studies reported adverse effects, apart from four cases of superficial vein thrombosis in varicose veins in the knee region that were compressed by the upper edge of the stocking in one study.
Figure 14.1.b Example of alternative ‘Summary of findings’ table
14.1.4 Producing ‘Summary of findings’ tables
The GRADE Working Group’s software, GRADEpro GDT ( www.gradepro.org ), including GRADE’s interactive handbook, is available to assist review authors in the preparation of ‘Summary of findings’ tables. GRADEpro can use data on the comparator group risk and the effect estimate (entered by the review authors or imported from files generated in RevMan) to produce the relative effects and absolute risks associated with experimental interventions. In addition, it leads the user through the process of a GRADE assessment, and produces a table that can be used as a standalone table in a review (including by direct import into software such as RevMan or integration with RevMan Web), or an interactive ‘Summary of findings’ table (see help resources in GRADEpro).
14.1.5 Statistical considerations in ‘Summary of findings’ tables
14.1.5.1 dichotomous outcomes.
‘Summary of findings’ tables should include both absolute and relative measures of effect for dichotomous outcomes. Risk ratios, odds ratios and risk differences are different ways of comparing two groups with dichotomous outcome data (see Chapter 6, Section 6.4.1 ). Furthermore, there are two distinct risk ratios, depending on which event (e.g. ‘yes’ or ‘no’) is the focus of the analysis (see Chapter 6, Section 6.4.1.5 ). In the presence of a non-zero intervention effect, any variation across studies in the comparator group risks (i.e. variation in the risk of the event occurring without the intervention of interest, for example in different populations) makes it impossible for more than one of these measures to be truly the same in every study.
It has long been assumed in epidemiology that relative measures of effect are more consistent than absolute measures of effect from one scenario to another. There is empirical evidence to support this assumption (Engels et al 2000, Deeks and Altman 2001, Furukawa et al 2002). For this reason, meta-analyses should generally use either a risk ratio or an odds ratio as a measure of effect (see Chapter 10, Section 10.4.3 ). Correspondingly, a single estimate of relative effect is likely to be a more appropriate summary than a single estimate of absolute effect. If a relative effect is indeed consistent across studies, then different comparator group risks will have different implications for absolute benefit. For instance, if the risk ratio is consistently 0.75, then the experimental intervention would reduce a comparator group risk of 80% to 60% in the intervention group (an absolute risk reduction of 20 percentage points), but would also reduce a comparator group risk of 20% to 15% in the intervention group (an absolute risk reduction of 5 percentage points).
‘Summary of findings’ tables are built around the assumption of a consistent relative effect. It is therefore important to consider the implications of this effect for different comparator group risks (these can be derived or estimated from a number of sources, see Section 14.1.6.3 ), which may require an assessment of the certainty of evidence for prognostic evidence (Spencer et al 2012, Iorio et al 2015). For any comparator group risk, it is possible to estimate a corresponding intervention group risk (i.e. the absolute risk with the intervention) from the meta-analytic risk ratio or odds ratio. Note that the numbers provided in the ‘Corresponding risk’ column are specific to the ‘risks’ in the adjacent column.
For the meta-analytic risk ratio (RR) and assumed comparator risk (ACR) the corresponding intervention risk is obtained as:

As an example, in Figure 14.1.a , the meta-analytic risk ratio for symptomless deep vein thrombosis (DVT) is RR = 0.10 (95% CI 0.04 to 0.26). Assuming a comparator risk of ACR = 10 per 1000 = 0.01, we obtain:

For the meta-analytic odds ratio (OR) and assumed comparator risk, ACR, the corresponding intervention risk is obtained as:

Upper and lower confidence limits for the corresponding intervention risk are obtained by replacing RR or OR by their upper and lower confidence limits, respectively (e.g. replacing 0.10 with 0.04, then with 0.26, in the example). Such confidence intervals do not incorporate uncertainty in the assumed comparator risks.
When dealing with risk ratios, it is critical that the same definition of ‘event’ is used as was used for the meta-analysis. For example, if the meta-analysis focused on ‘death’ (as opposed to survival) as the event, then corresponding risks in the ‘Summary of findings’ table must also refer to ‘death’.
In (rare) circumstances in which there is clear rationale to assume a consistent risk difference in the meta-analysis, in principle it is possible to present this for relevant ‘assumed risks’ and their corresponding risks, and to present the corresponding (different) relative effects for each assumed risk.
The risk difference expresses the difference between the ACR and the corresponding intervention risk (or the difference between the experimental and the comparator intervention).
For the meta-analytic risk ratio (RR) and assumed comparator risk (ACR) the corresponding risk difference is obtained as (note that risks can also be expressed using percentage or percentage points):

As an example, in Figure 14.1.b the meta-analytic risk ratio is 0.41 (95% CI 0.29 to 0.55) for diarrhoea in children less than 5 years of age. Assuming a comparator group risk of 22.3% we obtain:

For the meta-analytic odds ratio (OR) and assumed comparator risk (ACR) the absolute risk difference is obtained as (percentage points):

Upper and lower confidence limits for the absolute risk difference are obtained by re-running the calculation above while replacing RR or OR by their upper and lower confidence limits, respectively (e.g. replacing 0.41 with 0.28, then with 0.55, in the example). Such confidence intervals do not incorporate uncertainty in the assumed comparator risks.
14.1.5.2 Time-to-event outcomes
Time-to-event outcomes measure whether and when a particular event (e.g. death) occurs (van Dalen et al 2007). The impact of the experimental intervention relative to the comparison group on time-to-event outcomes is usually measured using a hazard ratio (HR) (see Chapter 6, Section 6.8.1 ).
A hazard ratio expresses a relative effect estimate. It may be used in various ways to obtain absolute risks and other interpretable quantities for a specific population. Here we describe how to re-express hazard ratios in terms of: (i) absolute risk of event-free survival within a particular period of time; (ii) absolute risk of an event within a particular period of time; and (iii) median time to the event. All methods are built on an assumption of consistent relative effects (i.e. that the hazard ratio does not vary over time).
(i) Absolute risk of event-free survival within a particular period of time Event-free survival (e.g. overall survival) is commonly reported by individual studies. To obtain absolute effects for time-to-event outcomes measured as event-free survival, the summary HR can be used in conjunction with an assumed proportion of patients who are event-free in the comparator group (Tierney et al 2007). This proportion of patients will be specific to a period of time of observation. However, it is not strictly necessary to specify this period of time. For instance, a proportion of 50% of event-free patients might apply to patients with a high event rate observed over 1 year, or to patients with a low event rate observed over 2 years.

As an example, suppose the meta-analytic hazard ratio is 0.42 (95% CI 0.25 to 0.72). Assuming a comparator group risk of event-free survival (e.g. for overall survival people being alive) at 2 years of ACR = 900 per 1000 = 0.9 we obtain:

so that that 956 per 1000 people will be alive with the experimental intervention at 2 years. The derivation of the risk should be explained in a comment or footnote.
(ii) Absolute risk of an event within a particular period of time To obtain this absolute effect, again the summary HR can be used (Tierney et al 2007):

In the example, suppose we assume a comparator group risk of events (e.g. for mortality, people being dead) at 2 years of ACR = 100 per 1000 = 0.1. We obtain:

so that that 44 per 1000 people will be dead with the experimental intervention at 2 years.
(iii) Median time to the event Instead of absolute numbers, the time to the event in the intervention and comparison groups can be expressed as median survival time in months or years. To obtain median survival time the pooled HR can be applied to an assumed median survival time in the comparator group (Tierney et al 2007):

In the example, assuming a comparator group median survival time of 80 months, we obtain:

For all three of these options for re-expressing results of time-to-event analyses, upper and lower confidence limits for the corresponding intervention risk are obtained by replacing HR by its upper and lower confidence limits, respectively (e.g. replacing 0.42 with 0.25, then with 0.72, in the example). Again, as for dichotomous outcomes, such confidence intervals do not incorporate uncertainty in the assumed comparator group risks. This is of special concern for long-term survival with a low or moderate mortality rate and a corresponding high number of censored patients (i.e. a low number of patients under risk and a high censoring rate).
14.1.6 Detailed contents of a ‘Summary of findings’ table
14.1.6.1 table title and header.
The title of each ‘Summary of findings’ table should specify the healthcare question, framed in terms of the population and making it clear exactly what comparison of interventions are made. In Figure 14.1.a , the population is people taking long aeroplane flights, the intervention is compression stockings, and the control is no compression stockings.
The first rows of each ‘Summary of findings’ table should provide the following ‘header’ information:
Patients or population This further clarifies the population (and possibly the subpopulations) of interest and ideally the magnitude of risk of the most crucial adverse outcome at which an intervention is directed. For instance, people on a long-haul flight may be at different risks for DVT; those using selective serotonin reuptake inhibitors (SSRIs) might be at different risk for side effects; while those with atrial fibrillation may be at low (< 1%), moderate (1% to 4%) or high (> 4%) yearly risk of stroke.
Setting This should state any specific characteristics of the settings of the healthcare question that might limit the applicability of the summary of findings to other settings (e.g. primary care in Europe and North America).
Intervention The experimental intervention.
Comparison The comparator intervention (including no specific intervention).
14.1.6.2 Outcomes
The rows of a ‘Summary of findings’ table should include all desirable and undesirable health outcomes (listed in order of importance) that are essential for decision making, up to a maximum of seven outcomes. If there are more outcomes in the review, review authors will need to omit the less important outcomes from the table, and the decision selecting which outcomes are critical or important to the review should be made during protocol development (see Chapter 3 ). Review authors should provide time frames for the measurement of the outcomes (e.g. 90 days or 12 months) and the type of instrument scores (e.g. ranging from 0 to 100).
Note that review authors should include the pre-specified critical and important outcomes in the table whether data are available or not. However, they should be alert to the possibility that the importance of an outcome (e.g. a serious adverse effect) may only become known after the protocol was written or the analysis was carried out, and should take appropriate actions to include these in the ‘Summary of findings’ table.
The ‘Summary of findings’ table can include effects in subgroups of the population for different comparator risks and effect sizes separately. For instance, in Figure 14.1.b effects are presented for children younger and older than 5 years separately. Review authors may also opt to produce separate ‘Summary of findings’ tables for different populations.
Review authors should include serious adverse events, but it might be possible to combine minor adverse events as a single outcome, and describe this in an explanatory footnote (note that it is not appropriate to add events together unless they are independent, that is, a participant who has experienced one adverse event has an unaffected chance of experiencing the other adverse event).
Outcomes measured at multiple time points represent a particular problem. In general, to keep the table simple, review authors should present multiple time points only for outcomes critical to decision making, where either the result or the decision made are likely to vary over time. The remainder should be presented at a common time point where possible.
Review authors can present continuous outcome measures in the ‘Summary of findings’ table and should endeavour to make these interpretable to the target audience. This requires that the units are clear and readily interpretable, for example, days of pain, or frequency of headache, and the name and scale of any measurement tools used should be stated (e.g. a Visual Analogue Scale, ranging from 0 to 100). However, many measurement instruments are not readily interpretable by non-specialist clinicians or patients, for example, points on a Beck Depression Inventory or quality of life score. For these, a more interpretable presentation might involve converting a continuous to a dichotomous outcome, such as >50% improvement (see Chapter 15, Section 15.5 ).
14.1.6.3 Best estimate of risk with comparator intervention
Review authors should provide up to three typical risks for participants receiving the comparator intervention. For dichotomous outcomes, we recommend that these be presented in the form of the number of people experiencing the event per 100 or 1000 people (natural frequency) depending on the frequency of the outcome. For continuous outcomes, this would be stated as a mean or median value of the outcome measured.
Estimated or assumed comparator intervention risks could be based on assessments of typical risks in different patient groups derived from the review itself, individual representative studies in the review, or risks derived from a systematic review of prognosis studies or other sources of evidence which may in turn require an assessment of the certainty for the prognostic evidence (Spencer et al 2012, Iorio et al 2015). Ideally, risks would reflect groups that clinicians can easily identify on the basis of their presenting features.
An explanatory footnote should specify the source or rationale for each comparator group risk, including the time period to which it corresponds where appropriate. In Figure 14.1.a , clinicians can easily differentiate individuals with risk factors for deep venous thrombosis from those without. If there is known to be little variation in baseline risk then review authors may use the median comparator group risk across studies. If typical risks are not known, an option is to choose the risk from the included studies, providing the second highest for a high and the second lowest for a low risk population.
14.1.6.4 Risk with intervention
For dichotomous outcomes, review authors should provide a corresponding absolute risk for each comparator group risk, along with a confidence interval. This absolute risk with the (experimental) intervention will usually be derived from the meta-analysis result presented in the relative effect column (see Section 14.1.6.6 ). Formulae are provided in Section 14.1.5 . Review authors should present the absolute effect in the same format as the risks with comparator intervention (see Section 14.1.6.3 ), for example as the number of people experiencing the event per 1000 people.
For continuous outcomes, a difference in means or standardized difference in means should be presented with its confidence interval. These will typically be obtained directly from a meta-analysis. Explanatory text should be used to clarify the meaning, as in Figures 14.1.a and 14.1.b .
14.1.6.5 Risk difference
For dichotomous outcomes, the risk difference can be provided using one of the ‘Summary of findings’ table formats as an additional option (see Figure 14.1.b ). This risk difference expresses the difference between the experimental and comparator intervention and will usually be derived from the meta-analysis result presented in the relative effect column (see Section 14.1.6.6 ). Formulae are provided in Section 14.1.5 . Review authors should present the risk difference in the same format as assumed and corresponding risks with comparator intervention (see Section 14.1.6.3 ); for example, as the number of people experiencing the event per 1000 people or as percentage points if the assumed and corresponding risks are expressed in percentage.
For continuous outcomes, if the ‘Summary of findings’ table includes this option, the mean difference can be presented here and the ‘corresponding risk’ column left blank (see Figure 14.1.b ).
14.1.6.6 Relative effect (95% CI)
The relative effect will typically be a risk ratio or odds ratio (or occasionally a hazard ratio) with its accompanying 95% confidence interval, obtained from a meta-analysis performed on the basis of the same effect measure. Risk ratios and odds ratios are similar when the comparator intervention risks are low and effects are small, but may differ considerably when comparator group risks increase. The meta-analysis may involve an assumption of either fixed or random effects, depending on what the review authors consider appropriate, and implying that the relative effect is either an estimate of the effect of the intervention, or an estimate of the average effect of the intervention across studies, respectively.
14.1.6.7 Number of participants (studies)
This column should include the number of participants assessed in the included studies for each outcome and the corresponding number of studies that contributed these participants.
14.1.6.8 Certainty of the evidence (GRADE)
Review authors should comment on the certainty of the evidence (also known as quality of the body of evidence or confidence in the effect estimates). Review authors should use the specific evidence grading system developed by the GRADE Working Group (Atkins et al 2004, Guyatt et al 2008, Guyatt et al 2011a), which is described in detail in Section 14.2 . The GRADE approach categorizes the certainty in a body of evidence as ‘high’, ‘moderate’, ‘low’ or ‘very low’ by outcome. This is a result of judgement, but the judgement process operates within a transparent structure. As an example, the certainty would be ‘high’ if the summary were of several randomized trials with low risk of bias, but the rating of certainty becomes lower if there are concerns about risk of bias, inconsistency, indirectness, imprecision or publication bias. Judgements other than of ‘high’ certainty should be made transparent using explanatory footnotes or the ‘Comments’ column in the ‘Summary of findings’ table (see Section 14.1.6.10 ).
14.1.6.9 Comments
The aim of the ‘Comments’ field is to help interpret the information or data identified in the row. For example, this may be on the validity of the outcome measure or the presence of variables that are associated with the magnitude of effect. Important caveats about the results should be flagged here. Not all rows will need comments, and it is best to leave a blank if there is nothing warranting a comment.
14.1.6.10 Explanations
Detailed explanations should be included as footnotes to support the judgements in the ‘Summary of findings’ table, such as the overall GRADE assessment. The explanations should describe the rationale for important aspects of the content. Table 14.1.a lists guidance for useful explanations. Explanations should be concise, informative, relevant, easy to understand and accurate. If explanations cannot be sufficiently described in footnotes, review authors should provide further details of the issues in the Results and Discussion sections of the review.
Table 14.1.a Guidance for providing useful explanations in ‘Summary of findings’ (SoF) tables. Adapted from Santesso et al (2016)
14.2 Assessing the certainty or quality of a body of evidence
14.2.1 the grade approach.
The Grades of Recommendation, Assessment, Development and Evaluation Working Group (GRADE Working Group) has developed a system for grading the certainty of evidence (Schünemann et al 2003, Atkins et al 2004, Schünemann et al 2006, Guyatt et al 2008, Guyatt et al 2011a). Over 100 organizations including the World Health Organization (WHO), the American College of Physicians, the American Society of Hematology (ASH), the Canadian Agency for Drugs and Technology in Health (CADTH) and the National Institutes of Health and Clinical Excellence (NICE) in the UK have adopted the GRADE system ( www.gradeworkinggroup.org ).
Cochrane has also formally adopted this approach, and all Cochrane Reviews should use GRADE to evaluate the certainty of evidence for important outcomes (see MECIR Box 14.2.a ).
MECIR Box 14.2.a Relevant expectations for conduct of intervention reviews
For systematic reviews, the GRADE approach defines the certainty of a body of evidence as the extent to which one can be confident that an estimate of effect or association is close to the quantity of specific interest. Assessing the certainty of a body of evidence involves consideration of within- and across-study risk of bias (limitations in study design and execution or methodological quality), inconsistency (or heterogeneity), indirectness of evidence, imprecision of the effect estimates and risk of publication bias (see Section 14.2.2 ), as well as domains that may increase our confidence in the effect estimate (as described in Section 14.2.3 ). The GRADE system entails an assessment of the certainty of a body of evidence for each individual outcome. Judgements about the domains that determine the certainty of evidence should be described in the results or discussion section and as part of the ‘Summary of findings’ table.
The GRADE approach specifies four levels of certainty ( Figure 14.2.a ). For interventions, including diagnostic and other tests that are evaluated as interventions (Schünemann et al 2008b, Schünemann et al 2008a, Balshem et al 2011, Schünemann et al 2012), the starting point for rating the certainty of evidence is categorized into two types:
- randomized trials; and
- non-randomized studies of interventions (NRSI), including observational studies (including but not limited to cohort studies, and case-control studies, cross-sectional studies, case series and case reports, although not all of these designs are usually included in Cochrane Reviews).
There are many instances in which review authors rely on information from NRSI, in particular to evaluate potential harms (see Chapter 24 ). In addition, review authors can obtain relevant data from both randomized trials and NRSI, with each type of evidence complementing the other (Schünemann et al 2013).
In GRADE, a body of evidence from randomized trials begins with a high-certainty rating while a body of evidence from NRSI begins with a low-certainty rating. The lower rating with NRSI is the result of the potential bias induced by the lack of randomization (i.e. confounding and selection bias).
However, when using the new Risk Of Bias In Non-randomized Studies of Interventions (ROBINS-I) tool (Sterne et al 2016), an assessment tool that covers the risk of bias due to lack of randomization, all studies may start as high certainty of the evidence (Schünemann et al 2018). The approach of starting all study designs (including NRSI) as high certainty does not conflict with the initial GRADE approach of starting the rating of NRSI as low certainty evidence. This is because a body of evidence from NRSI should generally be downgraded by two levels due to the inherent risk of bias associated with the lack of randomization, namely confounding and selection bias. Not downgrading NRSI from high to low certainty needs transparent and detailed justification for what mitigates concerns about confounding and selection bias (Schünemann et al 2018). Very few examples of where not rating down by two levels is appropriate currently exist.
The highest certainty rating is a body of evidence when there are no concerns in any of the GRADE factors listed in Figure 14.2.a . Review authors often downgrade evidence to moderate, low or even very low certainty evidence, depending on the presence of the five factors in Figure 14.2.a . Usually, certainty rating will fall by one level for each factor, up to a maximum of three levels for all factors. If there are very severe problems for any one domain (e.g. when assessing risk of bias, all studies were unconcealed, unblinded and lost over 50% of their patients to follow-up), evidence may fall by two levels due to that factor alone. It is not possible to rate lower than ‘very low certainty’ evidence.
Review authors will generally grade evidence from sound non-randomized studies as low certainty, even if ROBINS-I is used. If, however, such studies yield large effects and there is no obvious bias explaining those effects, review authors may rate the evidence as moderate or – if the effect is large enough – even as high certainty ( Figure 14.2.a ). The very low certainty level is appropriate for, but is not limited to, studies with critical problems and unsystematic clinical observations (e.g. case series or case reports).
Figure 14.2.a Levels of the certainty of a body of evidence in the GRADE approach. *Upgrading criteria are usually applicable to non-randomized studies only (but exceptions exist).
14.2.2 Domains that can lead to decreasing the certainty level of a body of evidence
We now describe in more detail the five reasons (or domains) for downgrading the certainty of a body of evidence for a specific outcome. In each case, if no reason is found for downgrading the evidence, it should be classified as 'no limitation or not serious' (not important enough to warrant downgrading). If a reason is found for downgrading the evidence, it should be classified as 'serious' (downgrading the certainty rating by one level) or 'very serious' (downgrading the certainty grade by two levels). For non-randomized studies assessed with ROBINS-I, rating down by three levels should be classified as 'extremely' serious.
(1) Risk of bias or limitations in the detailed design and implementation
Our confidence in an estimate of effect decreases if studies suffer from major limitations that are likely to result in a biased assessment of the intervention effect. For randomized trials, these methodological limitations include failure to generate a random sequence, lack of allocation sequence concealment, lack of blinding (particularly with subjective outcomes that are highly susceptible to biased assessment), a large loss to follow-up or selective reporting of outcomes. Chapter 8 provides a discussion of study-level assessments of risk of bias in the context of a Cochrane Review, and proposes an approach to assessing the risk of bias for an outcome across studies as ‘Low’ risk of bias, ‘Some concerns’ and ‘High’ risk of bias for randomized trials. Levels of ‘Low’. ‘Moderate’, ‘Serious’ and ‘Critical’ risk of bias arise for non-randomized studies assessed with ROBINS-I ( Chapter 25 ). These assessments should feed directly into this GRADE domain. In particular, ‘Low’ risk of bias would indicate ‘no limitation’; ‘Some concerns’ would indicate either ‘no limitation’ or ‘serious limitation’; and ‘High’ risk of bias would indicate either ‘serious limitation’ or ‘very serious limitation’. ‘Critical’ risk of bias on ROBINS-I would indicate extremely serious limitations in GRADE. Review authors should use their judgement to decide between alternative categories, depending on the likely magnitude of the potential biases.
Every study addressing a particular outcome will differ, to some degree, in the risk of bias. Review authors should make an overall judgement on whether the certainty of evidence for an outcome warrants downgrading on the basis of study limitations. The assessment of study limitations should apply to the studies contributing to the results in the ‘Summary of findings’ table, rather than to all studies that could potentially be included in the analysis. We have argued in Chapter 7, Section 7.6.2 , that the primary analysis should be restricted to studies at low (or low and unclear) risk of bias where possible.
Table 14.2.a presents the judgements that must be made in going from assessments of the risk of bias to judgements about study limitations for each outcome included in a ‘Summary of findings’ table. A rating of high certainty evidence can be achieved only when most evidence comes from studies that met the criteria for low risk of bias. For example, of the 22 studies addressing the impact of beta-blockers on mortality in patients with heart failure, most probably or certainly used concealed allocation of the sequence, all blinded at least some key groups and follow-up of randomized patients was almost complete (Brophy et al 2001). The certainty of evidence might be downgraded by one level when most of the evidence comes from individual studies either with a crucial limitation for one item, or with some limitations for multiple items. An example of very serious limitations, warranting downgrading by two levels, is provided by evidence on surgery versus conservative treatment in the management of patients with lumbar disc prolapse (Gibson and Waddell 2007). We are uncertain of the benefit of surgery in reducing symptoms after one year or longer, because the one study included in the analysis had inadequate concealment of the allocation sequence and the outcome was assessed using a crude rating by the surgeon without blinding.
(2) Unexplained heterogeneity or inconsistency of results
When studies yield widely differing estimates of effect (heterogeneity or variability in results), investigators should look for robust explanations for that heterogeneity. For instance, drugs may have larger relative effects in sicker populations or when given in larger doses. A detailed discussion of heterogeneity and its investigation is provided in Chapter 10, Section 10.10 and Section 10.11 . If an important modifier exists, with good evidence that important outcomes are different in different subgroups (which would ideally be pre-specified), then a separate ‘Summary of findings’ table may be considered for a separate population. For instance, a separate ‘Summary of findings’ table would be used for carotid endarterectomy in symptomatic patients with high grade stenosis (70% to 99%) in which the intervention is, in the hands of the right surgeons, beneficial, and another (if review authors considered it relevant) for asymptomatic patients with low grade stenosis (less than 30%) in which surgery appears harmful (Orrapin and Rerkasem 2017). When heterogeneity exists and affects the interpretation of results, but review authors are unable to identify a plausible explanation with the data available, the certainty of the evidence decreases.
(3) Indirectness of evidence
Two types of indirectness are relevant. First, a review comparing the effectiveness of alternative interventions (say A and B) may find that randomized trials are available, but they have compared A with placebo and B with placebo. Thus, the evidence is restricted to indirect comparisons between A and B. Where indirect comparisons are undertaken within a network meta-analysis context, GRADE for network meta-analysis should be used (see Chapter 11, Section 11.5 ).
Second, a review may find randomized trials that meet eligibility criteria but address a restricted version of the main review question in terms of population, intervention, comparator or outcomes. For example, suppose that in a review addressing an intervention for secondary prevention of coronary heart disease, most identified studies happened to be in people who also had diabetes. Then the evidence may be regarded as indirect in relation to the broader question of interest because the population is primarily related to people with diabetes. The opposite scenario can equally apply: a review addressing the effect of a preventive strategy for coronary heart disease in people with diabetes may consider studies in people without diabetes to provide relevant, albeit indirect, evidence. This would be particularly likely if investigators had conducted few if any randomized trials in the target population (e.g. people with diabetes). Other sources of indirectness may arise from interventions studied (e.g. if in all included studies a technical intervention was implemented by expert, highly trained specialists in specialist centres, then evidence on the effects of the intervention outside these centres may be indirect), comparators used (e.g. if the comparator groups received an intervention that is less effective than standard treatment in most settings) and outcomes assessed (e.g. indirectness due to surrogate outcomes when data on patient-important outcomes are not available, or when investigators seek data on quality of life but only symptoms are reported). Review authors should make judgements transparent when they believe downgrading is justified, based on differences in anticipated effects in the group of primary interest. Review authors may be aided and increase transparency of their judgements about indirectness if they use Table 14.2.b available in the GRADEpro GDT software (Schünemann et al 2013).
(4) Imprecision of results
When studies include few participants or few events, and thus have wide confidence intervals, review authors can lower their rating of the certainty of the evidence. The confidence intervals included in the ‘Summary of findings’ table will provide readers with information that allows them to make, to some extent, their own rating of precision. Review authors can use a calculation of the optimal information size (OIS) or review information size (RIS), similar to sample size calculations, to make judgements about imprecision (Guyatt et al 2011b, Schünemann 2016). The OIS or RIS is calculated on the basis of the number of participants required for an adequately powered individual study. If the 95% confidence interval excludes a risk ratio (RR) of 1.0, and the total number of events or patients exceeds the OIS criterion, precision is adequate. If the 95% CI includes appreciable benefit or harm (an RR of under 0.75 or over 1.25 is often suggested as a very rough guide) downgrading for imprecision may be appropriate even if OIS criteria are met (Guyatt et al 2011b, Schünemann 2016).
(5) High probability of publication bias
The certainty of evidence level may be downgraded if investigators fail to report studies on the basis of results (typically those that show no effect: publication bias) or outcomes (typically those that may be harmful or for which no effect was observed: selective outcome non-reporting bias). Selective reporting of outcomes from among multiple outcomes measured is assessed at the study level as part of the assessment of risk of bias (see Chapter 8, Section 8.7 ), so for the studies contributing to the outcome in the ‘Summary of findings’ table this is addressed by domain 1 above (limitations in the design and implementation). If a large number of studies included in the review do not contribute to an outcome, or if there is evidence of publication bias, the certainty of the evidence may be downgraded. Chapter 13 provides a detailed discussion of reporting biases, including publication bias, and how it may be tackled in a Cochrane Review. A prototypical situation that may elicit suspicion of publication bias is when published evidence includes a number of small studies, all of which are industry-funded (Bhandari et al 2004). For example, 14 studies of flavanoids in patients with haemorrhoids have shown apparent large benefits, but enrolled a total of only 1432 patients (i.e. each study enrolled relatively few patients) (Alonso-Coello et al 2006). The heavy involvement of sponsors in most of these studies raises questions of whether unpublished studies that suggest no benefit exist (publication bias).
A particular body of evidence can suffer from problems associated with more than one of the five factors listed here, and the greater the problems, the lower the certainty of evidence rating that should result. One could imagine a situation in which randomized trials were available, but all or virtually all of these limitations would be present, and in serious form. A very low certainty of evidence rating would result.
Table 14.2.a Further guidelines for domain 1 (of 5) in a GRADE assessment: going from assessments of risk of bias in studies to judgements about study limitations for main outcomes across studies
Table 14.2.b Judgements about indirectness by outcome (available in GRADEpro GDT)
Intervention:
Comparator:
Direct comparison:
Final judgement about indirectness across domains:
14.2.3 Domains that may lead to increasing the certainty level of a body of evidence
Although NRSI and downgraded randomized trials will generally yield a low rating for certainty of evidence, there will be unusual circumstances in which review authors could ‘upgrade’ such evidence to moderate or even high certainty ( Table 14.3.a ).
- Large effects On rare occasions when methodologically well-done observational studies yield large, consistent and precise estimates of the magnitude of an intervention effect, one may be particularly confident in the results. A large estimated effect (e.g. RR >2 or RR <0.5) in the absence of plausible confounders, or a very large effect (e.g. RR >5 or RR <0.2) in studies with no major threats to validity, might qualify for this. In these situations, while the NRSI may possibly have provided an over-estimate of the true effect, the weak study design may not explain all of the apparent observed benefit. Thus, despite reservations based on the observational study design, review authors are confident that the effect exists. The magnitude of the effect in these studies may move the assigned certainty of evidence from low to moderate (if the effect is large in the absence of other methodological limitations). For example, a meta-analysis of observational studies showed that bicycle helmets reduce the risk of head injuries in cyclists by a large margin (odds ratio (OR) 0.31, 95% CI 0.26 to 0.37) (Thompson et al 2000). This large effect, in the absence of obvious bias that could create the association, suggests a rating of moderate-certainty evidence. Note : GRADE guidance suggests the possibility of rating up one level for a large effect if the relative effect is greater than 2.0. However, if the point estimate of the relative effect is greater than 2.0, but the confidence interval is appreciably below 2.0, then some hesitation would be appropriate in the decision to rate up for a large effect. Another situation allows inference of a strong association without a formal comparative study. Consider the question of the impact of routine colonoscopy versus no screening for colon cancer on the rate of perforation associated with colonoscopy. Here, a large series of representative patients undergoing colonoscopy may provide high certainty evidence about the risk of perforation associated with colonoscopy. When the risk of the event among patients receiving the relevant comparator is known to be near 0 (i.e. we are certain that the incidence of spontaneous colon perforation in patients not undergoing colonoscopy is extremely low), case series or cohort studies of representative patients can provide high certainty evidence of adverse effects associated with an intervention, thereby allowing us to infer a strong association from even a limited number of events.
- Dose-response The presence of a dose-response gradient may increase our confidence in the findings of observational studies and thereby enhance the assigned certainty of evidence. For example, our confidence in the result of observational studies that show an increased risk of bleeding in patients who have supratherapeutic anticoagulation levels is increased by the observation that there is a dose-response gradient between the length of time needed for blood to clot (as measured by the international normalized ratio (INR)) and an increased risk of bleeding (Levine et al 2004). A systematic review of NRSI investigating the effect of cyclooxygenase-2 inhibitors on cardiovascular events found that the summary estimate (RR) with rofecoxib was 1.33 (95% CI 1.00 to 1.79) with doses less than 25mg/d, and 2.19 (95% CI 1.64 to 2.91) with doses more than 25mg/d. Although residual confounding is likely to exist in the NRSI that address this issue, the existence of a dose-response gradient and the large apparent effect of higher doses of rofecoxib markedly increase our strength of inference that the association cannot be explained by residual confounding, and is therefore likely to be both causal and, at high levels of exposure, substantial. Note : GRADE guidance suggests the possibility of rating up one level for a large effect if the relative effect is greater than 2.0. Here, the fact that the point estimate of the relative effect is greater than 2.0, but the confidence interval is appreciably below 2.0 might make some hesitate in the decision to rate up for a large effect
- Plausible confounding On occasion, all plausible biases from randomized or non-randomized studies may be working to under-estimate an apparent intervention effect. For example, if only sicker patients receive an experimental intervention or exposure, yet they still fare better, it is likely that the actual intervention or exposure effect is larger than the data suggest. For instance, a rigorous systematic review of observational studies including a total of 38 million patients demonstrated higher death rates in private for-profit versus private not-for-profit hospitals (Devereaux et al 2002). One possible bias relates to different disease severity in patients in the two hospital types. It is likely, however, that patients in the not-for-profit hospitals were sicker than those in the for-profit hospitals. Thus, to the extent that residual confounding existed, it would bias results against the not-for-profit hospitals. The second likely bias was the possibility that higher numbers of patients with excellent private insurance coverage could lead to a hospital having more resources and a spill-over effect that would benefit those without such coverage. Since for-profit hospitals are likely to admit a larger proportion of such well-insured patients than not-for-profit hospitals, the bias is once again against the not-for-profit hospitals. Since the plausible biases would all diminish the demonstrated intervention effect, one might consider the evidence from these observational studies as moderate rather than low certainty. A parallel situation exists when observational studies have failed to demonstrate an association, but all plausible biases would have increased an intervention effect. This situation will usually arise in the exploration of apparent harmful effects. For example, because the hypoglycaemic drug phenformin causes lactic acidosis, the related agent metformin was under suspicion for the same toxicity. Nevertheless, very large observational studies have failed to demonstrate an association (Salpeter et al 2007). Given the likelihood that clinicians would be more alert to lactic acidosis in the presence of the agent and over-report its occurrence, one might consider this moderate, or even high certainty, evidence refuting a causal relationship between typical therapeutic doses of metformin and lactic acidosis.
14.3 Describing the assessment of the certainty of a body of evidence using the GRADE framework
Review authors should report the grading of the certainty of evidence in the Results section for each outcome for which this has been performed, providing the rationale for downgrading or upgrading the evidence, and referring to the ‘Summary of findings’ table where applicable.
Table 14.3.a provides a framework and examples for how review authors can justify their judgements about the certainty of evidence in each domain. These justifications should also be included in explanatory notes to the ‘Summary of Findings’ table (see Section 14.1.6.10 ).
Chapter 15, Section 15.6 , describes in more detail how the overall GRADE assessment across all domains can be used to draw conclusions about the effects of the intervention, as well as providing implications for future research.
Table 14.3.a Framework for describing the certainty of evidence and justifying downgrading or upgrading
14.4 Chapter information
Authors: Holger J Schünemann, Julian PT Higgins, Gunn E Vist, Paul Glasziou, Elie A Akl, Nicole Skoetz, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group (formerly Applicability and Recommendations Methods Group) and the Cochrane Statistical Methods Group
Acknowledgements: Andrew D Oxman contributed to earlier versions. Professor Penny Hawe contributed to the text on adverse effects in earlier versions. Jon Deeks provided helpful contributions on an earlier version of this chapter. For details of previous authors and editors of the Handbook , please refer to the Preface.
Funding: This work was in part supported by funding from the Michael G DeGroote Cochrane Canada Centre and the Ontario Ministry of Health.
14.5 References
Alonso-Coello P, Zhou Q, Martinez-Zapata MJ, Mills E, Heels-Ansdell D, Johanson JF, Guyatt G. Meta-analysis of flavonoids for the treatment of haemorrhoids. British Journal of Surgery 2006; 93 : 909-920.
Atkins D, Best D, Briss PA, Eccles M, Falck-Ytter Y, Flottorp S, Guyatt GH, Harbour RT, Haugh MC, Henry D, Hill S, Jaeschke R, Leng G, Liberati A, Magrini N, Mason J, Middleton P, Mrukowicz J, O'Connell D, Oxman AD, Phillips B, Schünemann HJ, Edejer TT, Varonen H, Vist GE, Williams JW, Jr., Zaza S. Grading quality of evidence and strength of recommendations. BMJ 2004; 328 : 1490.
Balshem H, Helfand M, Schünemann HJ, Oxman AD, Kunz R, Brozek J, Vist GE, Falck-Ytter Y, Meerpohl J, Norris S, Guyatt GH. GRADE guidelines: 3. Rating the quality of evidence. Journal of Clinical Epidemiology 2011; 64 : 401-406.
Bhandari M, Busse JW, Jackowski D, Montori VM, Schünemann H, Sprague S, Mears D, Schemitsch EH, Heels-Ansdell D, Devereaux PJ. Association between industry funding and statistically significant pro-industry findings in medical and surgical randomized trials. Canadian Medical Association Journal 2004; 170 : 477-480.
Brophy JM, Joseph L, Rouleau JL. Beta-blockers in congestive heart failure. A Bayesian meta-analysis. Annals of Internal Medicine 2001; 134 : 550-560.
Carrasco-Labra A, Brignardello-Petersen R, Santesso N, Neumann I, Mustafa RA, Mbuagbaw L, Etxeandia Ikobaltzeta I, De Stio C, McCullagh LJ, Alonso-Coello P, Meerpohl JJ, Vandvik PO, Brozek JL, Akl EA, Bossuyt P, Churchill R, Glenton C, Rosenbaum S, Tugwell P, Welch V, Garner P, Guyatt G, Schünemann HJ. Improving GRADE evidence tables part 1: a randomized trial shows improved understanding of content in summary of findings tables with a new format. Journal of Clinical Epidemiology 2016; 74 : 7-18.
Deeks JJ, Altman DG. Effect measures for meta-analysis of trials with binary outcomes. In: Egger M, Davey Smith G, Altman DG, editors. Systematic Reviews in Health Care: Meta-analysis in Context . 2nd ed. London (UK): BMJ Publication Group; 2001. p. 313-335.
Devereaux PJ, Choi PT, Lacchetti C, Weaver B, Schünemann HJ, Haines T, Lavis JN, Grant BJ, Haslam DR, Bhandari M, Sullivan T, Cook DJ, Walter SD, Meade M, Khan H, Bhatnagar N, Guyatt GH. A systematic review and meta-analysis of studies comparing mortality rates of private for-profit and private not-for-profit hospitals. Canadian Medical Association Journal 2002; 166 : 1399-1406.
Engels EA, Schmid CH, Terrin N, Olkin I, Lau J. Heterogeneity and statistical significance in meta-analysis: an empirical study of 125 meta-analyses. Statistics in Medicine 2000; 19 : 1707-1728.
Furukawa TA, Guyatt GH, Griffith LE. Can we individualize the 'number needed to treat'? An empirical study of summary effect measures in meta-analyses. International Journal of Epidemiology 2002; 31 : 72-76.
Gibson JN, Waddell G. Surgical interventions for lumbar disc prolapse: updated Cochrane Review. Spine 2007; 32 : 1735-1747.
Guyatt G, Oxman A, Vist G, Kunz R, Falck-Ytter Y, Alonso-Coello P, Schünemann H. GRADE: an emerging consensus on rating quality of evidence and strength of recommendations. BMJ 2008; 336 : 3.
Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, Norris S, Falck-Ytter Y, Glasziou P, DeBeer H, Jaeschke R, Rind D, Meerpohl J, Dahm P, Schünemann HJ. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. Journal of Clinical Epidemiology 2011a; 64 : 383-394.
Guyatt GH, Oxman AD, Kunz R, Brozek J, Alonso-Coello P, Rind D, Devereaux PJ, Montori VM, Freyschuss B, Vist G, Jaeschke R, Williams JW, Jr., Murad MH, Sinclair D, Falck-Ytter Y, Meerpohl J, Whittington C, Thorlund K, Andrews J, Schünemann HJ. GRADE guidelines 6. Rating the quality of evidence--imprecision. Journal of Clinical Epidemiology 2011b; 64 : 1283-1293.
Iorio A, Spencer FA, Falavigna M, Alba C, Lang E, Burnand B, McGinn T, Hayden J, Williams K, Shea B, Wolff R, Kujpers T, Perel P, Vandvik PO, Glasziou P, Schünemann H, Guyatt G. Use of GRADE for assessment of evidence about prognosis: rating confidence in estimates of event rates in broad categories of patients. BMJ 2015; 350 : h870.
Langendam M, Carrasco-Labra A, Santesso N, Mustafa RA, Brignardello-Petersen R, Ventresca M, Heus P, Lasserson T, Moustgaard R, Brozek J, Schünemann HJ. Improving GRADE evidence tables part 2: a systematic survey of explanatory notes shows more guidance is needed. Journal of Clinical Epidemiology 2016; 74 : 19-27.
Levine MN, Raskob G, Landefeld S, Kearon C, Schulman S. Hemorrhagic complications of anticoagulant treatment: the Seventh ACCP Conference on Antithrombotic and Thrombolytic Therapy. Chest 2004; 126 : 287S-310S.
Orrapin S, Rerkasem K. Carotid endarterectomy for symptomatic carotid stenosis. Cochrane Database of Systematic Reviews 2017; 6 : CD001081.
Salpeter S, Greyber E, Pasternak G, Salpeter E. Risk of fatal and nonfatal lactic acidosis with metformin use in type 2 diabetes mellitus. Cochrane Database of Systematic Reviews 2007; 4 : CD002967.
Santesso N, Carrasco-Labra A, Langendam M, Brignardello-Petersen R, Mustafa RA, Heus P, Lasserson T, Opiyo N, Kunnamo I, Sinclair D, Garner P, Treweek S, Tovey D, Akl EA, Tugwell P, Brozek JL, Guyatt G, Schünemann HJ. Improving GRADE evidence tables part 3: detailed guidance for explanatory footnotes supports creating and understanding GRADE certainty in the evidence judgments. Journal of Clinical Epidemiology 2016; 74 : 28-39.
Schünemann HJ, Best D, Vist G, Oxman AD, Group GW. Letters, numbers, symbols and words: how to communicate grades of evidence and recommendations. Canadian Medical Association Journal 2003; 169 : 677-680.
Schünemann HJ, Jaeschke R, Cook DJ, Bria WF, El-Solh AA, Ernst A, Fahy BF, Gould MK, Horan KL, Krishnan JA, Manthous CA, Maurer JR, McNicholas WT, Oxman AD, Rubenfeld G, Turino GM, Guyatt G. An official ATS statement: grading the quality of evidence and strength of recommendations in ATS guidelines and recommendations. American Journal of Respiratory and Critical Care Medicine 2006; 174 : 605-614.
Schünemann HJ, Oxman AD, Brozek J, Glasziou P, Jaeschke R, Vist GE, Williams JW, Jr., Kunz R, Craig J, Montori VM, Bossuyt P, Guyatt GH. Grading quality of evidence and strength of recommendations for diagnostic tests and strategies. BMJ 2008a; 336 : 1106-1110.
Schünemann HJ, Oxman AD, Brozek J, Glasziou P, Bossuyt P, Chang S, Muti P, Jaeschke R, Guyatt GH. GRADE: assessing the quality of evidence for diagnostic recommendations. ACP Journal Club 2008b; 149 : 2.
Schünemann HJ, Mustafa R, Brozek J. [Diagnostic accuracy and linked evidence--testing the chain]. Zeitschrift für Evidenz, Fortbildung und Qualität im Gesundheitswesen 2012; 106 : 153-160.
Schünemann HJ, Tugwell P, Reeves BC, Akl EA, Santesso N, Spencer FA, Shea B, Wells G, Helfand M. Non-randomized studies as a source of complementary, sequential or replacement evidence for randomized controlled trials in systematic reviews on the effects of interventions. Research Synthesis Methods 2013; 4 : 49-62.
Schünemann HJ. Interpreting GRADE's levels of certainty or quality of the evidence: GRADE for statisticians, considering review information size or less emphasis on imprecision? Journal of Clinical Epidemiology 2016; 75 : 6-15.
Schünemann HJ, Cuello C, Akl EA, Mustafa RA, Meerpohl JJ, Thayer K, Morgan RL, Gartlehner G, Kunz R, Katikireddi SV, Sterne J, Higgins JPT, Guyatt G, Group GW. GRADE guidelines: 18. How ROBINS-I and other tools to assess risk of bias in nonrandomized studies should be used to rate the certainty of a body of evidence. Journal of Clinical Epidemiology 2018.
Spencer-Bonilla G, Quinones AR, Montori VM, International Minimally Disruptive Medicine W. Assessing the Burden of Treatment. Journal of General Internal Medicine 2017; 32 : 1141-1145.
Spencer FA, Iorio A, You J, Murad MH, Schünemann HJ, Vandvik PO, Crowther MA, Pottie K, Lang ES, Meerpohl JJ, Falck-Ytter Y, Alonso-Coello P, Guyatt GH. Uncertainties in baseline risk estimates and confidence in treatment effects. BMJ 2012; 345 : e7401.
Sterne JAC, Hernán MA, Reeves BC, Savović J, Berkman ND, Viswanathan M, Henry D, Altman DG, Ansari MT, Boutron I, Carpenter JR, Chan AW, Churchill R, Deeks JJ, Hróbjartsson A, Kirkham J, Jüni P, Loke YK, Pigott TD, Ramsay CR, Regidor D, Rothstein HR, Sandhu L, Santaguida PL, Schünemann HJ, Shea B, Shrier I, Tugwell P, Turner L, Valentine JC, Waddington H, Waters E, Wells GA, Whiting PF, Higgins JPT. ROBINS-I: a tool for assessing risk of bias in non-randomised studies of interventions. BMJ 2016; 355 : i4919.
Thompson DC, Rivara FP, Thompson R. Helmets for preventing head and facial injuries in bicyclists. Cochrane Database of Systematic Reviews 2000; 2 : CD001855.
Tierney JF, Stewart LA, Ghersi D, Burdett S, Sydes MR. Practical methods for incorporating summary time-to-event data into meta-analysis. Trials 2007; 8 .
van Dalen EC, Tierney JF, Kremer LCM. Tips and tricks for understanding and using SR results. No. 7: time‐to‐event data. Evidence-Based Child Health 2007; 2 : 1089-1090.
For permission to re-use material from the Handbook (either academic or commercial), please see here for full details.
- Departments and Units
- Majors and Minors
- LSA Course Guide
- LSA Gateway
Search: {{$root.lsaSearchQuery.q}}, Page {{$root.page}}
- Accessibility
- Undergraduates
- Instructors
- Alums & Friends
- ★ Writing Support
- Minor in Writing
- First-Year Writing Requirement
- Transfer Students
- Writing Guides
- Peer Writing Consultant Program
- Upper-Level Writing Requirement
- Writing Prizes
- International Students
- ★ The Writing Workshop
- Dissertation ECoach
- Fellows Seminar
- Dissertation Writing Groups
- Rackham / Sweetland Workshops
- Dissertation Writing Institute
- Guides to Teaching Writing
- Teaching Support and Services
- Support for FYWR Courses
- Support for ULWR Courses
- Writing Prize Nominating
- Alums Gallery
- Commencement
- Giving Opportunities
- How Do I Present Findings From My Experiment in a Report?
- How Do I Make Sure I Understand an Assignment?
- How Do I Decide What I Should Argue?
- How Can I Create Stronger Analysis?
- How Do I Effectively Integrate Textual Evidence?
- How Do I Write a Great Title?
- What Exactly is an Abstract?
- What is a Run-on Sentence & How Do I Fix It?
- How Do I Check the Structure of My Argument?
- How Do I Write an Intro, Conclusion, & Body Paragraph?
- How Do I Incorporate Quotes?
- How Can I Create a More Successful Powerpoint?
- How Can I Create a Strong Thesis?
- How Can I Write More Descriptively?
- How Do I Incorporate a Counterargument?
- How Do I Check My Citations?
See the bottom of the main Writing Guides page for licensing information.
Many believe that a scientist’s most difficult job is not conducting an experiment but presenting the results in an effective and coherent way. Even when your methods and technique are sound and your notes are comprehensive, writing a report can be a challenge because organizing and communicating scientific findings requires patience and a thorough grasp of certain conventions. Having a clear understanding of the typical goals and strategies for writing an effective lab report can make the process much less troubling.
General Considerations
It is useful to note that effective scientific writing serves the same purpose that your lab report should. Good scientific writing explains:
- The goal(s) of your experiment
- How you performed the experiment
- The results you obtained
- Why these results are important
While it’s unlikely that you’re going to win the Nobel Prize for your work in an undergraduate laboratory course, tailoring your writing strategies in imitation of professional journals is easier than you might think, since they all follow a consistent pattern. However, your instructor has the final say in determining how your report should be structured and what should appear in each section. Please use the following explanations only to supplement your given writing criteria, rather than thinking of them as an indication of how all lab reports must be written.
In Practice
The Structure of a Report
The traditional experimental report is structured using the acronym “IMRAD” which stands for I ntroduction, M ethods, R esults and D iscussion. The “ A ” is sometimes used to stand for A bstract. For help writing abstracts, please see Sweetland’s resource entitled “What is an abstract, and how do I write one?”
Introduction: “What am I doing here?” The introduction should accomplish what any good introduction does: draw the reader into the paper. To simplify things, follow the “inverted pyramid” structure, which involves narrowing information from the most broad (providing context for your experiment’s place in science) to the most specific (what exactly your experiment is about). Consider the example below.
Most broad: “Caffeine is a mild stimulant that is found in many common beverages, including coffee.”
Less broad: “Common reactions to caffeine use include increased heart rate and increased respiratory rate.”
Slightly more specific (moving closer to your experiment): Previous research has shown that people who consume multiple caffeinated beverages per day are also more likely to be irritable.
Most specific (your experiment): This study examines the emotional states of college students (ages 18-22) after they have consumed three cups of coffee each day.
See how that worked? Each idea became slightly more focused, ending with a brief description of your particular experiment. Here are a couple more tips to keep in mind when writing an introduction:
- Include an overview of the topic in question, including relevant literature A good example: “In 1991, Rogers and Hammerstein concluded that drinking coffee improves alertness and mental focus (citation 1991).
- Explain what your experiment might contribute to past findings A good example: “Despite these established benefits, coffee may negatively impact mood and behavior. This study aims to investigate the emotions of college coffee drinkers during finals week.”
- Keep the introduction brief There’s no real advantage to writing a long introduction. Most people reading your paper already know what coffee is, and where it comes from, so what’s the point of giving them a detailed history of the coffee bean? A good example: “Caffeine is a psychoactive stimulant, much like nicotine.” (Appropriate information, because it gives context to caffeine—the molecule of study) A bad example: “Some of the more popular coffee drinks in America include cappuccinos, lattés, and espresso.” (Inappropriate for your introduction. This information is useless for your audience, because not only is it already familiar, but it doesn’t mention anything about caffeine or its effects, which is the reason that you’re doing the experiment.)
- Avoid giving away the detailed technique and data you gathered in your experiment A good example: “A sample of coffee-drinking college students was observed during end-of-semester exams.” ( Appropriate for an introduction ) A bad example: “25 college students were studied, and each given 10oz of premium dark roast coffee (containing 175mg caffeine/serving, except for Folgers, which has significantly lower caffeine content) three times a day through a plastic straw, with intervals of two hours, for three weeks.” ( Too detailed for an intro. More in-depth information should appear in your “Methods” or “Results” sections. )
Methods: “Where am I going to get all that coffee…?”
A “methods” section should include all the information necessary for someone else to recreate your experiment. Your experimental notes will be very useful for this section of the report. More or less, this section will resemble a recipe for your experiment. Don’t concern yourself with writing clever, engaging prose. Just say what you did, as clearly as possible. Address the types of questions listed below:
- Where did you perform the experiment? (This one is especially important in field research— work done outside the laboratory.)
- How much did you use? (Be precise.)
- Did you change anything about them? (i.e. Each 5 oz of coffee was diluted with 2 oz distilled water.)
- Did you use any special method for recording data? (i.e. After drinking coffee, students’ happiness was measured using the Walter Gumdrop Rating System, on a scale of 1-10.)
- Did you use any techniques/methods that are significant for the research? (i.e. Maybe you did a double blinded experiment with X and Y as controls. Was your control a placebo? Be specific.)
- Any unusual/unique methods for collecting data? If so, why did you use them?
After you have determined the basic content for your “methods” section, consider these other tips:
- Decide between using active or passive voice
There has been much debate over the use of passive voice in scientific writing. “Passive voice” is when the subject of a sentence is the recipient of the action.
- For example: Coffee was given to the students.
“Active voice” is when the subject of a sentence performs the action.
- For example: I gave coffee to the students.
The merits of using passive voice are obvious in some cases. For instance, scientific reports are about what is being studied, and not about YOU. Using too many personal pronouns can make your writing sound more like a narrative and less like a report. For that reason, many people recommend using passive voice to create a more objective, professional tone, emphasizing what was done TO your subject. However, active voice is becoming increasingly common in scientific writing, especially in social sciences, so the ultimate decision of passive vs. active voice is up to you (and whoever is grading your report).
- Units are important When using numbers, it is important to always list units, and keep them consistent throughout the section. There is a big difference between giving someone 150 milligrams of coffee and 150 grams of coffee—the first will keep you awake for a while, and the latter will put you to sleep indefinitely. So make sure you’re consistent in this regard.
- Don’t needlessly explain common techniques If you’re working in a chemistry lab, for example, and you want to take the melting point of caffeine, there’s no point saying “I used the “Melting point-ometer 3000” to take a melting point of caffeine. First I plugged it in…then I turned it on…” Your reader can extrapolate these techniques for him or herself, so a simple “Melting point was recorded” will work just fine.
- If it isn’t important to your results, don’t include it No one cares if you bought the coffee for your experiment on “3 dollar latte day”. The price of the coffee won’t affect the outcome of your experiment, so don’t bore your reader with it. Simply record all the things that WILL affect your results (i.e. masses, volumes, numbers of trials, etc).
Results: The only thing worth reading?
The “results” section is the place to tell your reader what you observed. However, don’t do anything more than “tell.” Things like explaining and analyzing belong in your discussion section. If you find yourself using words like “because” or “which suggests” in your results section, then STOP! You’re giving too much analysis.
A good example: “In this study, 50% of subjects exhibited symptoms of increased anger and annoyance in response to hearing Celine Dion music.” ( Appropriate for a “results” section—it doesn’t get caught up in explaining WHY they were annoyed. )
In your “results” section, you should:
- Display facts and figures in tables and graphs whenever possible. Avoid listing results like “In trial one, there were 5 students out of 10 who showed irritable behavior in response to caffeine. In trial two…” Instead, make a graph or table. Just be sure to label it so you can refer to it in your writing (i.e. “As Table 1 shows, the number of swear words spoken by students increased in proportion to the amount of coffee consumed.”) Likewise, be sure to label every axis/heading on a chart or graph (a good visual representation can be understood on its own without any textual explanation). The following example clearly shows what happened during each trial of an experiment, making the trends visually apparent, and thus saving the experimenter from having to explain each trial with words.
- Identify only the most significant trends. Don’t try to include every single bit of data in this section, because much of it won’t be relevant to your hypothesis. Just pick out the biggest trends, or what is most significant to your goals.
Discussion: “What does it all mean?”
The “discussion” section is intended to explain to your reader what your data can be interpreted to mean. As with all science, the goal for your report is simply to provide evidence that something might be true or untrue—not to prove it unequivocally. The following questions should be addressed in your “discussion” section:
- Is your hypothesis supported? If you didn’t have a specific hypothesis, then were the results consistent with what previous studies have suggested? A good example: “Consistent with caffeine’s observed effects on heart rate, students’ tendency to react strongly to the popping of a balloon strongly suggests that caffeine’s ability to heighten alertness may also increase nervousness.”
- Was there any data that surprised you? Outliers are seldom significant, and mentioning them is largely useless. However, if you see another cluster of points on a graph that establish their own trend, this is worth mentioning.
- Are the results useful? If you have no significant findings, then just say that. Don’t try to make wild claims about the meanings of your work if there is no statistical/observational basis for these claims—doing so is dishonest and unhelpful to other scientists reading your work. Similarly, try to avoid using the word “proof” or “proves.” Your work is merely suggesting evidence for new ideas. Just because things worked out one way in your trials, that doesn’t mean these results will always be repeatable or true.
- What are the implications of your work? Here are some examples of the types of questions that can begin to show how your study can be significant outside of this one particular experiment: Why should anyone care about what you’re saying? How might these findings affect coffee drinkers? Do your findings suggest that drinking coffee is more harmful than previously thought? Less harmful? How might these findings affect other fields of science? What about the effects of caffeine on people with emotional disorders? Do your findings suggest that they should or should not drink coffee?
- Any shortcomings of your work? Were there any flaws in your experimental design? How should future studies in this field accommodate for these complications. Does your research raise any new questions? What other areas of science should be explored as a result of your work?
Resources: Hogg, Alan. "Tutoring Scientific Writing." Sweetland Center for Writing. University of Michigan, Ann Arbor. 3/15/2011. Lecture. Swan, Judith A, and George D. Gopen. "The Science of Scientific Writing." American Scientist . 78. (1990): 550-558. Print. "Scientific Reports." The Writing Center . University of North Carolina, n.d. Web. 5 May 2011. http://www.unc.edu/depts/wcweb/handouts/lab_report_complete.html
- Information For
- Prospective Students
- Current Students
- Faculty and Staff
- Alumni and Friends
- More about LSA
- How Do I Apply?
- LSA Magazine
- Student Resources
- Academic Advising
- Global Studies
- LSA Opportunity Hub
- Social Media
- Update Contact Info
- Privacy Statement
- Report Feedback
When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
- How to Write Discussions and Conclusions

The discussion section contains the results and outcomes of a study. An effective discussion informs readers what can be learned from your experiment and provides context for the results.
What makes an effective discussion?
When you’re ready to write your discussion, you’ve already introduced the purpose of your study and provided an in-depth description of the methodology. The discussion informs readers about the larger implications of your study based on the results. Highlighting these implications while not overstating the findings can be challenging, especially when you’re submitting to a journal that selects articles based on novelty or potential impact. Regardless of what journal you are submitting to, the discussion section always serves the same purpose: concluding what your study results actually mean.
A successful discussion section puts your findings in context. It should include:
- the results of your research,
- a discussion of related research, and
- a comparison between your results and initial hypothesis.
Tip: Not all journals share the same naming conventions.
You can apply the advice in this article to the conclusion, results or discussion sections of your manuscript.
Our Early Career Researcher community tells us that the conclusion is often considered the most difficult aspect of a manuscript to write. To help, this guide provides questions to ask yourself, a basic structure to model your discussion off of and examples from published manuscripts.
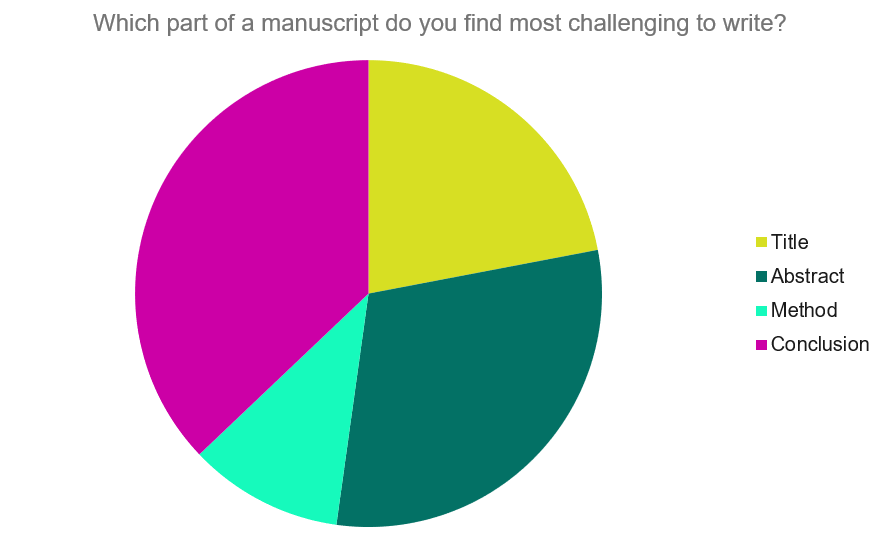
Questions to ask yourself:
- Was my hypothesis correct?
- If my hypothesis is partially correct or entirely different, what can be learned from the results?
- How do the conclusions reshape or add onto the existing knowledge in the field? What does previous research say about the topic?
- Why are the results important or relevant to your audience? Do they add further evidence to a scientific consensus or disprove prior studies?
- How can future research build on these observations? What are the key experiments that must be done?
- What is the “take-home” message you want your reader to leave with?
How to structure a discussion
Trying to fit a complete discussion into a single paragraph can add unnecessary stress to the writing process. If possible, you’ll want to give yourself two or three paragraphs to give the reader a comprehensive understanding of your study as a whole. Here’s one way to structure an effective discussion:
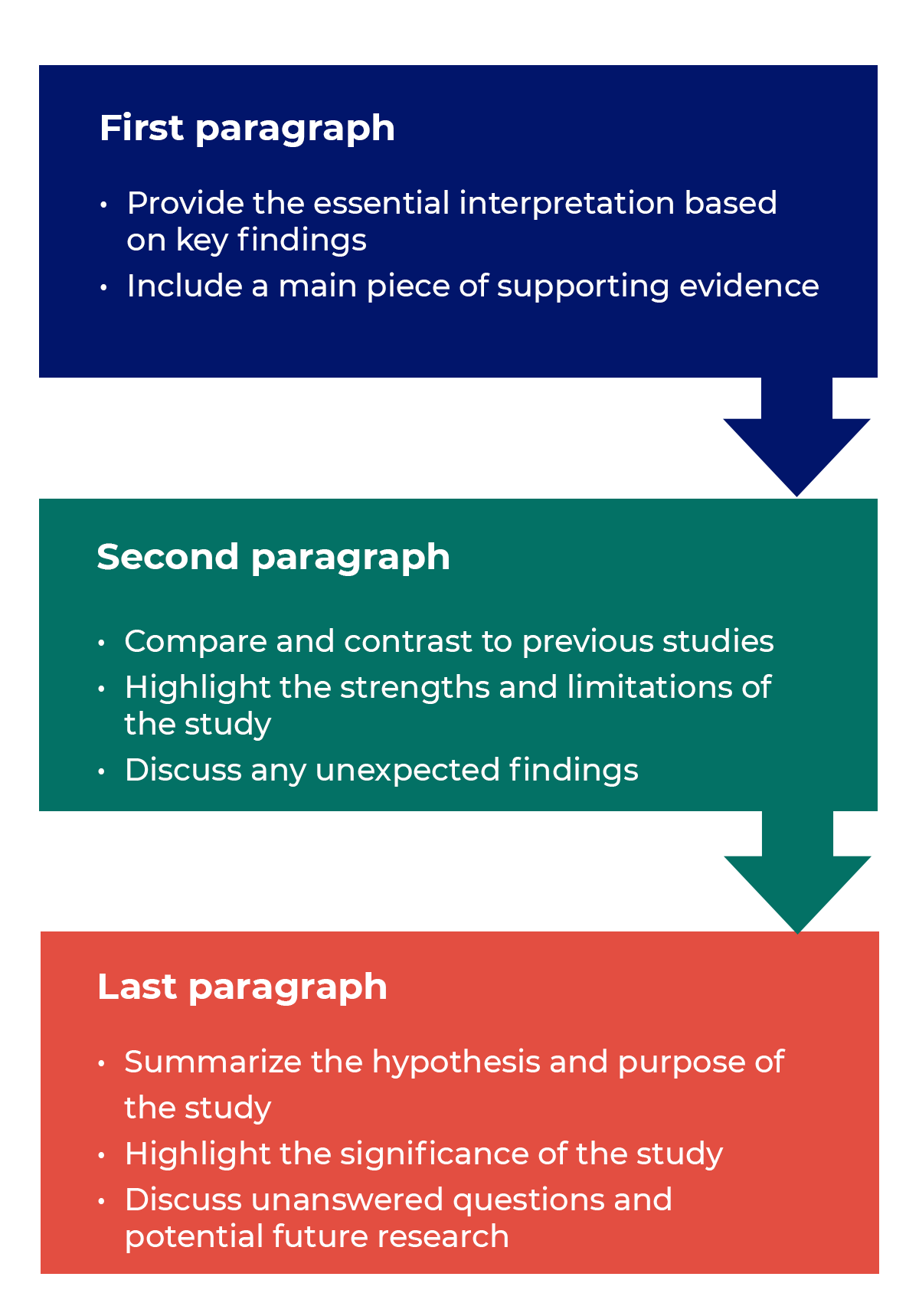
Writing Tips
While the above sections can help you brainstorm and structure your discussion, there are many common mistakes that writers revert to when having difficulties with their paper. Writing a discussion can be a delicate balance between summarizing your results, providing proper context for your research and avoiding introducing new information. Remember that your paper should be both confident and honest about the results!

- Read the journal’s guidelines on the discussion and conclusion sections. If possible, learn about the guidelines before writing the discussion to ensure you’re writing to meet their expectations.
- Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion.
- Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and limitations of the research.
- State whether the results prove or disprove your hypothesis. If your hypothesis was disproved, what might be the reasons?
- Introduce new or expanded ways to think about the research question. Indicate what next steps can be taken to further pursue any unresolved questions.
- If dealing with a contemporary or ongoing problem, such as climate change, discuss possible consequences if the problem is avoided.
- Be concise. Adding unnecessary detail can distract from the main findings.

Don’t
- Rewrite your abstract. Statements with “we investigated” or “we studied” generally do not belong in the discussion.
- Include new arguments or evidence not previously discussed. Necessary information and evidence should be introduced in the main body of the paper.
- Apologize. Even if your research contains significant limitations, don’t undermine your authority by including statements that doubt your methodology or execution.
- Shy away from speaking on limitations or negative results. Including limitations and negative results will give readers a complete understanding of the presented research. Potential limitations include sources of potential bias, threats to internal or external validity, barriers to implementing an intervention and other issues inherent to the study design.
- Overstate the importance of your findings. Making grand statements about how a study will fully resolve large questions can lead readers to doubt the success of the research.
Snippets of Effective Discussions:
Consumer-based actions to reduce plastic pollution in rivers: A multi-criteria decision analysis approach
Identifying reliable indicators of fitness in polar bears
- How to Write a Great Title
- How to Write an Abstract
- How to Write Your Methods
- How to Report Statistics
- How to Edit Your Work
The contents of the Peer Review Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
The contents of the Writing Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
There’s a lot to consider when deciding where to submit your work. Learn how to choose a journal that will help your study reach its audience, while reflecting your values as a researcher…

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
5.6: Experimental Research (Summary)
- Last updated
- Save as PDF
- Page ID 19650

- Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton
- Kwantlen Polytechnic U., Washington State U., & Texas A&M U.—Texarkana
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Key Takeaways
- An experiment is a type of empirical study that features the manipulation of an independent variable, the measurement of a dependent variable, and control of extraneous variables.
- An extraneous variable is any variable other than the independent and dependent variables. A confound is an extraneous variable that varies systematically with the independent variable.
- Experimental research on the effectiveness of a treatment requires both a treatment condition and a control condition, which can be a no-treatment control condition, a placebo control condition, or a wait-list control condition. Experimental treatments can also be compared with the best available alternative.
- Experiments can be conducted using either between-subjects or within-subjects designs. Deciding which to use in a particular situation requires careful consideration of the pros and cons of each approach.
- Random assignment to conditions in between-subjects experiments or counterbalancing of orders of conditions in within-subjects experiments is a fundamental element of experimental research. The purpose of these techniques is to control extraneous variables so that they do not become confounding variables.
- Studies are high in internal validity to the extent that the way they are conducted supports the conclusion that the independent variable caused any observed differences in the dependent variable. Experiments are generally high in internal validity because of the manipulation of the independent variable and control of extraneous variables.
- Studies are high in external validity to the extent that the result can be generalized to people and situations beyond those actually studied. Although experiments can seem “artificial”—and low in external validity—it is important to consider whether the psychological processes under study are likely to operate in other people and situations.
- There are several effective methods you can use to recruit research participants for your experiment, including through formal subject pools, advertisements, and personal appeals. Field experiments require well-defined participant selection procedures.
- It is important to standardize experimental procedures to minimize extraneous variables, including experimenter expectancy effects.
- It is important to conduct one or more small-scale pilot tests of an experiment to be sure that the procedure works as planned.
Bauman, C.W., McGraw, A.P., Bartels, D.M., & Warren, C. (2014). Revisiting external validity: Concerns about trolley problems and other sacrificial dilemmas in moral psychology. Social and Personality Psychology Compass, 8/9 , 536-554.
Birnbaum, M.H. (1999). How to show that 9>221: Collect judgments in a between-subjects design. Psychological Methods, 4 (3), 243-249.
Cialdini, R. (2005, April). Don’t throw in the towel: Use social influence research. APS Observer. Retrieved from http ://www.psychologicalscience.org/index.php/publications/observer/2005/april-05/dont-throw-in-the-towel-use-social-influence-research.html
Darley, J. M., & Latané, B. (1968). Bystander intervention in emergencies: Diffusion of responsibility. Journal of Personality and Social Psychology, 4 , 377–383.
Fredrickson, B. L., Roberts, T.-A., Noll, S. M., Quinn, D. M., & Twenge, J. M. (1998). The swimsuit becomes you: Sex differences in self-objectification, restrained eating, and math performance. Journal of Personality and Social Psychology, 75 , 269–284.
Goldstein, N. J., Cialdini, R. B., & Griskevicius, V. (2008). A room with a viewpoint: Using social norms to motivate environmental conservation in hotels. Journal of Consumer Research, 35 , 472–482.
Guéguen, N., & de Gail, Marie-Agnès. (2003). The effect of smiling on helping behavior: Smiling and good Samaritan behavior. Communication Reports, 16 , 133–140.
Ibolya, K., Brake, A., & Voss, U. (2004). The effect of experimenter characteristics on pain reports in women and men. Pain, 112 , 142–147.
Judd, C.M. & Kenny, D.A. (1981). Estimating the effects of social interventions . Cambridge, MA: Cambridge University Press.
Knecht, S., Dräger, B., Deppe, M., Bobe, L., Lohmann, H., Flöel, A., . . . Henningsen, H. (2000). Handedness and hemispheric language dominance in healthy humans. Brain: A Journal of Neurology, 123 (12), 2512-2518. http://dx.doi.org/10.1093/brain/123.12.2512
Manning, R., Levine, M., & Collins, A. (2007). The Kitty Genovese murder and the social psychology of helping: The parable of the 38 witnesses. American Psychologist, 62 , 555–562.
Morling, B. (2014, April). Teach your students to be better consumers. APS Observer . Retrieved from http ://www.psychologicalscience.org/index.php/publications/observer/2014/april-14/teach-your-students-to-be-better-consumers.html
Moseley, J. B., O’Malley, K., Petersen, N. J., Menke, T. J., Brody, B. A., Kuykendall, D. H., … Wray, N. P. (2002). A controlled trial of arthroscopic surgery for osteoarthritis of the knee. The New England Journal of Medicine, 347 , 81–88.
Price, D. D., Finniss, D. G., & Benedetti, F. (2008). A comprehensive review of the placebo effect: Recent advances and current thought. Annual Review of Psychology, 59 , 565–590.
Rosenthal, R., & Fode, K. (1963). The effect of experimenter bias on performance of the albino rat. Behavioral Science, 8 , 183-189.
Rosenthal, R., & Rosnow, R. L. (1976). The volunteer subject . New York, NY: Wiley.
Rosenthal, R. (1976). Experimenter effects in behavioral research (enlarged ed.). New York, NY: Wiley.
Shapiro, A. K., & Shapiro, E. (1999). The powerful placebo: From ancient priest to modern physician . Baltimore, MD: Johns Hopkins University Press.
- Practice: List five variables that can be manipulated by the researcher in an experiment. List five variables that cannot be manipulated by the researcher in an experiment.
- Effect of parietal lobe damage on people’s ability to do basic arithmetic.
- Effect of being clinically depressed on the number of close friendships people have.
- Effect of group training on the social skills of teenagers with Asperger’s syndrome.
- Effect of paying people to take an IQ test on their performance on that test.
- Discussion: Imagine that an experiment shows that participants who receive psychodynamic therapy for a dog phobia improve more than participants in a no-treatment control group. Explain a fundamental problem with this research design and at least two ways that it might be corrected.
- You want to test the relative effectiveness of two training programs for running a marathon.
- Using photographs of people as stimuli, you want to see if smiling people are perceived as more intelligent than people who are not smiling.
- In a field experiment, you want to see if the way a panhandler is dressed (neatly vs. sloppily) affects whether or not passersby give him any money.
- You want to see if concrete nouns (e.g., dog) are recalled better than abstract nouns (e.g., truth).
- elderly adults
- unemployed people
- regular exercisers
- math majors
- Discussion: Imagine a study in which you will visually present participants with a list of 20 words, one at a time, wait for a short time, and then ask them to recall as many of the words as they can. In the stressed condition, they are told that they might also be chosen to give a short speech in front of a small audience. In the unstressed condition, they are not told that they might have to give a speech. What are several specific things that you could do to standardize the procedure?
- Affiliate Program

- UNITED STATES
- 台灣 (TAIWAN)
- TÜRKIYE (TURKEY)
- Academic Editing Services
- - Research Paper
- - Journal Manuscript
- - Dissertation
- - College & University Assignments
- Admissions Editing Services
- - Application Essay
- - Personal Statement
- - Recommendation Letter
- - Cover Letter
- - CV/Resume
- Business Editing Services
- - Business Documents
- - Report & Brochure
- - Website & Blog
- Writer Editing Services
- - Script & Screenplay
- Our Editors
- Client Reviews
- Editing & Proofreading Prices
- Wordvice Points
- Partner Discount
- Plagiarism Checker
- APA Citation Generator
- MLA Citation Generator
- Chicago Citation Generator
- Vancouver Citation Generator
- - APA Style
- - MLA Style
- - Chicago Style
- - Vancouver Style
- Writing & Editing Guide
- Academic Resources
- Admissions Resources
How to Write the Results/Findings Section in Research
What is the research paper Results section and what does it do?
The Results section of a scientific research paper represents the core findings of a study derived from the methods applied to gather and analyze information. It presents these findings in a logical sequence without bias or interpretation from the author, setting up the reader for later interpretation and evaluation in the Discussion section. A major purpose of the Results section is to break down the data into sentences that show its significance to the research question(s).
The Results section appears third in the section sequence in most scientific papers. It follows the presentation of the Methods and Materials and is presented before the Discussion section —although the Results and Discussion are presented together in many journals. This section answers the basic question “What did you find in your research?”
What is included in the Results section?
The Results section should include the findings of your study and ONLY the findings of your study. The findings include:
- Data presented in tables, charts, graphs, and other figures (may be placed into the text or on separate pages at the end of the manuscript)
- A contextual analysis of this data explaining its meaning in sentence form
- All data that corresponds to the central research question(s)
- All secondary findings (secondary outcomes, subgroup analyses, etc.)
If the scope of the study is broad, or if you studied a variety of variables, or if the methodology used yields a wide range of different results, the author should present only those results that are most relevant to the research question stated in the Introduction section .
As a general rule, any information that does not present the direct findings or outcome of the study should be left out of this section. Unless the journal requests that authors combine the Results and Discussion sections, explanations and interpretations should be omitted from the Results.
How are the results organized?
The best way to organize your Results section is “logically.” One logical and clear method of organizing research results is to provide them alongside the research questions—within each research question, present the type of data that addresses that research question.
Let’s look at an example. Your research question is based on a survey among patients who were treated at a hospital and received postoperative care. Let’s say your first research question is:

“What do hospital patients over age 55 think about postoperative care?”
This can actually be represented as a heading within your Results section, though it might be presented as a statement rather than a question:
Attitudes towards postoperative care in patients over the age of 55
Now present the results that address this specific research question first. In this case, perhaps a table illustrating data from a survey. Likert items can be included in this example. Tables can also present standard deviations, probabilities, correlation matrices, etc.
Following this, present a content analysis, in words, of one end of the spectrum of the survey or data table. In our example case, start with the POSITIVE survey responses regarding postoperative care, using descriptive phrases. For example:
“Sixty-five percent of patients over 55 responded positively to the question “ Are you satisfied with your hospital’s postoperative care ?” (Fig. 2)
Include other results such as subcategory analyses. The amount of textual description used will depend on how much interpretation of tables and figures is necessary and how many examples the reader needs in order to understand the significance of your research findings.
Next, present a content analysis of another part of the spectrum of the same research question, perhaps the NEGATIVE or NEUTRAL responses to the survey. For instance:
“As Figure 1 shows, 15 out of 60 patients in Group A responded negatively to Question 2.”
After you have assessed the data in one figure and explained it sufficiently, move on to your next research question. For example:
“How does patient satisfaction correspond to in-hospital improvements made to postoperative care?”

This kind of data may be presented through a figure or set of figures (for instance, a paired T-test table).
Explain the data you present, here in a table, with a concise content analysis:
“The p-value for the comparison between the before and after groups of patients was .03% (Fig. 2), indicating that the greater the dissatisfaction among patients, the more frequent the improvements that were made to postoperative care.”
Let’s examine another example of a Results section from a study on plant tolerance to heavy metal stress . In the Introduction section, the aims of the study are presented as “determining the physiological and morphological responses of Allium cepa L. towards increased cadmium toxicity” and “evaluating its potential to accumulate the metal and its associated environmental consequences.” The Results section presents data showing how these aims are achieved in tables alongside a content analysis, beginning with an overview of the findings:
“Cadmium caused inhibition of root and leave elongation, with increasing effects at higher exposure doses (Fig. 1a-c).”
The figure containing this data is cited in parentheses. Note that this author has combined three graphs into one single figure. Separating the data into separate graphs focusing on specific aspects makes it easier for the reader to assess the findings, and consolidating this information into one figure saves space and makes it easy to locate the most relevant results.

Following this overall summary, the relevant data in the tables is broken down into greater detail in text form in the Results section.
- “Results on the bio-accumulation of cadmium were found to be the highest (17.5 mg kgG1) in the bulb, when the concentration of cadmium in the solution was 1×10G2 M and lowest (0.11 mg kgG1) in the leaves when the concentration was 1×10G3 M.”
Captioning and Referencing Tables and Figures
Tables and figures are central components of your Results section and you need to carefully think about the most effective way to use graphs and tables to present your findings . Therefore, it is crucial to know how to write strong figure captions and to refer to them within the text of the Results section.
The most important advice one can give here as well as throughout the paper is to check the requirements and standards of the journal to which you are submitting your work. Every journal has its own design and layout standards, which you can find in the author instructions on the target journal’s website. Perusing a journal’s published articles will also give you an idea of the proper number, size, and complexity of your figures.
Regardless of which format you use, the figures should be placed in the order they are referenced in the Results section and be as clear and easy to understand as possible. If there are multiple variables being considered (within one or more research questions), it can be a good idea to split these up into separate figures. Subsequently, these can be referenced and analyzed under separate headings and paragraphs in the text.
To create a caption, consider the research question being asked and change it into a phrase. For instance, if one question is “Which color did participants choose?”, the caption might be “Color choice by participant group.” Or in our last research paper example, where the question was “What is the concentration of cadmium in different parts of the onion after 14 days?” the caption reads:
“Fig. 1(a-c): Mean concentration of Cd determined in (a) bulbs, (b) leaves, and (c) roots of onions after a 14-day period.”
Steps for Composing the Results Section
Because each study is unique, there is no one-size-fits-all approach when it comes to designing a strategy for structuring and writing the section of a research paper where findings are presented. The content and layout of this section will be determined by the specific area of research, the design of the study and its particular methodologies, and the guidelines of the target journal and its editors. However, the following steps can be used to compose the results of most scientific research studies and are essential for researchers who are new to preparing a manuscript for publication or who need a reminder of how to construct the Results section.
Step 1 : Consult the guidelines or instructions that the target journal or publisher provides authors and read research papers it has published, especially those with similar topics, methods, or results to your study.
- The guidelines will generally outline specific requirements for the results or findings section, and the published articles will provide sound examples of successful approaches.
- Note length limitations on restrictions on content. For instance, while many journals require the Results and Discussion sections to be separate, others do not—qualitative research papers often include results and interpretations in the same section (“Results and Discussion”).
- Reading the aims and scope in the journal’s “ guide for authors ” section and understanding the interests of its readers will be invaluable in preparing to write the Results section.
Step 2 : Consider your research results in relation to the journal’s requirements and catalogue your results.
- Focus on experimental results and other findings that are especially relevant to your research questions and objectives and include them even if they are unexpected or do not support your ideas and hypotheses.
- Catalogue your findings—use subheadings to streamline and clarify your report. This will help you avoid excessive and peripheral details as you write and also help your reader understand and remember your findings. Create appendices that might interest specialists but prove too long or distracting for other readers.
- Decide how you will structure of your results. You might match the order of the research questions and hypotheses to your results, or you could arrange them according to the order presented in the Methods section. A chronological order or even a hierarchy of importance or meaningful grouping of main themes or categories might prove effective. Consider your audience, evidence, and most importantly, the objectives of your research when choosing a structure for presenting your findings.
Step 3 : Design figures and tables to present and illustrate your data.
- Tables and figures should be numbered according to the order in which they are mentioned in the main text of the paper.
- Information in figures should be relatively self-explanatory (with the aid of captions), and their design should include all definitions and other information necessary for readers to understand the findings without reading all of the text.
- Use tables and figures as a focal point to tell a clear and informative story about your research and avoid repeating information. But remember that while figures clarify and enhance the text, they cannot replace it.
Step 4 : Draft your Results section using the findings and figures you have organized.
- The goal is to communicate this complex information as clearly and precisely as possible; precise and compact phrases and sentences are most effective.
- In the opening paragraph of this section, restate your research questions or aims to focus the reader’s attention to what the results are trying to show. It is also a good idea to summarize key findings at the end of this section to create a logical transition to the interpretation and discussion that follows.
- Try to write in the past tense and the active voice to relay the findings since the research has already been done and the agent is usually clear. This will ensure that your explanations are also clear and logical.
- Make sure that any specialized terminology or abbreviation you have used here has been defined and clarified in the Introduction section .
Step 5 : Review your draft; edit and revise until it reports results exactly as you would like to have them reported to your readers.
- Double-check the accuracy and consistency of all the data, as well as all of the visual elements included.
- Read your draft aloud to catch language errors (grammar, spelling, and mechanics), awkward phrases, and missing transitions.
- Ensure that your results are presented in the best order to focus on objectives and prepare readers for interpretations, valuations, and recommendations in the Discussion section . Look back over the paper’s Introduction and background while anticipating the Discussion and Conclusion sections to ensure that the presentation of your results is consistent and effective.
- Consider seeking additional guidance on your paper. Find additional readers to look over your Results section and see if it can be improved in any way. Peers, professors, or qualified experts can provide valuable insights.
One excellent option is to use a professional English proofreading and editing service such as Wordvice, including our paper editing service . With hundreds of qualified editors from dozens of scientific fields, Wordvice has helped thousands of authors revise their manuscripts and get accepted into their target journals. Read more about the proofreading and editing process before proceeding with getting academic editing services and manuscript editing services for your manuscript.
As the representation of your study’s data output, the Results section presents the core information in your research paper. By writing with clarity and conciseness and by highlighting and explaining the crucial findings of their study, authors increase the impact and effectiveness of their research manuscripts.
For more articles and videos on writing your research manuscript, visit Wordvice’s Resources page.
Wordvice Resources
- How to Write a Research Paper Introduction
- Which Verb Tenses to Use in a Research Paper
- How to Write an Abstract for a Research Paper
- How to Write a Research Paper Title
- Useful Phrases for Academic Writing
- Common Transition Terms in Academic Papers
- Active and Passive Voice in Research Papers
- 100+ Verbs That Will Make Your Research Writing Amazing
- Tips for Paraphrasing in Research Papers
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- A Quick Guide to Experimental Design | 5 Steps & Examples
A Quick Guide to Experimental Design | 5 Steps & Examples
Published on 11 April 2022 by Rebecca Bevans . Revised on 5 December 2022.
Experiments are used to study causal relationships . You manipulate one or more independent variables and measure their effect on one or more dependent variables.
Experimental design means creating a set of procedures to systematically test a hypothesis . A good experimental design requires a strong understanding of the system you are studying.
There are five key steps in designing an experiment:
- Consider your variables and how they are related
- Write a specific, testable hypothesis
- Design experimental treatments to manipulate your independent variable
- Assign subjects to groups, either between-subjects or within-subjects
- Plan how you will measure your dependent variable
For valid conclusions, you also need to select a representative sample and control any extraneous variables that might influence your results. If if random assignment of participants to control and treatment groups is impossible, unethical, or highly difficult, consider an observational study instead.
Table of contents
Step 1: define your variables, step 2: write your hypothesis, step 3: design your experimental treatments, step 4: assign your subjects to treatment groups, step 5: measure your dependent variable, frequently asked questions about experimental design.
You should begin with a specific research question . We will work with two research question examples, one from health sciences and one from ecology:
To translate your research question into an experimental hypothesis, you need to define the main variables and make predictions about how they are related.
Start by simply listing the independent and dependent variables .
Then you need to think about possible extraneous and confounding variables and consider how you might control them in your experiment.
Finally, you can put these variables together into a diagram. Use arrows to show the possible relationships between variables and include signs to show the expected direction of the relationships.

Here we predict that increasing temperature will increase soil respiration and decrease soil moisture, while decreasing soil moisture will lead to decreased soil respiration.
Prevent plagiarism, run a free check.
Now that you have a strong conceptual understanding of the system you are studying, you should be able to write a specific, testable hypothesis that addresses your research question.
The next steps will describe how to design a controlled experiment . In a controlled experiment, you must be able to:
- Systematically and precisely manipulate the independent variable(s).
- Precisely measure the dependent variable(s).
- Control any potential confounding variables.
If your study system doesn’t match these criteria, there are other types of research you can use to answer your research question.
How you manipulate the independent variable can affect the experiment’s external validity – that is, the extent to which the results can be generalised and applied to the broader world.
First, you may need to decide how widely to vary your independent variable.
- just slightly above the natural range for your study region.
- over a wider range of temperatures to mimic future warming.
- over an extreme range that is beyond any possible natural variation.
Second, you may need to choose how finely to vary your independent variable. Sometimes this choice is made for you by your experimental system, but often you will need to decide, and this will affect how much you can infer from your results.
- a categorical variable : either as binary (yes/no) or as levels of a factor (no phone use, low phone use, high phone use).
- a continuous variable (minutes of phone use measured every night).
How you apply your experimental treatments to your test subjects is crucial for obtaining valid and reliable results.
First, you need to consider the study size : how many individuals will be included in the experiment? In general, the more subjects you include, the greater your experiment’s statistical power , which determines how much confidence you can have in your results.
Then you need to randomly assign your subjects to treatment groups . Each group receives a different level of the treatment (e.g. no phone use, low phone use, high phone use).
You should also include a control group , which receives no treatment. The control group tells us what would have happened to your test subjects without any experimental intervention.
When assigning your subjects to groups, there are two main choices you need to make:
- A completely randomised design vs a randomised block design .
- A between-subjects design vs a within-subjects design .
Randomisation
An experiment can be completely randomised or randomised within blocks (aka strata):
- In a completely randomised design , every subject is assigned to a treatment group at random.
- In a randomised block design (aka stratified random design), subjects are first grouped according to a characteristic they share, and then randomly assigned to treatments within those groups.
Sometimes randomisation isn’t practical or ethical , so researchers create partially-random or even non-random designs. An experimental design where treatments aren’t randomly assigned is called a quasi-experimental design .
Between-subjects vs within-subjects
In a between-subjects design (also known as an independent measures design or classic ANOVA design), individuals receive only one of the possible levels of an experimental treatment.
In medical or social research, you might also use matched pairs within your between-subjects design to make sure that each treatment group contains the same variety of test subjects in the same proportions.
In a within-subjects design (also known as a repeated measures design), every individual receives each of the experimental treatments consecutively, and their responses to each treatment are measured.
Within-subjects or repeated measures can also refer to an experimental design where an effect emerges over time, and individual responses are measured over time in order to measure this effect as it emerges.
Counterbalancing (randomising or reversing the order of treatments among subjects) is often used in within-subjects designs to ensure that the order of treatment application doesn’t influence the results of the experiment.
Finally, you need to decide how you’ll collect data on your dependent variable outcomes. You should aim for reliable and valid measurements that minimise bias or error.
Some variables, like temperature, can be objectively measured with scientific instruments. Others may need to be operationalised to turn them into measurable observations.
- Ask participants to record what time they go to sleep and get up each day.
- Ask participants to wear a sleep tracker.
How precisely you measure your dependent variable also affects the kinds of statistical analysis you can use on your data.
Experiments are always context-dependent, and a good experimental design will take into account all of the unique considerations of your study system to produce information that is both valid and relevant to your research question.
Experimental designs are a set of procedures that you plan in order to examine the relationship between variables that interest you.
To design a successful experiment, first identify:
- A testable hypothesis
- One or more independent variables that you will manipulate
- One or more dependent variables that you will measure
When designing the experiment, first decide:
- How your variable(s) will be manipulated
- How you will control for any potential confounding or lurking variables
- How many subjects you will include
- How you will assign treatments to your subjects
The key difference between observational studies and experiments is that, done correctly, an observational study will never influence the responses or behaviours of participants. Experimental designs will have a treatment condition applied to at least a portion of participants.
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word ‘between’ means that you’re comparing different conditions between groups, while the word ‘within’ means you’re comparing different conditions within the same group.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bevans, R. (2022, December 05). A Quick Guide to Experimental Design | 5 Steps & Examples. Scribbr. Retrieved 21 May 2024, from https://www.scribbr.co.uk/research-methods/guide-to-experimental-design/
Is this article helpful?

Rebecca Bevans
Experimental Research: Definition, Types, Design, Examples
Appinio Research · 14.05.2024 · 31min read

Experimental research is a cornerstone of scientific inquiry, providing a systematic approach to understanding cause-and-effect relationships and advancing knowledge in various fields. At its core, experimental research involves manipulating variables, observing outcomes, and drawing conclusions based on empirical evidence. By controlling factors that could influence the outcome, researchers can isolate the effects of specific variables and make reliable inferences about their impact. This guide offers a step-by-step exploration of experimental research, covering key elements such as research design, data collection, analysis, and ethical considerations. Whether you're a novice researcher seeking to understand the basics or an experienced scientist looking to refine your experimental techniques, this guide will equip you with the knowledge and tools needed to conduct rigorous and insightful research.
What is Experimental Research?
Experimental research is a systematic approach to scientific inquiry that aims to investigate cause-and-effect relationships by manipulating independent variables and observing their effects on dependent variables. Experimental research primarily aims to test hypotheses, make predictions, and draw conclusions based on empirical evidence.
By controlling extraneous variables and randomizing participant assignment, researchers can isolate the effects of specific variables and establish causal relationships. Experimental research is characterized by its rigorous methodology, emphasis on objectivity, and reliance on empirical data to support conclusions.
Importance of Experimental Research
- Establishing Cause-and-Effect Relationships : Experimental research allows researchers to establish causal relationships between variables by systematically manipulating independent variables and observing their effects on dependent variables. This provides valuable insights into the underlying mechanisms driving phenomena and informs theory development.
- Testing Hypotheses and Making Predictions : Experimental research provides a structured framework for testing hypotheses and predicting the relationship between variables . By systematically manipulating variables and controlling for confounding factors, researchers can empirically test the validity of their hypotheses and refine theoretical models.
- Informing Evidence-Based Practice : Experimental research generates empirical evidence that informs evidence-based practice in various fields, including healthcare, education, and business. Experimental research contributes to improving outcomes and informing decision-making in real-world settings by identifying effective interventions, treatments, and strategies.
- Driving Innovation and Advancement : Experimental research drives innovation and advancement by uncovering new insights, challenging existing assumptions, and pushing the boundaries of knowledge. Through rigorous experimentation and empirical validation, researchers can develop novel solutions to complex problems and contribute to the advancement of science and technology.
- Enhancing Research Rigor and Validity : Experimental research upholds high research rigor and validity standards by employing systematic methods, controlling for confounding variables, and ensuring replicability of findings. By adhering to rigorous methodology and ethical principles, experimental research produces reliable and credible evidence that withstands scrutiny and contributes to the cumulative body of knowledge.
Experimental research plays a pivotal role in advancing scientific understanding, informing evidence-based practice, and driving innovation across various disciplines. By systematically testing hypotheses, establishing causal relationships, and generating empirical evidence, experimental research contributes to the collective pursuit of knowledge and the improvement of society.
Understanding Experimental Design
Experimental design serves as the blueprint for your study, outlining how you'll manipulate variables and control factors to draw valid conclusions.
Experimental Design Components
Experimental design comprises several essential elements:
- Independent Variable (IV) : This is the variable manipulated by the researcher. It's what you change to observe its effect on the dependent variable. For example, in a study testing the impact of different study techniques on exam scores, the independent variable might be the study method (e.g., flashcards, reading, or practice quizzes).
- Dependent Variable (DV) : The dependent variable is what you measure to assess the effect of the independent variable. It's the outcome variable affected by the manipulation of the independent variable. In our study example, the dependent variable would be the exam scores.
- Control Variables : These factors could influence the outcome but are kept constant or controlled to isolate the effect of the independent variable. Controlling variables helps ensure that any observed changes in the dependent variable can be attributed to manipulating the independent variable rather than other factors.
- Experimental Group : This group receives the treatment or intervention being tested. It's exposed to the manipulated independent variable. In contrast, the control group does not receive the treatment and serves as a baseline for comparison.
Types of Experimental Designs
Experimental designs can vary based on the research question, the nature of the variables, and the desired level of control. Here are some common types:
- Between-Subjects Design : In this design, different groups of participants are exposed to varying levels of the independent variable. Each group represents a different experimental condition, and participants are only exposed to one condition. For instance, in a study comparing the effectiveness of two teaching methods, one group of students would use Method A, while another would use Method B.
- Within-Subjects Design : Also known as repeated measures design , this approach involves exposing the same group of participants to all levels of the independent variable. Participants serve as their own controls, and the order of conditions is typically counterbalanced to control for order effects. For example, participants might be tested on their reaction times under different lighting conditions, with the order of conditions randomized to eliminate any research bias .
- Mixed Designs : Mixed designs combine elements of both between-subjects and within-subjects designs. This allows researchers to examine both between-group differences and within-group changes over time. Mixed designs help study complex phenomena that involve multiple variables and temporal dynamics.
Factors Influencing Experimental Design Choices
Several factors influence the selection of an appropriate experimental design:
- Research Question : The nature of your research question will guide your choice of experimental design. Some questions may be better suited to between-subjects designs, while others may require a within-subjects approach.
- Variables : Consider the number and type of variables involved in your study. A factorial design might be appropriate if you're interested in exploring multiple factors simultaneously. Conversely, if you're focused on investigating the effects of a single variable, a simpler design may suffice.
- Practical Considerations : Practical constraints such as time, resources, and access to participants can impact your choice of experimental design. Depending on your study's specific requirements, some designs may be more feasible or cost-effective than others .
- Ethical Considerations : Ethical concerns, such as the potential risks to participants or the need to minimize harm, should also inform your experimental design choices. Ensure that your design adheres to ethical guidelines and safeguards the rights and well-being of participants.
By carefully considering these factors and selecting an appropriate experimental design, you can ensure that your study is well-designed and capable of yielding meaningful insights.
Experimental Research Elements
When conducting experimental research, understanding the key elements is crucial for designing and executing a robust study. Let's explore each of these elements in detail to ensure your experiment is well-planned and executed effectively.
Independent and Dependent Variables
In experimental research, the independent variable (IV) is the factor that the researcher manipulates or controls, while the dependent variable (DV) is the measured outcome or response. The independent variable is what you change in the experiment to observe its effect on the dependent variable.
For example, in a study investigating the effect of different fertilizers on plant growth, the type of fertilizer used would be the independent variable, while the plant growth (height, number of leaves, etc.) would be the dependent variable.
Control Groups and Experimental Groups
Control groups and experimental groups are essential components of experimental design. The control group serves as a baseline for comparison and does not receive the treatment or intervention being studied. Its purpose is to provide a reference point to assess the effects of the independent variable.
In contrast, the experimental group receives the treatment or intervention and is used to measure the impact of the independent variable. For example, in a drug trial, the control group would receive a placebo, while the experimental group would receive the actual medication.
Randomization and Random Sampling
Randomization is the process of randomly assigning participants to different experimental conditions to minimize biases and ensure that each participant has an equal chance of being assigned to any condition. Randomization helps control for extraneous variables and increases the study's internal validity .
Random sampling, on the other hand, involves selecting a representative sample from the population of interest to generalize the findings to the broader population. Random sampling ensures that each member of the population has an equal chance of being included in the sample, reducing the risk of sampling bias .
Replication and Reliability
Replication involves repeating the experiment to confirm the results and assess the reliability of the findings . It is essential for ensuring the validity of scientific findings and building confidence in the robustness of the results. A study that can be replicated consistently across different settings and by various researchers is considered more reliable. Researchers should strive to design experiments that are easily replicable and transparently report their methods to facilitate replication by others.
Validity: Internal, External, Construct, and Statistical Conclusion Validity
Validity refers to the degree to which an experiment measures what it intends to measure and the extent to which the results can be generalized to other populations or contexts. There are several types of validity that researchers should consider:
- Internal Validity : Internal validity refers to the extent to which the study accurately assesses the causal relationship between variables. Internal validity is threatened by factors such as confounding variables, selection bias, and experimenter effects. Researchers can enhance internal validity through careful experimental design and control procedures.
- External Validity : External validity refers to the extent to which the study's findings can be generalized to other populations or settings. External validity is influenced by factors such as the representativeness of the sample and the ecological validity of the experimental conditions. Researchers should consider the relevance and applicability of their findings to real-world situations.
- Construct Validity : Construct validity refers to the degree to which the study accurately measures the theoretical constructs of interest. Construct validity is concerned with whether the operational definitions of the variables align with the underlying theoretical concepts. Researchers can establish construct validity through careful measurement selection and validation procedures.
- Statistical Conclusion Validity : Statistical conclusion validity refers to the accuracy of the statistical analyses and conclusions drawn from the data. It ensures that the statistical tests used are appropriate for the data and that the conclusions drawn are warranted. Researchers should use robust statistical methods and report effect sizes and confidence intervals to enhance statistical conclusion validity.
By addressing these elements of experimental research and ensuring the validity and reliability of your study, you can conduct research that contributes meaningfully to the advancement of knowledge in your field.
How to Conduct Experimental Research?
Embarking on an experimental research journey involves a series of well-defined phases, each crucial for the success of your study. Let's explore the pre-experimental, experimental, and post-experimental phases to ensure you're equipped to conduct rigorous and insightful research.
Pre-Experimental Phase
The pre-experimental phase lays the foundation for your study, setting the stage for what's to come. Here's what you need to do:
- Formulating Research Questions and Hypotheses : Start by clearly defining your research questions and formulating testable hypotheses. Your research questions should be specific, relevant, and aligned with your research objectives. Hypotheses provide a framework for testing the relationships between variables and making predictions about the outcomes of your study.
- Reviewing Literature and Establishing Theoretical Framework : Dive into existing literature relevant to your research topic and establish a solid theoretical framework. Literature review helps you understand the current state of knowledge, identify research gaps, and build upon existing theories. A well-defined theoretical framework provides a conceptual basis for your study and guides your research design and analysis.
Experimental Phase
The experimental phase is where the magic happens – it's time to put your hypotheses to the test and gather data. Here's what you need to consider:
- Participant Recruitment and Sampling Techniques : Carefully recruit participants for your study using appropriate sampling techniques . The sample should be representative of the population you're studying to ensure the generalizability of your findings. Consider factors such as sample size , demographics , and inclusion criteria when recruiting participants.
- Implementing Experimental Procedures : Once you've recruited participants, it's time to implement your experimental procedures. Clearly outline the experimental protocol, including instructions for participants, procedures for administering treatments or interventions, and measures for controlling extraneous variables. Standardize your procedures to ensure consistency across participants and minimize sources of bias.
- Data Collection and Measurement : Collect data using reliable and valid measurement instruments. Depending on your research questions and variables of interest, data collection methods may include surveys , observations, physiological measurements, or experimental tasks. Ensure that your data collection procedures are ethical, respectful of participants' rights, and designed to minimize errors and biases.
Post-Experimental Phase
In the post-experimental phase, you make sense of your data, draw conclusions, and communicate your findings to the world . Here's what you need to do:
- Data Analysis Techniques : Analyze your data using appropriate statistical techniques . Choose methods that are aligned with your research design and hypotheses. Standard statistical analyses include descriptive statistics, inferential statistics (e.g., t-tests, ANOVA), regression analysis , and correlation analysis. Interpret your findings in the context of your research questions and theoretical framework.
- Interpreting Results and Drawing Conclusions : Once you've analyzed your data, interpret the results and draw conclusions. Discuss the implications of your findings, including any theoretical, practical, or real-world implications. Consider alternative explanations and limitations of your study and propose avenues for future research. Be transparent about the strengths and weaknesses of your study to enhance the credibility of your conclusions.
- Reporting Findings : Finally, communicate your findings through research reports, academic papers, or presentations. Follow standard formatting guidelines and adhere to ethical standards for research reporting. Clearly articulate your research objectives, methods, results, and conclusions. Consider your target audience and choose appropriate channels for disseminating your findings to maximize impact and reach.
By meticulously planning and executing each experimental research phase, you can generate valuable insights, advance knowledge in your field, and contribute to scientific progress.
A s you navigate the intricate phases of experimental research, leveraging Appinio can streamline your journey toward actionable insights. With our intuitive platform, you can swiftly gather real-time consumer data, empowering you to make informed decisions with confidence. Say goodbye to the complexities of traditional market research and hello to a seamless, efficient process that puts you in the driver's seat of your research endeavors.
Ready to revolutionize your approach to data-driven decision-making? Book a demo today and discover the power of Appinio in transforming your research experience!
Book a Demo
Experimental Research Examples
Understanding how experimental research is applied in various contexts can provide valuable insights into its practical significance and effectiveness. Here are some examples illustrating the application of experimental research in different domains:
Market Research
Experimental studies are crucial in market research in testing hypotheses, evaluating marketing strategies, and understanding consumer behavior . For example, a company may conduct an experiment to determine the most effective advertising message for a new product. Participants could be exposed to different versions of an advertisement, each emphasizing different product features or appeals.
By measuring variables such as brand recall, purchase intent, and brand perception, researchers can assess the impact of each advertising message and identify the most persuasive approach.
Software as a Service (SaaS)
In the SaaS industry, experimental research is often used to optimize user interfaces, features, and pricing models to enhance user experience and drive engagement. For instance, a SaaS company may conduct A/B tests to compare two versions of its software interface, each with a different layout or navigation structure.
Researchers can identify design elements that lead to higher user satisfaction and retention by tracking user interactions, conversion rates, and customer feedback . Experimental research also enables SaaS companies to test new product features or pricing strategies before full-scale implementation, minimizing risks and maximizing return on investment.
Business Management
Experimental research is increasingly utilized in business management to inform decision-making, improve organizational processes, and drive innovation. For example, a business may conduct an experiment to evaluate the effectiveness of a new training program on employee productivity. Participants could be randomly assigned to either receive the training or serve as a control group.
By measuring performance metrics such as sales revenue, customer satisfaction, and employee turnover, researchers can assess the training program's impact and determine its return on investment. Experimental research in business management provides empirical evidence to support strategic initiatives and optimize resource allocation.
In healthcare , experimental research is instrumental in testing new treatments, interventions, and healthcare delivery models to improve patient outcomes and quality of care. For instance, a clinical trial may be conducted to evaluate the efficacy of a new drug in treating a specific medical condition. Participants are randomly assigned to either receive the experimental drug or a placebo, and their health outcomes are monitored over time.
By comparing the effectiveness of the treatment and placebo groups, researchers can determine the drug's efficacy, safety profile, and potential side effects. Experimental research in healthcare informs evidence-based practice and drives advancements in medical science and patient care.
These examples illustrate the versatility and applicability of experimental research across diverse domains, demonstrating its value in generating actionable insights, informing decision-making, and driving innovation. Whether in market research or healthcare, experimental research provides a rigorous and systematic approach to testing hypotheses, evaluating interventions, and advancing knowledge.
Experimental Research Challenges
Even with careful planning and execution, experimental research can present various challenges. Understanding these challenges and implementing effective solutions is crucial for ensuring the validity and reliability of your study. Here are some common challenges and strategies for addressing them.
Sample Size and Statistical Power
Challenge : Inadequate sample size can limit your study's generalizability and statistical power, making it difficult to detect meaningful effects. Small sample sizes increase the risk of Type II errors (false negatives) and reduce the reliability of your findings.
Solution : Increase your sample size to improve statistical power and enhance the robustness of your results. Conduct a power analysis before starting your study to determine the minimum sample size required to detect the effects of interest with sufficient power. Consider factors such as effect size, alpha level, and desired power when calculating sample size requirements. Additionally, consider using techniques such as bootstrapping or resampling to augment small sample sizes and improve the stability of your estimates.
To enhance the reliability of your experimental research findings, you can leverage our Sample Size Calculator . By determining the optimal sample size based on your desired margin of error, confidence level, and standard deviation, you can ensure the representativeness of your survey results. Don't let inadequate sample sizes hinder the validity of your study and unlock the power of precise research planning!
Confounding Variables and Bias
Challenge : Confounding variables are extraneous factors that co-vary with the independent variable and can distort the relationship between the independent and dependent variables. Confounding variables threaten the internal validity of your study and can lead to erroneous conclusions.
Solution : Implement control measures to minimize the influence of confounding variables on your results. Random assignment of participants to experimental conditions helps distribute confounding variables evenly across groups, reducing their impact on the dependent variable. Additionally, consider using matching or blocking techniques to ensure that groups are comparable on relevant variables. Conduct sensitivity analyses to assess the robustness of your findings to potential confounders and explore alternative explanations for your results.
Researcher Effects and Experimenter Bias
Challenge : Researcher effects and experimenter bias occur when the experimenter's expectations or actions inadvertently influence the study's outcomes. This bias can manifest through subtle cues, unintentional behaviors, or unconscious biases , leading to invalid conclusions.
Solution : Implement double-blind procedures whenever possible to mitigate researcher effects and experimenter bias. Double-blind designs conceal information about the experimental conditions from both the participants and the experimenters, minimizing the potential for bias. Standardize experimental procedures and instructions to ensure consistency across conditions and minimize experimenter variability. Additionally, consider using objective outcome measures or automated data collection procedures to reduce the influence of experimenter bias on subjective assessments.
External Validity and Generalizability
Challenge : External validity refers to the extent to which your study's findings can be generalized to other populations, settings, or conditions. Limited external validity restricts the applicability of your results and may hinder their relevance to real-world contexts.
Solution : Enhance external validity by designing studies closely resembling real-world conditions and populations of interest. Consider using diverse samples that represent the target population's demographic, cultural, and ecological variability. Conduct replication studies in different contexts or with different populations to assess the robustness and generalizability of your findings. Additionally, consider conducting meta-analyses or systematic reviews to synthesize evidence from multiple studies and enhance the external validity of your conclusions.
By proactively addressing these challenges and implementing effective solutions, you can strengthen the validity, reliability, and impact of your experimental research. Remember to remain vigilant for potential pitfalls throughout the research process and adapt your strategies as needed to ensure the integrity of your findings.
Advanced Topics in Experimental Research
As you delve deeper into experimental research, you'll encounter advanced topics and methodologies that offer greater complexity and nuance.
Quasi-Experimental Designs
Quasi-experimental designs resemble true experiments but lack random assignment to experimental conditions. They are often used when random assignment is impractical, unethical, or impossible. Quasi-experimental designs allow researchers to investigate cause-and-effect relationships in real-world settings where strict experimental control is challenging. Common examples include:
- Non-Equivalent Groups Design : This design compares two or more groups that were not created through random assignment. While similar to between-subjects designs, non-equivalent group designs lack the random assignment of participants, increasing the risk of confounding variables.
- Interrupted Time Series Design : In this design, multiple measurements are taken over time before and after an intervention is introduced. Changes in the dependent variable are assessed over time, allowing researchers to infer the impact of the intervention.
- Regression Discontinuity Design : This design involves assigning participants to different groups based on a cutoff score on a continuous variable. Participants just above and below the cutoff are treated as if they were randomly assigned to different conditions, allowing researchers to estimate causal effects.
Quasi-experimental designs offer valuable insights into real-world phenomena but require careful consideration of potential confounding variables and limitations inherent to non-random assignment.
Factorial Designs
Factorial designs involve manipulating two or more independent variables simultaneously to examine their main effects and interactions. By systematically varying multiple factors, factorial designs allow researchers to explore complex relationships between variables and identify how they interact to influence outcomes. Common types of factorial designs include:
- 2x2 Factorial Design : This design manipulates two independent variables, each with two levels. It allows researchers to examine the main effects of each variable as well as any interaction between them.
- Mixed Factorial Design : In this design, one independent variable is manipulated between subjects, while another is manipulated within subjects. Mixed factorial designs enable researchers to investigate both between-subjects and within-subjects effects simultaneously.
Factorial designs provide a comprehensive understanding of how multiple factors contribute to outcomes and offer greater statistical efficiency compared to studying variables in isolation.
Longitudinal and Cross-Sectional Studies
Longitudinal studies involve collecting data from the same participants over an extended period, allowing researchers to observe changes and trajectories over time. Cross-sectional studies , on the other hand, involve collecting data from different participants at a single point in time, providing a snapshot of the population at that moment. Both longitudinal and cross-sectional studies offer unique advantages and challenges:
- Longitudinal Studies : Longitudinal designs allow researchers to examine developmental processes, track changes over time, and identify causal relationships. However, longitudinal studies require long-term commitment, are susceptible to attrition and dropout, and may be subject to practice effects and cohort effects.
- Cross-Sectional Studies : Cross-sectional designs are relatively quick and cost-effective, provide a snapshot of population characteristics, and allow for comparisons across different groups. However, cross-sectional studies cannot assess changes over time or establish causal relationships between variables.
Researchers should carefully consider the research question, objectives, and constraints when choosing between longitudinal and cross-sectional designs.
Meta-Analysis and Systematic Reviews
Meta-analysis and systematic reviews are quantitative methods used to synthesize findings from multiple studies and draw robust conclusions. These methods offer several advantages:
- Meta-Analysis : Meta-analysis combines the results of multiple studies using statistical techniques to estimate overall effect sizes and assess the consistency of findings across studies. Meta-analysis increases statistical power, enhances generalizability, and provides more precise estimates of effect sizes.
- Systematic Reviews : Systematic reviews involve systematically searching, appraising, and synthesizing existing literature on a specific topic. Systematic reviews provide a comprehensive summary of the evidence, identify gaps and inconsistencies in the literature, and inform future research directions.
Meta-analysis and systematic reviews are valuable tools for evidence-based practice, guiding policy decisions, and advancing scientific knowledge by aggregating and synthesizing empirical evidence from diverse sources.
By exploring these advanced topics in experimental research, you can expand your methodological toolkit, tackle more complex research questions, and contribute to deeper insights and understanding in your field.
Experimental Research Ethical Considerations
When conducting experimental research, it's imperative to uphold ethical standards and prioritize the well-being and rights of participants. Here are some key ethical considerations to keep in mind throughout the research process:
- Informed Consent : Obtain informed consent from participants before they participate in your study. Ensure that participants understand the purpose of the study, the procedures involved, any potential risks or benefits, and their right to withdraw from the study at any time without penalty.
- Protection of Participants' Rights : Respect participants' autonomy, privacy, and confidentiality throughout the research process. Safeguard sensitive information and ensure that participants' identities are protected. Be transparent about how their data will be used and stored.
- Minimizing Harm and Risks : Take steps to mitigate any potential physical or psychological harm to participants. Conduct a risk assessment before starting your study and implement appropriate measures to reduce risks. Provide support services and resources for participants who may experience distress or adverse effects as a result of their participation.
- Confidentiality and Data Security : Protect participants' privacy and ensure the security of their data. Use encryption and secure storage methods to prevent unauthorized access to sensitive information. Anonymize data whenever possible to minimize the risk of data breaches or privacy violations.
- Avoiding Deception : Minimize the use of deception in your research and ensure that any deception is justified by the scientific objectives of the study. If deception is necessary, debrief participants fully at the end of the study and provide them with an opportunity to withdraw their data if they wish.
- Respecting Diversity and Cultural Sensitivity : Be mindful of participants' diverse backgrounds, cultural norms, and values. Avoid imposing your own cultural biases on participants and ensure that your research is conducted in a culturally sensitive manner. Seek input from diverse stakeholders to ensure your research is inclusive and respectful.
- Compliance with Ethical Guidelines : Familiarize yourself with relevant ethical guidelines and regulations governing research with human participants, such as those outlined by institutional review boards (IRBs) or ethics committees. Ensure that your research adheres to these guidelines and that any potential ethical concerns are addressed appropriately.
- Transparency and Openness : Be transparent about your research methods, procedures, and findings. Clearly communicate the purpose of your study, any potential risks or limitations, and how participants' data will be used. Share your research findings openly and responsibly, contributing to the collective body of knowledge in your field.
By prioritizing ethical considerations in your experimental research, you demonstrate integrity, respect, and responsibility as a researcher, fostering trust and credibility in the scientific community.
Conclusion for Experimental Research
Experimental research is a powerful tool for uncovering causal relationships and expanding our understanding of the world around us. By carefully designing experiments, collecting data, and analyzing results, researchers can make meaningful contributions to their fields and address pressing questions. However, conducting experimental research comes with responsibilities. Ethical considerations are paramount to ensure the well-being and rights of participants, as well as the integrity of the research process. Researchers can build trust and credibility in their work by upholding ethical standards and prioritizing participant safety and autonomy. Furthermore, as you continue to explore and innovate in experimental research, you must remain open to new ideas and methodologies. Embracing diversity in perspectives and approaches fosters creativity and innovation, leading to breakthrough discoveries and scientific advancements. By promoting collaboration and sharing findings openly, we can collectively push the boundaries of knowledge and tackle some of society's most pressing challenges.
How to Conduct Research in Minutes?
Discover the power of Appinio , the real-time market research platform revolutionizing experimental research. With Appinio, you can access real-time consumer insights to make better data-driven decisions in minutes. Join the thousands of companies worldwide who trust Appinio to deliver fast, reliable consumer insights.
Here's why you should consider using Appinio for your research needs:
- From questions to insights in minutes: With Appinio, you can conduct your own market research and get actionable insights in record time, allowing you to make fast, informed decisions for your business.
- Intuitive platform for anyone: You don't need a PhD in research to use Appinio. Our platform is designed to be user-friendly and intuitive so that anyone can easily create and launch surveys.
- Extensive reach and targeting options: Define your target audience from over 1200 characteristics and survey them in over 90 countries. Our platform ensures you reach the right people for your research needs, no matter where they are.

Get free access to the platform!
Join the loop 💌
Be the first to hear about new updates, product news, and data insights. We'll send it all straight to your inbox.
Get the latest market research news straight to your inbox! 💌
Wait, there's more

16.05.2024 | 30min read
Time Series Analysis: Definition, Types, Techniques, Examples
14.05.2024 | 31min read

07.05.2024 | 29min read
Interval Scale: Definition, Characteristics, Examples

Improved Surface Drainage of Pavements: Final Report (1998)
Chapter: chapter 5 summary, findings, and recommendations.
Below is the uncorrected machine-read text of this chapter, intended to provide our own search engines and external engines with highly rich, chapter-representative searchable text of each book. Because it is UNCORRECTED material, please consider the following text as a useful but insufficient proxy for the authoritative book pages.
CHAPIER 5 SI~MARY, FINDINGS, AND RECOMMENDATIONS SUGARY The primary objective of this research was to identify unproved methods for draining rainwater from the surface of multi-lane pavements and to develop guidelines for their use. The guidelines, along with details on the rationale for their development, are presented in a separate document' "Proposed Design Guidelines for Improving Pavement Surface Drainage" (2J. The guidelines support an interactive computer program, PAVDRN, that can be used by practicing engineers In the process of designing new pavements or rehabilitating old pavements' is outlined In figure 39. The intended audience for the guidelines is practicing highway design engineers that work for transportation agencies or consulting firms. Improved pavement surface drainage is needed for two reasons: (~) to minimize splash and spray and (2) to control the tendency for hydroplaning. Both issues are primary safety concerns. At the request of the advisory panel for the project, the main focus of this study was on ~mprov~g surface drainage to mammae the tendency for hydroplaning. In terms of reducing the tendency for hydroplaTuT g, the needed level of drainage is defined in terms of the thickness of the film of water on the pavement. Therefore, the guidelines were developed within the context of reducing the thickness of the water film on pavement surfaces to the extent that hydroplaning is unlikely at highway design speeds. Since hydroplaning is ~7
DESIGN CRITERIA Pavement Geometry Number of lanes Section type - Tangent - Horizontal curve - Transition - Vertical crest curve - Vertical sag curve Enviromnental oramaters Rainfall intensity ~ Temperature Pavement Tvpe Dense-graded asphalt Porous asphalt Portland cement concrete ~ Grooved Portland cement concrete Desion Soeed Allowable speed for onset of hydroplaning Recommend Desion Changes Alter geometry Alter pavement surface Add appurtenances Groove (Portland cement concrete) CALCULATIONS Lenoth of flow path Calculate on basis of pavement geometry IT Hydraulic Analvses . No? Water film thickness Equation No. 10 Equation No.'s. 16-19 1 Hvdroolanino Analvsis Hydroplaning speed Equation No.'s 21-24 Rainfall Intensity Equation No. 25 -A I / Meet Design ~ \ Cntena? / \<es? Accent Desinn | Figure 39. Flow diagram representing PAVI)RN design process In "Proposed Guidelines for Improving Pavement Surface DrmT~age" (2). 118
controlled primarily by the thickness of the water film on the pavement surface, the design guidelines focus on the prediction and control of ache depth of water flowing across the pavement surface as a result of rainfall, often referred to as sheet flow. Water film thickness on highway pavements can be controlled In three fundamental ways, by: I. Minimizing the length of the longest flow path of the water over We pavement and thereby the distance over which the flow can develop; 2. Increasing the texture of the pavement surface; and 3. Removing water from the pavement's surface. In the process of using PAVDRN to implement the design guidelines, the designer is guided to (~) minimize the longest drainage path length of the section under design by altering the pavement geometry and (2) reduce the resultant water film thickness that will develop along that drainage path length by increasing the mean texture depth, choosing a surface that maximizes texture, or using permeable pavements, grooving, and appurtenances to remove water from the surface. Through the course of a typical design project, four key areas need to be considered in order to analyze and eventually reduce the potential for hydroplaning. These areas are: ~9
I. Environmental conditions: 2. Geometry of the roadway surface; 3. Pavement surface (texture) properties; and 4. Appurtenances. Each of these areas and their influence on the resulting hydroplaning speed of the designed section are discussed In detail In the guidelines (21. The environmental conditions considered are rainfall ~ntensibr and water temperature, which determines the kinematic viscosity of the water. The designer has no real control over these environmental factors but needs to select appropriate values when analyzing the effect of flow over the pavement surface and hydroplaning potential. Five section types, one for each of the basic geometric configurations used In highway design, are examined. These section are: 1. TaIlgent; 2. Superelevated curve; 3. Transition; 4. Vertical crest curve; and 5. Vertical sag curve. 120
Pavement properties that affect the water fihn thickness mclude surface characteristics, such as mean texture depth and grooving of Portland cement concrete surfaces, are considered In the process of applying PAVDRN. Porous asphalt pavement surfaces can also reduce He water film thickness and thereby contribute to the reduction of hydroplaning tendency and their presence can also be accounted for when using PAVDRN. Finally, PAVDRN also allows the design engineer to consider the effect of drainage appurtenances, such as slotted drain inlets. A complete description of the various elements that are considered In the PAVDRN program is illustrated In figure 40. A more complete description of the design process, the parameters used in the design process, and typical values for the parameters is presented In the "Proposed Design Guidelines for Improving Pavement Surface Drainage" (2) alla in Appendix A. fIN1)INGS The following findings are based on the research accomplished during the project, a survey of the literature, and a state-of-the-art survey of current practice. I. Model. The one~unensional mode} is adequate as a design tool. The simplicity and stability of the one~imensional mode} offsets any increased accuracy afforded by a two-d~mensional model. The one~mensional model as a predictor of water fiDn thickness and How path length was verified by using data from a previous study (11). 121
No. of Planes Length of Plane Grade Step Increment Wdth of Plane Cross Slope Section T,rne 1) Tangent 2) Honzontal Curare 3) Transition 4) Vertical Crest 5) Vertical Sag U=tS 1)U.S. 2) S. I. Rainfall Intenstity ~ , \ |Kinematic Viscosity |Design Speed Note: PC = Point of Curvature PI. = Point of Tangency PCC = Portland cement concrete WAC = Dense graded asphalt concrete 0GAC = 0pcn~raded asphalt concrete where OGAC includes all types of intentally draining asphalt surfaces GPCC = Grooved Ponland cement concrete Taneent Pavement Type Mean Texture Depth 1) PCC 2) DGAC 3) OGAC 4) GPCC Horizontal Cun~c Grade Cross Slope Radius of Cunran~re Wdth Pavement Type _ 2) DGAC 3) OGAC 4) GPCC Mean Texture Depth Step Increment _ Transition Length of Plane Super Elevation Tangent Cross Slope Tangent Grade width of Curve Transition Width Pavement Type_ 1) PCC 3) OGAC 4) GPCC Mean Texture Depth Step Increment Horizontal Length Cross slope width PC Grade PI' Grade Elevation: Pr-PC Vertical Crest Flow Direction Step Increment Pavement Type 1) PC Side I 2) PI. Side | 1)PCC 2) DGAC 3) OGAC 4) GPCC Mean Tex~rc Depth _ _ ~ Figure 40. Factors considered in PAVDRN program. 122 ~1 r - . , Vertical Sad | Horizontal Length | Cross slope Wldth PC Grade PI Grade Elevation: PIE Flow Direction Step Increment / Stored :_ ~ cats ~ 1) PC Side | 2) PI Side | . Pavement Typed 1) PCC 3) OGAC 14) GPCC Mean Texture Depth I I
~ Stored data V ~ 3 L IN1T For use with a second nut using data from the first run.) , 1 EPRINT (Echos input to output ) 1 CONVERT (Converts units to and from SI and English.) ~ , ADVP (Advances Page of output.) KINW (Calculates Minning's n, Water Film Thickness (WEIR), and Hydroplaning Speed UPS).) , EDGE (Determines if flow has reached the edge of the pavement.) out roar Figure 40. Factors considered in PAVDRN program (continued). 123
2. Occurrence of Hydropl~r g. In general, based on the PAVDRN mode! and the assumptions inherent in its development, hydroplaning can be expected at speeds below roadway design speeds if the length of the flow path exceeds two lane widths. 3. Water Film Thickness. Hydroplaning is initiated primarily by the depth of the water film thickness. Therefore, the primary design objective when controlling hydroplaning must be to limit the depth of the water film. 4. Reducing Water Film Thickness. There are no simple means for controlling water John thickness, but a number of methods can effectively reduce water film thickness and consequently hydroplaning potential. These include: Optimizing pavement geometry, especially cross-slope. Providing some means of additional drainage, such as use of grooved surfaces (PCC) or porous mixtures (HMA). Including slotted drains within the roadway. 5. Tests Needed for Design. The design guidelines require an estimate of the surface texture (MTD) and the coefficient of permeability Porous asphalt only). The sand patch is an acceptable test method for measuring surface texture, except for the more open (20-percent air voids) porous asphalt mixes. In these cases, an estimate of the surface texture, based on tabulated data, is sufficient. As an alternative, 124
sand patch measurements can be made on cast replicas of the surface. For the open mixes, the glass beads flow into the voids within the mixture, giving an inaccurate measure of surface texture. Based on the measurements obtained In the laboratory, the coefficient of permeability for the open-graded asphalt concrete does not exhibit a wide range of values, and values of k may be selected for design purposes from tabulated design data (k versus air voids). Given the uncertainty of this property resulting from compaction under traffic and clogging from contaminants and anti-skid material, a direct measurement (e.g., drainage lag permeameter) of k is not warranted. Based on the previous discussion, no new test procedures are needed to adopt the design guidelines developed during this project. 6. Grooving. Grooving of PCC pavements provides a reservoir for surface water and can facilitate the removal of water if the grooves are placed parallel to the flow oath. Parallel orientation is generally not practical because the flow on highway pavements is typically not transverse to the pavement. Thus, the primary contribution offered by grooving is to provide a surface reservoir unless the grooves comlect with drainage at the edge of the pavement. Once the grooves are filled with water, the tops of the grooves are the datum for the Why and do not contribute to the reduction in the hydroplaning potential. 125
7. Porous Pavements. These mixtures can enhance the water removal and Hereby reduce water film tHch~ess. They merit more consideration by highway agencies In the United States, but they are not a panacea for eliminating hydroplaning. As with grooved PCC pavements, the internal voids do not contribute to the reduction of hydroplaning; based on the field tests done In this study. hv~ronImiina can be if, , , ~ expected on these mixtures given sufficient water fiLn thickness. Other than their ability to conduct water through internal flow, the large MTD offered by porous asphalt is the main contribution offered by the mixtures to the reduction of hydroplaning potential. The high-void ~ > 20 percent), modified binder mixes used In Europe merit further evaluation in the United States. They should be used In areas where damage from freezing water and the problems of black ice are not likely. 8. Slotted Drains. These fixtures, when installed between travel lanes, offer perhaps the most effective means of controlling water film thickness from a hydraulics standpoint. They have not been used extensively In the traveled lanes and questions remain unanswered with respect to their installation (especially in rehabilitation situations) and maintenance. The ability to support traffic loads and still maintain surface smoothness has not been demonstrated and they may be susceptible to clogging from roadway debris, ice, or snow. 126
RECOMMENDATIONS AND CONCLUSIONS The following recommendations are offered based on the work accomplished during this project and on the conclusions given previously: I. Implementation. The PAVDRN program and associated guidelines need to be field tested and revised as needed. The program and the guidelines are sufficiently complete so that they can be used in a design office. Some of the parameters and algorithms will I~ely need to be modified as experience is gained with the program. 2. Database of Material Properties. A database of material properties should be gathered to supplement the information contained in PAVDRN. This information should Include typical values for the permeability of porous asphalt and topical values for the surface texture (MTD) for different pavement surfaces to include toned Portland cement concrete surfaces. A series of photographs of typical pavement sections and their associated texture depths should be considered as an addition to the design guide (21. 3. Pavement Geometry. The AASHTO design guidelines (~) should be re-evaluated In terms of current design criteria to determine if they can be modified to enhance drainage without adversely affecting vehicle handling or safety. ~27
4. Use of appurtenances. Slotted drams should be evaluated In the field to determine if they are practical when Installed In the traveled way. Manufacturers should reconsider the design of slotted drains and their Installation recommendations currently In force to maximize them for use In multi-lane pavements and to determine if slotted drains are suitable for installations In the traveled right of way. 5. Porous Asphalt Mixtures. More use should be made of these mixtures, especially the modified high a~r-void mixtures as used In France. Field trials should be conducted to monitor HPS and the long-term effectiveness of these mixtures and to validate the MPS and WDT predicted by PAVDRN. 6. Two-D~mensional Model. Further work should be done with two~mensional models to determine if they improve accuracy of PAVDRN and to determine if they are practical from a computational standpoint. ADDITIONAL STUDIES On the basis of the work done during this study, a number of additional items warrant furler study. These Include: 1. Full-scale skid resistance studies to validate PAVDRN in general and the relationship between water film thickness and hydroplaning potential in particular are needed in light of the unexpectedly low hvdronlanin~ speeds predicted during 128 , . ~. , ~
this study. The effect of water infiltration into pavement cracks and loss of water by splash and spray need to be accounted for In the prediction of water fihn Sickness. Surface Irregularities, especially rutting, need to be considered in the prediction models. 2. Field trials are needed to confirm the effectiveness of alternative asphalt and Portland cement concrete surfaces. These include porous Portland cement concrete surfaces, porous asphalt concrete, and various asphalt m~cro-surfaces. 3. The permeability of porous surface mixtures needs to be confirmed with samples removed from the field, and the practicality of a simplified method for measuring in-situ permeability must be investigated and compared to alternative measurements, such as the outflow meter. 4. For measuring pavement texture, alternatives to the sand patch method should be investigated, especially for use with porous asphalt mixtures. 129
THIS PAGE INTENTIONALLY LEFT BLANK
READ FREE ONLINE
Welcome to OpenBook!
You're looking at OpenBook, NAP.edu's online reading room since 1999. Based on feedback from you, our users, we've made some improvements that make it easier than ever to read thousands of publications on our website.
Do you want to take a quick tour of the OpenBook's features?
Show this book's table of contents , where you can jump to any chapter by name.
...or use these buttons to go back to the previous chapter or skip to the next one.
Jump up to the previous page or down to the next one. Also, you can type in a page number and press Enter to go directly to that page in the book.
To search the entire text of this book, type in your search term here and press Enter .
Share a link to this book page on your preferred social network or via email.
View our suggested citation for this chapter.
Ready to take your reading offline? Click here to buy this book in print or download it as a free PDF, if available.
Get Email Updates
Do you enjoy reading reports from the Academies online for free ? Sign up for email notifications and we'll let you know about new publications in your areas of interest when they're released.
- Privacy Policy
Home » Research Findings – Types Examples and Writing Guide
Research Findings – Types Examples and Writing Guide
Table of Contents

Research Findings
Definition:
Research findings refer to the results obtained from a study or investigation conducted through a systematic and scientific approach. These findings are the outcomes of the data analysis, interpretation, and evaluation carried out during the research process.
Types of Research Findings
There are two main types of research findings:
Qualitative Findings
Qualitative research is an exploratory research method used to understand the complexities of human behavior and experiences. Qualitative findings are non-numerical and descriptive data that describe the meaning and interpretation of the data collected. Examples of qualitative findings include quotes from participants, themes that emerge from the data, and descriptions of experiences and phenomena.
Quantitative Findings
Quantitative research is a research method that uses numerical data and statistical analysis to measure and quantify a phenomenon or behavior. Quantitative findings include numerical data such as mean, median, and mode, as well as statistical analyses such as t-tests, ANOVA, and regression analysis. These findings are often presented in tables, graphs, or charts.
Both qualitative and quantitative findings are important in research and can provide different insights into a research question or problem. Combining both types of findings can provide a more comprehensive understanding of a phenomenon and improve the validity and reliability of research results.
Parts of Research Findings
Research findings typically consist of several parts, including:
- Introduction: This section provides an overview of the research topic and the purpose of the study.
- Literature Review: This section summarizes previous research studies and findings that are relevant to the current study.
- Methodology : This section describes the research design, methods, and procedures used in the study, including details on the sample, data collection, and data analysis.
- Results : This section presents the findings of the study, including statistical analyses and data visualizations.
- Discussion : This section interprets the results and explains what they mean in relation to the research question(s) and hypotheses. It may also compare and contrast the current findings with previous research studies and explore any implications or limitations of the study.
- Conclusion : This section provides a summary of the key findings and the main conclusions of the study.
- Recommendations: This section suggests areas for further research and potential applications or implications of the study’s findings.
How to Write Research Findings
Writing research findings requires careful planning and attention to detail. Here are some general steps to follow when writing research findings:
- Organize your findings: Before you begin writing, it’s essential to organize your findings logically. Consider creating an outline or a flowchart that outlines the main points you want to make and how they relate to one another.
- Use clear and concise language : When presenting your findings, be sure to use clear and concise language that is easy to understand. Avoid using jargon or technical terms unless they are necessary to convey your meaning.
- Use visual aids : Visual aids such as tables, charts, and graphs can be helpful in presenting your findings. Be sure to label and title your visual aids clearly, and make sure they are easy to read.
- Use headings and subheadings: Using headings and subheadings can help organize your findings and make them easier to read. Make sure your headings and subheadings are clear and descriptive.
- Interpret your findings : When presenting your findings, it’s important to provide some interpretation of what the results mean. This can include discussing how your findings relate to the existing literature, identifying any limitations of your study, and suggesting areas for future research.
- Be precise and accurate : When presenting your findings, be sure to use precise and accurate language. Avoid making generalizations or overstatements and be careful not to misrepresent your data.
- Edit and revise: Once you have written your research findings, be sure to edit and revise them carefully. Check for grammar and spelling errors, make sure your formatting is consistent, and ensure that your writing is clear and concise.
Research Findings Example
Following is a Research Findings Example sample for students:
Title: The Effects of Exercise on Mental Health
Sample : 500 participants, both men and women, between the ages of 18-45.
Methodology : Participants were divided into two groups. The first group engaged in 30 minutes of moderate intensity exercise five times a week for eight weeks. The second group did not exercise during the study period. Participants in both groups completed a questionnaire that assessed their mental health before and after the study period.
Findings : The group that engaged in regular exercise reported a significant improvement in mental health compared to the control group. Specifically, they reported lower levels of anxiety and depression, improved mood, and increased self-esteem.
Conclusion : Regular exercise can have a positive impact on mental health and may be an effective intervention for individuals experiencing symptoms of anxiety or depression.
Applications of Research Findings
Research findings can be applied in various fields to improve processes, products, services, and outcomes. Here are some examples:
- Healthcare : Research findings in medicine and healthcare can be applied to improve patient outcomes, reduce morbidity and mortality rates, and develop new treatments for various diseases.
- Education : Research findings in education can be used to develop effective teaching methods, improve learning outcomes, and design new educational programs.
- Technology : Research findings in technology can be applied to develop new products, improve existing products, and enhance user experiences.
- Business : Research findings in business can be applied to develop new strategies, improve operations, and increase profitability.
- Public Policy: Research findings can be used to inform public policy decisions on issues such as environmental protection, social welfare, and economic development.
- Social Sciences: Research findings in social sciences can be used to improve understanding of human behavior and social phenomena, inform public policy decisions, and develop interventions to address social issues.
- Agriculture: Research findings in agriculture can be applied to improve crop yields, develop new farming techniques, and enhance food security.
- Sports : Research findings in sports can be applied to improve athlete performance, reduce injuries, and develop new training programs.
When to use Research Findings
Research findings can be used in a variety of situations, depending on the context and the purpose. Here are some examples of when research findings may be useful:
- Decision-making : Research findings can be used to inform decisions in various fields, such as business, education, healthcare, and public policy. For example, a business may use market research findings to make decisions about new product development or marketing strategies.
- Problem-solving : Research findings can be used to solve problems or challenges in various fields, such as healthcare, engineering, and social sciences. For example, medical researchers may use findings from clinical trials to develop new treatments for diseases.
- Policy development : Research findings can be used to inform the development of policies in various fields, such as environmental protection, social welfare, and economic development. For example, policymakers may use research findings to develop policies aimed at reducing greenhouse gas emissions.
- Program evaluation: Research findings can be used to evaluate the effectiveness of programs or interventions in various fields, such as education, healthcare, and social services. For example, educational researchers may use findings from evaluations of educational programs to improve teaching and learning outcomes.
- Innovation: Research findings can be used to inspire or guide innovation in various fields, such as technology and engineering. For example, engineers may use research findings on materials science to develop new and innovative products.
Purpose of Research Findings
The purpose of research findings is to contribute to the knowledge and understanding of a particular topic or issue. Research findings are the result of a systematic and rigorous investigation of a research question or hypothesis, using appropriate research methods and techniques.
The main purposes of research findings are:
- To generate new knowledge : Research findings contribute to the body of knowledge on a particular topic, by adding new information, insights, and understanding to the existing knowledge base.
- To test hypotheses or theories : Research findings can be used to test hypotheses or theories that have been proposed in a particular field or discipline. This helps to determine the validity and reliability of the hypotheses or theories, and to refine or develop new ones.
- To inform practice: Research findings can be used to inform practice in various fields, such as healthcare, education, and business. By identifying best practices and evidence-based interventions, research findings can help practitioners to make informed decisions and improve outcomes.
- To identify gaps in knowledge: Research findings can help to identify gaps in knowledge and understanding of a particular topic, which can then be addressed by further research.
- To contribute to policy development: Research findings can be used to inform policy development in various fields, such as environmental protection, social welfare, and economic development. By providing evidence-based recommendations, research findings can help policymakers to develop effective policies that address societal challenges.
Characteristics of Research Findings
Research findings have several key characteristics that distinguish them from other types of information or knowledge. Here are some of the main characteristics of research findings:
- Objective : Research findings are based on a systematic and rigorous investigation of a research question or hypothesis, using appropriate research methods and techniques. As such, they are generally considered to be more objective and reliable than other types of information.
- Empirical : Research findings are based on empirical evidence, which means that they are derived from observations or measurements of the real world. This gives them a high degree of credibility and validity.
- Generalizable : Research findings are often intended to be generalizable to a larger population or context beyond the specific study. This means that the findings can be applied to other situations or populations with similar characteristics.
- Transparent : Research findings are typically reported in a transparent manner, with a clear description of the research methods and data analysis techniques used. This allows others to assess the credibility and reliability of the findings.
- Peer-reviewed: Research findings are often subject to a rigorous peer-review process, in which experts in the field review the research methods, data analysis, and conclusions of the study. This helps to ensure the validity and reliability of the findings.
- Reproducible : Research findings are often designed to be reproducible, meaning that other researchers can replicate the study using the same methods and obtain similar results. This helps to ensure the validity and reliability of the findings.
Advantages of Research Findings
Research findings have many advantages, which make them valuable sources of knowledge and information. Here are some of the main advantages of research findings:
- Evidence-based: Research findings are based on empirical evidence, which means that they are grounded in data and observations from the real world. This makes them a reliable and credible source of information.
- Inform decision-making: Research findings can be used to inform decision-making in various fields, such as healthcare, education, and business. By identifying best practices and evidence-based interventions, research findings can help practitioners and policymakers to make informed decisions and improve outcomes.
- Identify gaps in knowledge: Research findings can help to identify gaps in knowledge and understanding of a particular topic, which can then be addressed by further research. This contributes to the ongoing development of knowledge in various fields.
- Improve outcomes : Research findings can be used to develop and implement evidence-based practices and interventions, which have been shown to improve outcomes in various fields, such as healthcare, education, and social services.
- Foster innovation: Research findings can inspire or guide innovation in various fields, such as technology and engineering. By providing new information and understanding of a particular topic, research findings can stimulate new ideas and approaches to problem-solving.
- Enhance credibility: Research findings are generally considered to be more credible and reliable than other types of information, as they are based on rigorous research methods and are subject to peer-review processes.
Limitations of Research Findings
While research findings have many advantages, they also have some limitations. Here are some of the main limitations of research findings:
- Limited scope: Research findings are typically based on a particular study or set of studies, which may have a limited scope or focus. This means that they may not be applicable to other contexts or populations.
- Potential for bias : Research findings can be influenced by various sources of bias, such as researcher bias, selection bias, or measurement bias. This can affect the validity and reliability of the findings.
- Ethical considerations: Research findings can raise ethical considerations, particularly in studies involving human subjects. Researchers must ensure that their studies are conducted in an ethical and responsible manner, with appropriate measures to protect the welfare and privacy of participants.
- Time and resource constraints : Research studies can be time-consuming and require significant resources, which can limit the number and scope of studies that are conducted. This can lead to gaps in knowledge or a lack of research on certain topics.
- Complexity: Some research findings can be complex and difficult to interpret, particularly in fields such as science or medicine. This can make it challenging for practitioners and policymakers to apply the findings to their work.
- Lack of generalizability : While research findings are intended to be generalizable to larger populations or contexts, there may be factors that limit their generalizability. For example, cultural or environmental factors may influence how a particular intervention or treatment works in different populations or contexts.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples

Institutional Review Board – Application Sample...

Evaluating Research – Process, Examples and...
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
10 Experimental research
Experimental research—often considered to be the ‘gold standard’ in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research—rather than for descriptive or exploratory research—where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalisability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments are conducted in field settings such as in a real organisation, and are high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favourably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receiving a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the ‘cause’ in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and ensures that each unit in the population has a positive chance of being selected into the sample. Random assignment, however, is a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group prior to treatment administration. Random selection is related to sampling, and is therefore more closely related to the external validity (generalisability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam.
Not conducting a pretest can help avoid this threat.
Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
Regression threat —also called a regression to the mean—refers to the statistical tendency of a group’s overall performance to regress toward the mean during a posttest rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest were possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-group experimental designs

Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest-posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement—especially if the pretest introduces unusual topics or content.
Posttest -only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

The treatment effect is measured simply as the difference in the posttest scores between the two groups:
![\[E = (O_{1} - O_{2})\,.\]](https://usq.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-90f2ce47275e7b35def5c5b52b7d7d45_l3.png "Rendered by QuickLaTeX.com")
The appropriate statistical analysis of this design is also a two-group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.

Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:
Due to the presence of covariates, the right statistical analysis of this design is a two-group analysis of covariance (ANCOVA). This design has all the advantages of posttest-only design, but with internal validity due to the controlling of covariates. Covariance designs can also be extended to pretest-posttest control group design.
Factorial designs
Two-group designs are inadequate if your research requires manipulation of two or more independent variables (treatments). In such cases, you would need four or higher-group designs. Such designs, quite popular in experimental research, are commonly called factorial designs. Each independent variable in this design is called a factor , and each subdivision of a factor is called a level . Factorial designs enable the researcher to examine not only the individual effect of each treatment on the dependent variables (called main effects), but also their joint effect (called interaction effects).

In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for three hours/week of instructional time than for one and a half hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid experimental designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomised bocks design, Solomon four-group design, and switched replications design.
Randomised block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full-time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between the treatment group (receiving the same treatment) and the control group (see Figure 10.5). The purpose of this design is to reduce the ‘noise’ or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.

Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs, but not in posttest-only designs. The design notation is shown in Figure 10.6.

Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organisational contexts where organisational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.

Quasi-experimental designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organisation is used as the treatment group, while another section of the same class or a different organisation in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impacted by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.

In addition, there are quite a few unique non-equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to the treatment or control group based on a cut-off score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardised test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program.

Because of the use of a cut-off score, it is possible that the observed results may be a function of the cut-off score rather than the treatment, which introduces a new threat to internal validity. However, using the cut-off score also ensures that limited or costly resources are distributed to people who need them the most, rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design do not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.

Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, say you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data is not available from the same subjects.

An interesting variation of the NEDV design is a pattern-matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique—based on the degree of correspondence between theoretical and observed patterns—is a powerful way of alleviating internal validity concerns in the original NEDV design.

Perils of experimental research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, often experimental research uses inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies, and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artefact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if in doubt, use tasks that are simple and familiar for the respondent sample rather than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 08 May 2024
A meta-analysis on global change drivers and the risk of infectious disease
- Michael B. Mahon ORCID: orcid.org/0000-0002-9436-2998 1 , 2 na1 ,
- Alexandra Sack 1 , 3 na1 ,
- O. Alejandro Aleuy 1 ,
- Carly Barbera 1 ,
- Ethan Brown ORCID: orcid.org/0000-0003-0827-4906 1 ,
- Heather Buelow ORCID: orcid.org/0000-0003-3535-4151 1 ,
- David J. Civitello 4 ,
- Jeremy M. Cohen ORCID: orcid.org/0000-0001-9611-9150 5 ,
- Luz A. de Wit ORCID: orcid.org/0000-0002-3045-4017 1 ,
- Meghan Forstchen 1 , 3 ,
- Fletcher W. Halliday 6 ,
- Patrick Heffernan 1 ,
- Sarah A. Knutie 7 ,
- Alexis Korotasz 1 ,
- Joanna G. Larson ORCID: orcid.org/0000-0002-1401-7837 1 ,
- Samantha L. Rumschlag ORCID: orcid.org/0000-0003-3125-8402 1 , 2 ,
- Emily Selland ORCID: orcid.org/0000-0002-4527-297X 1 , 3 ,
- Alexander Shepack 1 ,
- Nitin Vincent ORCID: orcid.org/0000-0002-8593-1116 1 &
- Jason R. Rohr ORCID: orcid.org/0000-0001-8285-4912 1 , 2 , 3 na1
Nature volume 629 , pages 830–836 ( 2024 ) Cite this article
6710 Accesses
607 Altmetric
Metrics details
- Infectious diseases
Anthropogenic change is contributing to the rise in emerging infectious diseases, which are significantly correlated with socioeconomic, environmental and ecological factors 1 . Studies have shown that infectious disease risk is modified by changes to biodiversity 2 , 3 , 4 , 5 , 6 , climate change 7 , 8 , 9 , 10 , 11 , chemical pollution 12 , 13 , 14 , landscape transformations 15 , 16 , 17 , 18 , 19 , 20 and species introductions 21 . However, it remains unclear which global change drivers most increase disease and under what contexts. Here we amassed a dataset from the literature that contains 2,938 observations of infectious disease responses to global change drivers across 1,497 host–parasite combinations, including plant, animal and human hosts. We found that biodiversity loss, chemical pollution, climate change and introduced species are associated with increases in disease-related end points or harm, whereas urbanization is associated with decreases in disease end points. Natural biodiversity gradients, deforestation and forest fragmentation are comparatively unimportant or idiosyncratic as drivers of disease. Overall, these results are consistent across human and non-human diseases. Nevertheless, context-dependent effects of the global change drivers on disease were found to be common. The findings uncovered by this meta-analysis should help target disease management and surveillance efforts towards global change drivers that increase disease. Specifically, reducing greenhouse gas emissions, managing ecosystem health, and preventing biological invasions and biodiversity loss could help to reduce the burden of plant, animal and human diseases, especially when coupled with improvements to social and economic determinants of health.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
185,98 € per year
only 3,65 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
Similar content being viewed by others

Towards common ground in the biodiversity–disease debate

Biological invasions facilitate zoonotic disease emergences

Measuring the shape of the biodiversity-disease relationship across systems reveals new findings and key gaps
Data availability.
All the data for this Article have been deposited at Zenodo ( https://doi.org/10.5281/zenodo.8169979 ) 52 and GitHub ( https://github.com/mahonmb/GCDofDisease ) 53 .
Code availability
All the code for this Article has been deposited at Zenodo ( https://doi.org/10.5281/zenodo.8169979 ) 52 and GitHub ( https://github.com/mahonmb/GCDofDisease ) 53 . R markdown is provided in Supplementary Data 1 .
Jones, K. E. et al. Global trends in emerging infectious diseases. Nature 451 , 990–994 (2008).
Article ADS CAS PubMed PubMed Central Google Scholar
Civitello, D. J. et al. Biodiversity inhibits parasites: broad evidence for the dilution effect. Proc. Natl Acad. Sci USA 112 , 8667–8671 (2015).
Halliday, F. W., Rohr, J. R. & Laine, A.-L. Biodiversity loss underlies the dilution effect of biodiversity. Ecol. Lett. 23 , 1611–1622 (2020).
Article PubMed PubMed Central Google Scholar
Rohr, J. R. et al. Towards common ground in the biodiversity–disease debate. Nat. Ecol. Evol. 4 , 24–33 (2020).
Article PubMed Google Scholar
Johnson, P. T. J., Ostfeld, R. S. & Keesing, F. Frontiers in research on biodiversity and disease. Ecol. Lett. 18 , 1119–1133 (2015).
Keesing, F. et al. Impacts of biodiversity on the emergence and transmission of infectious diseases. Nature 468 , 647–652 (2010).
Cohen, J. M., Sauer, E. L., Santiago, O., Spencer, S. & Rohr, J. R. Divergent impacts of warming weather on wildlife disease risk across climates. Science 370 , eabb1702 (2020).
Article CAS PubMed PubMed Central Google Scholar
Rohr, J. R. et al. Frontiers in climate change-disease research. Trends Ecol. Evol. 26 , 270–277 (2011).
Altizer, S., Ostfeld, R. S., Johnson, P. T. J., Kutz, S. & Harvell, C. D. Climate change and infectious diseases: from evidence to a predictive framework. Science 341 , 514–519 (2013).
Article ADS CAS PubMed Google Scholar
Rohr, J. R. & Cohen, J. M. Understanding how temperature shifts could impact infectious disease. PLoS Biol. 18 , e3000938 (2020).
Carlson, C. J. et al. Climate change increases cross-species viral transmission risk. Nature 607 , 555–562 (2022).
Halstead, N. T. et al. Agrochemicals increase risk of human schistosomiasis by supporting higher densities of intermediate hosts. Nat. Commun. 9 , 837 (2018).
Article ADS PubMed PubMed Central Google Scholar
Martin, L. B., Hopkins, W. A., Mydlarz, L. D. & Rohr, J. R. The effects of anthropogenic global changes on immune functions and disease resistance. Ann. N. Y. Acad. Sci. 1195 , 129–148 (2010).
Rumschlag, S. L. et al. Effects of pesticides on exposure and susceptibility to parasites can be generalised to pesticide class and type in aquatic communities. Ecol. Lett. 22 , 962–972 (2019).
Allan, B. F., Keesing, F. & Ostfeld, R. S. Effect of forest fragmentation on Lyme disease risk. Conserv. Biol. 17 , 267–272 (2003).
Article Google Scholar
Brearley, G. et al. Wildlife disease prevalence in human‐modified landscapes. Biol. Rev. 88 , 427–442 (2013).
Rohr, J. R. et al. Emerging human infectious diseases and the links to global food production. Nat. Sustain. 2 , 445–456 (2019).
Bradley, C. A. & Altizer, S. Urbanization and the ecology of wildlife diseases. Trends Ecol. Evol. 22 , 95–102 (2007).
Allen, T. et al. Global hotspots and correlates of emerging zoonotic diseases. Nat. Commun. 8 , 1124 (2017).
Sokolow, S. H. et al. Ecological and socioeconomic factors associated with the human burden of environmentally mediated pathogens: a global analysis. Lancet Planet. Health 6 , e870–e879 (2022).
Young, H. S., Parker, I. M., Gilbert, G. S., Guerra, A. S. & Nunn, C. L. Introduced species, disease ecology, and biodiversity–disease relationships. Trends Ecol. Evol. 32 , 41–54 (2017).
Barouki, R. et al. The COVID-19 pandemic and global environmental change: emerging research needs. Environ. Int. 146 , 106272 (2021).
Article CAS PubMed Google Scholar
Nova, N., Athni, T. S., Childs, M. L., Mandle, L. & Mordecai, E. A. Global change and emerging infectious diseases. Ann. Rev. Resour. Econ. 14 , 333–354 (2021).
Zhang, L. et al. Biological invasions facilitate zoonotic disease emergences. Nat. Commun. 13 , 1762 (2022).
Olival, K. J. et al. Host and viral traits predict zoonotic spillover from mammals. Nature 546 , 646–650 (2017).
Guth, S. et al. Bats host the most virulent—but not the most dangerous—zoonotic viruses. Proc. Natl Acad. Sci. USA 119 , e2113628119 (2022).
Nelson, G. C. et al. in Ecosystems and Human Well-Being (Millennium Ecosystem Assessment) Vol. 2 (eds Rola, A. et al) Ch. 7, 172–222 (Island Press, 2005).
Read, A. F., Graham, A. L. & Raberg, L. Animal defenses against infectious agents: is damage control more important than pathogen control? PLoS Biol. 6 , 2638–2641 (2008).
Article CAS Google Scholar
Medzhitov, R., Schneider, D. S. & Soares, M. P. Disease tolerance as a defense strategy. Science 335 , 936–941 (2012).
Torchin, M. E. & Mitchell, C. E. Parasites, pathogens, and invasions by plants and animals. Front. Ecol. Environ. 2 , 183–190 (2004).
Bellay, S., de Oliveira, E. F., Almeida-Neto, M. & Takemoto, R. M. Ectoparasites are more vulnerable to host extinction than co-occurring endoparasites: evidence from metazoan parasites of freshwater and marine fishes. Hydrobiologia 847 , 2873–2882 (2020).
Scheffer, M. Critical Transitions in Nature and Society Vol. 16 (Princeton Univ. Press, 2020).
Rohr, J. R. et al. A planetary health innovation for disease, food and water challenges in Africa. Nature 619 , 782–787 (2023).
Reaser, J. K., Witt, A., Tabor, G. M., Hudson, P. J. & Plowright, R. K. Ecological countermeasures for preventing zoonotic disease outbreaks: when ecological restoration is a human health imperative. Restor. Ecol. 29 , e13357 (2021).
Hopkins, S. R. et al. Evidence gaps and diversity among potential win–win solutions for conservation and human infectious disease control. Lancet Planet. Health 6 , e694–e705 (2022).
Mitchell, C. E. & Power, A. G. Release of invasive plants from fungal and viral pathogens. Nature 421 , 625–627 (2003).
Chamberlain, S. A. & Szöcs, E. taxize: taxonomic search and retrieval in R. F1000Research 2 , 191 (2013).
Newman, M. Fundamentals of Ecotoxicology (CRC Press/Taylor & Francis Group, 2010).
Rohatgi, A. WebPlotDigitizer v.4.5 (2021); automeris.io/WebPlotDigitizer .
Lüdecke, D. esc: effect size computation for meta analysis (version 0.5.1). Zenodo https://doi.org/10.5281/zenodo.1249218 (2019).
Lipsey, M. W. & Wilson, D. B. Practical Meta-Analysis (SAGE, 2001).
R Core Team. R: A Language and Environment for Statistical Computing Vol. 2022 (R Foundation for Statistical Computing, 2020); www.R-project.org/ .
Viechtbauer, W. Conducting meta-analyses in R with the metafor package. J. Stat. Softw. 36 , 1–48 (2010).
Pustejovsky, J. E. & Tipton, E. Meta-analysis with robust variance estimation: Expanding the range of working models. Prev. Sci. 23 , 425–438 (2022).
Lenth, R. emmeans: estimated marginal means, aka least-squares means. R package v.1.5.1 (2020).
Bartoń, K. MuMIn: multi-modal inference. Model selection and model averaging based on information criteria (AICc and alike) (2019).
Burnham, K. P. & Anderson, D. R. Multimodel inference: understanding AIC and BIC in model selection. Sociol. Methods Res. 33 , 261–304 (2004).
Article MathSciNet Google Scholar
Marks‐Anglin, A. & Chen, Y. A historical review of publication bias. Res. Synth. Methods 11 , 725–742 (2020).
Nakagawa, S. et al. Methods for testing publication bias in ecological and evolutionary meta‐analyses. Methods Ecol. Evol. 13 , 4–21 (2022).
Gurevitch, J., Koricheva, J., Nakagawa, S. & Stewart, G. Meta-analysis and the science of research synthesis. Nature 555 , 175–182 (2018).
Bates, D., Mächler, M., Bolker, B. & Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67 , 1–48 (2015).
Mahon, M. B. et al. Data and code for ‘A meta-analysis on global change drivers and the risk of infectious disease’. Zenodo https://doi.org/10.5281/zenodo.8169979 (2024).
Mahon, M. B. et al. Data and code for ‘A meta-analysis on global change drivers and the risk of infectious disease’. GitHub github.com/mahonmb/GCDofDisease (2024).
Download references
Acknowledgements
We thank C. Mitchell for contributing data on enemy release; L. Albert and B. Shayhorn for assisting with data collection; J. Gurevitch, M. Lajeunesse and G. Stewart for providing comments on an earlier version of this manuscript; and C. Carlson and two anonymous reviewers for improving this paper. This research was supported by grants from the National Science Foundation (DEB-2109293, DEB-2017785, DEB-1518681, IOS-1754868), National Institutes of Health (R01TW010286) and US Department of Agriculture (2021-38420-34065) to J.R.R.; a US Geological Survey Powell grant to J.R.R. and S.L.R.; University of Connecticut Start-up funds to S.A.K.; grants from the National Science Foundation (IOS-1755002) and National Institutes of Health (R01 AI150774) to D.J.C.; and an Ambizione grant (PZ00P3_202027) from the Swiss National Science Foundation to F.W.H. The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
Author information
These authors contributed equally: Michael B. Mahon, Alexandra Sack, Jason R. Rohr
Authors and Affiliations
Department of Biological Sciences, University of Notre Dame, Notre Dame, IN, USA
Michael B. Mahon, Alexandra Sack, O. Alejandro Aleuy, Carly Barbera, Ethan Brown, Heather Buelow, Luz A. de Wit, Meghan Forstchen, Patrick Heffernan, Alexis Korotasz, Joanna G. Larson, Samantha L. Rumschlag, Emily Selland, Alexander Shepack, Nitin Vincent & Jason R. Rohr
Environmental Change Initiative, University of Notre Dame, Notre Dame, IN, USA
Michael B. Mahon, Samantha L. Rumschlag & Jason R. Rohr
Eck Institute of Global Health, University of Notre Dame, Notre Dame, IN, USA
Alexandra Sack, Meghan Forstchen, Emily Selland & Jason R. Rohr
Department of Biology, Emory University, Atlanta, GA, USA
David J. Civitello
Department of Ecology and Evolutionary Biology, Yale University, New Haven, CT, USA
Jeremy M. Cohen
Department of Botany and Plant Pathology, Oregon State University, Corvallis, OR, USA
Fletcher W. Halliday
Department of Ecology and Evolutionary Biology, Institute for Systems Genomics, University of Connecticut, Storrs, CT, USA
Sarah A. Knutie
You can also search for this author in PubMed Google Scholar
Contributions
J.R.R. conceptualized the study. All of the authors contributed to the methodology. All of the authors contributed to investigation. Visualization was performed by M.B.M. The initial study list and related information were compiled by D.J.C., J.M.C., F.W.H., S.A.K., S.L.R. and J.R.R. Data extraction was performed by M.B.M., A.S., O.A.A., C.B., E.B., H.B., L.A.d.W., M.F., P.H., A.K., J.G.L., E.S., A.S. and N.V. Data were checked for accuracy by M.B.M. and A.S. Analyses were performed by M.B.M. and J.R.R. Funding was acquired by D.J.C., J.R.R., S.A.K. and S.L.R. Project administration was done by J.R.R. J.R.R. supervised the study. J.R.R. and M.B.M. wrote the original draft. All of the authors reviewed and edited the manuscript. J.R.R. and M.B.M. responded to reviewers.
Corresponding author
Correspondence to Jason R. Rohr .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Peer review
Peer review information.
Nature thanks Colin Carlson and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended data fig. 1 prisma flowchart..
The PRISMA flow diagram of the search and selection of studies included in this meta-analysis. Note that 77 studies came from the Halliday et al. 3 database on biodiversity change.
Extended Data Fig. 2 Summary of the number of studies (A-F) and parasite taxa (G-L) in the infectious disease database across ecological contexts.
The contexts are global change driver ( A , G ), parasite taxa ( B , H ), host taxa ( C , I ), experimental venue ( D , J ), study habitat ( E , K ), and human parasite status ( F , L ).
Extended Data Fig. 3 Summary of the number of effect sizes (A-I), studies (J-R), and parasite taxa (S-a) in the infectious disease database for various parasite and host contexts.
Shown are parasite type ( A , J , S ), host thermy ( B , K , T ), vector status ( C , L , U ), vector-borne status ( D , M , V ), parasite transmission ( E , N , W ), free living stages ( F , O , X ), host (e.g. disease, host growth, host survival) or parasite (e.g. parasite abundance, prevalence, fecundity) endpoint ( G , P , Y ), micro- vs macroparasite ( H , Q , Z ), and zoonotic status ( I , R , a ).
Extended Data Fig. 4 The effects of global change drivers and subsequent subcategories on disease responses with Log Response Ratio instead of Hedge’s g.
Here, Log Response Ratio shows similar trends to that of Hedge’s g presented in the main text. The displayed points represent the mean predicted values (with 95% confidence intervals) from a meta-analytical model with separate random intercepts for study. Points that do not share letters are significantly different from one another (p < 0.05) based on a two-sided Tukey’s posthoc multiple comparison test with adjustment for multiple comparisons. See Table S 3 for pairwise comparison results. Effects of the five common global change drivers ( A ) have the same directionality, similar magnitude, and significance as those presented in Fig. 2 . Global change driver effects are significant when confidence intervals do not overlap with zero and explicitly tested with two-tailed t-test (indicated by asterisks; t 80.62 = 2.16, p = 0.034 for CP; t 71.42 = 2.10, p = 0.039 for CC; t 131.79 = −3.52, p < 0.001 for HLC; t 61.9 = 2.10, p = 0.040 for IS). The subcategories ( B ) also show similar patterns as those presented in Fig. 3 . Subcategories are significant when confidence intervals do not overlap with zero and were explicitly tested with two-tailed one sample t-test (t 30.52 = 2.17, p = 0.038 for CO 2 ; t 40.03 = 4.64, p < 0.001 for Enemy Release; t 47.45 = 2.18, p = 0.034 for Mean Temperature; t 110.81 = −4.05, p < 0.001 for Urbanization); all other subcategories have p > 0.20. Note that effect size and study numbers are lower here than in Figs. 3 and 4 , because log response ratios cannot be calculated for studies that provide coefficients (e.g., odds ratio) rather than raw data; as such, all observations within BC did not have associated RR values. Despite strong differences in sample size, patterns are consistent across effect sizes, and therefore, we can be confident that the results presented in the main text are not biased because of effect size selection.
Extended Data Fig. 5 Average standard errors of the effect sizes (A) and sample sizes per effect size (B) for each of the five global change drivers.
The displayed points represent the mean predicted values (with 95% confidence intervals) from the generalized linear mixed effects models with separate random intercepts for study (Gaussian distribution for standard error model, A ; Poisson distribution for sample size model, B ). Points that do not share letters are significantly different from one another (p < 0.05) based on a two-sided Tukey’s posthoc multiple comparison test with adjustment for multiple comparisons. Sample sizes (number of studies, n, and effect sizes, k) for each driver are as follows: n = 77, k = 392 for BC; n = 124, k = 364 for CP; n = 202, k = 380 for CC; n = 517, k = 1449 for HLC; n = 96, k = 355 for IS.
Extended Data Fig. 6 Forest plots of effect sizes, associated variances, and relative weights (A), Funnel plots (B), and Egger’s Test plots (C) for each of the five global change drivers and leave-one-out publication bias analyses (D).
In panel A , points are the individual effect sizes (Hedge’s G), error bars are standard errors of the effect size, and size of the points is the relative weight of the observation in the model, with larger points representing observations with higher weight in the model. Sample sizes are provided for each effect size in the meta-analytic database. Effect sizes were plotted in a random order. Egger’s tests indicated significant asymmetries (p < 0.05) in Biodiversity Change (worst asymmetry – likely not bias, just real effect of positive relationship between diversity and disease), Climate Change – (weak asymmetry, again likely not bias, climate change generally increases disease), and Introduced Species (relatively weak asymmetry – unclear whether this is a bias, may be driven by some outliers). No significant asymmetries (p > 0.05) were found in Chemical Pollution and Habitat Loss/Change, suggesting negligible publication bias in reported disease responses across these global change drivers ( B , C ). Egger’s test included publication year as moderator but found no significant relationship between Hedge’s g and publication year (p > 0.05) implying no temporal bias in effect size magnitude or direction. In panel D , the horizontal red lines denote the grand mean and SE of Hedge’s g and (g = 0.1009, SE = 0.0338). Grey points and error bars indicate the Hedge’s g and SEs, respectively, using the leave-one-out method (grand mean is recalculated after a given study is removed from dataset). While the removal of certain studies resulted in values that differed from the grand mean, all estimated Hedge’s g values fell well within the standard error of the grand mean. This sensitivity analysis indicates that our results were robust to the iterative exclusion of individual studies.
Extended Data Fig. 7 The effects of habitat loss/change on disease depend on parasite taxa and land use conversion contexts.
A) Enemy type influences the magnitude of the effect of urbanization on disease: helminths, protists, and arthropods were all negatively associated with urbanization, whereas viruses were non-significantly positively associated with urbanization. B) Reference (control) land use type influences the magnitude of the effect of urbanization on disease: disease was reduced in urban settings compared to rural and peri-urban settings, whereas there were no differences in disease along urbanization gradients or between urban and natural settings. C) The effect of forest fragmentation depends on whether a large/continuous habitat patch is compared to a small patch or whether disease it is measured along an increasing fragmentation gradient (Z = −2.828, p = 0.005). Conversely, the effect of deforestation on disease does not depend on whether the habitat has been destroyed and allowed to regrow (e.g., clearcutting, second growth forests, etc.) or whether it has been replaced with agriculture (e.g., row crop, agroforestry, livestock grazing; Z = 1.809, p = 0.0705). The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variables included enemy type (A), reference land use type (B), or land use conversion type (C). Data for (A) and (B) were only those studies that were within the “urbanization” subcategory; data for (C) were only those studies that were within the “deforestation” and “forest fragmentation” subcategories. Sample sizes (number of studies, n, and effect sizes, k) in (A) for each enemy are n = 48, k = 98 for Virus; n = 193, k = 343 for Protist; n = 159, k = 490 for Helminth; n = 10, k = 24 for Fungi; n = 103, k = 223 for Bacteria; and n = 30, k = 73 for Arthropod. Sample sizes in (B) for each reference land use type are n = 391, k = 1073 for Rural; n = 29, k = 74 for Peri-urban; n = 33, k = 83 for Natural; and n = 24, k = 58 for Urban Gradient. Sample sizes in (C) for each land use conversion type are n = 7, k = 47 for Continuous Gradient; n = 16, k = 44 for High/Low Fragmentation; n = 11, k = 27 for Clearcut/Regrowth; and n = 21, k = 43 for Agriculture.
Extended Data Fig. 8 The effects of common global change drivers on mean infectious disease responses in the literature depends on whether the endpoint is the host or parasite; whether the parasite is a vector, is vector-borne, has a complex or direct life cycle, or is a macroparasite; whether the host is an ectotherm or endotherm; or the venue and habitat in which the study was conducted.
A ) Parasite endpoints. B ) Vector-borne status. C ) Parasite transmission route. D ) Parasite size. E ) Venue. F ) Habitat. G ) Host thermy. H ) Parasite type (ecto- or endoparasite). See Table S 2 for number of studies and effect sizes across ecological contexts and global change drivers. See Table S 3 for pairwise comparison results. The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variables included the main effects and an interaction between global change driver and the focal independent variable (whether the endpoint measured was a host or parasite, whether the parasite is vector-borne, has a complex or direct life cycle, is a macroparasite, whether the study was conducted in the field or lab, habitat, the host is ectothermic, or the parasite is an ectoparasite).
Extended Data Fig. 9 The effects of five common global change drivers on mean infectious disease responses in the literature only occasionally depend on location, host taxon, and parasite taxon.
A ) Continent in which the field study occurred. Lack of replication in chemical pollution precluded us from including South America, Australia, and Africa in this analysis. B ) Host taxa. C ) Enemy taxa. See Table S 2 for number of studies and effect sizes across ecological contexts and global change drivers. See Table S 3 for pairwise comparison results. The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variables included the main effects and an interaction between global change driver and continent, host taxon, and enemy taxon.
Extended Data Fig. 10 The effects of human vs. non-human endpoints for the zoonotic disease subset of database and wild vs. domesticated animal endpoints for the non-human animal subset of database are consistent across global change drivers.
(A) Zoonotic disease responses measured on human hosts responded less positively (closer to zero when positive, further from zero when negative) than those measured on non-human (animal) hosts (Z = 2.306, p = 0.021). Note, IS studies were removed because of missing cells. (B) Disease responses measured on domestic animal hosts responded less positively (closer to zero when positive, further from zero when negative) than those measured on wild animal hosts (Z = 2.636, p = 0.008). These results were consistent across global change drivers (i.e., no significant interaction between endpoint and global change driver). As many of the global change drivers increase zoonotic parasites in non-human animals and all parasites in wild animals, this may suggest that anthropogenic change might increase the occurrence of parasite spillover from animals to humans and thus also pandemic risk. The displayed points represent the mean predicted values (with 95% confidence intervals) from a metafor model where the response variable was a Hedge’s g (representing the effect on an infectious disease endpoint relative to control), study was treated as a random effect, and the independent variable of global change driver and human/non-human hosts. Data for (A) were only those diseases that are considered “zoonotic”; data for (B) were only those endpoints that were measured on non-human animals. Sample sizes in (A) for zoonotic disease measured on human endpoints across global change drivers are n = 3, k = 17 for BC; n = 2, k = 6 for CP; n = 25, k = 39 for CC; and n = 175, k = 331 for HLC. Sample sizes in (A) for zoonotic disease measured on non-human endpoints across global change drivers are n = 25, k = 52 for BC; n = 2, k = 3 for CP; n = 18, k = 29 for CC; n = 126, k = 289 for HLC. Sample sizes in (B) for wild animal endpoints across global change drivers are n = 28, k = 69 for BC; n = 21, k = 44 for CP; n = 50, k = 89 for CC; n = 121, k = 360 for HLC; and n = 29, k = 45 for IS. Sample sizes in (B) for domesticated animal endpoints across global change drivers are n = 2, k = 4 for BC; n = 4, k = 11 for CP; n = 7, k = 20 for CC; n = 78, k = 197 for HLC; and n = 1, k = 2 for IS.
Supplementary information
Supplementary information.
Supplementary Discussion, Supplementary References and Supplementary Tables 1–3.
Reporting Summary
Peer review file, supplementary data 1.
R markdown code and output associated with this paper.
Supplementary Table 4
EcoEvo PRISMA checklist.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Cite this article.
Mahon, M.B., Sack, A., Aleuy, O.A. et al. A meta-analysis on global change drivers and the risk of infectious disease. Nature 629 , 830–836 (2024). https://doi.org/10.1038/s41586-024-07380-6
Download citation
Received : 02 August 2022
Accepted : 03 April 2024
Published : 08 May 2024
Issue Date : 23 May 2024
DOI : https://doi.org/10.1038/s41586-024-07380-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Anthropocene newsletter — what matters in anthropocene research, free to your inbox weekly.

IMAGES
VIDEO
COMMENTS
Research Summary. Definition: A research summary is a brief and concise overview of a research project or study that highlights its key findings, main points, and conclusions. It typically includes a description of the research problem, the research methods used, the results obtained, and the implications or significance of the findings.
Figure 14.1.a provides an example of a 'Summary of findings' table. Figure 15.1.b provides an alternative format that may further facilitate users' understanding and interpretation of the review's findings. Evidence evaluating different formats suggests that the 'Summary of findings' table should include a risk difference as a ...
The summary section of your paper shows that you understood the basic facts of the research. The analysis shows that you can evaluate the evidence presented in the research and explain why the research could be important. Summary. The summary portion of the paper should be written with enough detail so that a reader would not have to look at ...
A research article usually has seven major sections: Title, Abstract, Introduction, Method, Results, Discussion, and References. The first thing you should do is to decide why you need to summarize the article. If the purpose of the summary is to take notes to later remind yourself about the article you may want to write a longer summary ...
The introduction should accomplish what any good introduction does: draw the reader into the paper. To simplify things, follow the "inverted pyramid" structure, which involves narrowing information from the most broad (providing context for your experiment's place in science) to the most specific (what exactly your experiment is about).
A Summary of Findings (SoF) table provides a summary of the main results of a review together with an assessment of the quality or certainty1 of the evidence (assessed using the GRADE tool) upon which these results are based. Assessing the certainty of the evidence for each outcome using GRADE is now compulsory in all new and updated reviews.
Draft Summary of Findings: Draft a paragraph or two of discussion for each finding in your study. Assert the finding. Tell the reader how the finding is important or relevant to your studies aim and focus. Compare your finding to the literature. Be specific in the use of the literature. The link or connection should be clear to the reader.
Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion. Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and ...
So, follow the steps below to write a research summary that sticks. 1. Read the parent paper thoroughly. You should go through the research paper thoroughly multiple times to ensure that you have a complete understanding of its contents. A 3-stage reading process helps.
Key Takeaways. An experiment is a type of empirical study that features the manipulation of an independent variable, the measurement of a dependent variable, and control of extraneous variables. An extraneous variable is any variable other than the independent and dependent variables.
The conclusions are as stated below: i. Students' use of language in the oral sessions depicted their beliefs and values. based on their intentions. The oral sessions prompted the students to be ...
Taking time to reflect on your findings and what these might possibly mean requires some serious mind work—so do not try and rush this phase. Spend a few days away from your research, giving careful thought to the findings, trying to put them in perspective, and trying to gain some deeper insights. To begin facilitating the kind of thinking ...
The most logical way to structure quantitative results is to frame them around your research questions or hypotheses. For each question or hypothesis, share: A reminder of the type of analysis you used (e.g., a two-sample t test or simple linear regression). A more detailed description of your analysis should go in your methodology section.
Step 1: Consult the guidelines or instructions that the target journal or publisher provides authors and read research papers it has published, especially those with similar topics, methods, or results to your study. The guidelines will generally outline specific requirements for the results or findings section, and the published articles will ...
Step 1: Define your variables. You should begin with a specific research question. We will work with two research question examples, one from health sciences and one from ecology: Example question 1: Phone use and sleep. You want to know how phone use before bedtime affects sleep patterns.
Step 1: Define your variables. You should begin with a specific research question. We will work with two research question examples, one from health sciences and one from ecology: Example question 1: Phone use and sleep. You want to know how phone use before bedtime affects sleep patterns.
Content. Experimental research is a cornerstone of scientific inquiry, providing a systematic approach to understanding cause-and-effect relationships and advancing knowledge in various fields. At its core, experimental research involves manipulating variables, observing outcomes, and drawing conclusions based on empirical evidence.
experimental research study that looked at how gesture effects children's learning of math, particularly addition. The independent variable was gesture with three different conditions; gesture, no gesture, and partial gesture. The dependent variable of the study was the difference between pre- and post- test scores on a math task.
from this study. The analysis and interpretation of data is carried out in two phases. The. first part, which is based on the results of the questionnaire, deals with a quantitative. analysis of data. The second, which is based on the results of the interview and focus group. discussions, is a qualitative interpretation.
A more complete description of the design process, the parameters used in the design process, and typical values for the parameters is presented In the "Proposed Design Guidelines for Improving Pavement Surface Drainage" (2) alla in Appendix A. fIN1)INGS The following findings are based on the research accomplished during the project, a survey ...
Quantitative Summary of Research Findings ... between an experimental group and a comparison group or an effect measure that ... ized so that a weighted average effect can be computed (taking into account differences in sample sizes). The outcomes per study may be a standardized dif-ference between groups (e.g., Cohen's d) or a statistic that ...
Research findings can be used in a variety of situations, depending on the context and the purpose. Here are some examples of when research findings may be useful: Decision-making: Research findings can be used to inform decisions in various fields, such as business, education, healthcare, and public policy.
10 Experimental research. 10. Experimental research. Experimental research—often considered to be the 'gold standard' in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different ...
Table of contents. When to write a summary. Step 1: Read the text. Step 2: Break the text down into sections. Step 3: Identify the key points in each section. Step 4: Write the summary. Step 5: Check the summary against the article. Other interesting articles. Frequently asked questions about summarizing.
a-f, Summary of the number of observations (that is, effect sizes) in the infectious disease database across the following ecological contexts: global change driver (a), parasite taxa (b), host ...