Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 08 September 2022

Explainable artificial intelligence through graph theory by generalized social network analysis-based classifier
- Serkan Ucer 1 ,
- Tansel Ozyer 2 &
- Reda Alhajj 3 , 4 , 5
Scientific Reports volume 12 , Article number: 15210 ( 2022 ) Cite this article
9331 Accesses
6 Citations
11 Altmetric
Metrics details
- Computational biology and bioinformatics
- Mathematics and computing
We propose a new type of supervised visual machine learning classifier, GSNAc, based on graph theory and social network analysis techniques. In a previous study, we employed social network analysis techniques and introduced a novel classification model (called Social Network Analysis-based Classifier—SNAc) which efficiently works with time-series numerical datasets. In this study, we have extended SNAc to work with any type of tabular data by showing its classification efficiency on a broader collection of datasets that may contain numerical and categorical features. This version of GSNAc simply works by transforming traditional tabular data into a network where samples of the tabular dataset are represented as nodes and similarities between the samples are reflected as edges connecting the corresponding nodes. The raw network graph is further simplified and enriched by its edge space to extract a visualizable ‘graph classifier model—GCM’. The concept of the GSNAc classification model relies on the study of node similarities over network graphs. In the prediction step, the GSNAc model maps test nodes into GCM, and evaluates their average similarity to classes by employing vectorial and topological metrics. The novel side of this research lies in transforming multidimensional data into a 2D visualizable domain. This is realized by converting a conventional dataset into a network of ‘samples’ and predicting classes after a careful and detailed network analysis. We exhibit the classification performance of GSNAc as an effective classifier by comparing it with several well-established machine learning classifiers using some popular benchmark datasets. GSNAc has demonstrated superior or comparable performance compared to other classifiers. Additionally, it introduces a visually comprehensible process for the benefit of end-users. As a result, the spin-off contribution of GSNAc lies in the interpretability of the prediction task since the process is human-comprehensible; and it is highly visual.
Similar content being viewed by others

Metrics for network comparison using egonet feature distributions

Datascape: exploring heterogeneous dataspace

Exploiting graphlet decomposition to explain the structure of complex networks: the GHuST framework
Introduction.
Machine learning (ML) has dominated our daily life with many real-world applications, such as healthcare decision support systems, search engine recommendation systems, and autonomous driving, among others. One of the most common tasks of ML is ‘classification’ which broadly involves two steps, training and testing. While training inspires a model from one part of the data, testing uses the remaining data to check the accuracy of the model which reflects its capability in correctly realizing the classes of new samples. The data types processed with ML are not limited to tabular form, but may exist in a wide range of forms, including multimedia. Still, tabular data may be considered the most common form of data types 1 , dominating most of the applications of ML. The main struggle of the current ML paradigm is explainability of existing ML model to naive users. While the performance of the classification accuracy increases as new models emerge, surprisingly, classification decisions become complex to be justified by humans 2 . This ‘explainability’ phenomenon limits the usage of ML models in critical real-world applications (e.g., law or traffic management) since the context of a decision is hard to be justified and explained to the end-users. Our proposed social network analysis-based visual classifier, GSNAc, aims to solve this problematic aspect of ML by introducing visual cues, both at the model and at the prediction steps.
Social networks form a specific type of network graphs used for depicting real-life paradigms in the form of ‘actors’ and their ‘interactions’ with each other in a closed ecosystem 3 . In its most primitive form, a social network consists of a finite number of nodes (called actors) connected to each other via weighted edges (a weight of one for all edges is also possible) which represent a sort of ‘social interaction’ based on some kind of social quality, e.g., ‘frequency of their coffee meetings’. A pervasive form of a social network is ‘the friendship network’, e.g., Facebook.
Social Network Analysis (SNA) is a study conducted to understand various aspects of a network in general as well as its nodes individually and in groups. For example, in a friendship network, it is possible to find the most influential node (i.e., a person) in the analyzed domain. SNA techniques are widely used in various applications from link prediction for recommending useful connections in a ‘friendship network’ to detecting fraud in a ‘financial transactions network’, among others. SNA techniques mainly include, but are not limited to, detecting node or actor centrality, community (structure) detection, edge capacity, flow, and representative selection.
An overview of our past works
For a social network, it is not always necessary for the interaction to be linked to a human activity. Indeed, various types of entities other than humans may also socialize, or the relationship between them may be interpreted as a social activity analogous to human activities. Accordingly, interactions can be defined for a broader spectrum of entities such as among genomes, mice varieties, animals, insects, fruit types, etc. In this respect, increasing interest in the SNA domain has allowed many diverse real-life phenomena to be studied. In our former works 3 , 4 , we tried to address two machine learning tasks using graph theory fundamentals: “feature reduction via SNA” and “the SNAc—classification via SNA of time-genomic datasets”, respectively. For our work described in 5 , we employed SNA techniques and studied specific data from the life sciences domain, which in general do not represent any real ‘social’ value. The techniques themselves proved to be useful in the classification of a tabular dataset. We represented genomic datasets as social network graphs, where genomes are represented as ‘actors’ (nodes) and ‘their vectorial similarity’ to other genomes together with their interaction levels form ‘edges’.
Current model and the key contributions
Following the success of the proof-of-concept of this approach, we now continue searching for an extended generalized framework that is again based on graph theory and SNA. The target involves addressing the classification of tabular datasets containing either or both numerical and categorical features. Thus, the proposed GSNAc Model is a new type of visually explainable machine learning classifier that works on tabular datasets.
Our approach (see Fig. 1 ) moderately increases the explainability of the whole classification process, since it presents a traceable visual output for each predicted sample. Besides, the ‘graph classifier model—GCM’, which sits at the heart of the classification process, is again in a social network form that makes it visualizable. Those aspects merely address the current problem posed by the most advanced current set of state-of-the-art classifiers, which is the explainability of the classification task (i.e., XAI—explainability of artificial intelligence applications). To summarize, the key aspects and contributions of the GSNAc model could be enumerated as follows:
Clarity of the method, explainable process, deterministic classifier,
Graphical interface, explainability, visual engagement,
Versatility (i.e., works well for the classification of both numerical and categorical features),
Superior or on par performance (in terms of prediction accuracy) with the well-known state-of-the-art tabular data classifiers.

The brief pipeline of the GSNAc model.
Structure of the research presented
We will present our current work by introducing the problem and the techniques that will be used to address the problem posed in “ Related work and key concepts ” section. We will then discuss details of the GSNAc Model starting with an overview in “ GSNAc: a visual supervised learner ” section. We will further detail the model in “ The data: converting tabular data to raw network graph ”, “ The model: graph enrichment and extraction of the graph classifier model ”, “ The prediction process: using visual graph classifier model (GCM) ” sections. Experiments and results of the comparison with conventional machine learning classifiers will be present in “ Experiments and results ” section. We dedicated “ Explainability of the GSNAc model ” section to elaborate on the explainability aspect of the proposed GSNAc Model. Discussion and further study are covered in “ Discussion and further work ” section.
In Appendix I , we provide the code, the detailed parameters of the classifiers & the datasets, and the runtime parameters of the GSNAc Model, including the raw performance results, and the URL to the directory of outputs GSNAc produced throughout the experiments, all for the sake of the reproducibility of the conducted research. Finally, in Appendix II , we provide the user interface and the output of GSNAc.
Related work and key concepts
Graphs, social networks, and sna.
Social networks 6 form a subtype of network graphs that originated from graph theory. Graph theory is briefly the study of network graphs, which are mathematical representations used to model pairwise relations between objects. A graph is normally characterized by a set of nodes and edges which connect nodes. Typically, edges may have a default weight of 1; alternatively, varying weights may be assigned to various edges to reflect the value of the relationship between the connected nodes. Indeed, many real-world problems and systems can be reduced and represented as a network graph. For instance, the traffic system connecting roads in an area may be reorganized as a graph where intersections and roundabouts act as nodes and edges represent roads connecting them. This way, a navigation map application may identify a possible shortest path between two locations by analyzing the graph to determine the most appropriate route based on the combination of the costs of road segments connecting some consecutive junctions.
A network graph is simply the combination of nodes and edges connecting nodes. Each edge has a source node, a target node, and a weight value showing its effect based on the criteria applied to construct the network. Assume an edge e1 between nodes a and b has weight 4, and another edge e2 between a and c has weight 3, then we conclude that a is more similar to b than c. In some cases, edges of a network graph can be directed, i.e., the direction of connection between the source node and the target node matters, e.g., in a directed graph, two edges e1 from a to b and e3 from b to a are two different edges. If the direction doesn’t matter in the domain of study, it is safer to use undirected networks.
Having originated from the social sciences domain, Social Network Analysis (SNA) is the sum of measures inspired from graph theory to analyze the relationship among social entities. Social Network analysis encompasses many measures that can be broadly grouped as:
Centrality studies for nodes
Edge analysis
Node distance-similarity methods
Community structure studies
SNA measures used in this study are node similarity analysis, edge analysis and centrality studies.
Machine learning: the classification task
It is very common to come across the results of scientific experiments involving measurements of various aspects (in other words, features) of objects in a specific domain, and at the end objects are often categorized into a limited number of cases (called classes).
In the machine learning domain, the term ‘classification’ implies the task of first learning the characteristics of a group of objects from specific classes and then predicting the correct class for some previously unseen objects forming the test data.
Any learner model follows almost the same black-box model shown in Fig. 2 . According to this generalization, it starts with the ‘Data’ box, where the dataset under study is examined in terms of quality, completeness, and complementarity of its feature space and sample data points. Tasks such as decomposition, transformation, elimination, and improvement of the feature space are some of the common methods used in this step.

Illustrative box diagram of a general machine learning classification model.
The aim of the ‘classifier model’ box is to find and describe the connection between the data and its class, by employing mathematical and statistical techniques. Finally, in the ‘Prediction’ box, the proposed model implements its technique to process data with the model presented to produce appropriate predictions. Crucially, in this step ‘benchmarking’ ensures that we assess the merit of the classifier. Here, internal and external benchmarking can be employed, i.e., ‘statistical hypothesis testing techniques’ as the internal evaluation, and comparing the performance of the proposed classifier with the state-of-the-art established models as the external evaluation.
There is no silver bullet technique for classification tasks 7 . For instance, some classification techniques may perform efficiently on biological data while may fail to produce meaningful predictions on financial data. State-of-the-art techniques for tabular data classification consider decision tree-based classifiers. Among those, notably XGBoost 8 depends on tree learning, and dominates most of the recent 9 data science competitions. Another recent and popular research is deep learning, where its main contribution is on feature space reorganization and selection. Despite the fact that deep learning could be used for classification, their effective usage is still mainly on text, image, and video data types 10 .
Machine learning and network graphs
Even though SNA techniques are widely used to solve various problems from engineering to media; machine learning classification using network graphs is a domain that has not received enough attention from the research community. In our former work described in 5 , we employed various SNA techniques to convert time-sequential genomic data into a social network and developed a classification model to predict classes. The method proved to be useful when compared to conventional algorithms, but was limited to being applied only on time-sequential data. Within this work, we aim to generalize our classification model (abbreviated as GSNAc) to an extent that the method can be applicable to numerical/categorical datasets which include class information.
The machine learning applications for the social network domain are generally centered around two topics 11 : (i) the similarity between two graphs (or subgraph matching), and (ii) the similarity of the nodes/edges in a graph. The first one aims to find a motif between possibly two different-sized graphs (in terms of nodes and edges) to deduct a result, e.g., a deduction that both graphs have similar network dynamics. Here, a recent work in this area is worth mentioning 12 . It employed graph theory techniques for text classification. In 12 , NLP researchers first convert sentences into adjacency matrices based on the co-occurrence of words, and then to graphs. The process then efficiently predicts word similarities by employing graph similarity techniques. At this point, we state that the proposed GSNAc model has no relation with this ‘inter-graph similarity’ aspect of the mentioned research domain.
On the other hand, finding possible similarities ‘within’ a graph, in terms of the similarity between nodes or edges, is a problem partially addressed by GSNAc. The ‘node classification’ problem refers to the process of propagating labels to the unlabelled nodes on a partially labeled graph by evaluating the similarity of nodes 13 , 14 . A recent research in this area (refer to 15 ) handles node classification problems by introducing graph neural networks over graphs (particularly Graph Convolutional Networks—GCNs). This approach basically learns hidden layer representations that encode both the local graph structure and features of nodes. It has been proved useful in predicting labels on some types of networks including citation networks where it predicts the type of the document. Within this context, the node classification problem partially matches the definition of the problem tackled by GSNAc; since (after converting data to a graph and after its enrichment) we also predict the class (i.e., label) of an unseen node by evaluation against labels of the training nodes. However, in comparison to the node classification problem setting, there are major challenges that GSNAc needs to deal with. First, in the node classification problem, the complete (weighted) graph (including all nodes—i.e., training and test parts) is already in place initially, making it easier to assign labels based on their topological properties based on the complete connection structure within all nodes (labeled or unlabelled). Second, node classification can predict labels iteratively by depending on known positions, possibly starting with a frequently labeled portion of the graph. We believe that these dynamics differentiate the two problems well enough. Here it is worth mentioning that the GSNAc model is actually an end-to-end machine learning classifier on its own.
To sum up, we would like to present a recent trend on converting tabular data into networks. This approach becomes pretty useful when the aim is to visualize data to get an intuition-based idea. A recent research described in 16 efficiently converts tabular data into images (rather than networks as GSNAc does), and predicts drug responses of gene expression profiles using deep learning techniques on the generated images. While this approach does not coincide with GSNAc, it shows the popularization of expressing tabular data as 2D visible graphic items, a reasonable step towards explainability of tabular learning.
GSNAc: a visual supervised learner
In this section, following the formal problem description, we will present an overview of the GSNAc model both in diagram and pseudocode formats. A detailed description of the methodology and parameter selection strategies will be covered in the following three subsections.
Problem description and naming conventions
The formal problem description of GSNAc is exactly the same as the problem definition of machine learning for the categorical classification task: given a multi-class tabular dataset with numerical and categorical features, the process involves learning from the seen data and predicting the class of unseen data. Multi-class classification refers to predicting one or more classes for each sample. Imbalanced classification refers to a classification task where the distribution of samples across the classes is skewed. In other words, most of the existing objects represent specific classes. Fortunately, GSNAc is not merely a bi-class classifier. It does not aims to work only on balanced data, it also works on imbalanced data which makes it useful on a broader spectrum of problems. A final note on the use of GSNAc is that it currently does not support regression prediction which is predicting continuous numerical values.
Before we delve into detailed descriptions of the GSNAc methodology, we would like to present (see Fig. 3 ) the ‘naming’ convention for this research. Throughout this work, for the dataset part, our preference is to call individual observations (of an experiment) as the ‘samples’, and their defining characteristics (i.e., predictors) are called ‘features’ of the samples. Categories of the results of the experiment are called ‘classes’.

(i) Tabular data converted to adjacency (similarity) matrix (ii), and graph (iii) constructed and enriched with node degrees, edge weights, and colored by communities (classes). Layout graph intuitively shows the importance of some nodes (i.e., H. Sapiens and T-Rex have the highest number of weighted connections, therefore, larger in size) and visually depicts how similar nodes are (e.g., Shark has the smallest similarity to other nodes so it is distant from the core).
After converting the dataset to a network graph, basically dataset ‘samples’ become ‘nodes’ in the graph, and dataset ‘features’ are blended into ‘edges’ of the graph. A node may have a ‘neighbor’ if there is an edge between them. Finally, the classes are represented in the network graph as the ‘communities’.
The pipeline of the GSNAc methodology is diagrammatically described in Fig. 4 . It starts with the preprocessing of raw tabular data. After data is separated into training and test parts, a raw graph is generated using only the training part of the data. This raw graph is decorated and further processed to achieve a leaner version called graph classifier model (GCM) with fewer edges and repositioned nodes.

General overview of the GSNAc model illustrated on Iris dataset.
This GCM was then employed for predicting the class of test samples using two different similarity scores. Next, we present the master pseudocode summarizing the GSNAc methodology.

In Fig. 1 we described the GSNAc Models’ process pipeline: this type of framing comes useful when proposing a novel model. In this sense, we organized the following three sections focused on the boxes of the model, namely ‘Data: Graph generation’, ‘Model: GCM Generation’ and ‘Class Prediction’.
The data: converting tabular data to raw network graph
In this subsection, we present details on how we process the dataset, turn it into a network graph and finally how we produce, and process features that belong to the graph. Topics to be covered are:
splitting the data,
preprocessing,
feature importance and selection,
computation of similarity between samples, and
generating of the raw graph.
Splitting the tabular data
After preprocessing the data, the next step is to split the dataset into training and test samples for validation purposes. We selected cross-validation (CV) as the validation method since it is the de facto standard in ML research. For CV, the full dataset is split into k folds; and the classifier model is trained using data from (k-1) folds then tested on the remaining k’th fold. Eventually, after k iterations,, average performance scores (like F1 measure or ROC) of all folds are used to benchmark the classifier model.
A crucial step of CV is selecting the right proportion between the training and test subsamples, i.e., number of folds. Determining the most appropriate number of folds k for a given dataset is still an open research question 17 , besides de facto standard for selecting k is accumulated around k = 2, k = 5, or k = 10. To address the selection of the right fold size, we have identified two priorities:
Priority 1—Class Balance: We need to consider every split of the dataset needs to be class-balanced. Since the number of class types has a restrictive effect on selecting enough similar samples, detecting the effective number of folds depends heavily on this parameter. As a result, whenever we deal with a problem which has low represented class(es), we selected k = 2.
Priority 2—High Representation: In our model, briefly, we build a network from the training subsamples. Efficient network analysis depends on the size (i.e., number of nodes) of the network. Thus, maximize training subsamples with enough representatives from each class (diversity) is our priority as much as we can when splitting the dataset. This way we can have more nodes. In brief, whenever we do not cross priority 1, we selected k = 5.
By balancing these two priorities, we select efficient CV fold size by evaluating the characteristics of each datasets in terms of their sample size and the number of different classes. The selected fold value for each dataset will be specified in the “ Experiments and results ” section. To fulfill the class balancing priority, we employed stratified sampling. In this model, each CV fold contains approximately the same percentage of samples of each target class as the complete set.
Feature space organization and preprocessing
Preprocessing starts with the handling of missing data. For this part, we preferred to omit all samples which have one or more missing feature(s). By doing this, we have focused merely on developing the model, skipping trivial concerns.
As stated earlier, GSNAc can work on datasets that may have both numerical and categorical values. To ensure proper processing of those data types, as a first step, we separate numerical and categorical features 18 . First, in order to process them mathematically, categorical (string) features are transformed into unique integers for each unique category by a technique called labelization. It is worth noting that, against the general approach, we do not use the one-hot-encoding technique for transforming categorical features, which is the method of creating dummy binary-valued features. Labelization does not generate extra features, whereas one-hot-encoding extend the number of features.
For the numerical part, as a very important stage of preprocessing, scaling 19 of the features follows. Scaling is beneficial since the features may have a very different range and this might affect scale-dependent processes like distance computation. We have two generally accepted scaling techniques which are normalization and standardization. Normalization transforms features linearly into a closed range like [0, 1], which does not affect the variation of values among features. On the other hand, standardization transforms the feature space into a distribution of values that are centered around the mean with a unit standard deviation. This way, the mean of the attribute becomes zero and the resultant distribution has a unit standard deviation. Since GSNAc is heavily dependent on vectorial distances, we do not prefer to lose the structure of the variation within features and this way our choice for scaling the features becomes normalization. Here, it is worth mentioning that all the preprocessing is applied on the training part of the data and transformed on the test data, ensuring no data leakage occurs.
Feature importance and selection
Feature Importance (FI) broadly refers to the scoring of features based on their usefulness in prediction. It is obvious that in any problem some features might be more definitive in terms of their predictive capability of the class. Moreover, a combination of some features may have a higher effect than others in total than the sum of their capacity in this sense. FI models, in general, address this type of concern. Indeed, almost all ML classification algorithms use a FI algorithm under the hood; since this is required for the proper weighting of features before feeding data into the model. It is part of any ML classifier and GSNAc. As a scale-sensitive model, vectorial similarity needs to benefit much from more distinctive features.
For computing feature importance, we preferred to use an off-the-shelf algorithm, which is a supervised ‘k-best feature selection’ 18 method. The K-best feature selection algorithm simply ranks all features by evaluating features’ ANOVA analysis against class labels. ANOVA F-value analyzes the variance between each feature and its respective class and computes F-value which is the ratio of the variation between sample means, over the variation within the samples. This way, it assigns F values as features’ importance. Our general strategy is to keep all features for all the datasets, with an exception for genomic datasets, that contain thousands of features, we practiced omitting. For this reason, instead of selecting some features, we prefer to keep all and use the importance learned at this step as the weight vector in similarity calculation.
Computation of similarity between samples and construction of the raw graph
In this step, we generate an undirected network graph G, its nodes will be the samples and its edges will be constructed using the distance metrics 20 between feature values of the samples. Distances will be converted to similarity scores to generate an adjacency matrix from the raw graph. As a crucial note, we state that since we aim to predict test samples by using G, in each batch, we only process the training samples.
In our study for constructing a graph from a dataset we defined edge weights as the inverse of the Euclidean distance between the sample vectors. Simply, Euclidean distance (also known as L2-norm) gives the unitless straight line (shortest) distance between two vectors in space. In formal terms, for f-dimensional vectors u and v , Euclidean distance is defined as:
A slightly modified use of the Euclidean distance is introducing the weights for dimensions. Recall from the discussion of the feature importance in the former sections, some features may carry more information than others. So, we addressed this factor by computing ‘a weighted’ form of L2 norm based on distance which is presented as:
where w is the n-dimensional feature importance vector and i iterates over numerical dimensions.
The use of the Euclidean distance is not proper for the categorical variables, i.e. it is ambiguous and not easy to find how much a canary’s habitat ‘sky’ is distant from a sharks’ habitat ‘sea’. Accordingly, whenever the data contains categorical features, we have changed the distance metric accordingly to L0 norm. L0 norm is 0 if categories are the same; it is 1 whenever the categories are different, i.e., between the ‘sky’ and the ‘sea’ L0 norm is 1, which is the maximum value. Following the discussion of weights for features, the L0 norm is also computed in a weighted form as \({dist\_L0}_{w}\left(u,v\right)=\sum_{f}{w}_{j}(({u}_{j}\ne {v}_{j})\to 1)\) , where j iterates over categorical dimensions.
After computing the weighted pairwise distance between all the training samples, we combine numerical and categorical parts as: \({{dist}_{w}\left(u,v\right)}^{2}={{dist\_L2}_{w}\left(u,v\right)}^{2}+ {{dist\_L0}_{w}\left(u,v\right)}^{2}\) . With pairwise distances for each pair of samples, we get a n x n square and symmetric distance matrix D, where n is the number of training samples. In matrix D, each element shows the distance between corresponding vectors.
We aim to get a weighted network, where edge weights represent the ‘closeness’ of its connected nodes. We need to first convert distance scores to similarity scores. We simply convert distances to similarities by subtracting the maximum distance on distances’ series from each element.
Finally, after removing self-loops (i.e. setting diagonal elements of A to zero), we use adjacency matrix A to generate an undirected network graph G. In this step, we delete the lower triangular part (which is symmetric to the upper triangular part) to avoid redundancy. Note that, in transition from the adjacency matrix to a graph, the existence of a (positive) similarity score between two samples u and v creates an edge between them, and of course, the similarity score will serve as the ‘vectorial weight’ of this particular edge in graph G.
The raw graph generated in this step is a ‘complete graph’: that is, all nodes are connected to all other nodes via an edge having some weight. Complete graphs are very complex and sometimes impossible to analyze. For instance, it is impossible to produce some SNA metrics such as betweenness centrality in this kind of a graph.
The model: graph enrichment and extraction of the graph classifier model
In this section, we first compute basic SNA metrics over the network graph, then decorate the raw graph with certain properties of the tabular data, and finally process edge analysis of the raw graph. To reduce the complexity and denseness of the graph, we will trim unimportant edges by considering their structure to get a subtle form of the graph which will serve as our visual classifier model.
To increase the understandability of the procedures presented, we visualized the whole process in Fig. 5 , which belongs to a biological dataset. This dataset inspired from C. Elegans Connectome ( https://commons.wikimedia.org/wiki/File:Caenorhabditis_elegans_hermaphrodite_adult-en.svg ) incorporates 279 samples over 12 features (2 categorical, 10 numerical). It has 10 (imbalanced) classes. C. Elegans is indeed a simple worm, and its whole neuron system has been extracted, filed, and widely researched in recent years 21 , 22 , 23 . This worm has exactly 302 neurons (having unique names and positions) connected to 158 muscles and organs on its body. Out of those 302 neurons, following the Connectome research 24 , non-pharynx neurons and neurons with no synaptic connections are omitted, leaving 279 somatic neurons out of the initial 302. This dataset is useful in showing the capabilities of the proposed model. We choose the ‘AY Ganglion’ feature as the class to be predicted. In this specific case, we intend to find a predictive relationship between the neurons and their connections to specific regions throughout the worm’s body.

From raw data to GCM demonstrated on C. elegans Dataset.
Graph decoration and preprocessing
Node naming.
In general, the dataset associated with classification has dedicated sample names, e.g., names of the specific neurons in Connectome dataset or CustomerID’s in Caravan Insurance dataset 25 . Usually, this potentially beneficial information is ignored during the classification. In contrast to this, for the sake of explainability, we save and assign sample names throughout our raw graph as node names.
Community partition assignment
Community detection in a network graph refers to finding partitions of the graphs (subgraphs of connected nodes) displaying similar characteristics. It is beneficial since it reveals hidden relations among nodes in a network. Inevitably, we need to incorporate community detection within the raw graph. While many algorithms have been developed to detect communities, e.g., 26 , 27 , 28 , we do skip employing them intentionally since our network is already partitioned based on the given set of classes. That is, since the raw graph is only composed of training samples, we already do know the classes they have and the communities they belong to. In this fashion, we assign classes as communities in the raw graph.
Centrality SNA metrics
Within a graph, finding how central a node is (compared to other nodes topologically) in terms of the capacity of its entropy is an important branch of SNA metrics as mentioned in “ Related work and key concepts ” section. Among other centrality metrics 3 , the most primitive is ‘degree centrality’ which refers to the number of edges connected to a given node. ‘Weighted degree’ is the improved form of degree centrality, which also considers edge weights when aggregating node connections. Despite not using centrality metrics in the GSNAc model in a predictive capacity, we still find them useful in the model to enrich the displays produced. For this purpose, we use ‘weighted degree centrality’ for scaling the size of the nodes. The latter is a visually engaging concept and gives comparative clues about the entropy capacity of a node within a graph.
Edge pruning
We already highlighted the need for removing self-loops in the former section to simplify the complexity of the raw graph. But, still, this graph is a complete graph, i.e., every node is connected to every other node leading to a graph density of 100%. Now we need to identify and further remove unimportant edges of this complete graph to ensure that our model includes only relevant and important edges; this way, its entropy increases.
Some research 29 , 30 already addressed the raffination of the so-called ‘hairball graph’ which is overly dominated by unimportant edges. We prefer to use a custom raffination at this step, keeping only at most k strongest edges for each node and dropping the remaining edges. This way, by keeping the k value small, we can achieve a raffinated, less dense version of the raw graph. Also, by only keeping the most information-bearing edges, entropy of the graph will increase.
Instead of setting a constant k value for each dataset, we have set an upper limit, and dynamically identified the value of k by analyzing the frequency of the least represented class within the population.
Edge fortification
So far, we have only described how the ‘class’ information of tabular data is only used in graph community assignments. GSNAc might incorporate class information in the model generation step, since it is a supervised model. We prefer to use this very important class information as a secondary step in a reward/loss scheme for edges. This time, we reconsider weights of the edges by analyzing classes of their endpoints. The weight of an edge is improved by a constant factor when it connects two nodes from the same class. Likewise, the same factor is used to decrease the weight of an edge when its endpoints are from different classes. After these steps, the graph may become disconnected since some nodes can lose all of their edges and become isolated, or some group of nodes can be only connected to themselves, creating an isolated connected component.
The prediction process: using visual graph classifier model (GCM)
As described in the previous sections, we have carefully constructed a vectorial similarity-based network graph, pruned its edges by their importance, and finally generated a leaner graph which will act as our classifier model named GCM. At this point, we will feed test nodes one-by-one into GCM and conduct the prediction by analyzing most similar nodes. For this similarity analysis, we have employed two complementary methods: vectorial and topological.
Adding test node to GCM
Vectorial similarities of test node to gcm nodes.
Vectorial similarity is the weighted (L2 and/or L0) distance-based similarity score already computed during the network generation phase. To calculate this vectorial similarity score for each test data to be predicted, upon normalization of test nodes vector, L2 norm-based distance for the numerical part, and L0 norm-based distance for categorical part of the test data are calculated using the same weights that were learned from the training data at step FI. These distance scores are calculated pairwise between the test node and all nodes of GCM. Following the conversion from distances to similarity scores, the test node becomes connected to all nodes of GCM via different edge weights.
Topological similarities of test node to GCM nodes
As we already have a topological structure in the form of a graph, we can also analyze the neighborhood structure of nodes. A topological similarity, in its simple form, can be calculated by comparing the neighborhood structure of two nodes: if they have the same neighborhood with similar weights, they can be considered topologically similar. Pairwise cosine similarity 31 has been used to compute the topological similarity between the test node and nodes of GCM; this measure is useful when one needs to compare two bags of words (with frequencies). Indeed, it is widely used in natural language processing for comparing text similarity.
Our usage of cosine similarity is to define a bag of words as neighborhood lists of nodes and frequencies as the weights of edges (i.e., vectorial similarity) connecting them. As can be seen in the formula, it is again a pairwise calculation as the vector product of the test node (test) and a node from GCM (v) divided by the product of L2 norms of the same vectors. Note that, the value k in the formula refers to the number of neighbors of v; it is expected to be smaller than the number of neighbors of the test node which is already connected to all nodes of GCM.
To conclude, in topological similarity, we do not only consider the direct neighbors of a node from GCM. We also compare two nodes’ neighborhood structure, i.e., how their indirect neighbors match.
Prediction strategy: assigning class to the test node
Topological similarity is somewhat dependent on vectorial similarity since the former uses edge weights (i.e., vectorial similarity) as input. However, topological similarity does not produce the same graph as vectorial similarity, and GCM built by topological similarity gives some clue about nodes’ position within the graph. In this respect, it can be used as a secondary similarity metric, complementing vectorial similarity. We have decided to blend these two similarity metrics to achieve a higher prediction performance and it turned out that using topological similarities as secondary ‘sage’ (whenever decision margin is small with vectorial similarity) has been proven beneficial for prediction as described next.
For actual prediction, we primarily use vectorial similarity and keep the maximum number of edges for a given test node from each represented class in GCM based on their weights. Our prediction is then to group and aggregate those edges class-wise to get an average similarity of the test node to each class, respectively (see Fig. 6 a). To assign a class to a test node, we only consider the top two high-ranked classes and compare their aggregated similarity scores.

( a ) Prediction Phase 1 sample diagram on C. Elegans dataset. İllustrating the prediction attempt of the test node ADFL (not displayed in the diagram). Raw list of neighbors of ADFL listed, sorted by vectorial similarity, grouped by class, and finally similarities are aggregated by class. A prediction is not made since the top two highest averaged classes have very close scores (under margin). ( b ) Prediction Phase 2 sample diagram on C. Elegans dataset. Illustrating the prediction of the test node ADFL (not displayed in the diagram). This time, the prediction is made based on topological similarity in the same fashion with the first round. This time, without seeking a distinctive margin, the top (highest topological similarity average) class is assigned as the prediction.
When the top most classes differ by a magnitude, we assign the top-ranked class to the test node. However, in case the vectorial similarity-based model fails to find two distinctively separated classes (i.e., setting a margin threshold of 1% means the difference of the scores of the top two classes must be higher than 1%) we leave the prediction completely to the secondary sage, i.e., the topological similarity (see Fig. 6 b). This time, in the same fashion, we aggregate the average similarities of the classes over topological similarities, and (without further check) we assign the top-ranked class to the test node.
Experiments and results
The datasets.
GSNAc was initially designed to work efficiently with balanced and bi-class datasets (i.e., binary classification). However, during the development, we discovered that it can effectively classifies some multiclass and imbalanced datasets, as well. As a proof of concept for GSNAc, we carefully selected as many real-world diverse datasets from various domains with various feature and class structures. We also considered including synthetic datasets as they give the chance to compare similar work by other researchers. Finally, we considered some other custom datasets compiled for this research. Table 1 summarizes the datasets used in the experiments.
In the preprocessing steps, we standardized the datasets before feeding them to the ML classifiers since some classifiers (especially those based on scale sensitive distance metrics like SVM and kNN) heavily depend on the data to be scaled. To select the standardization over other competing techniques, normalization is also needed especially for SVM RBF classifier (GSNAc’s main competitors are reported in Table 3 ) since they assume that all the features are centered around zero and variance of the data is of the same order 32 .
Experimental setup
We implemented the GSNAc Model using Python. We selected the platform of GSNAc to be compatible with python’s sklearn library 33 since it is the de facto standard platform in the ML domain. Also, it allows parameter optimization by grid or random search methods, making it useful to find the best performer set of parameters for a given task. Within this context, we did not practice parameter search or optimization for this research in order to present a fair comparison with other ML classifiers. We also used other python libraries such as networkx, bokeh, pandas, and NumPy.
Classifiers used for benchmarking
To be comprehensive and fair in the testing, we decided to include as diverse ML models as possible in terms of their approach for the classification. All the classifiers run with their default parameter set (except for ANN where the maximum number of iterations was upgraded from 200 to 2000 since it does not usually converge with 200 iterations), and likewise, we used default parameters for GSNAc, i.e., we did not search for the best parameters. We used scikit-learn 33 implementation of the utilized classifiers except xgboost, where we used the native xgboost python library 8 . We present in Table 2 the list of classifiers and their parameters used for the comparison.
Performance comparison of GSNAc with traditional tabular learners
In order to test classification efficiency of the GSNAc on the given datasets, we have investigated the comparison of SNAc with traditional machine learning classification algorithms. We selected ten traditional machine learning classification methods to compare their performance with the GSNAc Model over the twenty datasets listed in Table 1 .
Machine learning classification algorithms usually fall into 3 categories, namely statistical, function-based and tree-based (hierarchical) models. We selected at least one algorithm from each category in order to present a balanced comparison.
The reported results, as summarized in Table 3 , show that GSNAc beats or on par with other classifiers on 10 of the datasets. Most notable success of these is on the PBC dataset 34 , where the problem is to predict one of 4 heavily imbalanced classes. On the remaining 10 other datasets, where GSNAc doesn’t score at top, we have noted comparable performance with other classifiers.
Detailed performance results of GSNAc in comparison with other classifiers are presented in Appendix I .
Explainability of the GSNAc model
Considering the rise of deep learners, ML models are increasingly getting complex in terms of their prediction model generation. The so-called black-box classifier models are not comprehendible for end-users on how the actual prediction is decided. For instance, a person may be interested in learning the reason for declining his/her loan application which was evaluated by an AI system.
Explainable AI (XAI) is a recent trend in machine learning research 2 , 35 which aims to identify how predictions are made in an explainable manner (see Fig. 7 ). Explainability and/ or interpretability is essential for end-users to effectively trust, and manage artificial intelligence applications 36 .

Explainable AI approach versus todays’ classifier models in a nutshell.
There are various (recent) research efforts conducted to address the explainability of the already existing machine learning classifier models. In 37 , researchers efficiently extended the use of a convolutional neural network classifier by developing an explainability module. With this extra module, they displayed comprehensionable prediction results of microseismic wave-form signal data while keeping excellent classification performance. Similarly, in 38 , researchers put significant effort to translate deep neural networks-based prediction results over traffic analysis data into visually comprehensible map data; thus providing an explainable (learned) trajectory segmentation to the end user of the deep learner model. Though relevant, we argue that these efforts do not actually coincide with the work developed in this research since GSNAc’s procedures and predictions are already designed with explainability in mind, and hence need no further translation procedure for explainability purposes.
SNA concentrates on generating, and visualizing interactions and information flows among network actors. The power of social networks is stemming mostly due to their capacity in revealing and visualizing interactions in a connected structure. It is no doubt that one can comprehend data more efficiently in a visual way, and network graphs allow us to better understand how nodes are similar to each other, which nodes bear most information, and most importantly, how information flows within a network. By converting and visualizing tabular data, we can reveal and learn several aspects, such as: which samples can distribute information to the largest audience, who is connected to the most influential nodes, and who creates fragility to graph, i.e., the single point of failure by being a single connector between two separate communities. As powered up by the idea of network graphs, GSNAc surely presents some advantages of social networks to its users as briefly summarized in the following three stages:
The first advantage is the visual classifier model (i.e., GCM) which makes sense of the data by keeping sample names as node names and keeping class information as a colored community. This is illustrated in Figs. 3 , 4 , and 5 .
The second advantage towards explainability lies in the actual visual prediction step (see Fig. 8 ): end-users can receive visual clues on how the test node is assigned into one class but not others by analyzing the structure of GCM nodes and weights of the edges.
The final advantage is based on the comparison of prediction results of GSNAc across different classifiers (see Fig. 9 ). GSNAc produces a set of graphs and displays the comparison on the overall prediction process. This way, an end-user can perceive how classifiers (in contrast to GSNAc) predicted a certain sample, whether true or false.

Sample visualization of the prediction step. Test node ADAR from the C. elegans dataset has been classified as CL-E (orange).

Overall classification result on C. Elegans dataset. Blue color implies that the specific sample has been predicted true by the respective classifier (such as AdaBoost); red color indicates false prediction. Boxes in black indicate cases where the same sample has been predicted true (as in blue colors) by XGBoost and AdaBoost classifiers, but false (as in red colors) by GSNAc, and boxes in orange indicate opposite cases (i.e., false by XGBoost and AdaBoost while true by GSNAc).
Discussion and further work
We have proposed GSNAc as a novel graph-based machine learning classifier which works on both numerical and categorical tabular datasets. It outperforms the previous version named SNAc both in performance and capability of handling a wide range of datasets. The main contribution of GSNAc is its capability of visualizing the decision-making process behind the model, while maintaining a fine prediction performance when compared to other classifiers.
GSNAc uses easy-to-grasp similarity-based metrics in graph generation and prediction steps; so might be a choice of some group of end-users who would like to diagrammatically perceive the whole classification process. Since GSNAc also provides prediction margins to end-user, one of its other advantages might be seen as determining and transferring low-margined classification decisions to a human expert for further investigation.
We demonstrated that GSNAc outperforms or is on par with state-of-the-art classifiers across different domains in terms of prediction performance. However, the main drawback of GSNAc is the duration of its run, since its core data structure is a ‘graph’ which has a processing complexity of O(n 2 ). Except for scalability, we are not aware of any shortcomings of this Model.
Lastly, we believe in the future this work can be effectively extended into node classification problems.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Abbreviations
Explainable artificial intelligence
Generalized social network analysis-based classifier
Graph classifier model
Social network
Social network analysis
Social network analysis-based classifier
Machine learning
Natural language processing
Chui, M. C. M. et al. Notes from the AI Frontier: Insights from Hundreds of Use Cases (McKinsey Global Institute, 2018).
Google Scholar
Adadi, A. & Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 6 , 52138–52160 (2018).
Article Google Scholar
Alhajj, R. & Rokne, J. (eds) Encyclopedia of Social Network Analysis and Mining (Springer New York, 2018).
Özyer, T., Ucer, S. & Iyidogan, T. Employing social network analysis for disease biomarker detection. Int. J. Data Min. Bioinforma. 12 (3), 343 (2015).
Üçer, S., Koçak, Y., Ozyer, T. & Alhajj, R. Social network Analysis-based classifier (SNAc): A case study on time course gene expression data. Comput. Methods Programs Biomed. 150 , 73–84 (2017).
Tabassum, S., Pereira, F. S. F., Fernandes, S. & Gama, J. Social network analysis: An overview. WIREs Data Min. Knowl. Discov. 8 (5), e1256 (2018).
Bishop, C. M. Pattern Recognition and Machine Learning (Springer, Preface p.viii, 2006).
MATH Google Scholar
Chen, T. & Guestrin, C. XGBoost: a scalable tree boosting system. In Proc. 22nd ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. , 785–794 (2016).
Bansal, S. Data Science Trends on Kaggle !! (Kaggle, 2022).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521 (7553), 436–444 (2015).
Article ADS CAS Google Scholar
Kumar, R., Novak, J. & Tomkins, A. Structure and evolution of online social networks. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining—KDD ’06, Philadelphia, PA, USA, 611 (2006) (Accessed 26 Feb 2022).
Shanavas, N., Wang, H., Lin, Z. & Hawe, G. Knowledge-driven graph similarity for text classification. Int. J. Mach. Learn. Cybern. 12 (4), 1067–1081 (2021).
Zhu, X., Ghahramani, Z. & Lafferty, J. Semi-supervised learning using Gaussian fields and harmonic functions. In Proceedings of the Twentieth International Conference on International Conference on Machine Learning , 912–919, Washington, DC, USA (2003).
Belkin, M., Niyogi, P. & Sindhwani, V. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples. J. Mach. Learn. Res. 7 , 2399–2434 (2006).
MathSciNet MATH Google Scholar
Kipf, T. N. & Welling, M. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR) (2017).
Zhu, Y. et al. Converting tabular data into images for deep learning with convolutional neural networks. Sci. Rep. 11 (1), 11325 (2021).
Kuhn, M. & Johnson, K. Applied Predictive Modeling , 1st ed. 2013, Corr. 2nd printing 2018 edition. (Springer, 2013).
Kuhn, M. & Johnson, K. Feature Engineering and Selection: A Practical Approach for Predictive Models (CRC Press, Taylor & Francis Group, 2020).
Bhandari, A. Feature scaling|standardization vs normalization. Analytics Vidhya, (2020).
Deza, M. M. & Deza, E. Encyclopedia of Distances (Springer, 2016).
Book Google Scholar
Cook, S. J. et al. Whole-animal connectomes of both Caenorhabditis elegans sexes. Nature 571 (7763), 63–71 (2019).
Emmons, S. W. The beginning of connectomics: A commentary on White et al. (1986) ‘The structure of the nervous system of the nematode Caenorhabditis elegans ’. Philos. Trans. R. Soc. B Biol. Sci. 370 (1666), 20140309 (2015).
Badhwar, R. & Bagler, G. Control of neuronal network in Caenorhabditis elegans . PLoS ONE 10 (9), e0139204 (2015).
Varshney, L. R., Chen, B. L., Paniagua, E., Hall, D. H. & Chklovskii, D. B. Structural properties of the Caenorhabditis elegans neuronal network. PLoS Comput. Biol. 7 (2), e1001066 (2011).
The Insurance Company Benchmark (COIL 2000). http://kdd.ics.uci.edu/databases/tic/tic.data.html (Accessed 30 Dec 2021).
Alamsyah, A. et al. Community detection methods in social network analysis. Adv. Sci. Lett. 20 (1), 250–253 (2014).
Blondel, V. D., Guillaume, J.-L., Lambiotte, R. & Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008 (10), P10008 (2008).
Clauset, A., Newman, M. E. J. & Moore, C. Finding community structure in very large networks. Phys. Rev. E 70 (6), 066111 (2004).
Article ADS Google Scholar
Dianati, N. Unwinding the hairball graph: Pruning algorithms for weighted complex networks. Phys. Rev. E. 93 (1), 012304 (2016).
Article ADS MathSciNet Google Scholar
Edge, D., Larson, J., Mobius, M. & White, C. Trimming the hairball: Edge cutting strategies for making dense graphs usable. In 2018 IEEE International Conference on Big Data (Big Data) , (2018).
Han, J., Kamber, M. & Pei, J. Data Mining: Concepts and Techniques (2011).
“6.3. Preprocessing data,” scikit-learn. http://scikit-learn.org/stable/modules/preprocessing.html , (2021).
Pedregosa, F. et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 12 , 2825–2830 (2011).
Fleming, T. R. & Harrington, D. P. Counting processes and survival analysis. (Wiley-Interscience, 2005). (Accessed 13 Jan 2022).
Das, A. & Rad, P. Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey . ArXiv: 200611371 Cs (2020).
Gunning, D. et al. XAI—Explainable artificial intelligence. Sci. Robot. 4 , eaay7120 (2019).
Bi, X. et al. Explainable time–frequency convolutional neural network for microseismic waveform classification. Inf. Sci. 546 , 883–896. https://doi.org/10.1016/j.ins.2020.08.109 (2021).
Article MathSciNet MATH Google Scholar
Bi, X. et al. An uncertainty-based neural network for explainable trajectory segmentation. ACM Trans. Intell. Syst. Technol. 13 (1), 1–18. https://doi.org/10.1145/3467978 (2022).
Download references
Author information
Authors and affiliations.
The Scientific and Technological Research Council of Turkey, TUBITAK, Ankara, Turkey
Serkan Ucer
Department of Computer Engineering, Ankara Medipol University, Ankara, Turkey
Tansel Ozyer
Department of Computer Science, University of Calgary, Alberta, Canada
Reda Alhajj
Department of Computer Engineering, Istanbul Medipol University, Istanbul, Turkey
Department of Heath Informatics, University of Southern Denmark, Odense, Denmark
You can also search for this author in PubMed Google Scholar
Contributions
All authors (S.U., T.O. and R.A.) developed the methodology, S.U. wrote the programs, run the experiments, analyzed the results and wrote the manuscript. All authors reviewed and approved the manuscript.
Corresponding author
Correspondence to Reda Alhajj .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary information., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Ucer, S., Ozyer, T. & Alhajj, R. Explainable artificial intelligence through graph theory by generalized social network analysis-based classifier. Sci Rep 12 , 15210 (2022). https://doi.org/10.1038/s41598-022-19419-7
Download citation
Received : 13 March 2022
Accepted : 29 August 2022
Published : 08 September 2022
DOI : https://doi.org/10.1038/s41598-022-19419-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Exploring the use of social network analysis methods in process improvement within healthcare organizations: a scoping review.
- Troy Francis
- Morgan Davidson
- Patricia Trbovich
BMC Health Services Research (2024)
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

Help | Advanced Search
Computer Science > Data Structures and Algorithms
Title: graph theory and its uses in graph algorithms and beyond.
Abstract: Graphs are fundamental objects that find widespread applications across computer science and beyond. Graph Theory has yielded deep insights about structural properties of various families of graphs, which are leveraged in the design and analysis of algorithms for graph optimization problems and other computational optimization problems. These insights have also proved helpful in understanding the limits of efficient computation by providing constructions of hard problem instances. At the same time, algorithmic tools and techniques provide a fresh perspective on graph theoretic problems, often leading to novel discoveries. In this thesis, we exploit this symbiotic relationship between graph theory and algorithms for graph optimization problems and beyond. This thesis consists of three parts. In the first part, we study a graph routing problem called the Node-Disjoint Paths (NDP) problem. Given a graph and a set of source-destination pairs of its vertices, the goal is to route the maximum number of pairs via node-disjoint paths. We come close to resolving the approximability of NDP by showing that it is $n^{\Omega(1/poly\log\log n)}$-hard to approximate, even on grid graphs, where n is the number of vertices. In the second part of this thesis, we use graph decomposition techniques developed for efficient algorithms to derive a graph theoretic result. We show that for every n-vertex expander graph G, if H is any graph with at most $O(n/\log n)$ vertices and edges, then H is a minor of G. In the last part, we show that the graph theoretic tools and graph algorithmic techniques can shed light on problems seemingly unrelated to graphs. We show that the randomized space complexity of the Longest Increasing Subsequence (LIS) problem in the streaming model is intrinsically tied to the query-complexity of the Non-Crossing Matching problem on graphs in a new model of computation that we define.
| Comments: | PhD Thesis |
| Subjects: | Data Structures and Algorithms (cs.DS); Computational Complexity (cs.CC) |
| Cite as: | [cs.DS] |
| (or [cs.DS] for this version) | |
| Focus to learn more arXiv-issued DOI via DataCite |
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Advertisement
Graph theory applications for advanced geospatial modelling and decision-making
- Published: 25 September 2024
Cite this article

- Surajit Ghosh ORCID: orcid.org/0000-0002-3928-2135 1 ,
- Archita Mallick ORCID: orcid.org/0009-0007-6456-615X 2 , 6 ,
- Anuva Chowdhury ORCID: orcid.org/0000-0002-2246-2228 3 ,
- Kounik De Sarkar ORCID: orcid.org/0009-0002-6757-0975 4 , 7 &
- Jayesh Mukherjee ORCID: orcid.org/0000-0003-2007-8756 5
64 Accesses
1 Altmetric
Explore all metrics
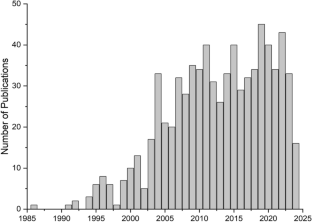
Geospatial sciences (GS) include a wide range of applications, from environmental monitoring to infrastructure development, as well as location-based analysis and services. Notably, graph theory algorithms have emerged as indispensable tools in GS because of their capability to model and analyse spatial relationships efficiently. This article underscores the critical role of graph theory applications in addressing real-world geospatial challenges, emphasising their significance and potential for future innovations in advanced spatial analytics, including the digital twin concept. The analysis shows that researchers from 58 countries have contributed to exploring graph theory and its application over 37 years through more than 700 research articles. A comprehensive collection of case studies has been showcased to provide an overview of graph theory’s diverse and impactful applications in advanced geospatial research across various disciplines (transportation, urban planning, environmental management, ecology, disaster studies and many more) and their linkages to the United Nations Sustainable Development Goals (UN SDGs). Thus, the interdisciplinary nature of graph theory can foster an understanding of the association among different scientific domains for sustainable resource management and planning.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

The Use of Graphs to Explore the Network Paradigm in Urban and Territorial Studies

Case Studies

A Review of Spatial Network Insights and Methods in the Context of Planning: Applications, Challenges, and Opportunities
Explore related subjects.
- Artificial Intelligence
Data availability
No datasets are generated or analysed during the current study.
Aavik T, Holderegger R, Bolliger J (2014) The structural and functional connectivity of the grassland plant Lychnis flos-cuculi. Heredity 112(5):471–478. https://doi.org/10.1038/hdy.2013.120
Article CAS Google Scholar
Abdelkarim A, Al-Alola SS, Alogayell HM, Mohamed SA, Alkadi II, Ismail IY (2020) Integration of GIS-based multicriteria decision analysis and analytic hierarchy process to assess flood hazard on the Al-shamal train pathway in Al-Qurayyat region, kingdom of Saudi Arabia. Water 12(6):1702. https://doi.org/10.3390/w12061702
Article Google Scholar
Abebe GA (2013) Quantifying urban growth pattern in developing countries using remote sensing and spatial metrics: a case study in Kampala, Uganda (Master's thesis, University of Twente, Netherlands). https://essay.utwente.nl/84729/1/abebe.pdf . Accessed 10 June 2024
Adade D, de Vries WT (2023) Digital twin for active stakeholder participation in land-use planning. Land 12(3):538. https://doi.org/10.3390/land12030538
Adriaensen F, Chardon JP, De Blust G, Swinnen E, Villalba S, Gulinck H, Matthysen E (2003) The application of ‘least-cost’modelling as a functional landscape model. Landsc Urban Plan 64(4):233–247. https://doi.org/10.1016/S0169-2046(02)00242-6
Aina YA (2012) Applications of geospatial technologies for practitioners: an emerging perspective of geospatial education. Emerg Inform–Innov Concepts Appl 3–20. https://www.intechopen.com/chapters/35692 . Accessed 12 Sept 2024
Alexander M (2012) Decision-making using the analytic hierarchy process (AHP) and SAS/IML
Ali SS, Kaur R, Khan S (2023) Identification of innovative technology enablers and drone technology determinants adoption: a graph theory matrix analysis framework. Oper Manage Res 1–23:1. https://doi.org/10.1007/s12063-023-00346-3
Amudha P, Sagayaraj AC, Sheela AS (2018) An application of graph theory in cryptography. Int J Pure Appl Math 119(13):375–383 (Last accessed on 30 May 2024)
Google Scholar
Anderson T, Dragićević S (2020) Representing complex evolving spatial networks: Geographic network automata. ISPRS Int J Geo-Information 9(4):270. https://doi.org/10.3390/ijgi9040270
Arcaute E, Molinero C, Hatna E, Murcio R, Vargas-Ruiz C, Masucci AP, Batty M (2016) Cities and regions in Britain through hierarchical percolation. R Soc Open Sci 3(4):150691. https://doi.org/10.1098/rsos.150691
Barabási AL (2016) Network science. Cambridge University Press, Glasgow, UK
Bastille-Rousseau G, Douglas‐Hamilton I, Blake S, Northrup JM, Wittemyer G (2018) Applying network theory to animal movements to identify properties of landscape space use. Ecol Appl 28(3):854–864. https://doi.org/10.1002/eap.1697
Batty M (2013) The new science of cities. MIT Press
Book Google Scholar
Batz GV, Delling D, Sanders P, Vetter C (2009) Time-dependent contraction hierarchies. In: 2009 Proceedings of the Eleventh Workshop on Algorithm Engineering and Experiments (ALENEX). Society for Industrial and Applied Mathematics, pp 97–105. https://doi.org/10.1137/1.9781611972894.10
Chapter Google Scholar
Baykasoglu A (2014) A review and analysis of graph theoretical-matrix permanent approach to decision making with example applications. Artif Intell Rev 42:573–605. https://doi.org/10.1007/s10462-012-9354-y
Benenson I, Torrens P (2004) Geosimulation: Automata-based modeling of urban phenomena. John Wiley & Sons
Bhatti UA, Tang H, Wu G, Marjan S, Hussain A (2023) Deep learning with graph convolutional networks: an overview and latest applications in computational intelligence. Int J Intell Syst 2023:1–28. https://doi.org/10.1155/2023/8342104
Bono F, Gutiérrez E (2011) A network-based analysis of the impact of structural damage on urban accessibility following a disaster: the case of the seismically damaged Port Au Prince and Carrefour urban road networks. J Transp Geogr 19(6):1443–1455. https://doi.org/10.1016/j.jtrangeo.2011.08.002
Bornmann L, Leydesdorff L, Mutz R (2013) The use of percentiles and percentile rank classes in the analysis of bibliometric data: opportunities and limits. J Informetrics 7(1):158–165
Botai JO, Ghosh S, Matheswaran K, Dickens C, Langa N, Garcia M (2023) Options for digital twin application in developing country river basin management: a review. International Water Management Institute (IWMI), Colombo. CGIAR Initiative on Digital Innovation, 20p. https://hdl.handle.net/10568/134763
Brost RC, Parekh OD, Rintoul MD, Woodbridge D, Strip DR (2014) Facility search in remote sensing data using geospatial semantic graphs (No. SAND2014-1362 C). Sandia National Lab. (SNL-NM), Albuquerque, NM (United States). https://www.osti.gov/servlets/purl/1141268 . (Last accessed on 29 May 2024)
Bunn AG, Urban DL, Keitt TH (2000) Landscape connectivity: a conservation application of graph theory. J Environ Manage 59(4):265–278
Burnham JF (2006) Scopus database: a review. Biomed Digit Libr 3(1):1–8. https://doi.org/10.1006/jema.2000.0373
Cao B, Shahraki AA (2023) Planning of Transportation Infrastructure Networks for Sustainable Development with Case studies in Chabahar. Sustainability 15(6):5154. https://doi.org/10.3390/su15065154
Cavallaro L, Bagdasar O, De Meo P, Fiumara G, Liotta A (2021) Graph and network theory for the analysis of criminal networks. In: Fortino G, Liotta A, Gravina R, Longheu A (eds) Data Science and Internet of things: internet of things. Springer, Cham, pp 139–156. https://doi.org/10.1007/978-3-030-67197-6_8
Chauhan A, Kumar P (2024) A Novel Approach for Controlling the spread of viral diseases using epidemic Role Index (ERI) and graph-theoretic contract tracing model. SN Comput Sci 5(5):570. https://doi.org/10.1007/s42979-024-02871-9
Chen CYH, Okhrin Y, Wang T (2024) Monitoring network changes in social media. J Bus Economic Stat 42(2):391–406. https://doi.org/10.1080/07350015.2021.2016425
Chowdhury A, Ghosh S, Holmatov B (2023) Earth observation-based rice mapping studies in Vietnamese Mekong delta compared to global context: a bibliometric analysis. Sustainability 16(1):189. https://doi.org/10.3390/su16010189
Dangermond J, Goodchild MF (2020) Building geospatial infrastructure. Geospatial Inform Sci 23(1):1–9. https://doi.org/10.1080/10095020.2019.1698274
Dawood HA (2014) Graph theory and cyber security. In: 2014 3rd International Conference on Advanced Computer Science Applications and Technologies. IEEE, pp 90–96. https://doi.org/10.1109/ACSAT.2014.23
Demšar U, Špatenková O, Virrantaus K (2008) Identifying critical locations in a spatial network with graph theory. Trans GIS 12(1):61–82. https://doi.org/10.1111/j.1467-9671.2008.01086.x
Devi BS, Murthy MSR, Debnath B, Jha CS (2013) Forest patch connectivity diagnostics and prioritisation using graph theory. Ecol Model 251:279–287. https://doi.org/10.1016/j.ecolmodel.2012.12.022
Dijksta EW (1959) A note on two problems in connexion with graphs. Numer Math 1(1):269–271
Dilts TE, Weisberg PJ, Leitner P, Matocq MD, Inman RD, Nussear KE, Esque TC (2016) Multiscale connectivity and graph theory highlight critical areas for conservation under climate change. Ecol Appl 26(4):1223–1237. https://doi.org/10.1890/15-0925
Doukas H, Karakosta C, Flamos A, Flouri M, Psarras J (2011) Graph theory-based approach for energy corridors network to Greece. Int J Energy Sect Manage 5(1):60–80. https://doi.org/10.1108/17506221111120901
Dutta S, Patra D, Shankar H, Alok Verma P (2014) Development of GIS tool for the solution of minimum spanning tree problem using prim’s algorithm. Int Archives Photogrammetry Remote Sens Spat Inform Sci 40:1105–1114. https://doi.org/10.5194/isprsarchives-XL-8-1105-2014
Egelston A, Cook S, Nguyen T, Shaffer S (2019) Networks for the future: a mathematical network analysis of the partnership data for sustainable development goals. Sustainability 11(19):5511. https://doi.org/10.3390/su11195511
Estrada E (2012) Complex networks in the Euclidean space of communicability distances. Phys Rev E 85(6):066122. https://doi.org/10.1103/PhysRevE.85.066122
Eunus Ali M, Aamir Cheema M, Hashem T, Ulhaq A, Babar MA (2023) Enabling spatial digital twins: technologies, challenges, and future research directions. https://doi.org/10.48550/arXiv.2306.06600
Feng J (2002) A fast method for continuous nearest target objects query on road network. In: Proceedings of VSMM’02. pp 182–191
Ferrer-Cid P, Barcelo-Ordinas JM, Garcia-Vidal J (2022) Data reconstruction applications for IoT air pollution sensor networks using graph signal processing. J Netw Comput Appl 205:103434. https://doi.org/10.1016/j.jnca.2022.103434
Freeman LC (1977) A set of measures of centrality based on betweenness. Sociometry 40:35–41. https://doi.org/10.2307/3033543
Gadelha Filho T, Silvia C, Aleksandar D, Massimo B, Marco M (2021) Rural electrification planning based on graph theory and geospatial data: a realistic topology oriented approach. Sustainable Energy Grids Networks 28:100525. https://doi.org/10.1016/j.segan.2021.100525
Garcia Andarcia M, Dickens C, Silva P, Matheswaran K, Koo J (2024) Digital twin for management of water resources in the Limpopo River basin: a concept. International water management institute (IWMI). CGIAR initiative on digital innovation. p 4. https://hdl.handle.net/10568/151898
Ge Y, Li X, Cai X, Deng X, Wu F, Li Z, Luan W (2018) Converting UN sustainable development goals (SDGs) to decision-making objectives and implementation options at the river basin scale. Sustainability 10(4):1056. https://doi.org/10.3390/su10041056
Geetha NK, Sekar P (2018) An unprecedented multi attribute decision making using graph theory matrix approach. Eng Sci Technol Int J 21(1):7–16. https://doi.org/10.1016/j.jestch.2017.12.011
Ghosh S, Mallick A, Chowdhury A, De Sarkar K (2023) Graph theory applications in advanced geospatial research. arXiv preprint arXiv:2309.03249
Gorbani R, Rostaei S, Karbasi P (2021) An analysis of the Continuity and Cohesion of Urban Ecologic Network through a Graph Theory Model. Town Ctry Plann 13(2):281–309. https://doi.org/10.22059/jtcp.2020.313025.670169
Guze S (2017) An application of the selected graph theory domination concepts to transportation networks modelling. Zeszyty Naukowe Akademii Morskiej w Szczecinie. https://doi.org/10.17402/250
Guze S (2019) Graph theory approach to the vulnerability of transportation networks. Algorithms 12(12):270. https://doi.org/10.3390/a12120270
Han J, Cui Q, Yang C, Tao X (2014) Bipartite matching approach to optimal resource allocation in device to device underlaying cellular network. Electron Lett 50(3):212–214. https://doi.org/10.1049/el.2013.2378
Harmon RR, Castro-Leon EG, Bhide S (2015) Smart cities and the internet of things. In: 2015 Portland International Conference on Management of Engineering and Technology (PICMET). IEEE, pp 485–494. https://doi.org/10.1109/PICMET.2015.7273174
Heckmann T, Schwanghart W, Phillips JD (2015) Graph theory—recent developments of its application in geomorphology. Geomorphology 243:130–146. https://doi.org/10.1016/j.geomorph.2014.12.024
Issa L, Mezher T, El Fadel M (2024) Can network analysis ascertain SDGs interlinkages towards evidence-based policy planning? A systematic critical assessment. Environ Impact Assess Rev 104:107295. https://doi.org/10.1016/j.eiar.2023.107295
Jayabalasamy G, Pujol C, Latha Bhaskaran K (2024) Application of Graph Theory for Blockchain technologies. Mathematics 12(8):1133. https://doi.org/10.3390/math12081133
Jensen CS, Lu H, Yang B (2009) Graph model based indoor tracking. In: 2009 tenth international conference on mobile data management: systems, services and middleware. IEEE, pp 122–131. https://doi.org/10.1109/MDM.2009.23
Kar R (2022) To study the impact of social network analysis on social media marketing using graph theory. Int J Softw Sci Comput Intell (IJSSCI) 14(1):1–20. https://doi.org/10.4018/IJSSCI.304437
Kasyk L, Kowalewski M, Pyrchla J, Kijewska M, Leyk M (2016) Modeling the impact of surface currents in a harbor using graph theory. Zeszyty Naukowe Akademii Morskiej w Szczecinie 46(118):189–196. https://doi.org/10.17402/136
Kaur R, Gupta K (2022) Blue-Green infrastructure (BGI) network in urban areas for sustainable storm water management: a geospatial approach. City Environ Interact 16:100087. https://doi.org/10.1016/j.cacint.2022.100087
Khiste GP, Maske DB, Deshmukh RK (2018) Knowledge management output in scopus during 2007 to 2016. Asian J Res Social Sci Humanit 8(1):10–19. https://doi.org/10.5958/2249-7315.2018.00002.3
Khiste GP, Paithankar RR (2017) Analysis of bibliometric term in Scopus. Int J Libr Sci Inform Manage (IJLSIM) 3(3):81–88
Koutrouli M, Karatzas E, Paez-Espino D, Pavlopoulos GA (2020) A guide to conquer the biological network era using graph theory. Front Bioeng Biotechnol 8:34. https://doi.org/10.3389/fbioe.2020.00034
Kruskal JB (1956) On the shortest spanning subtree of a graph and the traveling salesman problem. Proc Am Math Soc 7(1):48–50. https://community.ams.org/journals/proc/1956-007-01/S0002-9939-1956-0078686-7/S0002-9939-1956-0078686-7.pdf . (Last accessed on 29 May 2024)
Leal Filho W, Lovren VO, Will M, Salvia AL, Frankenberger F (2021) Poverty: a central barrier to the implementation of the UN Sustainable Development Goals. Environ Sci Policy 125:96–104. https://doi.org/10.1016/j.envsci.2021.08.020
Lehtola VV, Koeva M, Elberink SO, Raposo P, Virtanen JP, Vahdatikhaki F, Borsci S (2022) Digital twin of a city: review of technology serving city needs. Int J Appl Earth Obs Geoinf 102915:102915. https://doi.org/10.1016/j.jag.2022.102915
Li J, Wang Y, Liu H (2024) The optimization of split demand route planning under metro-truck collaborative distribution. Urban Rail Transit 10(2):144–159. https://doi.org/10.1007/s40864-024-00216-6
Li K, Liu Q, Zeng Z (2020) Distributed optimisation based on multi-agent system for resource allocation with communication time‐delay. IET Control Theory Appl 14(4):549–557. https://doi.org/10.1049/iet-cta.2019.0020
Li W, Zhao Y (2015) Bibliometric analysis of global environmental assessment research in a 20-year period. Environ Impact Assess Rev 50:158–166. https://doi.org/10.1016/j.eiar.2014.09.012
Maciejewski W, Puleo GJ (2014) Environmental evolutionary graph theory. J Theor Biol 360:117–128. https://doi.org/10.1016/j.jtbi.2014.06.040
McGowan C (2023) Geofence warrants, Geospatial Innovation, and implications for data privacy. Proc Association Inform Sci Technol 60(1):661–665. https://doi.org/10.1002/pra2.835
McIntyre NE, Wright CK, Swain S, Hayhoe K, Liu G, Schwartz FW, Henebry GM (2014) Climate forcing of wetland landscape connectivity in the Great Plains. Front Ecol Environ 12(1):59–64. https://doi.org/10.1890/120369
Melnik S, Garcia-Molina H, Rahm E (2002) Similarity flooding: a versatile graph matching algorithm and its application to schema matching. In: Proceedings 18th International Conference on Data Engineering, IEEE, pp 213–226. https://doi.org/10.1109/ICDE.2002.994702
Minor ES, Urban DL (2008) A graph-theory framework for evaluating landscape connectivity and conservation planning. Conserv Biol 22(2):297–307. https://doi.org/10.1111/j.1523-1739.2007.00871.x
Mohamed RE, Kosba E, Mahar K, Mesbah S (2018) A framework for emergency-evacuation planning using GIS and DSS. In: Popovich V, Schrenk M, Thill JC, Claramunt C, Wang T (eds) Information Fusion and Intelligent Geographic Information Systems (IF&IGIS’17). Springer, Cham, pp 213–226. https://doi.org/10.1007/978-3-319-59539-9_16
Mukherjee J, Ghosh S (2023) Decoding the vitality of Earth Observation for Flood Monitoring in the Lower Godavari River Basin, India. J Geol Soc India 99(6):802–808. https://doi.org/10.1007/s12594-023-2387-9
Nagarajan K, Muniyandi M, Palani B, Sellappan S (2020) Social network analysis methods for exploring SARS-CoV-2 contact tracing data. BMC Med Res Methodol 20:1–10. https://doi.org/10.1186/s12874-020-01119-3
Nelson Q, Steffensmeier D, Pawaskar S (2018) A simple approach for sustainable transportation systems in smart cities: A graph theory model. In: 2018 IEEE Conference on Technologies for Sustainability (SusTech), IEEE, pp 1–5. https://doi.org/10.1109/SusTech.2018.8671384
Oliveira M, Gama J (2012) An overview of social network analysis. Wiley Interdisciplinary Reviews: Data Min Knowl Discovery 2(2):99–115. https://doi.org/10.1002/widm.1048
Ospina-Forero L, Castañeda G, Guerrero OA (2022) Estimating networks of sustainable development goals. Inf Manag 59(5):103342. https://doi.org/10.1016/j.im.2020.103342
Pavlopoulos GA, Secrier M, Moschopoulos CN, Soldatos TG, Kossida S, Aerts J, Bagos PG (2011) Using graph theory to analyze biological networks. BioData Min 4:1–27. https://doi.org/10.1186/1756-0381-4-10
Phillips JD, Schwanghart W, Heckmann T (2015) Graph theory in the geosciences. Earth Sci Rev 143:147–160. https://doi.org/10.1016/j.earscirev.2015.02.002
Prim RC (1957) Shortest connection networks and some generalisations. Bell Syst Tech J 36(6):1389–1401. https://doi.org/10.1002/j.1538-7305.1957.tb01515.x
Rajbanshi J, Das S, Patel PP (2022) Planform changes and alterations of longitudinal connectivity caused by the 2019 flood event on the braided Brahmaputra River in Assam, India. Geomorphology 403:108174. https://doi.org/10.1016/j.geomorph.2022.108174
Ruiz-Frau A, Ospina-Alvarez A, Villasante S, Pita P, Maya-Jariego I, de Juan S (2020) Using graph theory and social media data to assess cultural ecosystem services in coastal areas: Method development and application. Ecosyst Serv 45:101176. https://doi.org/10.1016/j.ecoser.2020.101176
Sanyal J, Chowdhury A (2023) Reassessment of reservoir sedimentation rates under monsoon climate with combined optical and microwave remote sensing: a case study of three reservoirs in the Upper Godavari Basin, India. J Hydrol Eng 28(11):05023022. https://doi.org/10.1061/JHYEFF.HEENG-5995
Saunders MI, Brown CJ, Foley MM, Febria CM, Albright R, Mehling MG, Burfeind DD (2015) Human impacts on connectivity in marine and freshwater ecosystems assessed using graph theory: a review. Mar Freshw Res 67(3):277–290. https://doi.org/10.1071/MF14358
Schrotter G, H¨urzeler C (2020) The digital twin of the city of Zurich for urban planning. PFG–Journal Photogrammetry Remote Sens Geoinf Sci 88(1):99–112. https://doi.org/10.1007/s41064-020-00092-2
Scott G, Rajabifard A (2017) Sustainable development and geospatial information: a strategic framework for integrating a global policy agenda into national geospatial capabilities. Geospatial Inform Sci 20(2):59–76. https://doi.org/10.1080/10095020.2017.1325594
Shen LH, Feng KT, Hanzo L (2023) Five facets of 6G: research challenges andopportunities. ACM Comput Surv 55(11):1–39. https://doi.org/10.1145/3571072
Singh RP (2014) Application of graph theory in computer science and engineering. Int J Comput Appl 104(1). https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=f8c4188e4aa9d21ed06e5e01d42726d3a825b79b (Last accessed 29 May 2024)
Singh RP, Kataria R, Singhal S (2019) Decision-making in real-life industrial environment through graph theory approach. Comput Archit Ind Biomech Biomed Eng 119. https://www.intechopen.com/chapters/66967 . Accessed 12 Sept 2024
Swain RB, Ranganathan S (2021) Modeling interlinkages between sustainable development goals using network analysis. World Dev 138:105136. https://doi.org/10.1016/j.worlddev.2020.105136
Ustimenko VA (2015) On algebraic graph theory and non-bijective multivariate maps in cryptography. Algebra Discrete Math 20(1):152–170 (Last accessed on 30 May 2024)
Vanhove S, Fack V (2010) Applications of graph algorithms in GIS. SIGSPATIAL Special 2(3):31–36. https://doi.org/10.1145/1953102.1953108
Vu DD, Kaddoum G (2017) A waste city management system for smart cities applications. In: 2017 advances in wireless and optical communications (RTUWO). IEEE, pp 225–229. https://doi.org/10.1109/RTUWO.2017.8228538
Wang J, Banzhaf E (2018) Towards a better understanding of Green Infrastructure: A critical review. Ecol Indic 85:758–772. https://doi.org/10.1016/j.ecolind.2017.09.018
Wang L, Duan J, Wang B (2005) Algorithms research and simulation of shortestpath in GIS. Compute Simul 22(1):117–120
Wang Y, Sun H, Zhao Y, Zhou W, Zhu S (2019) A heterogeneous graph embedding framework for location-based social network analysis in smart cities. IEEE Trans Industr Inf 16(4):2747–2755. https://doi.org/10.1109/TII.2019.2953973
Watson BC, Morris ZB, Weissburg M, Bras B (2023) System of system design-for-resilience heuristics derived from forestry case study variants. Reliab Eng Syst Saf 229:108807. https://doi.org/10.1016/j.ress.2022.108807
Watts DJ, Strogatz SH (1998) Collective dynamics of ‘small-world’networks. Nature 393(6684):440–442
Wejdling RL, Tinggaard N, Leth TL, Jensen K, Husted N, Møller M (2006) Multiple routes planning. http://www.afterschool.dk/uploads/p2-report.pdf (Last accessed on 29 may 2024)
Yao B, Liu X, Zhang WJ, Chen XE, Zhang XM, Yao M, Zhao ZX (2013) Applying graph theory to the internet of things. In: 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, IEEE, pp 2354–2361. https://doi.org/10.1109/HPCC.and.EUC.2013.339
Yu X, Xu Z (2012) Graph-based multi-agent decision making. Int J Approximate Reasoning 53(4):502–512. https://doi.org/10.1016/j.ijar.2011.12.002
Zetterberg A, Mörtberg UM, Balfors B (2010) Making graph theory operational for landscape ecological assessments, planning, and design. Landsc Urban Plann 95(4):181–191. https://doi.org/10.1016/j.landurbplan.2010.01.002
Zhu D, Liu Y (2018) Modelling spatial patterns using graph convolutional networks (short paper). In: 10th International Conference on Geographic Information Science (GIScience 2018). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik. https://doi.org/10.4230/LIPIcs.GISCIENCE.2018.73
Download references
Acknowledgements
This publication has been prepared as an output of the CGIAR Initiative on Digital Innovation, which researches pathways to accelerate the transformation towards sustainable and inclusive agrifood systems by generating research-based evidence and innovative digital solutions. We thank all funders who supported this research through their contributions to the CGIAR Trust Fund ( https://www.cgiar.org/funders/ ).
No funding is available for this publication.
Author information
Authors and affiliations.
International Water Management Institute, Colombo, Sri Lanka
Surajit Ghosh
Department of Computer Applications, Techno Main Salt Lake, Kolkata, West Bengal, India
Archita Mallick
Department of Remote Sensing, Birla Institute of Technology Mesra, Ranchi, Jharkhand, India
Anuva Chowdhury
Department of Earth and Environmental Studies, National Institute of Technology Durgapur, West Bengal, India
Kounik De Sarkar
Earth Surface Processes Research Group, Department of Geography and Earth Sciences, Aberystwyth University, Aberystwyth, Wales, United Kingdom
Jayesh Mukherjee
Centre of Excellence in Disaster Mitigation and Management, Indian Institute Technology Roorkee, Uttarakhand, India
Department of Environmental Science and Engineering, Indian Institute Technology Bombay, Mumbai, Maharashtra, India
You can also search for this author in PubMed Google Scholar
Contributions
S.G. and A.M. contributed to the concept, design and writing the original draft of the manuscript. A.C., K.D.S., and S.G. took the lead for data collection and conducted the bibliometric analysis. A.M., A.C., S.G. and J.M. prepared figures and tables. J.M. contributed to the concept and wrote the policy and SDG section. All authors reviewed, edited and approved this version to be published.
Corresponding author
Correspondence to Surajit Ghosh .
Ethics declarations
Ethical approval.
Not applicable to the present study.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Ghosh, S., Mallick, A., Chowdhury, A. et al. Graph theory applications for advanced geospatial modelling and decision-making. Appl Geomat (2024). https://doi.org/10.1007/s12518-024-00586-3
Download citation
Received : 27 February 2024
Accepted : 05 September 2024
Published : 25 September 2024
DOI : https://doi.org/10.1007/s12518-024-00586-3
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Graph theory applications
- Spatial network
- Geospatial science
- Digital twin
- Find a journal
- Publish with us
- Track your research
Theory and Applications of Graphs
Home > Journals > TAG
Theory and Applications of Graphs (TAG) publishes high quality papers containing results of wide interest in the areas of graph theory and its applications.
As a platinum open access journal, TAG is freely available to both authors and readers.
Journal promotional flyer available here .
See the Aims and Scope for more information about the journal.
Additional Instructions for Screen Reader Users
The Readership Activity Map feature further down the page presents a real time interactive world map with pins indicating where documents from our collection have been downloaded recently. Begin reading after the Zoom buttons to find additional real time statistics.
Current Issue: Volume 11, Issue 1 (2024)
Recent studies on the super edge-magic deficiency of graphs Rikio Ichishima, Susana C. Lopez, Francesc Muntaner, and Yukio Takahashi
Strongly i-Bicritical Graphs Michelle Edwards, Gary MacGillivray, and Shahla Nasserasr
Approval Gap of Weighted k-Majority Tournaments Jeremy Coste, Breeann Flesch, Joshua D. Laison, Erin McNicholas, and Dane Miyata
- Journal Home
- About This Journal
- Aims & Scope
- Editorial Board
- Submit Article
- Most Popular Papers
- Receive Email Notices or RSS
Special Issues:
- Dynamic Surveys
Search GS Commons
Advanced Search
ISSN: 2470-9859
Home | About | FAQ | My Account | Accessibility Statement
Privacy Copyright
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Journal Proposal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Journal Menu
- Mathematics Home
- Aims & Scope
- Editorial Board
- Reviewer Board
- Topical Advisory Panel
- Instructions for Authors
- Special Issues
- Sections & Collections
- Article Processing Charge
- Indexing & Archiving
- Editor’s Choice Articles
- Most Cited & Viewed
- Journal Statistics
- Journal History
- Journal Awards
- Society Collaborations
- Conferences
- Editorial Office
Journal Browser
- arrow_forward_ios Forthcoming issue arrow_forward_ios Current issue
- Vol. 12 (2024)
- Vol. 11 (2023)
- Vol. 10 (2022)
- Vol. 9 (2021)
- Vol. 8 (2020)
- Vol. 7 (2019)
- Vol. 6 (2018)
- Vol. 5 (2017)
- Vol. 4 (2016)
- Vol. 3 (2015)
- Vol. 2 (2014)
- Vol. 1 (2013)
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
Recent Advances in Chemical Graph Theory and Their Applications
Special issue editors, special issue information, benefits of publishing in a special issue.
- Published Papers
A special issue of Mathematics (ISSN 2227-7390). This special issue belongs to the section " Network Science ".
Deadline for manuscript submissions: closed (31 January 2021) | Viewed by 23611
Share This Special Issue

Dear Colleagues,
Since the seminal paper of the American chemist Harold Wiener in 1947, many numerical quantities of graphs have been introduced and extensively studied in order to describe various physicochemical properties. Such graph invariants are most commonly referred to as topological indices and are often defined using degrees of vertices, distances between vertices, eigenvalues, symmetries, and many other properties of graphs. It is desirable for a topological index to also be a molecular descriptor. In order to establish the connection between topological indices and the properties or activities of studied compounds, quantitative structure–activity relationships (QSAR) and quantitative structure–property relationships (QSPR) must be performed. This enables the process of finding new compounds with desired properties in silico instead of in vitro.
There are well studied groups of molecules composed of carbon and hydrogen atoms, but modeling of more complex heteroatomic compounds is much more challenging. On the other hand, topological indices have also found enormous applications in rapidly growing research of complex networks, which include communications networks, social networks, biological networks, etc. In such networks, these indices are used as measures for various structural properties.
The purpose of this Special Issue is to report and review recent developments concerning mathematical properties, methods of calculations, and applications of topological indices in any area of interest. Moreover, papers on other topics in chemical graph theory are also welcome.
Prof. Dr. Petra Zigert Pletersek Dr. Niko Tratnik Guest Editors
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website . Once you are registered, click here to go to the submission form . Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the special issue website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Mathematics is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript. The Article Processing Charge (APC) for publication in this open access journal is 2600 CHF (Swiss Francs). Submitted papers should be well formatted and use good English. Authors may use MDPI's English editing service prior to publication or during author revisions.
- Topological indices
- Molecular descriptors
- Methods of calculations
- QSP(A)R analysis
- Molecular graphs
- Complex molecules
- Nanostructures
- Different measures in networks
- Ease of navigation: Grouping papers by topic helps scholars navigate broad scope journals more efficiently.
- Greater discoverability: Special Issues support the reach and impact of scientific research. Articles in Special Issues are more discoverable and cited more frequently.
- Expansion of research network: Special Issues facilitate connections among authors, fostering scientific collaborations.
- External promotion: Articles in Special Issues are often promoted through the journal's social media, increasing their visibility.
- e-Book format: Special Issues with more than 10 articles can be published as dedicated e-books, ensuring wide and rapid dissemination.
Further information on MDPI's Special Issue polices can be found here .
Published Papers (5 papers)
Graphical abstract
Further Information
Mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
IMAGES
VIDEO
COMMENTS
This paper provides a description of implementations of graphical theory in a number of heterogeneous areas but focuses mostly on information science, electrical engineering, linguistics, physics ...
The Journal of Graph Theory is a high-calibre graphs and combinatorics journal publishing rigorous research on how these areas interact with other mathematical sciences. Our editorial team of influential graph theorists welcome submissions on a range of graph theory topics, such as structural results about graphs, graph algorithms with ...
A recent research in this area (refer to 15) handles node classification problems by introducing graph neural networks over graphs (particularly Graph Convolutional Networks—GCNs).
The Journal of Graph Theory publishes high-calibre research on graph theory and combinatorics, and how these areas interact with other mathematical sciences.
Many graph theory problems appear as either real or theoretical problems. We would like to invite you submit an article on your recent research in the area of graph theory along with its application to our Special Issue "Recent Advances in Graph Theory with Applications".
Graph theory is an important area of Applied Mathematics with a broad spectrum of applications in many fields. In the Call for Papers for this issue, I asked for submissions presenting new and inoovative approaches for traditional graph-theoretic problems as well as for new applications of graph theory in emerging fields, such as network ...
Recent advances in graph theory have opened up new avenues for research and practical applications. The growing availability of large-scale graph data and the need to extract insights from complex interconnected systems continue to drive the evolution of this field.
In this thesis, we exploit this symbiotic relationship between graph theory and algorithms for graph optimization problems and beyond. This thesis consists of three parts. In the first part, we study a graph routing problem called the Node-Disjoint Paths (NDP) problem. Given a graph and a set of source-destination pairs of its vertices, the ...
Graph theory (GT) concepts are potentially applicable in the field of computer science (CS) for many purposes. The unique applications of GT in the CS field such as clustering of web documents, cryptography, and analyzing an algorithm's execution, among others, are promising applications. Furthermore, GT concepts can be employed to electronic circuit simplifications and analysis. Recently ...
This book offers an introduction to a graph theory topic of current research, with recent advances and open problems.
The first research on graph theory, titled 'The uses of spatial analysis in medical geography: A review', is published in 1986 in the journal Social Science and Medicine. The rise in publications started in 2000, with 10 articles published. The highest publication is recorded in 2019 (45), followed by 2022 (43), 2020, 2015, and 2011 (40).
Abstract Based on a literature review, we present a framework for structuring the application of graph theory in the library domain. Our goal is to provide both researchers and libraries with a standard tool to classify scientific work, at the same time allowing for the identification of previously underrepresented areas where future research might be productive. To achieve this, we compile ...
Theory and Applications of Graphs (TAG) publishes high quality papers containing results of wide interest in the areas of graph theory and its applications. As a platinum open access journal, TAG is freely available to both authors and readers.
search topics in graph the-ory and its applications. The topics are in the form of research projects developed by the author over the last 15 years. We dis-cuss various research ideas devoted to -discrepancy, strongly perfect graphs, the reconstruction conjectures, graph invariants, hereditary classes of graphs, embedding graphs on topological surfaces, as well as applications of graph theory ...
A labeling or a valuation of a graph is any mapping that sends a certain set of graph elements to a certain set of numbers subject to certain conditions. Please note that all submitted papers must be within the general scope of the Symmetry journal. Prof. Dr. Andrea Semaničová-Feňovčíková. Prof. Dr. Martin Bača.
Explore the latest full-text research PDFs, articles, conference papers, preprints and more on ALGEBRAIC GRAPH THEORY. Find methods information, sources, references or conduct a literature review ...
TheJournal of Graph Theory is a high-calibre graphs and combinatorics journal publishing rigorous research on how these areas interact with other mathematical sciences. Our editorial team of influential graph theorists welcome submissions on a range of graph theory topics, such as structural results about graphs, graph algorithms with ...
1 Introduction In this paper we will discuss how problems like Page ranking and finding the shortest paths can be solved by using Graph Theory. At its core, graph theory is the study of graphs as mathematical structures. In our paper, we will first cover Graph Theory as a broad topic. Then we will move on to Linear Algebra. Linear Algebra is the study of matrices. We will apply the skills ...
Abstract Recently, graph neural networks (GNNs) have become a hot topic in machine learning community. This paper presents a Scopus-based bibliometric overview of the GNNs' research since 2004 when GNN papers were first published. The study aims to evaluate GNN research trends, both quantitatively and qualitatively. We provide the trend of research, distribution of subjects, active and ...
The purpose of this Special Issue is to report and review recent developments concerning mathematical properties, methods of calculations, and applications of topological indices in any area of interest. Moreover, papers on other topics in chemical graph theory are also welcome. Manuscript Submission Information.
Explore the latest full-text research PDFs, articles, conference papers, preprints and more on SPECTRAL GRAPH THEORY. Find methods information, sources, references or conduct a literature review ...
The Journal of Graph Theory publishes high-calibre research on graph theory and combinatorics, and how these areas interact with other mathematical sciences.