
Top 9 Statistical Tools Used in Research
Well-designed research requires a well-chosen study sample and a suitable statistical test selection . To plan an epidemiological study or a clinical trial, you’ll need a solid understanding of the data . Improper inferences from it could lead to false conclusions and unethical behavior . And given the ocean of data available nowadays, it’s often a daunting task for researchers to gauge its credibility and do statistical analysis on it.
With that said, thanks to all the statistical tools available in the market that help researchers make such studies much more manageable. Statistical tools are extensively used in academic and research sectors to study human, animal, and material behaviors and reactions.
Statistical tools aid in the interpretation and use of data. They can be used to evaluate and comprehend any form of data. Some statistical tools can help you see trends, forecast future sales, and create links between causes and effects. When you’re unsure where to go with your study, other tools can assist you in navigating through enormous amounts of data.
In this article, we will discuss some of the best statistical tools and their key features . So, let’s start without any further ado.
What is Statistics? And its Importance in Research
Statistics is the study of collecting, arranging, and interpreting data from samples and inferring it to the total population. Also known as the “Science of Data,” it allows us to derive conclusions from a data set. It may also assist people in all industries in answering research or business queries and forecast outcomes, such as what show you should watch next on your favorite video app.

Statistical Tools Used in Research
Researchers often cannot discern a simple truth from a set of data. They can only draw conclusions from data after statistical analysis. On the other hand, creating a statistical analysis is a difficult task. This is when statistical tools come into play. Researchers can use statistical tools to back up their claims, make sense of a vast set of data, graphically show complex data, or help clarify many things in a short period.
Let’s go through the top 9 best statistical tools used in research below:
SPSS (Statistical Package for the Social Sciences) is a collection of software tools compiled as a single package. This program’s primary function is to analyze scientific data in social science. This information can be utilized for market research, surveys, and data mining, among other things. It is mainly used in the following areas like marketing, healthcare, educational research, etc.
SPSS first stores and organizes the data, then compile the data set to generate appropriate output. SPSS is intended to work with a wide range of variable data formats.
Some of the highlights of SPSS :
- It gives you greater tools for analyzing and comprehending your data. With SPSS’s excellent interface, you can easily handle complex commercial and research challenges.
- It assists you in making accurate and high-quality decisions.
- It also comes with a variety of deployment options for managing your software.
- You may also use a point-and-click interface to produce unique visualizations and reports. To start using SPSS, you don’t need prior coding skills.
- It provides the best views of missing data patterns and summarizes variable distributions.
R is a statistical computing and graphics programming language that you may use to clean, analyze and graph your data. It is frequently used to estimate and display results by researchers from various fields and lecturers of statistics and research methodologies. It’s free, making it an appealing option, but it relies upon programming code rather than drop-down menus or buttons.
Some of the highlights of R :
- It offers efficient storage and data handling facility.
- R has the most robust set of operators. They are used for array calculations, namely matrices.
- It has the best data analysis tools.
- It’s a full-featured high-level programming language with conditional loops, decision statements, and various functions.
SAS is a statistical analysis tool that allows users to build scripts for more advanced analyses or use the GUI. It’s a high-end solution frequently used in industries including business, healthcare, and human behavior research. Advanced analysis and publication-worthy figures and charts are conceivable, albeit coding can be a challenging transition for people who aren’t used to this approach.
Many big tech companies are using SAS due to its support and integration for vast teams. Setting up the tool might be a bit time-consuming initially, but once it’s up and running, it’ll surely streamline your statistical processes.
Some of the highlights of SAS are:
- , with a range of tutorials available.
- Its package includes a wide range of statistics tools.
- It has the best technical support available.
- It gives reports of excellent quality and aesthetic appeal
- It provides the best assistance for detecting spelling and grammar issues. As a result, the analysis is more precise.
MATLAB is one of the most well-reputed statistical analysis tools and statistical programming languages. It has a toolbox with several features that make programming languages simple. With MATLAB, you may perform the most complex statistical analysis, such as EEG data analysis . Add-ons for toolboxes can be used to increase the capability of MATLAB.
Moreover, MATLAB provides a multi-paradigm numerical computing environment, which means that the language may be used for both procedural and object-oriented programming. MATLAB is ideal for matrix manipulation, including data function plotting, algorithm implementation, and user interface design, among other things. Last but not least, MATLAB can also run programs written in other programming languages.
Some of the highlights of MATLAB :
- MATLAB toolboxes are meticulously developed and professionally executed. It is also put through its paces by the tester under various settings. Aside from that, MATLAB provides complete documents.
- MATLAB is a production-oriented programming language. As a result, the MATLAB code is ready for production. All that is required is the integration of data sources and business systems with corporate systems.
- It has the ability to convert MATLAB algorithms to C, C++, and CUDA cores.
- For users, MATLAB is the best simulation platform.
- It provides the optimum conditions for performing data analysis procedures.
Some of the highlights of Tableau are:
- It gives the most compelling end-to-end analytics.
- It provides us with a system of high-level security.
- It is compatible with practically all screen resolutions.
Minitab is a data analysis program that includes basic and advanced statistical features. The GUI and written instructions can be used to execute commands, making it accessible to beginners and those wishing to perform more advanced analysis.
Some of the highlights of Minitab are:
- Minitab can be used to perform various sorts of analysis, such as measurement systems analysis, capability analysis, graphical analysis, hypothesis analysis, regression, non-regression, etcetera.
- , such as scatterplots, box plots, dot plots, histograms, time series plots, and so on.
- Minitab also allows you to run a variety of statistical tests, including one-sample Z-tests, one-sample, two-sample t-tests, paired t-tests, and so on.
7. MS EXCEL:
You can apply various formulas and functions to your data in Excel without prior knowledge of statistics. The learning curve is great, and even freshers can achieve great results quickly since everything is just a click away. This makes Excel a great choice not only for amateurs but beginners as well.
Some of the highlights of MS Excel are:
- It has the best GUI for data visualization solutions, allowing you to generate various graphs with it.
- MS Excel has practically every tool needed to undertake any type of data analysis.
- It enables you to do basic to complicated computations.
- Excel has a lot of built-in formulas that make it a good choice for performing extensive data jobs.
8. RAPIDMINER:
RapidMiner is a valuable platform for data preparation, machine learning, and the deployment of predictive models. RapidMiner makes it simple to develop a data model from the beginning to the end. It comes with a complete data science suite. Machine learning, deep learning, text mining, and predictive analytics are all possible with it.
Some of the highlights of RapidMiner are:
- It has outstanding security features.
- It allows for seamless integration with a variety of third-party applications.
- RapidMiner’s primary functionality can be extended with the help of plugins.
- It provides an excellent platform for data processing and visualization of results.
- It has the ability to track and analyze data in real-time.
9. APACHE HADOOP:
Apache Hadoop is an open-source software that is best known for its top-of-the-drawer scaling capabilities. It is capable of resolving the most challenging computational issues and excels at data-intensive activities as well, given its distributed architecture . The primary reason why it outperforms its contenders in terms of computational power and speed is that it does not directly transfer files to the node. It divides enormous files into smaller bits and transmits them to separate nodes with specific instructions using HDFS . More about it here .
So, if you have massive data on your hands and want something that doesn’t slow you down and works in a distributed way, Hadoop is the way to go.
Some of the highlights of Apache Hadoop are:
- It is cost-effective.
- Apache Hadoop offers built-in tools that automatically schedule tasks and manage clusters.
- It can effortlessly integrate with third-party applications and apps.
- Apache Hadoop is also simple to use for beginners. It includes a framework for managing distributed computing with user intervention.
Learn more about Statistics and Key Tools
Elasticity of Demand Explained in Plain Terms
When you think of “elasticity,” you probably think of flexibility or the ability of an object to bounce back to its original conditions after some change. The type of elasticity
Learn More…
An Introduction to Statistical Power And A/B Testing
Statistical power is an integral part of A/B testing. And in this article, you will learn everything you need to know about it and how it is applied in A/B testing. A/B
What Data Analytics Tools Are And How To Use Them
When it comes to improving the quality of your products and services, data analytic tools are the antidotes. Regardless, people often have questions. What are data analytic tools? Why are
There are a variety of software tools available, each of which offers something slightly different to the user – which one you choose will be determined by several things, including your research question, statistical understanding, and coding experience. These factors may indicate that you are on the cutting edge of data analysis, but the quality of the data acquired depends on the study execution, as with any research.
It’s worth noting that even if you have the most powerful statistical software (and the knowledge to utilize it), the results would be meaningless if they weren’t collected properly. Some online statistics tools are an alternative to the above-mentioned statistical tools. However, each of these tools is the finest in its domain. Hence, you really don’t need a second opinion to use any of these tools. But it’s always recommended to get your hands dirty a little and see what works best for your specific use case before choosing it.
Emidio Amadebai
As an IT Engineer, who is passionate about learning and sharing. I have worked and learned quite a bit from Data Engineers, Data Analysts, Business Analysts, and Key Decision Makers almost for the past 5 years. Interested in learning more about Data Science and How to leverage it for better decision-making in my business and hopefully help you do the same in yours.
Recent Posts
Bootstrapping vs. Boosting
Over the past decade, the field of machine learning has witnessed remarkable advancements in predictive techniques and ensemble learning methods. Ensemble techniques are very popular in machine...
Boosting Algorithms vs. Random Forests Explained
Imagine yourself in the position of a marketing analyst for an e-commerce site who has to make a model that will predict if a customer purchases in the next month or not. In such a scenario, you...
Standard statistical tools in research and data analysis
Introduction.
Statistics is a field of science concerned with gathering, organising, analysing, and extrapolating data from samples to the entire population. This necessitates a well-designed study, a well-chosen study sample, and a proper statistical test selection. A good understanding of statistics is required to design epidemiological research or a clinical trial. Improper statistical approaches might lead to erroneous findings and unethical behaviour.
A variable is a trait that differs from one person to the next within a population. Quantitative variables are measured by a scale and provide quantitative information, such as height and weight. Qualitative factors, such as sex and eye colour, provide qualitative information (Figure 1).
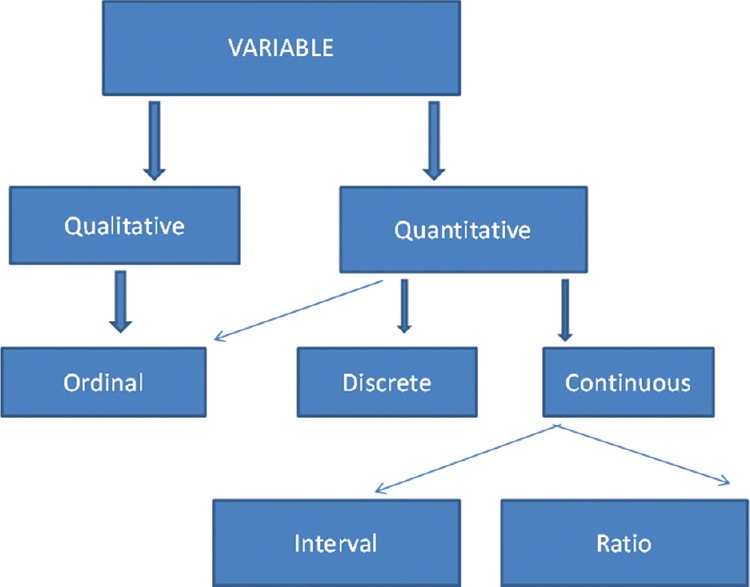
Figure 1. Classification of variables [1]
Quantitative variables
Discrete and continuous measures are used to split quantitative or numerical data. Continuous data can take on any value, whereas discrete numerical data is stored as a whole number such as 0, 1, 2, 3,… (integer). Discrete data is made up of countable observations, while continuous data is made up of measurable observations. Discrete data examples include the number of respiratory arrest episodes or re-intubation in an intensive care unit. Continuous data includes serial serum glucose levels, partial pressure of oxygen in arterial blood, and oesophageal temperature. A hierarchical scale with increasing precision can be used based on category, ordinal, interval and ratio scales (Figure 1).
Descriptive statistics try to explain how variables in a sample or population are related. The mean, median, and mode forms, descriptive statistics give an overview of data. Inferential statistics use a random sample of data from that group to characterise and infer about a community as a whole. It’s useful when it’s not possible to investigate every single person in a group.

Descriptive statistics
The central tendency describes how observations cluster about a centre point, whereas the degree of dispersion describes the spread towards the extremes.
Inferential statistics
In inferential statistics, data from a sample is analysed to conclude the entire population. The goal is to prove or disprove the theories. A hypothesis is a suggested explanation for a phenomenon (plural hypotheses). Hypothesis testing is essential to process for making logical choices regarding observed effects’ veracity.
SOFTWARES FOR STATISTICS, SAMPLE SIZE CALCULATION AND POWER ANALYSIS
There are several statistical software packages accessible today. The most commonly used software systems are Statistical Package for the Social Sciences (SPSS – manufactured by IBM corporation), Statistical Analysis System (SAS – developed by SAS Institute North Carolina, Minitab (developed by Minitab Inc), United States of America), R (designed by Ross Ihaka and Robert Gentleman from the R core team), Stata (developed by StataCorp), and MS Excel. There are several websites linked to statistical power studies. Here are a few examples:
- StatPages.net – contains connections to a variety of online power calculators.
- G-Power — a downloadable power analysis software that works on DOS.
- ANOVA power analysis creates an interactive webpage that estimates the power or sample size required to achieve a specified power for one effect in a factorial ANOVA design.
- Sample Power is software created by SPSS. It generates a comprehensive report on the computer screen that may be copied and pasted into another document.
A researcher must be familiar with the most important statistical approaches for doing research. This will aid in the implementation of a well-designed study that yields accurate and valid data. Incorrect statistical approaches can result in erroneous findings, mistakes, and reduced paper’s importance. Poor statistics can lead to poor research, which can lead to immoral behaviour. As a result, proper statistical understanding and the right application of statistical tests are essential. A thorough understanding of fundamental statistical methods will go a long way toward enhancing study designs and creating high-quality medical research that may be used to develop evidence-based guidelines.
[1] Ali, Zulfiqar, and S Bala Bhaskar. “Basic statistical tools in research and data analysis.” Indian journal of anaesthesia vol. 60,9 (2016): 662-669. doi:10.4103/0019-5049.190623
[2] Ali, Zulfiqar, and S Bala Bhaskar. “Basic statistical tools in research and data analysis.” Indian journal of anaesthesia vol. 60,9 (2016): 662-669. doi:10.4103/0019-5049.190623
- ANOVA power analysis
- Quantitative Data analysis
- quantitative variables
- R programming
- sample size calculation.

- A global market analysis (1)
- Academic (22)
- Algorithms (1)
- Big Data Analytics (4)
- Bio Statistics (3)
- Clinical Prediction Model (1)
- Corporate (9)
- Corporate statistics service (1)
- Data Analyses (23)
- Data collection (11)
- Genomics & Bioinformatics (1)
- Guidelines (2)
- Machine Learning – Blogs (1)
- Meta-analysis service (2)
- Network Analysis (1)
- Predictive analyses (2)
- Qualitative (1)
- Quantitaive (2)
- Quantitative Data analysis service (1)
- Research (59)
- Shipping & Logistics (1)
- Statistical analysis service (7)
- Statistical models (1)
- Statistical Report Writing (1)
- Statistical Software (10)
- Statistics (64)
- Survey & Interview from Statswork (1)
- Uncategorized (1)
Recent Posts
- Top 10 Machine Learning Algorithms Expected to Shape the Future of AI
- Data-Driven Governance: Revolutionizing State Youth Policies through Web Scraping
- The Future is Now: The Potential of Predictive Analytics Models and Algorithms
- 2024 Vision: Exploring the Impact and Evolution of Advanced Analytics Tools
- Application of machine learning in marketing
Statswork is a pioneer statistical consulting company providing full assistance to researchers and scholars. Statswork offers expert consulting assistance and enhancing researchers by our distinct statistical process and communication throughout the research process with us.
Functional Area
– Research Planning – Tool Development – Data Mining – Data Collection – Statistics Coursework – Research Methodology – Meta Analysis – Data Analysis
- – Corporate
- – Statistical Software
- – Statistics
Corporate Office
#10, Kutty Street, Nungambakkam, Chennai, Tamil Nadu – 600034, India No : +91 4433182000, UK No : +44-1223926607 , US No : +1-9725029262 Email: [email protected]
Website: www.statswork.com
© 2024 Statswork. All Rights Reserved

Effective Use of Statistics in Research – Methods and Tools for Data Analysis
Remember that impending feeling you get when you are asked to analyze your data! Now that you have all the required raw data, you need to statistically prove your hypothesis. Representing your numerical data as part of statistics in research will also help in breaking the stereotype of being a biology student who can’t do math.
Statistical methods are essential for scientific research. In fact, statistical methods dominate the scientific research as they include planning, designing, collecting data, analyzing, drawing meaningful interpretation and reporting of research findings. Furthermore, the results acquired from research project are meaningless raw data unless analyzed with statistical tools. Therefore, determining statistics in research is of utmost necessity to justify research findings. In this article, we will discuss how using statistical methods for biology could help draw meaningful conclusion to analyze biological studies.
Table of Contents
Role of Statistics in Biological Research
Statistics is a branch of science that deals with collection, organization and analysis of data from the sample to the whole population. Moreover, it aids in designing a study more meticulously and also give a logical reasoning in concluding the hypothesis. Furthermore, biology study focuses on study of living organisms and their complex living pathways, which are very dynamic and cannot be explained with logical reasoning. However, statistics is more complex a field of study that defines and explains study patterns based on the sample sizes used. To be precise, statistics provides a trend in the conducted study.
Biological researchers often disregard the use of statistics in their research planning, and mainly use statistical tools at the end of their experiment. Therefore, giving rise to a complicated set of results which are not easily analyzed from statistical tools in research. Statistics in research can help a researcher approach the study in a stepwise manner, wherein the statistical analysis in research follows –
1. Establishing a Sample Size
Usually, a biological experiment starts with choosing samples and selecting the right number of repetitive experiments. Statistics in research deals with basics in statistics that provides statistical randomness and law of using large samples. Statistics teaches how choosing a sample size from a random large pool of sample helps extrapolate statistical findings and reduce experimental bias and errors.
2. Testing of Hypothesis
When conducting a statistical study with large sample pool, biological researchers must make sure that a conclusion is statistically significant. To achieve this, a researcher must create a hypothesis before examining the distribution of data. Furthermore, statistics in research helps interpret the data clustered near the mean of distributed data or spread across the distribution. These trends help analyze the sample and signify the hypothesis.
3. Data Interpretation Through Analysis
When dealing with large data, statistics in research assist in data analysis. This helps researchers to draw an effective conclusion from their experiment and observations. Concluding the study manually or from visual observation may give erroneous results; therefore, thorough statistical analysis will take into consideration all the other statistical measures and variance in the sample to provide a detailed interpretation of the data. Therefore, researchers produce a detailed and important data to support the conclusion.
Types of Statistical Research Methods That Aid in Data Analysis

Statistical analysis is the process of analyzing samples of data into patterns or trends that help researchers anticipate situations and make appropriate research conclusions. Based on the type of data, statistical analyses are of the following type:
1. Descriptive Analysis
The descriptive statistical analysis allows organizing and summarizing the large data into graphs and tables . Descriptive analysis involves various processes such as tabulation, measure of central tendency, measure of dispersion or variance, skewness measurements etc.
2. Inferential Analysis
The inferential statistical analysis allows to extrapolate the data acquired from a small sample size to the complete population. This analysis helps draw conclusions and make decisions about the whole population on the basis of sample data. It is a highly recommended statistical method for research projects that work with smaller sample size and meaning to extrapolate conclusion for large population.
3. Predictive Analysis
Predictive analysis is used to make a prediction of future events. This analysis is approached by marketing companies, insurance organizations, online service providers, data-driven marketing, and financial corporations.
4. Prescriptive Analysis
Prescriptive analysis examines data to find out what can be done next. It is widely used in business analysis for finding out the best possible outcome for a situation. It is nearly related to descriptive and predictive analysis. However, prescriptive analysis deals with giving appropriate suggestions among the available preferences.
5. Exploratory Data Analysis
EDA is generally the first step of the data analysis process that is conducted before performing any other statistical analysis technique. It completely focuses on analyzing patterns in the data to recognize potential relationships. EDA is used to discover unknown associations within data, inspect missing data from collected data and obtain maximum insights.
6. Causal Analysis
Causal analysis assists in understanding and determining the reasons behind “why” things happen in a certain way, as they appear. This analysis helps identify root cause of failures or simply find the basic reason why something could happen. For example, causal analysis is used to understand what will happen to the provided variable if another variable changes.
7. Mechanistic Analysis
This is a least common type of statistical analysis. The mechanistic analysis is used in the process of big data analytics and biological science. It uses the concept of understanding individual changes in variables that cause changes in other variables correspondingly while excluding external influences.
Important Statistical Tools In Research
Researchers in the biological field find statistical analysis in research as the scariest aspect of completing research. However, statistical tools in research can help researchers understand what to do with data and how to interpret the results, making this process as easy as possible.
1. Statistical Package for Social Science (SPSS)
It is a widely used software package for human behavior research. SPSS can compile descriptive statistics, as well as graphical depictions of result. Moreover, it includes the option to create scripts that automate analysis or carry out more advanced statistical processing.
2. R Foundation for Statistical Computing
This software package is used among human behavior research and other fields. R is a powerful tool and has a steep learning curve. However, it requires a certain level of coding. Furthermore, it comes with an active community that is engaged in building and enhancing the software and the associated plugins.
3. MATLAB (The Mathworks)
It is an analytical platform and a programming language. Researchers and engineers use this software and create their own code and help answer their research question. While MatLab can be a difficult tool to use for novices, it offers flexibility in terms of what the researcher needs.
4. Microsoft Excel
Not the best solution for statistical analysis in research, but MS Excel offers wide variety of tools for data visualization and simple statistics. It is easy to generate summary and customizable graphs and figures. MS Excel is the most accessible option for those wanting to start with statistics.
5. Statistical Analysis Software (SAS)
It is a statistical platform used in business, healthcare, and human behavior research alike. It can carry out advanced analyzes and produce publication-worthy figures, tables and charts .
6. GraphPad Prism
It is a premium software that is primarily used among biology researchers. But, it offers a range of variety to be used in various other fields. Similar to SPSS, GraphPad gives scripting option to automate analyses to carry out complex statistical calculations.
This software offers basic as well as advanced statistical tools for data analysis. However, similar to GraphPad and SPSS, minitab needs command over coding and can offer automated analyses.
Use of Statistical Tools In Research and Data Analysis
Statistical tools manage the large data. Many biological studies use large data to analyze the trends and patterns in studies. Therefore, using statistical tools becomes essential, as they manage the large data sets, making data processing more convenient.
Following these steps will help biological researchers to showcase the statistics in research in detail, and develop accurate hypothesis and use correct tools for it.
There are a range of statistical tools in research which can help researchers manage their research data and improve the outcome of their research by better interpretation of data. You could use statistics in research by understanding the research question, knowledge of statistics and your personal experience in coding.
Have you faced challenges while using statistics in research? How did you manage it? Did you use any of the statistical tools to help you with your research data? Do write to us or comment below!
Frequently Asked Questions
Statistics in research can help a researcher approach the study in a stepwise manner: 1. Establishing a sample size 2. Testing of hypothesis 3. Data interpretation through analysis
Statistical methods are essential for scientific research. In fact, statistical methods dominate the scientific research as they include planning, designing, collecting data, analyzing, drawing meaningful interpretation and reporting of research findings. Furthermore, the results acquired from research project are meaningless raw data unless analyzed with statistical tools. Therefore, determining statistics in research is of utmost necessity to justify research findings.
Statistical tools in research can help researchers understand what to do with data and how to interpret the results, making this process as easy as possible. They can manage large data sets, making data processing more convenient. A great number of tools are available to carry out statistical analysis of data like SPSS, SAS (Statistical Analysis Software), and Minitab.

nice article to read
Holistic but delineating. A very good read.
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles

- Reporting Research
Research Interviews: An effective and insightful way of data collection
Research interviews play a pivotal role in collecting data for various academic, scientific, and professional…

Planning Your Data Collection: Designing methods for effective research
Planning your research is very important to obtain desirable results. In research, the relevance of…

- Language & Grammar
Best Plagiarism Checker Tool for Researchers — Top 4 to choose from!
While common writing issues like language enhancement, punctuation errors, grammatical errors, etc. can be dealt…

- Industry News
- Publishing News
2022 in a Nutshell — Reminiscing the year when opportunities were seized and feats were achieved!
It’s beginning to look a lot like success! Some of the greatest opportunities to research…

- Manuscript Preparation
- Publishing Research
Qualitative Vs. Quantitative Research — A step-wise guide to conduct research
A research study includes the collection and analysis of data. In quantitative research, the data…
2022 in a Nutshell — Reminiscing the year when opportunities were seized and feats…

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

What should universities' stance be on AI tools in research and academic writing?
Basic statistical tools in research and data analysis
Affiliations.
- 1 Department of Anaesthesiology, Division of Neuroanaesthesiology, Sheri Kashmir Institute of Medical Sciences, Soura, Srinagar, Jammu and Kashmir, India.
- 2 Department of Anaesthesiology and Critical Care, Vijayanagar Institute of Medical Sciences, Bellary, Karnataka, India.
- PMID: 27729694
- PMCID: PMC5037948
- DOI: 10.4103/0019-5049.190623
Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise only if proper statistical tests are used. This article will try to acquaint the reader with the basic research tools that are utilised while conducting various studies. The article covers a brief outline of the variables, an understanding of quantitative and qualitative variables and the measures of central tendency. An idea of the sample size estimation, power analysis and the statistical errors is given. Finally, there is a summary of parametric and non-parametric tests used for data analysis.
Keywords: Basic statistical tools; degree of dispersion; measures of central tendency; parametric tests and non-parametric tests; variables; variance.
Publication types
Reporting statistical methods and outcome of statistical analyses in research articles
- Published: 15 June 2020
- Volume 72 , pages 481–485, ( 2020 )
Cite this article
- Mariusz Cichoń 1
17k Accesses
12 Citations
1 Altmetric
Explore all metrics
Avoid common mistakes on your manuscript.
Introduction
Statistical methods constitute a powerful tool in modern life sciences. This tool is primarily used to disentangle whether the observed differences, relationships or congruencies are meaningful or may just occur by chance. Thus, statistical inference is an unavoidable part of scientific work. The knowledge of statistics is usually quite limited among researchers representing the field of life sciences, particularly when it comes to constraints imposed on the use of statistical tools and possible interpretations. A common mistake is that researchers take for granted the ability to perform a valid statistical analysis. However, at the stage of data analysis, it may turn out that the gathered data cannot be analysed with any known statistical tools or that there are critical flaws in the interpretation of the results due to violations of basic assumptions of statistical methods. A common mistake made by authors is to thoughtlessly copy the choice of the statistical tests from other authors analysing similar data. This strategy, although sometimes correct, may lead to an incorrect choice of statistical tools and incorrect interpretations. Here, I aim to give some advice on how to choose suitable statistical methods and how to present the results of statistical analyses.
Important limits in the use of statistics
Statistical tools face a number of constraints. Constraints should already be considered at the stage of planning the research, as mistakes made at this stage may make statistical analyses impossible. Therefore, careful planning of sampling is critical for future success in data analyses. The most important is ensuring that the general population is sampled randomly and independently, and that the experimental design corresponds to the aims of the research. Planning a control group/groups is of particular importance. Without a suitable control group, any further inference may not be possible. Parametric tests are stronger (it is easier to reject a null hypothesis), so they should always be preferred, but such methods can be used only when the data are drawn from a general population with normal distribution. For methods based on analysis of variance (ANOVA), residuals should come from a general population with normal distribution, and in this case there is an additional important assumption of homogeneity of variance. Inferences made from analyses violating these assumptions may be incorrect.
Statistical inference
Statistical inference is asymmetrical. Scientific discovery is based on rejecting null hypotheses, so interpreting non-significant results should be taken with special care. We never know for sure why we fail to reject the null hypothesis. It may indeed be true, but it is also possible that our sample size was too small or variance too large to capture the differences or relationships. We also may fail just by chance. Assuming a significance level of p = 0.05 means that we run the risk of rejecting a null hypothesis in 5% of such analyses. Thus, interpretation of non-significant results should always be accompanied by the so-called power analysis, which shows the strength of our inference.
Experimental design and data analyses
The experimental design is a critical part of study planning. The design must correspond to the aims of the study presented in the Introduction section. In turn, the statistical methods must be suited to the experimental design so that the data analyses will enable the questions stated in the Introduction to be answered. In general, simple experimental designs allow the use of simple methods like t-tests, simple correlations, etc., while more complicated designs (multifactor designs) require more advanced methods (see, Fig. 1 ). Data coming from more advanced designs usually cannot be analysed with simple methods. Therefore, multifactor designs cannot be followed by a simple t-test or even with one-way ANOVA, as factors may not act independently, and in such a case the interpretation of the results of one-way ANOVA may be incorrect. Here, it is particularly important that one may be interested in a concerted action of factors (interaction) or an action of a given factor while controlling for other factors (independent action of a factor). But even with one factor design with more than two levels, one cannot use just a simple t-test with multiple comparisons between groups. In such a case, one-way ANOVA should be performed followed by a post hoc test. The post hoc test can be done only if ANOVA rejects the null hypothesis. There is no point in using the post hoc test if the factors have only two levels (groups). In this case, the differences are already clear after ANOVA.

Test selection chart
Description of statistical methods in the Materials and methods section
It is in the author’s interest to provide the reader with all necessary information to judge whether the statistical tools used in the paper are the most suitable to answer the scientific question and are suited to the data structure. In the Materials and methods section, the experimental design must be described in detail, so that the reader may easily understand how the study was performed and later why such specific statistical methods were chosen. It must be clear whether the study is planned to test the relationships or differences between groups. Here, the reader should already understand the data structure, what the dependent variable is, what the factors are, and should be able to determine, even without being directly informed, whether the factors are categorical or continuous, and whether they are fixed or random. The sample size used in the analysis should be clearly stated. Sometimes sample sizes used in analyses are smaller than the original. This can happen for various reasons, for example if one fails to perform some measurements, and in such a case, the authors must clearly explain why the original sample size differs from the one used in the analyses. There must be a very good reason to omit existing data points from the analyses. Removing the so-called outliers should be an exception rather than the rule.
A description of the statistical methods should come at the end of the Materials and methods section. Here, we start by introducing the statistical techniques used to test predictions formulated in the Introduction. We describe in detail the structure of the statistical model (defining the dependent variable, the independent variables—factors, interactions if present, character of the factors—fixed or random). The variables should be defined as categorical or continuous. In the case of more advanced models, information on the methods of effects estimation or degrees of freedom should be provided. Unless there are good reasons, interactions should always be tested, even if the study is not aimed at testing an interaction. If the interaction is not the main aim of the study, non-significant interactions should be dropped from the model and new analyses without interactions should be carried out and such results reported. If the interaction appears to be significant, one cannot remove it from the model even if the interaction is not the main aim of the study. In such a case, only the interaction can be interpreted, while the interpretation of the main effects is not allowed. The author should clearly describe how the interactions will be dealt with. One may also consider using a model selection procedure which should also be clearly described.
The authors should reassure the reader that the assumptions of the selected statistical technique are fully met. It must be described how the normality of data distribution and homogeneity of variance was checked and whether these assumptions have been met. When performing data transformation, one needs to explain how it was done and whether the transformation helped to fulfil the assumptions of the parametric tests. If these assumptions are not fulfilled, one may apply non-parametric tests. It must be clearly stated why non-parametric tests are performed. Post hoc tests can be performed only when the ANOVA/Kruskal–Wallis test shows significant effects. These tests are valid for the main effects only when the interaction is not included in the model. These tests are also applicable for significant interactions. There are a number of different post hoc tests, so the selected test must be introduced in the materials and methods section.
The significance level is often mentioned in the materials and methods section. There is common consensus among researchers in life sciences for a significance level set at p = 0.05, so it is not strictly necessary to report this conventional level unless the authors always give the I type error (p-value) throughout the paper. If the author sets the significance level at a lower value, which could be the case, for example, in medical sciences, the reader must be informed about the use of a more conservative level. If the significance level is not reported, the reader will assume p = 0.05. In general, it does not matter which statistical software was used for the analyses. However, the outcome may differ slightly between different software, even if exactly the same model is set. Thus, it may be a good practice to report the name of the software at the end of the subsection describing the statistical methods. If the original code of the model analysed is provided, it would be sensible to inform the reader of the specific software and version that was used.
Presentation of the outcome in the Results section
Only the data and the analyses needed to test the hypotheses and predictions stated in the Introduction and those important for discussion should be placed in the Results section. All other outcome might be provided as supplementary materials. Some descriptive statistics are often reported in the Results section, such as means, standard errors (SE), standard deviation (SD), confidence interval (CI). It is of critical importance that these estimates can only be provided if the described data are drawn from a general population with normal distribution; otherwise median values with quartiles should be provided. A common mistake is to provide the results of non-parametric tests with parametric estimates. If one cannot assume normal distribution, providing arithmetic mean with standard deviation is misleading, as they are estimates of normal distribution. I recommend using confidence intervals instead of SE or SD, as confidence intervals are more informative (non-overlapping intervals suggest the existence of potential differences).
Descriptive statistics can be calculated from raw data (measured values) or presented as estimates from the calculated models (values corrected for independent effects of other factors in the model). The issue whether estimates from models or statistics calculated from the raw data provided throughout the paper should be clearly stated in the Materials and methods section. It is not necessary to report the descriptive statistics in the text if it is already reported in the tables or can be easily determined from the graphs.
The Results section is a narrative text which tells the reader about all the findings and guides them to refer to tables and figures if present. Each table and figure should be referenced in the text at least once. It is in the author’s interest to provide the reader the outcome of the statistical tests in such a way that the correctness of the reported values can be assessed. The value of the appropriate statistics (e.g. F, t, H, U, z, r) must always be provided, along with the sample size (N; non-parametric tests) or degrees of freedom (df; parametric tests) and I type error (p-value). The p-value is an important information, as it tells the reader about confidence related to rejecting the null hypothesis. Thus one needs to provide an exact value of I type error. A common mistake is to provide information as an inequality (p < 0.05). There is an important difference for interpretation if p = 0.049 or p = 0.001.
The outcome of simple tests (comparing two groups, testing relationship between two variables) can easily be reported in the text, but in case of multivariate models, one may rather report the outcome in the form of a table in which all factors with their possible interactions are listed with their estimates, statistics and p-values. The results of post hoc tests, if performed, may be reported in the main text, but if one reports differences between many groups or an interaction, then presenting such results in the form of a table or graph could be more informative.
The main results are often presented graphically, particularly when the effects appear to be significant. The graphs should be constructed so that they correspond to the analyses. If the main interest of the study is in an interaction, then it should be depicted in the graph. One should not present interaction in the graph if it appeared to be non-significant. When presenting differences, the mean or median value should be visualised as a dot, circle or some other symbol with some measure of variability (quartiles if a non-parametric test was performed, and SD, SE or preferably confidence intervals in the case of parametric tests) as whiskers below and above the midpoint. The midpoints should not be linked with a line unless an interaction is presented or, more generally, if the line has some biological/logical meaning in the experimental design. Some authors present differences as bar graphs. When using bar graphs, the Y -axis must start from a zero value. If a bar graph is used to show differences between groups, some measure of variability (SD, SE, CI) must also be provided, as whiskers, for example. Graphs may present the outcome of post hoc tests in the form of letters placed above the midpoint or whiskers, with the same letter indicating lack of differences and different letters signalling pairwise differences. The significant differences can also be denoted as asterisks or, preferably, p-values placed above the horizontal line linking the groups. All this must be explained in the figure caption. Relationships should be presented in the form of a scatterplot. This could be accompanied by a regression line, but only if the relationship is statistically significant. The regression line is necessary if one is interested in describing a functional relationship between two variables. If one is interested in correlation between variables, the regression line is not necessary, but could be placed in order to visualise the relationship. In this case, it must be explained in the figure caption. If regression is of interest, then providing an equation of this regression is necessary in the figure caption. Remember that graphs serve to represent the analyses performed, so if the analyses were carried out on the transformed data, the graphs should also present transformed data. In general, the tables and figure captions must be self-explanatory, so that the reader is able to understand the table/figure content without reading the main text. The table caption should be written in such a way that it is possible to understand the statistical analysis from which the results are presented.
Guidelines for the Materials and methods section:
Provide detailed description of the experimental design so that the statistical techniques will be understandable for the reader.
Make sure that factors and groups within factors are clearly introduced.
Describe all statistical techniques applied in the study and provide justification for each test (both parametric and non-parametric methods).
If parametric tests are used, describe how the normality of data distribution and homogeneity of variance (in the case of analysis of variance) was checked and state clearly that these important assumptions for parametric tests are met.
Give a rationale for using non-parametric tests.
If data transformation was applied, provide details of how this transformation was performed and state clearly that this helped to achieve normal distribution/homogeneity of variance.
In the case of multivariate analyses, describe the statistical model in detail and explain what you did with interactions.
If post hoc tests are used, clearly state which tests you use.
Specify the type of software and its version if you think it is important.
Guidelines for presentation of the outcome of statistical analyses in the Results section:
Make sure you report appropriate descriptive statistics—means, standard errors (SE), standard deviation (SD), confidence intervals (CI), etc. in case of parametric tests or median values with quartiles in case of non-parametric tests.
Provide appropriate statistics for your test (t value for t-test, F for ANOVA, H for Kruskal–Wallis test, U for Mann–Whitney test, χ 2 for chi square test, or r for correlation) along with the sample size (non-parametric tests) or degrees of freedom (df; parametric tests).
t 23 = 3.45 (the number in the subscript denotes degree of freedom, meaning the sample size of the first group minus 1 plus the sample size of the second group minus 1 for the test with independent groups, or number of pairs in paired t-test minus 1).
F 1,23 = 6.04 (first number in the subscript denotes degrees of freedom for explained variance—number of groups within factor minus 1, second number denotes degree of freedom for unexplained variance—residual variance). F-statistics should be provided separately for all factors and interactions (only if interactions are present in the model).
H = 13.8, N 1 = 15, N 2 = 18, N 3 = 12 (N 1, N 2, N 3 are sample sizes for groups compared).
U = 50, N 1 = 20, N 2 = 19 for Mann–Whitney test (N 1 and N 2 are sample sizes for groups).
χ 2 = 3.14 df = 1 (here meaning e.g. 2 × 2 contingency table).
r = 0.78, N = 32 or df = 30 (df = N − 2).
Provide exact p-values (e.g. p = 0.03), rather than standard inequality (p ≤ 0.05)
If the results of statistical analysis are presented in the form of a table, make sure the statistical model is accurately described so that the reader will understand the context of the table without referring to the text. Please ensure that the table is cited in the text.
The figure caption should include all information necessary to understand what is seen in the figure. Describe what is denoted by a bar, symbols, whiskers (mean/median, SD, SE, CI/quartiles). If you present transformed data, inform the reader about the transformation you applied. If you present the results of a post hoc test on the graph, please note what test was used and how you denote the significant differences. If you present a regression line on the scatter plot, give information as to whether you provide the line to visualise the relationship or you are indeed interested in regression, and in the latter case, give the equation for this regression line.
Further reading in statistics:
Sokal and Rolf. 2011. Biometry. Freeman.
Zar. 2010. Biostatistical analyses. Prentice Hall.
McDonald, J.H. 2014. Handbook of biological statistics. Sparky House Publishing, Baltimore, Maryland.
Quinn and Keough. 2002. Experimental design and data analysis for biologists. Cambridge University Press.
Author information
Authors and affiliations.
Institute of Environmental Sciences, Jagiellonian University, Gronostajowa 7, 30-376, Kraków, Poland
Mariusz Cichoń
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Mariusz Cichoń .
Rights and permissions
Reprints and permissions
About this article
Cichoń, M. Reporting statistical methods and outcome of statistical analyses in research articles. Pharmacol. Rep 72 , 481–485 (2020). https://doi.org/10.1007/s43440-020-00110-5
Download citation
Published : 15 June 2020
Issue Date : June 2020
DOI : https://doi.org/10.1007/s43440-020-00110-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Find a journal
- Publish with us
- Track your research

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Med Internet Res
- v.20(11); 2018 Nov
Assessing the Methods, Tools, and Statistical Approaches in Google Trends Research: Systematic Review
Amaryllis mavragani.
1 Department of Computing Science and Mathematics, University of Stirling, Stirling, Scotland, United Kingdom
Gabriela Ochoa
Konstantinos p tsagarakis.
2 Department of Environmental Engineering, Democritus University of Thrace, Xanthi, Greece
Associated Data
Publication details and categorization.
In the era of information overload, are big data analytics the answer to access and better manage available knowledge? Over the last decade, the use of Web-based data in public health issues, that is, infodemiology, has been proven useful in assessing various aspects of human behavior. Google Trends is the most popular tool to gather such information, and it has been used in several topics up to this point, with health and medicine being the most focused subject. Web-based behavior is monitored and analyzed in order to examine actual human behavior so as to predict, better assess, and even prevent health-related issues that constantly arise in everyday life.
This systematic review aimed at reporting and further presenting and analyzing the methods, tools, and statistical approaches for Google Trends (infodemiology) studies in health-related topics from 2006 to 2016 to provide an overview of the usefulness of said tool and be a point of reference for future research on the subject.
Following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines for selecting studies, we searched for the term “Google Trends” in the Scopus and PubMed databases from 2006 to 2016, applying specific criteria for types of publications and topics. A total of 109 published papers were extracted, excluding duplicates and those that did not fall inside the topics of health and medicine or the selected article types. We then further categorized the published papers according to their methodological approach, namely, visualization, seasonality, correlations, forecasting, and modeling.
All the examined papers comprised, by definition, time series analysis, and all but two included data visualization. A total of 23.1% (24/104) studies used Google Trends data for examining seasonality, while 39.4% (41/104) and 32.7% (34/104) of the studies used correlations and modeling, respectively. Only 8.7% (9/104) of the studies used Google Trends data for predictions and forecasting in health-related topics; therefore, it is evident that a gap exists in forecasting using Google Trends data.
Conclusions
The monitoring of online queries can provide insight into human behavior, as this field is significantly and continuously growing and will be proven more than valuable in the future for assessing behavioral changes and providing ground for research using data that could not have been accessed otherwise.
Introduction
Big data are characterized by the 8 Vs [ 1 ]: volume (exponentially increasing volumes) [ 2 ], variety (wide range of datasets), velocity (high processing speed) [ 3 ], veracity, value [ 4 , 5 ], variability, volatility, and validity [ 1 ]. Big data have shown great potential in forecasting and better decision making [ 1 ]; though handling these data with conventional ways is inadequate [ 6 ], they are being continuously integrated in research [ 7 ] with novel approaches and methods.
The analysis of online search queries has been of notable popularity in the field of big data analytics in academic research [ 8 , 9 ]. As internet penetration is continuously increasing, the use of search traffic data, social media data, and data from other Web-based sources and tools can assist in facilitating a better understanding and analysis of Web-based behavior and behavioral changes [ 10 ].
The most popular tool for analyzing behavior using Web-based data is Google Trends [ 11 ]. Online search traffic data have been suggested to be a good analyzer of internet behavior, while Google Trends acts as a reliable tool in predicting changes in human behavior; subject to careful selection of the searched-for terms, Google data can accurately measure the public’s interest [ 12 ]. Google Trends provides the field of big data with new opportunities, as it has been shown to be valid [ 13 ] and has been proven valuable [ 14 , 15 ], accurate [ 16 ], and beneficial [ 17 ] for forecasting. Therefore, great potential arises from using Web-based queries to examine topics and issues that would have been difficult or even impossible to explore without the use of big data. The monitoring of Web-based activity is a valid indicator of public behavior, and it has been effectively used in predictions [ 18 , 19 ], nowcastings [ 20 ], and forecasting [ 17 , 21 , 22 ].
Google Trends shows the changes in online interest for time series in any selected term in any country or region over a selected time period, for example, a specific year, several years, 3 weeks, 4 months, 30 days, 7 days, 4 hours, 1 hour, or a specified time-frame. In addition, different terms in different regions can be compared simultaneously. Data are downloaded from the Web in “.csv” format and are adjusted as follows: “ Search results are proportionate to the time and location of a query: Each data point is divided by the total searches of the geography and time range it represents, to compare relative popularity. Otherwise places with the most search volume would always be ranked highest. The resulting numbers are then scaled on a range of 0 to 100 based on a topic’s proportion to all searches on all topics. Different regions that show the same number of searches for a term will not always have the same total search volumes ” [ 23 ].
Healthcare is one of the fields in which big data are widely applied [ 24 , 25 ], with the number of publications in this field showing a high increase [ 26 ]. Researchers have placed a significant focus on examining Web-based search queries for health and medicine related topics [ 27 ]. Data from Google Trends have been shown to be valuable in predictions, detection of outbreaks, and monitoring interest, as detailed below, while such applications could be analyzed and evaluated by government officials and policy makers to deal with various health issues and disease occurrence.
The monitoring and analysis of internet data fall under the research field of infodemiology, that is, employing data collected from Web-based sources aiming at informing public health and policy [ 28 ]. These data have the advantage of being real time, thus tackling the issue of long periods of delay from gathering data to analysis and forecasting. Over the past decade, the field of infodemiology has been shown to be highly valuable in assessing health topics, retrieving web-based data from, for example, Google [ 29 , 30 ], Twitter [ 31 - 34 ], social media [ 35 , 36 ], or combinations of ≥2 Web-based data sources [ 37 , 38 ].
As the use of Google Trends in examining human behavior is relatively novel, new methods of assessing Google health data are constantly arising. Up to this point, several topics have been examined, such as epilepsy [ 39 , 40 ], cancer [ 41 ], thrombosis [ 42 ], silicosis [ 43 ], and various medical procedures including cancer screening examinations [ 44 , 45 ], bariatric surgery [ 46 ], and laser eye surgery [ 47 ].
Another trend rising is the measurement of the change in interest in controversial issues [ 48 , 49 ] and in drug-related subjects, such as searches in prescription [ 50 ] or illicit drugs [ 51 , 52 ]. In addition, Google Trends data have been used in examining interest in various aspects of the health care system [ 53 - 55 ].
Apart from the above, Google Trends data have also been useful in measuring the public’s reaction to various outbreaks or incidents, such as attention to the epidemic of Middle East Respiratory Syndrome [ 56 ], the Ebola outbreak [ 57 ], measles [ 58 ], and Swine flu [ 59 ], as well as the influence of media coverage on online interest [ 60 ]. Google queries for the respective terms have been reported to increase or peak when a public figure or celebrity is related [ 61 - 65 ].
Google Trends has also been valuable in examining seasonal trends in various diseases and health issues, such as Lyme disease [ 66 ], urinary tract infection [ 67 ], asthma [ 30 ], varicose vein treatment [ 68 ], and snoring and sleep apnea [ 69 ]. Furthermore, Deiner et al [ 70 ] showed that indeed there exists the same seasonality in Google Trends and clinical diagnoses. What has also been reported is that seasonality in Google searches on tobacco is correlated with seasonality in Google searches on lung cancer [ 71 ], while online queries for allergic rhinitis have the same seasonality as in real life cases [ 72 ]. Thus, we observe that, apart from measuring public interest, Google Trends studies show that the seasonality of online search traffic data can be related to the seasonality of actual cases of the respective diseases searched for.
As mentioned above, Google queries have been used so far to examine general interest in drugs. Taking a step further, Schuster et al [ 73 ] found a correlation between the percentage change in the global revenues in Lipitor statin for dyslipidemia treatment and Google searches, while several other studies have reported findings toward this direction, that is, correlations of Web-based searches with prescription issuing [ 74 - 76 ]. The detection and monitoring of flu has also been of notable popularity in health assessment. Data from Google Flu Trends have been shown to correlate with official flu data [ 77 , 78 ], and Google data on the relevant terms correlate with cases of influenza-like illness [ 79 ].
In addition, online search queries for suicide have been shown to be associated with actual suicide rates [ 80 , 81 ], while other examples indicative of the relationship between Web-based data and human behavior include the correlations between official data and internet searches in veterinary issues [ 82 ], sleep deprivation [ 83 ], sexually transmitted infections [ 84 ], Ebola-related searches [ 85 ], and allergies [ 86 , 87 ].
Furthermore, Zhou et al [ 88 ] showed how the early detection of tuberculosis outbreaks can be improved using Google Trends data; while suicide rates and Google data seem to be related, the former are suggested to be a good indicator for developing suicide prevention policies [ 89 ]. In addition, methamphetamine criminal behavior has been shown to be related to meth searches [ 90 ]. Finally, recent research on using Google Trends in predictions and forecasting include the development of predictive models of pertussis occurrence [ 91 ], while online search queries have been employed to forecast dementia incidence [ 92 ] and prescription volumes in ototopical antibiotics [ 93 ].
Given the diversity of subjects that Google Trends data have been used up for until this point to examine changes in interest and the usefulness of this tool in assessing human behavior, it is evident that the analysis of online search traffic data is indeed valuable in exploring and predicting behavioral changes.
In 2014, Nuti et al [ 27 ] published a systematic review of Google Trends research including the years up to 2013. This review was of importance as the first one in the field, and it reported Google Trends research up to that point. The current review differs from Nuti et al’s in two ways. First, it includes 3 more full years of Google Trends research, that is, 2014, 2015, and 2016, which account for the vast majority of the research conducted in this field for the examined period based on our selection criteria. Second, while the first part of our paper is a systematic review reporting standard information, that is, authors, country, region, keywords, and language, the second part offers a detailed analysis and categorization of the methods, approaches, and statistical tools used in each of this paper. Thus, it serves as a point of reference in Google Trends research not only by subject or topic but by analysis or method as well.
The aim of this review was to include all articles on the topics of health and medicine that have used Google Trends data since its establishment in 2006 through 2016. We searched for the term “Google Trends” in the Scopus [ 94 ] and PubMed [ 95 ] databases from 2006 to 2016, and following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines ( Figure 1 ), the total number of publications included in this review was 109.

Preferred Reporting Items for Systematic Reviews and Meta-Analyses flow diagram of the selection procedure for including studies.
First, we conducted a search in Scopus for the keyword “Google Trends” in the “Abstract-Title-Keywords” field for “Articles,” “Articles in press,” “Reviews,” and “Conference papers” from 2006 to 2016. Out of the available categories, we selected “Medicine,” “Biochemistry Genetics and Molecular Biology,” “Neuroscience,” “Immunology and Microbiology,” “Pharmacology, Toxicology, and Pharmaceuticals,” “Health Profession,” “Nursing,” and “Veterinary.” The search returned 102 publications. Second, we searched for the keyword “Google Trends” in PubMed from 2006 to 2016, which provided a total of 141 publications. Excluding the duplicates, which numbered 84 in total, 159 publications met our criteria. Excluding the ones that did not match the criteria for article type (10 publications) and the ones that did not fall inside the scope of health and medicine (40 publications), a total of 109 studies were included in this review. Note that 5 studies were written in a language other than English and were therefore not included in the quantitative part or in the detailed analysis of the methods of each study. Figure 2 depicts the number of publications by year from 2009 to 2016: 2 in 2009, 3 in 2010, 2 in 2011, 1 in 2012, 12 in 2013, 21 in 2014, 28 in 2015, and 40 in 2016.

Google Trends' publications per year in health-related fields from 2009 to 2016.
The selected studies are further analyzed according to their methodologies, and the gaps, advantages, and limitations of the tool have been discussed so as to assist in future research. Thus, we provide a more detailed categorization of the examined papers according to the main category that they belong to, that is, visualization and general time series analysis, seasonality, correlations, predictions or forecasting, modeling, and statistical method or tool employed. Note that a study can fall into >1 category. The categorization by individual medical field is not applicable due to the high number of individual topics. Table 1 consists of the description of each parameter used to classify each study.
Description of the parameters used for classification.
Multimedia Appendix 1 consists of the first classification of the selected studies [ 27 , 39 - 57 , 59 - 93 , 96 - 144 ]; there are 104 in total, as the studies of Kohler et al [ 145 ], Orellano et al [ 146 ], Cjuno et al [ 147 ], Tejada-Llacsa [ 148 ], and Yang et al [ 149 ] are written in German, Spanish, or Chinese, and thus are not included in the more detailed categorization and analysis.
All the examined papers involve, by definition, time series analysis, and almost all include some form of visualization. Only 8.7% (9/104) studies used Google Trends data for predictions and forecasting, and 23.1% (24/104) used them for examining seasonality, while correlations and modeling were performed in 39.4% (41/104) and 32.7% (34/104) studies, respectively. As the category of forecasting and predictions exhibits the least number of studies, it is evident that a gap exists in the literature for forecasting using Google Trends in health assessment.
As is evident in Multimedia Appendix 1 , Google queries have been employed up to this point in many countries and several languages. Figure 3 shows a worldwide map by examined country for assessing health and medicine related issues using Google Trends data up to 2016. Worldwide, the studies that explore topics related to the respective terms number 23 in total. As far as individual countries are concerned, US data have been employed in the most (60) studies, while other countries that have been significantly examined include the United Kingdom (15), Australia (13), Canada (9), Germany (8), and Italy (7).

Countries by number of Scopus and PubMed publications using Google Trends.
The four most examined countries are English-speaking ones. The reasons for this could include that Google Trends, though not case-sensitive, does take into account accents and spelling mistakes; therefore, for countries with more complicated alphabets, the analysis of Web-based data should be more careful. In addition, other factors that could play a significant role and are taken into account when choosing the countries to be examined using online search traffic data are the availability of official data, the openness of said data, any internet restrictions or monitoring in countries with lower scores in freedom of press or freedom of speech, and internet penetration.
The rest of the analysis consists of the further breaking down of the initial categorization to include the respective methods that were used for examining seasonality, correlations, forecasting, and performing statistical tests and estimating models, along with a concise introduction to each of these methods and how they were used to assess health issues.
Table 2 shows the methods used to explore seasonality; Tables 3 and and4 4 present the methods used to examine correlations and perform predictions and forecasting, respectively. Finally, Tables 5 and and6 6 list the modeling methods and other statistical tools employed in health assessment using Google Trends.
Methods for exploring seasonality with Google Trends in health assessment.
a N/A: not applicable.
Methods of exploring correlations using Google Trends in health assessment.
Forecasting and predictions using Google Trends in health assessment.
Statistical modeling using Google Trends in health assessment.
a ARIMA: autoregressive integrated moving average.
b ARGO: autoregression with Google search data.
Statistical tests and tools using Google Trends in health assessment.
b ANOVA: analysis of variance.
The most popular way to explore seasonality is to use visual evidence and examine and discuss peaks, as shown in Table 2 . Furthermore, several studies have used cosinor analysis [ 8 , 69 , 134 , 138 , 142 ], which is a time series analysis method for seasonal data using least squares.
Apart from seasonality [ 122 ], analysis of variance (ANOVA) has been also used for geographical comparisons between regions or countries [ 49 , 51 , 68 , 93 ] and between differences in monthly data [ 41 ]. It is a test used for examining if significant differences between means exist. In the case of 2 means, t test is the equivalent to ANOVA.
The Kruskal-Wallis test is also a popular method for examining seasonality using Google Trends [ 57 , 68 , 113 ]. It is a nonparametric, independent of distribution test, for continuous as well as ordinal-level dependent variables, employed when the one-way ANOVA assumptions do not hold, that is, for examining statistically significant differences between ≥3 groups. It uses random sample with independent observations, with the dependent variable being at least ordinal.
Other methods of exploring seasonality include the nonparametric tests (independent of distribution) Wilcoxon signed rank [ 18 , 113 ] and Mann-Whitney U test [ 67 ], which are used for comparing data in different seasons or time periods when the equivalent parametric t tests cannot be used. The latter has been also used by some studies to compare weekly data [ 105 ] and differences among regions [ 113 ].
For examining correlations ( Table 3 ), the vast majority of the studies used the Pearson correlation coefficient, which examines the strength of association between 2 quantitative, continuous variables, employed when the relationship is linear. The Spearman rho (rank-order) correlation, the second most used method, is the nonparametric version of the Pearson correlation, has also been used to explore seasonality between time series [ 70 ]. Spearman correlation coefficient (denoted by ρ or r s ) measures the levels to which 2 ranked variables (ordinal, interval, or ratio) are related to each other.
Cross-correlations are used for examining the relationship of 2 time series, while simultaneously exploring if the data are periodic. It is often employed in correlating Google Trends data with observed data [ 50 , 82 , 90 , 135 ] and between different Google search terms [ 80 ], while it can be also used for examining linear and temporal associations of seasonal data [ 71 ]. Cross-correlations have been also used in forecasting, where Wang et al [ 92 ] showed that cross-correlations of new dementia cases with Google Trends data can assist with the forecasting of dementia cases, and Solano et al [ 80 ] forecasted the suicide rates 2 years ahead using Google queries. The autocorrelations are basically cross-correlations for one time series, that is, a time series cross-correlated with itself.
The Kendall’s tau-b test correlation coefficient is a nonparametric alternative to Pearson and Spearman correlations and is used to measure the strength and direction of the relationship between 2 (at least ordinal) variables. It has been employed by 1 study [ 138 ] to examine the correlations between Google Trends data and the results of a paper interview survey.
The Spearman-Brown prediction (or prophecy) formula is used to predict how reliable the test is after changing its length. It has also been employed by only 1 study [ 65 ] to explore the relationship between railway suicide and Google hits.
The generalized linear model estimates the linear relationship between a dependent and ≥1 independent variables. It was used by Domnich et al [ 79 ] to predict influenza-like illness morbidity, with the exploratory variables being “Influenza,” “Fever,” and “Tachipirin search volumes,” along with the Holt-Winters method and the autoregressive moving average process for the residuals. Holt-Winters is a method employed in exploring the seasonality in time series, and for predictions, the autoregressive moving average (also called the Box-Jenkins model) is a special case of the autoregressive integrated moving average, used for the analysis of time series and predictions.
Autoregressive integrated moving average is a commonly used method for time series analysis and predictions [ 55 , 63 , 86 , 92 , 141 ], the latter having also been assessed by linear regressions and modeling [ 88 , 91 ]. Multivariable regressions are used to estimate the relationship of ≥2 independent variables with a dependent one. In Google Trends, they have been used to relate Ebola searches, reported cases, and the Human Development Index [ 85 ] and to study the relationship between climate and environmental variables and Google hits [ 125 ].
Hierarchical linear modeling is a regression of ordinary least squares that is employed to analyze hierarchically structured data, that is, units that are grouped together, and it has been employed by 1 study so far [ 83 ].
The Mann-Kendall test, which is the nonparametric alternative test to the independent sample, has been used to show the statistical differences of peaks [ 43 ] and to detect trends [ 140 ]. Finally, the t test is used to compare 2 sample means of the same population, and it has been employed for comparing Google searches with the baseline period [ 105 ] and to examine the statistical differences of peaks [ 41 ].
Many studies have employed Google Trends for visualizing the changes in online interest or discussing peaks and spikes [ 60 , 62 , 123 , 124 ]. Brigo and Trinka [ 40 ] and Brigo et al [ 39 ] have studied the search volumes for related terms, Chaves et al [ 109 ] and Luckett et al [ 128 ] have explored terms related to the studied topic, and Davis et al [ 110 ] have examined related internet searches. Other approaches include the reporting of the polynomial trend lines [ 46 ] and investigation of statistically significant differences in yearly increases [ 119 ]. In addition, “Google Correlate” has been used to explore related terms [ 91 , 138 ].
Finally, several studies have used other sources of big data, namely, Google News [ 43 , 63 , 80 ], Twitter [ 43 , 54 , 61 , 63 , 108 ], Yandex [ 52 ], Baidu [ 121 ], Wikipedia [ 43 , 63 ], Facebook and Google+ [ 54 ], and YouTube [ 43 , 54 , 63 ]. Google is the most popular search engine. However, other Web-based sources are used or even preferred to Google in some regions; therefore, many studies use data from these sources to examine general interest in the respective subjects, compare them to Google Trends data, or use them together as variables.
Principal Findings
With internet penetration constantly growing, users’ Web-based search patterns can provide a great opportunity to examine and further predict human behavior. In addressing the challenge of big data analytics, Google Trends has been a popular tool in research over the past decade, with its main advantage being that it uses the revealed and not the stated data. Health and medicine are the most popular fields where Google Trends data have been employed so far to examine and predict human behavior. This review provides a detailed overview and classification of the examined studies (109 in total from 2006 through 2016), which are then further categorized and analyzed by approach, method, and statistical tools employed for data analysis.
The vast majority of studies using Google Trends in health assessment so far have included data visualization, that is, figures, maps, or screenshots. As discussed in the analysis, the most popular way of using Google Trends data in this field is correlating them with official data on disease occurrence, spreading, and outbreaks. The assessment of suicide tendencies and (prescription or illegal) drug-related queries has been of notably growing popularity over the course of the last years. As is evident, the gap in the existing literature is the use of Google Trends for predictions and forecasting in health-related topics and issues. Though data on reported cases of various health issues and the respective Google Trends data have been correlated in a large number of studies, only a few have proceeded with forecasting incidents and occurrences using online search traffic data.
In research using Google Trends in health and medicine from 2006 to 2016, the ultimate goal is to be able to use and analyze Web-based data to predict and provide insight to better assess health issues and topics. The four main steps, based on the presentation of the papers published up to this point in assessing health using Google Trends, are as follows ( Figure 4 ):

The four steps toward employing Google Trends for health assessment.
- Measure the general Web-based interest.
- Detect any variations or seasonality of Web-based interest, and proceed with examining any relations between actual events or cases.
- Correlate Web-based search queries among them or with official or actual data and events.
- Predict, nowcast, and forecast health-related events, outbreaks, etc.
Limitations
This review followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines for selecting the examined papers from the Scopus and PubMed databases. Though this includes the majority of papers published on the topic from 2006 to 2016, the studies that are not indexed in these databases or are not indexed based on the selection criteria used in this review were not included in further analysis. In addition, as is evident in Figure 2 , research using Google Trends data has shown a significant increase from each year to the next since 2013. This review included studies published in Google Trends research through 2016. However, there are several studies published in 2017 and 2018 that are not included. This review provides, at first, an overall description of each examined study, which is standard review information. The second part is a classification and assessment of the methodology, tools, and results of each study. Though the first part mainly reports what is included in the methodology of each study, the second part could include a bias, as it is the authors’ assessment and categorization of the methods employed based on the results obtained after a very careful and thorough examination of each individual study.
This review consists of the studies published from 2006 to 2016 on Google Trends research in the Scopus and PubMed databases based on the selected criteria. The aim of this review was to serve as a point of reference for future research in health assessment using Google Trends, as each study, apart from the basic information, for example, period, region, language, is also categorized by the method, approach, and statistical tools employed for the analysis of the data retrieved from Google Trends. Google Trends data are being all the more integrated in infodemiology research, and Web-based data have been shown to empirically correlate with official health data in many topics. It is thus evident that this field will become increasingly popular in the future in health assessment, as the gathering of real time data is crucial in monitoring and analyzing seasonal diseases as well as epidemics and outbreaks.
Abbreviations
Multimedia appendix 1.
Conflicts of Interest: None declared.
Statistics Research Paper

View sample Statistics Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our custom writing service s for professional assistance. We offer high-quality assignments for reasonable rates.

Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% off with 24start discount code, more statistics research papers:.
- Time Series Research Paper
- Crime Statistics Research Paper
- Economic Statistics Research Paper
- Education Statistics Research Paper
- Health Statistics Research Paper
- Labor Statistics Research Paper
- History of Statistics Research Paper
- Survey Sampling Research Paper
- Multidimensional Scaling Research Paper
- Sequential Statistical Methods Research Paper
- Simultaneous Equation Estimation Research Paper
- Statistical Clustering Research Paper
- Statistical Sufficiency Research Paper
- Censuses Of Population Research Paper
- Stochastic Models Research Paper
- Stock Market Predictability Research Paper
- Structural Equation Modeling Research Paper
- Survival Analysis Research Paper
- Systems Modeling Research Paper
- Nonprobability Sampling Research Paper
1. Introduction
Statistics is a body of quantitative methods associated with empirical observation. A primary goal of these methods is coping with uncertainty. Most formal statistical methods rely on probability theory to express this uncertainty and to provide a formal mathematical basis for data description and for analysis. The notion of variability associated with data, expressed through probability, plays a fundamental role in this theory. As a consequence, much statistical effort is focused on how to control and measure variability and/or how to assign it to its sources.
Almost all characterizations of statistics as a field include the following elements:
(a) Designing experiments, surveys, and other systematic forms of empirical study.
(b) Summarizing and extracting information from data.
(c) Drawing formal inferences from empirical data through the use of probability.
(d) Communicating the results of statistical investigations to others, including scientists, policy makers, and the public.
This research paper describes a number of these elements, and the historical context out of which they grew. It provides a broad overview of the field, that can serve as a starting point to many of the other statistical entries in this encyclopedia.
2. The Origins Of The Field of Statistics
The word ‘statistics’ is related to the word ‘state’ and the original activity that was labeled as statistics was social in nature and related to elements of society through the organization of economic, demographic, and political facts. Paralleling this work to some extent was the development of the probability calculus and the theory of errors, typically associated with the physical sciences. These traditions came together in the nineteenth century and led to the notion of statistics as a collection of methods for the analysis of scientific data and the drawing of inferences therefrom.
As Hacking (1990) has noted: ‘By the end of the century chance had attained the respectability of a Victorian valet, ready to be the logical servant of the natural, biological and social sciences’ ( p. 2). At the beginning of the twentieth century, we see the emergence of statistics as a field under the leadership of Karl Pearson, George Udny Yule, Francis Y. Edgeworth, and others of the ‘English’ statistical school. As Stigler (1986) suggests:
Before 1900 we see many scientists of different fields developing and using techniques we now recognize as belonging to modern statistics. After 1900 we begin to see identifiable statisticians developing such techniques into a unified logic of empirical science that goes far beyond its component parts. There was no sharp moment of birth; but with Pearson and Yule and the growing number of students in Pearson’s laboratory, the infant discipline may be said to have arrived. (p. 361)
Pearson’s laboratory at University College, London quickly became the first statistics department in the world and it was to influence subsequent developments in a profound fashion for the next three decades. Pearson and his colleagues founded the first methodologically-oriented statistics journal, Biometrika, and they stimulated the development of new approaches to statistical methods. What remained before statistics could legitimately take on the mantle of a field of inquiry, separate from mathematics or the use of statistical approaches in other fields, was the development of the formal foundations of theories of inference from observations, rooted in an axiomatic theory of probability.
Beginning at least with the Rev. Thomas Bayes and Pierre Simon Laplace in the eighteenth century, most early efforts at statistical inference used what was known as the method of inverse probability to update a prior probability using the observed data in what we now refer to as Bayes’ Theorem. (For a discussion of who really invented Bayes’ Theorem, see Stigler 1999, Chap. 15). Inverse probability came under challenge in the nineteenth century, but viable alternative approaches gained little currency. It was only with the work of R. A. Fisher on statistical models, estimation, and significance tests, and Jerzy Neyman and Egon Pearson, in the 1920s and 1930s, on tests of hypotheses, that alternative approaches were fully articulated and given a formal foundation. Neyman’s advocacy of the role of probability in the structuring of a frequency-based approach to sample surveys in 1934 and his development of confidence intervals further consolidated this effort at the development of a foundation for inference (cf. Statistical Methods, History of: Post- 1900 and the discussion of ‘The inference experts’ in Gigerenzer et al. 1989).
At about the same time Kolmogorov presented his famous axiomatic treatment of probability, and thus by the end of the 1930s, all of the requisite elements were finally in place for the identification of statistics as a field. Not coincidentally, the first statistical society devoted to the mathematical underpinnings of the field, The Institute of Mathematical Statistics, was created in the United States in the mid-1930s. It was during this same period that departments of statistics and statistical laboratories and groups were first formed in universities in the United States.
3. Emergence Of Statistics As A Field
3.1 the role of world war ii.
Perhaps the greatest catalysts to the emergence of statistics as a field were two major social events: the Great Depression of the 1930s and World War II. In the United States, one of the responses to the depression was the development of large-scale probability-based surveys to measure employment and unemployment. This was followed by the institutionalization of sampling as part of the 1940 US decennial census. But with World War II raging in Europe and in Asia, mathematicians and statisticians were drawn into the war effort, and as a consequence they turned their attention to a broad array of new problems. In particular, multiple statistical groups were established in both England and the US specifically to develop new methods and to provide consulting. (See Wallis 1980, on statistical groups in the US; Barnard and Plackett 1985, for related efforts in the United Kingdom; and Fienberg 1985). These groups not only created imaginative new techniques such as sequential analysis and statistical decision theory, but they also developed a shared research agenda. That agenda led to a blossoming of statistics after the war, and in the 1950s and 1960s to the creation of departments of statistics at universities—from coast to coast in the US, and to a lesser extent in England and elsewhere.
3.2 The Neo-Bayesian Revival
Although inverse probability came under challenge in the 1920s and 1930s, it was not totally abandoned. John Maynard Keynes (1921) wrote A Treatise on Probability that was rooted in this tradition, and Frank Ramsey (1926) provided an early effort at justifying the subjective nature of prior distributions and suggested the importance of utility functions as an adjunct to statistical inference. Bruno de Finetti provided further development of these ideas in the 1930s, while Harold Jeffreys (1938) created a separate ‘objective’ development of these and other statistical ideas on inverse probability.
Yet as statistics flourished in the post-World War II era, it was largely based on the developments of Fisher, Neyman and Pearson, as well as the decision theory methods of Abraham Wald (1950). L. J. Savage revived interest in the inverse probability approach with The Foundations of Statistics (1954) in which he attempted to provide the axiomatic foundation from the subjective perspective. In an essentially independent effort, Raiffa and Schlaifer (1961) attempted to provide inverse probability counterparts to many of the then existing frequentist tools, referring to these alternatives as ‘Bayesian.’ By 1960, the term ‘Bayesian inference’ had become standard usage in the statistical literature, the theoretical interest in the development of Bayesian approaches began to take hold, and the neo-Bayesian revival was underway. But the movement from Bayesian theory to statistical practice was slow, in large part because the computations associated with posterior distributions were an overwhelming stumbling block for those who were interested in the methods. Only in the 1980s and 1990s did new computational approaches revolutionize both Bayesian methods, and the interest in them, in a broad array of areas of application.
3.3 The Role Of Computation In Statistics
From the days of Pearson and Fisher, computation played a crucial role in the development and application of statistics. Pearson’s laboratory employed dozens of women who used mechanical devices to carry out the careful and painstaking calculations required to tabulate values from various probability distributions. This effort ultimately led to the creation of the Biometrika Tables for Statisticians that were so widely used by others applying tools such as chisquare tests and the like. Similarly, Fisher also developed his own set of statistical tables with Frank Yates when he worked at Rothamsted Experiment Station in the 1920s and 1930s. One of the most famous pictures of Fisher shows him seated at Whittingehame Lodge, working at his desk calculator (see Box 1978).
The development of the modern computer revolutionized statistical calculation and practice, beginning with the creation of the first statistical packages in the 1960s—such as the BMDP package for biological and medical applications, and Datatext for statistical work in the social sciences. Other packages soon followed—such as SAS and SPSS for both data management and production-like statistical analyses, and MINITAB for the teaching of statistics. In 2001, in the era of the desktop personal computer, almost everyone has easy access to interactive statistical programs that can implement complex statistical procedures and produce publication-quality graphics. And there is a new generation of statistical tools that rely upon statistical simulation such as the bootstrap and Markov Chain Monte Carlo methods. Complementing the traditional production-like packages for statistical analysis are more methodologically oriented languages such as S and S-PLUS, and symbolic and algebraic calculation packages. Statistical journals and those in various fields of application devote considerable space to descriptions of such tools.
4. Statistics At The End Of The Twentieth Century
It is widely recognized that any statistical analysis can only be as good as the underlying data. Consequently, statisticians take great care in the the design of methods for data collection and in their actual implementation. Some of the most important modes of statistical data collection include censuses, experiments, observational studies, and sample Surveys, all of which are discussed elsewhere in this encyclopedia. Statistical experiments gain their strength and validity both through the random assignment of treatments to units and through the control of nontreatment variables. Similarly sample surveys gain their validity for generalization through the careful design of survey questionnaires and probability methods used for the selection of the sample units. Approaches to cope with the failure to fully implement randomization in experiments or random selection in sample surveys are discussed in Experimental Design: Compliance and Nonsampling Errors.
Data in some statistical studies are collected essentially at a single point in time (cross-sectional studies), while in others they are collected repeatedly at several time points or even continuously, while in yet others observations are collected sequentially, until sufficient information is available for inferential purposes. Different entries discuss these options and their strengths and weaknesses.
After a century of formal development, statistics as a field has developed a number of different approaches that rely on probability theory as a mathematical basis for description, analysis, and statistical inference. We provide an overview of some of these in the remainder of this section and provide some links to other entries in this encyclopedia.
4.1 Data Analysis
The least formal approach to inference is often the first employed. Its name stems from a famous article by John Tukey (1962), but it is rooted in the more traditional forms of descriptive statistical methods used for centuries.
Today, data analysis relies heavily on graphical methods and there are different traditions, such as those associated with
(a) The ‘exploratory data analysis’ methods suggested by Tukey and others.
(b) The more stylized correspondence analysis techniques of Benzecri and the French school.
(c) The alphabet soup of computer-based multivariate methods that have emerged over the past decade such as ACE, MARS, CART, etc.
No matter which ‘school’ of data analysis someone adheres to, the spirit of the methods is typically to encourage the data to ‘speak for themselves.’ While no theory of data analysis has emerged, and perhaps none is to be expected, the flexibility of thought and method embodied in the data analytic ideas have influenced all of the other approaches.
4.2 Frequentism
The name of this group of methods refers to a hypothetical infinite sequence of data sets generated as was the data set in question. Inferences are to be made with respect to this hypothetical infinite sequence. (For details, see Frequentist Inference).
One of the leading frequentist methods is significance testing, formalized initially by R. A. Fisher (1925) and subsequently elaborated upon and extended by Neyman and Pearson and others (see below). Here a null hypothesis is chosen, for example, that the mean, µ, of a normally distributed set of observations is 0. Fisher suggested the choice of a test statistic, e.g., based on the sample mean, x, and the calculation of the likelihood of observing an outcome as or more extreme as x is from µ 0, a quantity usually labeled as the p-value. When p is small (e.g., less than 5 percent), either a rare event has occurred or the null hypothesis is false. Within this theory, no probability can be given for which of these two conclusions is the case.
A related set of methods is testing hypotheses, as proposed by Neyman and Pearson (1928, 1932). In this approach, procedures are sought having the property that, for an infinite sequence of such sets, in only (say) 5 percent for would the null hypothesis be rejected if the null hypothesis were true. Often the infinite sequence is restricted to sets having the same sample size, but this is unnecessary. Here, in addition to the null hypothesis, an alternative hypothesis is specified. This permits the definition of a power curve, reflecting the frequency of rejecting the null hypothesis when the specified alternative is the case. But, as with the Fisherian approach, no probability can be given to either the null or the alternative hypotheses.
The construction of confidence intervals, following the proposal of Neyman (1934), is intimately related to testing hypotheses; indeed a 95 percent confidence interval may be regarded as the set of null hypotheses which, had they been tested at the 5 percent level of significance, would not have been rejected. A confidence interval is a random interval, having the property that the specified proportion (say 95 percent) of the infinite sequence, of random intervals would have covered the true value. For example, an interval that 95 percent of the time (by auxiliary randomization) is the whole real line, and 5 percent of the time is the empty set, is a valid 95 percent confidence interval.
Estimation of parameters—i.e., choosing a single value of the parameters that is in some sense best—is also an important frequentist method. Many methods have been proposed, both for particular models and as general approaches regardless of model, and their frequentist properties explored. These methods usually extended to intervals of values through inversion of test statistics or via other related devices. The resulting confidence intervals share many of the frequentist theoretical properties of the corresponding test procedures.
Frequentist statisticians have explored a number of general properties thought to be desirable in a procedure, such as invariance, unbiasedness, sufficiency, conditioning on ancillary statistics, etc. While each of these properties has examples in which it appears to produce satisfactory recommendations, there are others in which it does not. Additionally, these properties can conflict with each other. No general frequentist theory has emerged that proposes a hierarchy of desirable properties, leaving a frequentist without guidance in facing a new problem.
4.3 Likelihood Methods
The likelihood function (first studied systematically by R. A. Fisher) is the probability density of the data, viewed as a function of the parameters. It occupies an interesting middle ground in the philosophical debate, as it is used both by frequentists (as in maximum likelihood estimation) and by Bayesians in the transition from prior distributions to posterior distributions. A small group of scholars (among them G. A. Barnard, A. W. F. Edwards, R. Royall, D. Sprott) have proposed the likelihood function as an independent basis for inference. The issue of nuisance parameters has perplexed this group, since maximization, as would be consistent with maximum likelihood estimation, leads to different results in general than does integration, which would be consistent with Bayesian ideas.
4.4 Bayesian Methods
Both frequentists and Bayesians accept Bayes’ Theorem as correct, but Bayesians use it far more heavily. Bayesian analysis proceeds from the idea that probability is personal or subjective, reflecting the views of a particular person at a particular point in time. These views are summarized in the prior distribution over the parameter space. Together the prior distribution and the likelihood function define the joint distribution of the parameters and the data. This joint distribution can alternatively be factored as the product of the posterior distribution of the parameter given the data times the predictive distribution of the data.
In the past, Bayesian methods were deemed to be controversial because of the avowedly subjective nature of the prior distribution. But the controversy surrounding their use has lessened as recognition of the subjective nature of the likelihood has spread. Unlike frequentist methods, Bayesian methods are, in principle, free of the paradoxes and counterexamples that make classical statistics so perplexing. The development of hierarchical modeling and Markov Chain Monte Carlo (MCMC) methods have further added to the current popularity of the Bayesian approach, as they allow analyses of models that would otherwise be intractable.
Bayesian decision theory, which interacts closely with Bayesian statistical methods, is a useful way of modeling and addressing decision problems of experimental designs and data analysis and inference. It introduces the notion of utilities and the optimum decision combines probabilities of events with utilities by the calculation of expected utility and maximizing the latter (e.g., see the discussion in Lindley 2000).
Current research is attempting to use the Bayesian approach to hypothesis testing to provide tests and pvalues with good frequentist properties (see Bayarri and Berger 2000).
4.5 Broad Models: Nonparametrics And Semiparametrics
These models include parameter spaces of infinite dimensions, whether addressed in a frequentist or Bayesian manner. In a sense, these models put more inferential weight on the assumption of conditional independence than does an ordinary parametric model.
4.6 Some Cross-Cutting Themes
Often different fields of application of statistics need to address similar issues. For example, dimensionality of the parameter space is often a problem. As more parameters are added, the model will in general fit better (at least no worse). Is the apparent gain in accuracy worth the reduction in parsimony? There are many different ways to address this question in the various applied areas of statistics.
Another common theme, in some sense the obverse of the previous one, is the question of model selection and goodness of fit. In what sense can one say that a set of observations is well-approximated by a particular distribution? (cf. Goodness of Fit: Overview). All statistical theory relies at some level on the use of formal models, and the appropriateness of those models and their detailed specification are of concern to users of statistical methods, no matter which school of statistical inference they choose to work within.
5. Statistics In The Twenty-first Century
5.1 adapting and generalizing methodology.
Statistics as a field provides scientists with the basis for dealing with uncertainty, and, among other things, for generalizing from a sample to a population. There is a parallel sense in which statistics provides a basis for generalization: when similar tools are developed within specific substantive fields, such as experimental design methodology in agriculture and medicine, and sample surveys in economics and sociology. Statisticians have long recognized the common elements of such methodologies and have sought to develop generalized tools and theories to deal with these separate approaches (see e.g., Fienberg and Tanur 1989).
One hallmark of modern statistical science is the development of general frameworks that unify methodology. Thus the tools of Generalized Linear Models draw together methods for linear regression and analysis of various models with normal errors and those log-linear and logistic models for categorical data, in a broader and richer framework. Similarly, graphical models developed in the 1970s and 1980s use concepts of independence to integrate work in covariance section, decomposable log-linear models, and Markov random field models, and produce new methodology as a consequence. And the latent variable approaches from psychometrics and sociology have been tied with simultaneous equation and measurement error models from econometrics into a broader theory of covariance analysis and structural equations models.
Another hallmark of modern statistical science is the borrowing of methods in one field for application in another. One example is provided by Markov Chain Monte Carlo methods, now used widely in Bayesian statistics, which were first used in physics. Survival analysis, used in biostatistics to model the disease-free time or time-to-mortality of medical patients, and analyzed as reliability in quality control studies, are now used in econometrics to measure the time until an unemployed person gets a job. We anticipate that this trend of methodological borrowing will continue across fields of application.
5.2 Where Will New Statistical Developments Be Focused ?
In the issues of its year 2000 volume, the Journal of the American Statistical Association explored both the state of the art of statistics in diverse areas of application, and that of theory and methods, through a series of vignettes or short articles. These essays provide an excellent supplement to the entries of this encyclopedia on a wide range of topics, not only presenting a snapshot of the current state of play in selected areas of the field but also affecting some speculation on the next generation of developments. In an afterword to the last set of these vignettes, Casella (2000) summarizes five overarching themes that he observed in reading through the entire collection:
(a) Large datasets.
(b) High-dimensional/nonparametric models.
(c) Accessible computing.
(d) Bayes/frequentist/who cares?
(e) Theory/applied/why differentiate?
Not surprisingly, these themes fit well those that one can read into the statistical entries in this encyclopedia. The coming together of Bayesian and frequentist methods, for example, is illustrated by the movement of frequentists towards the use of hierarchical models and the regular consideration of frequentist properties of Bayesian procedures (e.g., Bayarri and Berger 2000). Similarly, MCMC methods are being widely used in non-Bayesian settings and, because they focus on long-run sequences of dependent draws from multivariate probability distributions, there are frequentist elements that are brought to bear in the study of the convergence of MCMC procedures. Thus the oft-made distinction between the different schools of statistical inference (suggested in the preceding section) is not always clear in the context of real applications.
5.3 The Growing Importance Of Statistics Across The Social And Behavioral Sciences
Statistics touches on an increasing number of fields of application, in the social sciences as in other areas of scholarship. Historically, the closest links have been with economics; together these fields share parentage of econometrics. There are now vigorous interactions with political science, law, sociology, psychology, anthropology, archeology, history, and many others.
In some fields, the development of statistical methods has not been universally welcomed. Using these methods well and knowledgeably requires an understanding both of the substantive field and of statistical methods. Sometimes this combination of skills has been difficult to develop.
Statistical methods are having increasing success in addressing questions throughout the social and behavioral sciences. Data are being collected and analyzed on an increasing variety of subjects, and the analyses are becoming increasingly sharply focused on the issues of interest.
We do not anticipate, nor would we find desirable, a future in which only statistical evidence was accepted in the social and behavioral sciences. There is room for, and need for, many different approaches. Nonetheless, we expect the excellent progress made in statistical methods in the social and behavioral sciences in recent decades to continue and intensify.
Bibliography:
- Barnard G A, Plackett R L 1985 Statistics in the United Kingdom, 1939–1945. In: Atkinson A C, Fienberg S E (eds.) A Celebration of Statistics: The ISI Centennial Volume. Springer-Verlag, New York, pp. 31–55
- Bayarri M J, Berger J O 2000 P values for composite null models (with discussion). Journal of the American Statistical Association 95: 1127–72
- Box J 1978 R. A. Fisher, The Life of a Scientist. Wiley, New York
- Casella G 2000 Afterword. Journal of the American Statistical Association 95: 1388
- Fienberg S E 1985 Statistical developments in World War II: An international perspective. In: Anthony C, Atkinson A C, Fienberg S E (eds.) A Celebration of Statistics: The ISI Centennial Volume. Springer-Verlag, New York, pp. 25–30
- Fienberg S E, Tanur J M 1989 Combining cognitive and statistical approaches to survey design. Science 243: 1017–22
- Fisher R A 1925 Statistical Methods for Research Workers. Oliver and Boyd, London
- Gigerenzer G, Swijtink Z, Porter T, Daston L, Beatty J, Kruger L 1989 The Empire of Chance. Cambridge University Press, Cambridge, UK
- Hacking I 1990 The Taming of Chance. Cambridge University Press, Cambridge, UK
- Jeffreys H 1938 Theory of Probability, 2nd edn. Clarendon Press, Oxford, UK
- Keynes J 1921 A Treatise on Probability. Macmillan, London
- Lindley D V 2000/1932 The philosophy of statistics (with discussion). The Statistician 49: 293–337
- Neyman J 1934 On the two different aspects of the representative method: the method of stratified sampling and the method of purposive selection (with discussion). Journal of the Royal Statistical Society 97: 558–625
- Neyman J, Pearson E S 1928 On the use and interpretation of certain test criteria for purposes of statistical inference. Part I. Biometrika 20A: 175–240
- Neyman J, Pearson E S 1932 On the problem of the most efficient tests of statistical hypotheses. Philosophical Transactions of the Royal Society, Series. A 231: 289–337
- Raiffa H, Schlaifer R 1961 Applied Statistical Decision Theory. Harvard Business School, Boston
- Ramsey F P 1926 Truth and probability. In: The Foundations of Mathematics and Other Logical Essays. Kegan Paul, London, pp.
- Savage L J 1954 The Foundations of Statistics. Wiley, New York
- Stigler S M 1986 The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press, Cambridge, MA
- Stigler S M 1999 Statistics on the Table: The History of Statistical Concepts and Methods. Harvard University Press, Cambridge, MA
- Tukey John W 1962 The future of data analysis. Annals of Mathematical Statistics 33: 1–67
- Wald A 1950 Statistical Decision Functions. Wiley, New York
- Wallis W 1980 The Statistical Research Group, 1942–1945 (with discussion). Journal of the American Statistical Association 75: 320–35
ORDER HIGH QUALITY CUSTOM PAPER

Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Sampling Methods | Types, Techniques & Examples
Sampling Methods | Types, Techniques & Examples
Published on September 19, 2019 by Shona McCombes . Revised on June 22, 2023.
When you conduct research about a group of people, it’s rarely possible to collect data from every person in that group. Instead, you select a sample . The sample is the group of individuals who will actually participate in the research.
To draw valid conclusions from your results, you have to carefully decide how you will select a sample that is representative of the group as a whole. This is called a sampling method . There are two primary types of sampling methods that you can use in your research:
- Probability sampling involves random selection, allowing you to make strong statistical inferences about the whole group.
- Non-probability sampling involves non-random selection based on convenience or other criteria, allowing you to easily collect data.
You should clearly explain how you selected your sample in the methodology section of your paper or thesis, as well as how you approached minimizing research bias in your work.
Table of contents
Population vs. sample, probability sampling methods, non-probability sampling methods, other interesting articles, frequently asked questions about sampling.
First, you need to understand the difference between a population and a sample , and identify the target population of your research.
- The population is the entire group that you want to draw conclusions about.
- The sample is the specific group of individuals that you will collect data from.
The population can be defined in terms of geographical location, age, income, or many other characteristics.

It is important to carefully define your target population according to the purpose and practicalities of your project.
If the population is very large, demographically mixed, and geographically dispersed, it might be difficult to gain access to a representative sample. A lack of a representative sample affects the validity of your results, and can lead to several research biases , particularly sampling bias .
Sampling frame
The sampling frame is the actual list of individuals that the sample will be drawn from. Ideally, it should include the entire target population (and nobody who is not part of that population).
Sample size
The number of individuals you should include in your sample depends on various factors, including the size and variability of the population and your research design. There are different sample size calculators and formulas depending on what you want to achieve with statistical analysis .
Prevent plagiarism. Run a free check.
Probability sampling means that every member of the population has a chance of being selected. It is mainly used in quantitative research . If you want to produce results that are representative of the whole population, probability sampling techniques are the most valid choice.
There are four main types of probability sample.

1. Simple random sampling
In a simple random sample, every member of the population has an equal chance of being selected. Your sampling frame should include the whole population.
To conduct this type of sampling, you can use tools like random number generators or other techniques that are based entirely on chance.
2. Systematic sampling
Systematic sampling is similar to simple random sampling, but it is usually slightly easier to conduct. Every member of the population is listed with a number, but instead of randomly generating numbers, individuals are chosen at regular intervals.
If you use this technique, it is important to make sure that there is no hidden pattern in the list that might skew the sample. For example, if the HR database groups employees by team, and team members are listed in order of seniority, there is a risk that your interval might skip over people in junior roles, resulting in a sample that is skewed towards senior employees.
3. Stratified sampling
Stratified sampling involves dividing the population into subpopulations that may differ in important ways. It allows you draw more precise conclusions by ensuring that every subgroup is properly represented in the sample.
To use this sampling method, you divide the population into subgroups (called strata) based on the relevant characteristic (e.g., gender identity, age range, income bracket, job role).
Based on the overall proportions of the population, you calculate how many people should be sampled from each subgroup. Then you use random or systematic sampling to select a sample from each subgroup.
4. Cluster sampling
Cluster sampling also involves dividing the population into subgroups, but each subgroup should have similar characteristics to the whole sample. Instead of sampling individuals from each subgroup, you randomly select entire subgroups.
If it is practically possible, you might include every individual from each sampled cluster. If the clusters themselves are large, you can also sample individuals from within each cluster using one of the techniques above. This is called multistage sampling .
This method is good for dealing with large and dispersed populations, but there is more risk of error in the sample, as there could be substantial differences between clusters. It’s difficult to guarantee that the sampled clusters are really representative of the whole population.
In a non-probability sample, individuals are selected based on non-random criteria, and not every individual has a chance of being included.
This type of sample is easier and cheaper to access, but it has a higher risk of sampling bias . That means the inferences you can make about the population are weaker than with probability samples, and your conclusions may be more limited. If you use a non-probability sample, you should still aim to make it as representative of the population as possible.
Non-probability sampling techniques are often used in exploratory and qualitative research . In these types of research, the aim is not to test a hypothesis about a broad population, but to develop an initial understanding of a small or under-researched population.

1. Convenience sampling
A convenience sample simply includes the individuals who happen to be most accessible to the researcher.
This is an easy and inexpensive way to gather initial data, but there is no way to tell if the sample is representative of the population, so it can’t produce generalizable results. Convenience samples are at risk for both sampling bias and selection bias .
2. Voluntary response sampling
Similar to a convenience sample, a voluntary response sample is mainly based on ease of access. Instead of the researcher choosing participants and directly contacting them, people volunteer themselves (e.g. by responding to a public online survey).
Voluntary response samples are always at least somewhat biased , as some people will inherently be more likely to volunteer than others, leading to self-selection bias .
3. Purposive sampling
This type of sampling, also known as judgement sampling, involves the researcher using their expertise to select a sample that is most useful to the purposes of the research.
It is often used in qualitative research , where the researcher wants to gain detailed knowledge about a specific phenomenon rather than make statistical inferences, or where the population is very small and specific. An effective purposive sample must have clear criteria and rationale for inclusion. Always make sure to describe your inclusion and exclusion criteria and beware of observer bias affecting your arguments.
4. Snowball sampling
If the population is hard to access, snowball sampling can be used to recruit participants via other participants. The number of people you have access to “snowballs” as you get in contact with more people. The downside here is also representativeness, as you have no way of knowing how representative your sample is due to the reliance on participants recruiting others. This can lead to sampling bias .
5. Quota sampling
Quota sampling relies on the non-random selection of a predetermined number or proportion of units. This is called a quota.
You first divide the population into mutually exclusive subgroups (called strata) and then recruit sample units until you reach your quota. These units share specific characteristics, determined by you prior to forming your strata. The aim of quota sampling is to control what or who makes up your sample.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Quartiles & Quantiles
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Prospective cohort study
Research bias
- Implicit bias
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
- Social desirability bias
A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
Probability sampling means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling .
In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling, and quota sampling .
In multistage sampling , or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage.
This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from.
Sampling bias occurs when some members of a population are systematically more likely to be selected in a sample than others.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, June 22). Sampling Methods | Types, Techniques & Examples. Scribbr. Retrieved April 9, 2024, from https://www.scribbr.com/methodology/sampling-methods/
Is this article helpful?

Shona McCombes
Other students also liked, population vs. sample | definitions, differences & examples, simple random sampling | definition, steps & examples, sampling bias and how to avoid it | types & examples, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
COMMENTS
Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise only if ...
Table of contents. Step 1: Write your hypotheses and plan your research design. Step 2: Collect data from a sample. Step 3: Summarize your data with descriptive statistics. Step 4: Test hypotheses or make estimates with inferential statistics.
Abstract. Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings ...
Let's go through the top 9 best statistical tools used in research below: 1. SPSS: SPSS (Statistical Package for the Social Sciences) is a collection of software tools compiled as a single package. This program's primary function is to analyze scientific data in social science. This information can be utilized for market research, surveys ...
Introduction. Statistical analysis is necessary for any research project seeking to make quantitative conclusions. The following is a primer for research-based statistical analysis. It is intended to be a high-level overview of appropriate statistical testing, while not diving too deep into any specific methodology.
Example: Inferential statistics. You randomly select a sample of 11th graders in your state and collect data on their SAT scores and other characteristics. You can use inferential statistics to make estimates and test hypotheses about the whole population of 11th graders in the state based on your sample data.
As you read papers also notice the construction of the papers (learn from the good and bad examples). Abstract and Introduction { keys for getting readers engaged. Be gentle with your audience. Tell them your story. Writing is work { but ultimately rewarding! 13. Created Date.
Inferential statistics. In inferential statistics, data from a sample is analysed to conclude the entire population. The goal is to prove or disprove the theories. A hypothesis is a suggested explanation for a phenomenon (plural hypotheses). Hypothesis testing is essential to process for making logical choices regarding observed effects ...
The purpose of statistical analysis is to clarify and not confuse. It is a tool for answering questions. It allows us to take large bodies of information and summarize them with a few simple statements. It lets us come to solid conclusions even when the realities of the research world make it difficult to isolate the problems we seek to study.
When to perform a statistical test. You can perform statistical tests on data that have been collected in a statistically valid manner - either through an experiment, or through observations made using probability sampling methods.. For a statistical test to be valid, your sample size needs to be large enough to approximate the true distribution of the population being studied.
Role of Statistics in Biological Research. Statistics is a branch of science that deals with collection, organization and analysis of data from the sample to the whole population. Moreover, it aids in designing a study more meticulously and also give a logical reasoning in concluding the hypothesis.
Primary data: This refers to the first-hand data collected directly from the source or subject or sample of a study or research. The subject or sample of the study could be human beings or plants ...
The article covers a brief outline of the variables, an understanding of quantitative and qualitative variables and the measures of central tendency. An idea of the sample size estimation, power analysis and the statistical errors is given. Finally, there is a summary of parametric and non-parametric tests used for data analysis.
Basic Statistical Techniques in Research 3. present, data and conditions; it is also possible to make prediction s. based on this information. It would be observed that descriptive. statistics ...
Statistics is a branch of science that deals with the collection, organisation, analysis of data and drawing of inferences from the samples to the whole population. [ 1] This requires a proper design of the study, an appropriate selection of the study sample and choice of a suitable statistical test. An adequate knowledge of statistics is ...
Statistical methods constitute a powerful tool in modern life sciences. This tool is primarily used to disentangle whether the observed differences, relationships or congruencies are meaningful or may just occur by chance. Thus, statistical inference is an unavoidable part of scientific work.
The p value determines statistical significance. An extremely low p value indicates high statistical significance, while a high p value means low or no statistical significance. Example: Hypothesis testing. To test your hypothesis, you first collect data from two groups. The experimental group actively smiles, while the control group does not.
Thus, we provide a more detailed categorization of the examined papers according to the main category that they belong to, that is, visualization and general time series analysis, seasonality, correlations, predictions or forecasting, modeling, and statistical method or tool employed. Note that a study can fall into >1 category.
The function of statistics in research is to purpose as a tool in conniving research, analyzing its data and portrayal of conclusions there from. Most research studies result in a extensive ...
precision. Fortunately, with a few simple convenient statistical tools most of the information needed in regular laboratory work can be obtained: the "t-test, the "F-test", and regression analysis. Clearly, statistics are a tool, not an aim. Simple inspection of data, without statistical treatment, by an experienced and dedicated analyst
View sample Statistics Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a re ... And there is a new generation of statistical tools that rely upon statistical simulation such as the bootstrap and Markov Chain Monte Carlo methods. Complementing the traditional ...
Sampling methods are crucial for conducting reliable research. In this article, you will learn about the types, techniques and examples of sampling methods, and how to choose the best one for your study. Scribbr also offers free tools and guides for other aspects of academic writing, such as citation, bibliography, and fallacy.
Country statistical capacity is increasingly recognized as crucial for development, but no academic study exists that reviews the available assessment tools. This paper offers the first review study that fills this gap, paying particular attention to data and practical measurement challenges.