Quantitative Data Analysis: A Comprehensive Guide
By: Ofem Eteng Published: May 18, 2022

Related Articles
A healthcare giant successfully introduces the most effective drug dosage through rigorous statistical modeling, saving countless lives. A marketing team predicts consumer trends with uncanny accuracy, tailoring campaigns for maximum impact.
Table of Contents
These trends and dosages are not just any numbers but are a result of meticulous quantitative data analysis. Quantitative data analysis offers a robust framework for understanding complex phenomena, evaluating hypotheses, and predicting future outcomes.
In this blog, we’ll walk through the concept of quantitative data analysis, the steps required, its advantages, and the methods and techniques that are used in this analysis. Read on!
What is Quantitative Data Analysis?
Quantitative data analysis is a systematic process of examining, interpreting, and drawing meaningful conclusions from numerical data. It involves the application of statistical methods, mathematical models, and computational techniques to understand patterns, relationships, and trends within datasets.
Quantitative data analysis methods typically work with algorithms, mathematical analysis tools, and software to gain insights from the data, answering questions such as how many, how often, and how much. Data for quantitative data analysis is usually collected from close-ended surveys, questionnaires, polls, etc. The data can also be obtained from sales figures, email click-through rates, number of website visitors, and percentage revenue increase.
Quantitative Data Analysis vs Qualitative Data Analysis
When we talk about data, we directly think about the pattern, the relationship, and the connection between the datasets – analyzing the data in short. Therefore when it comes to data analysis, there are broadly two types – Quantitative Data Analysis and Qualitative Data Analysis.
Quantitative data analysis revolves around numerical data and statistics, which are suitable for functions that can be counted or measured. In contrast, qualitative data analysis includes description and subjective information – for things that can be observed but not measured.
Let us differentiate between Quantitative Data Analysis and Quantitative Data Analysis for a better understanding.
Data Preparation Steps for Quantitative Data Analysis
Quantitative data has to be gathered and cleaned before proceeding to the stage of analyzing it. Below are the steps to prepare a data before quantitative research analysis:
- Step 1: Data Collection
Before beginning the analysis process, you need data. Data can be collected through rigorous quantitative research, which includes methods such as interviews, focus groups, surveys, and questionnaires.
- Step 2: Data Cleaning
Once the data is collected, begin the data cleaning process by scanning through the entire data for duplicates, errors, and omissions. Keep a close eye for outliers (data points that are significantly different from the majority of the dataset) because they can skew your analysis results if they are not removed.
This data-cleaning process ensures data accuracy, consistency and relevancy before analysis.
- Step 3: Data Analysis and Interpretation
Now that you have collected and cleaned your data, it is now time to carry out the quantitative analysis. There are two methods of quantitative data analysis, which we will discuss in the next section.
However, if you have data from multiple sources, collecting and cleaning it can be a cumbersome task. This is where Hevo Data steps in. With Hevo, extracting, transforming, and loading data from source to destination becomes a seamless task, eliminating the need for manual coding. This not only saves valuable time but also enhances the overall efficiency of data analysis and visualization, empowering users to derive insights quickly and with precision
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources (40+ free sources), we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
Start for free now!
Now that you are familiar with what quantitative data analysis is and how to prepare your data for analysis, the focus will shift to the purpose of this article, which is to describe the methods and techniques of quantitative data analysis.
Methods and Techniques of Quantitative Data Analysis
Quantitative data analysis employs two techniques to extract meaningful insights from datasets, broadly. The first method is descriptive statistics, which summarizes and portrays essential features of a dataset, such as mean, median, and standard deviation.
Inferential statistics, the second method, extrapolates insights and predictions from a sample dataset to make broader inferences about an entire population, such as hypothesis testing and regression analysis.
An in-depth explanation of both the methods is provided below:
- Descriptive Statistics
- Inferential Statistics
1) Descriptive Statistics
Descriptive statistics as the name implies is used to describe a dataset. It helps understand the details of your data by summarizing it and finding patterns from the specific data sample. They provide absolute numbers obtained from a sample but do not necessarily explain the rationale behind the numbers and are mostly used for analyzing single variables. The methods used in descriptive statistics include:
- Mean: This calculates the numerical average of a set of values.
- Median: This is used to get the midpoint of a set of values when the numbers are arranged in numerical order.
- Mode: This is used to find the most commonly occurring value in a dataset.
- Percentage: This is used to express how a value or group of respondents within the data relates to a larger group of respondents.
- Frequency: This indicates the number of times a value is found.
- Range: This shows the highest and lowest values in a dataset.
- Standard Deviation: This is used to indicate how dispersed a range of numbers is, meaning, it shows how close all the numbers are to the mean.
- Skewness: It indicates how symmetrical a range of numbers is, showing if they cluster into a smooth bell curve shape in the middle of the graph or if they skew towards the left or right.
2) Inferential Statistics
In quantitative analysis, the expectation is to turn raw numbers into meaningful insight using numerical values, and descriptive statistics is all about explaining details of a specific dataset using numbers, but it does not explain the motives behind the numbers; hence, a need for further analysis using inferential statistics.
Inferential statistics aim to make predictions or highlight possible outcomes from the analyzed data obtained from descriptive statistics. They are used to generalize results and make predictions between groups, show relationships that exist between multiple variables, and are used for hypothesis testing that predicts changes or differences.
There are various statistical analysis methods used within inferential statistics; a few are discussed below.
- Cross Tabulations: Cross tabulation or crosstab is used to show the relationship that exists between two variables and is often used to compare results by demographic groups. It uses a basic tabular form to draw inferences between different data sets and contains data that is mutually exclusive or has some connection with each other. Crosstabs help understand the nuances of a dataset and factors that may influence a data point.
- Regression Analysis: Regression analysis estimates the relationship between a set of variables. It shows the correlation between a dependent variable (the variable or outcome you want to measure or predict) and any number of independent variables (factors that may impact the dependent variable). Therefore, the purpose of the regression analysis is to estimate how one or more variables might affect a dependent variable to identify trends and patterns to make predictions and forecast possible future trends. There are many types of regression analysis, and the model you choose will be determined by the type of data you have for the dependent variable. The types of regression analysis include linear regression, non-linear regression, binary logistic regression, etc.
- Monte Carlo Simulation: Monte Carlo simulation, also known as the Monte Carlo method, is a computerized technique of generating models of possible outcomes and showing their probability distributions. It considers a range of possible outcomes and then tries to calculate how likely each outcome will occur. Data analysts use it to perform advanced risk analyses to help forecast future events and make decisions accordingly.
- Analysis of Variance (ANOVA): This is used to test the extent to which two or more groups differ from each other. It compares the mean of various groups and allows the analysis of multiple groups.
- Factor Analysis: A large number of variables can be reduced into a smaller number of factors using the factor analysis technique. It works on the principle that multiple separate observable variables correlate with each other because they are all associated with an underlying construct. It helps in reducing large datasets into smaller, more manageable samples.
- Cohort Analysis: Cohort analysis can be defined as a subset of behavioral analytics that operates from data taken from a given dataset. Rather than looking at all users as one unit, cohort analysis breaks down data into related groups for analysis, where these groups or cohorts usually have common characteristics or similarities within a defined period.
- MaxDiff Analysis: This is a quantitative data analysis method that is used to gauge customers’ preferences for purchase and what parameters rank higher than the others in the process.
- Cluster Analysis: Cluster analysis is a technique used to identify structures within a dataset. Cluster analysis aims to be able to sort different data points into groups that are internally similar and externally different; that is, data points within a cluster will look like each other and different from data points in other clusters.
- Time Series Analysis: This is a statistical analytic technique used to identify trends and cycles over time. It is simply the measurement of the same variables at different times, like weekly and monthly email sign-ups, to uncover trends, seasonality, and cyclic patterns. By doing this, the data analyst can forecast how variables of interest may fluctuate in the future.
- SWOT analysis: This is a quantitative data analysis method that assigns numerical values to indicate strengths, weaknesses, opportunities, and threats of an organization, product, or service to show a clearer picture of competition to foster better business strategies
How to Choose the Right Method for your Analysis?
Choosing between Descriptive Statistics or Inferential Statistics can be often confusing. You should consider the following factors before choosing the right method for your quantitative data analysis:
1. Type of Data
The first consideration in data analysis is understanding the type of data you have. Different statistical methods have specific requirements based on these data types, and using the wrong method can render results meaningless. The choice of statistical method should align with the nature and distribution of your data to ensure meaningful and accurate analysis.
2. Your Research Questions
When deciding on statistical methods, it’s crucial to align them with your specific research questions and hypotheses. The nature of your questions will influence whether descriptive statistics alone, which reveal sample attributes, are sufficient or if you need both descriptive and inferential statistics to understand group differences or relationships between variables and make population inferences.
Pros and Cons of Quantitative Data Analysis
1. Objectivity and Generalizability:
- Quantitative data analysis offers objective, numerical measurements, minimizing bias and personal interpretation.
- Results can often be generalized to larger populations, making them applicable to broader contexts.
Example: A study using quantitative data analysis to measure student test scores can objectively compare performance across different schools and demographics, leading to generalizable insights about educational strategies.
2. Precision and Efficiency:
- Statistical methods provide precise numerical results, allowing for accurate comparisons and prediction.
- Large datasets can be analyzed efficiently with the help of computer software, saving time and resources.
Example: A marketing team can use quantitative data analysis to precisely track click-through rates and conversion rates on different ad campaigns, quickly identifying the most effective strategies for maximizing customer engagement.
3. Identification of Patterns and Relationships:
- Statistical techniques reveal hidden patterns and relationships between variables that might not be apparent through observation alone.
- This can lead to new insights and understanding of complex phenomena.
Example: A medical researcher can use quantitative analysis to pinpoint correlations between lifestyle factors and disease risk, aiding in the development of prevention strategies.
1. Limited Scope:
- Quantitative analysis focuses on quantifiable aspects of a phenomenon , potentially overlooking important qualitative nuances, such as emotions, motivations, or cultural contexts.
Example: A survey measuring customer satisfaction with numerical ratings might miss key insights about the underlying reasons for their satisfaction or dissatisfaction, which could be better captured through open-ended feedback.
2. Oversimplification:
- Reducing complex phenomena to numerical data can lead to oversimplification and a loss of richness in understanding.
Example: Analyzing employee productivity solely through quantitative metrics like hours worked or tasks completed might not account for factors like creativity, collaboration, or problem-solving skills, which are crucial for overall performance.
3. Potential for Misinterpretation:
- Statistical results can be misinterpreted if not analyzed carefully and with appropriate expertise.
- The choice of statistical methods and assumptions can significantly influence results.
This blog discusses the steps, methods, and techniques of quantitative data analysis. It also gives insights into the methods of data collection, the type of data one should work with, and the pros and cons of such analysis.
Gain a better understanding of data analysis with these essential reads:
- Data Analysis and Modeling: 4 Critical Differences
- Exploratory Data Analysis Simplified 101
- 25 Best Data Analysis Tools in 2024
Carrying out successful data analysis requires prepping the data and making it analysis-ready. That is where Hevo steps in.
Want to give Hevo a try? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You may also have a look at the amazing Hevo price , which will assist you in selecting the best plan for your requirements.
Share your experience of understanding Quantitative Data Analysis in the comment section below! We would love to hear your thoughts.

Ofem is a freelance writer specializing in data-related topics, who has expertise in translating complex concepts. With a focus on data science, analytics, and emerging technologies.
No-code Data Pipeline for your Data Warehouse
- Data Analysis
- Data Warehouse
- Quantitative Data Analysis
Continue Reading
Sarad Mohanan
Best Data Reconciliation Tools: Complete Guide
Satyam Agrawal
What is Data Reconciliation? Everything to Know
Sarthak Bhardwaj
Data Observability vs Data Quality: Difference and Relationships Explored
I want to read this e-book.
Quantitative Data Analysis 101
The lingo, methods and techniques, explained simply.
By: Derek Jansen (MBA) and Kerryn Warren (PhD) | December 2020
Quantitative data analysis is one of those things that often strikes fear in students. It’s totally understandable – quantitative analysis is a complex topic, full of daunting lingo , like medians, modes, correlation and regression. Suddenly we’re all wishing we’d paid a little more attention in math class…
The good news is that while quantitative data analysis is a mammoth topic, gaining a working understanding of the basics isn’t that hard , even for those of us who avoid numbers and math . In this post, we’ll break quantitative analysis down into simple , bite-sized chunks so you can approach your research with confidence.

Overview: Quantitative Data Analysis 101
- What (exactly) is quantitative data analysis?
- When to use quantitative analysis
- How quantitative analysis works
The two “branches” of quantitative analysis
- Descriptive statistics 101
- Inferential statistics 101
- How to choose the right quantitative methods
- Recap & summary
What is quantitative data analysis?
Despite being a mouthful, quantitative data analysis simply means analysing data that is numbers-based – or data that can be easily “converted” into numbers without losing any meaning.
For example, category-based variables like gender, ethnicity, or native language could all be “converted” into numbers without losing meaning – for example, English could equal 1, French 2, etc.
This contrasts against qualitative data analysis, where the focus is on words, phrases and expressions that can’t be reduced to numbers. If you’re interested in learning about qualitative analysis, check out our post and video here .
What is quantitative analysis used for?
Quantitative analysis is generally used for three purposes.
- Firstly, it’s used to measure differences between groups . For example, the popularity of different clothing colours or brands.
- Secondly, it’s used to assess relationships between variables . For example, the relationship between weather temperature and voter turnout.
- And third, it’s used to test hypotheses in a scientifically rigorous way. For example, a hypothesis about the impact of a certain vaccine.
Again, this contrasts with qualitative analysis , which can be used to analyse people’s perceptions and feelings about an event or situation. In other words, things that can’t be reduced to numbers.
How does quantitative analysis work?
Well, since quantitative data analysis is all about analysing numbers , it’s no surprise that it involves statistics . Statistical analysis methods form the engine that powers quantitative analysis, and these methods can vary from pretty basic calculations (for example, averages and medians) to more sophisticated analyses (for example, correlations and regressions).
Sounds like gibberish? Don’t worry. We’ll explain all of that in this post. Importantly, you don’t need to be a statistician or math wiz to pull off a good quantitative analysis. We’ll break down all the technical mumbo jumbo in this post.
Need a helping hand?
As I mentioned, quantitative analysis is powered by statistical analysis methods . There are two main “branches” of statistical methods that are used – descriptive statistics and inferential statistics . In your research, you might only use descriptive statistics, or you might use a mix of both , depending on what you’re trying to figure out. In other words, depending on your research questions, aims and objectives . I’ll explain how to choose your methods later.
So, what are descriptive and inferential statistics?
Well, before I can explain that, we need to take a quick detour to explain some lingo. To understand the difference between these two branches of statistics, you need to understand two important words. These words are population and sample .
First up, population . In statistics, the population is the entire group of people (or animals or organisations or whatever) that you’re interested in researching. For example, if you were interested in researching Tesla owners in the US, then the population would be all Tesla owners in the US.
However, it’s extremely unlikely that you’re going to be able to interview or survey every single Tesla owner in the US. Realistically, you’ll likely only get access to a few hundred, or maybe a few thousand owners using an online survey. This smaller group of accessible people whose data you actually collect is called your sample .
So, to recap – the population is the entire group of people you’re interested in, and the sample is the subset of the population that you can actually get access to. In other words, the population is the full chocolate cake , whereas the sample is a slice of that cake.
So, why is this sample-population thing important?
Well, descriptive statistics focus on describing the sample , while inferential statistics aim to make predictions about the population, based on the findings within the sample. In other words, we use one group of statistical methods – descriptive statistics – to investigate the slice of cake, and another group of methods – inferential statistics – to draw conclusions about the entire cake. There I go with the cake analogy again…
With that out the way, let’s take a closer look at each of these branches in more detail.

Branch 1: Descriptive Statistics
Descriptive statistics serve a simple but critically important role in your research – to describe your data set – hence the name. In other words, they help you understand the details of your sample . Unlike inferential statistics (which we’ll get to soon), descriptive statistics don’t aim to make inferences or predictions about the entire population – they’re purely interested in the details of your specific sample .
When you’re writing up your analysis, descriptive statistics are the first set of stats you’ll cover, before moving on to inferential statistics. But, that said, depending on your research objectives and research questions , they may be the only type of statistics you use. We’ll explore that a little later.
So, what kind of statistics are usually covered in this section?
Some common statistical tests used in this branch include the following:
- Mean – this is simply the mathematical average of a range of numbers.
- Median – this is the midpoint in a range of numbers when the numbers are arranged in numerical order. If the data set makes up an odd number, then the median is the number right in the middle of the set. If the data set makes up an even number, then the median is the midpoint between the two middle numbers.
- Mode – this is simply the most commonly occurring number in the data set.
- In cases where most of the numbers are quite close to the average, the standard deviation will be relatively low.
- Conversely, in cases where the numbers are scattered all over the place, the standard deviation will be relatively high.
- Skewness . As the name suggests, skewness indicates how symmetrical a range of numbers is. In other words, do they tend to cluster into a smooth bell curve shape in the middle of the graph, or do they skew to the left or right?
Feeling a bit confused? Let’s look at a practical example using a small data set.

On the left-hand side is the data set. This details the bodyweight of a sample of 10 people. On the right-hand side, we have the descriptive statistics. Let’s take a look at each of them.
First, we can see that the mean weight is 72.4 kilograms. In other words, the average weight across the sample is 72.4 kilograms. Straightforward.
Next, we can see that the median is very similar to the mean (the average). This suggests that this data set has a reasonably symmetrical distribution (in other words, a relatively smooth, centred distribution of weights, clustered towards the centre).
In terms of the mode , there is no mode in this data set. This is because each number is present only once and so there cannot be a “most common number”. If there were two people who were both 65 kilograms, for example, then the mode would be 65.
Next up is the standard deviation . 10.6 indicates that there’s quite a wide spread of numbers. We can see this quite easily by looking at the numbers themselves, which range from 55 to 90, which is quite a stretch from the mean of 72.4.
And lastly, the skewness of -0.2 tells us that the data is very slightly negatively skewed. This makes sense since the mean and the median are slightly different.
As you can see, these descriptive statistics give us some useful insight into the data set. Of course, this is a very small data set (only 10 records), so we can’t read into these statistics too much. Also, keep in mind that this is not a list of all possible descriptive statistics – just the most common ones.
But why do all of these numbers matter?
While these descriptive statistics are all fairly basic, they’re important for a few reasons:
- Firstly, they help you get both a macro and micro-level view of your data. In other words, they help you understand both the big picture and the finer details.
- Secondly, they help you spot potential errors in the data – for example, if an average is way higher than you’d expect, or responses to a question are highly varied, this can act as a warning sign that you need to double-check the data.
- And lastly, these descriptive statistics help inform which inferential statistical techniques you can use, as those techniques depend on the skewness (in other words, the symmetry and normality) of the data.
Simply put, descriptive statistics are really important , even though the statistical techniques used are fairly basic. All too often at Grad Coach, we see students skimming over the descriptives in their eagerness to get to the more exciting inferential methods, and then landing up with some very flawed results.
Don’t be a sucker – give your descriptive statistics the love and attention they deserve!

Branch 2: Inferential Statistics
As I mentioned, while descriptive statistics are all about the details of your specific data set – your sample – inferential statistics aim to make inferences about the population . In other words, you’ll use inferential statistics to make predictions about what you’d expect to find in the full population.
What kind of predictions, you ask? Well, there are two common types of predictions that researchers try to make using inferential stats:
- Firstly, predictions about differences between groups – for example, height differences between children grouped by their favourite meal or gender.
- And secondly, relationships between variables – for example, the relationship between body weight and the number of hours a week a person does yoga.
In other words, inferential statistics (when done correctly), allow you to connect the dots and make predictions about what you expect to see in the real world population, based on what you observe in your sample data. For this reason, inferential statistics are used for hypothesis testing – in other words, to test hypotheses that predict changes or differences.

Of course, when you’re working with inferential statistics, the composition of your sample is really important. In other words, if your sample doesn’t accurately represent the population you’re researching, then your findings won’t necessarily be very useful.
For example, if your population of interest is a mix of 50% male and 50% female , but your sample is 80% male , you can’t make inferences about the population based on your sample, since it’s not representative. This area of statistics is called sampling, but we won’t go down that rabbit hole here (it’s a deep one!) – we’ll save that for another post .
What statistics are usually used in this branch?
There are many, many different statistical analysis methods within the inferential branch and it’d be impossible for us to discuss them all here. So we’ll just take a look at some of the most common inferential statistical methods so that you have a solid starting point.
First up are T-Tests . T-tests compare the means (the averages) of two groups of data to assess whether they’re statistically significantly different. In other words, do they have significantly different means, standard deviations and skewness.
This type of testing is very useful for understanding just how similar or different two groups of data are. For example, you might want to compare the mean blood pressure between two groups of people – one that has taken a new medication and one that hasn’t – to assess whether they are significantly different.
Kicking things up a level, we have ANOVA, which stands for “analysis of variance”. This test is similar to a T-test in that it compares the means of various groups, but ANOVA allows you to analyse multiple groups , not just two groups So it’s basically a t-test on steroids…
Next, we have correlation analysis . This type of analysis assesses the relationship between two variables. In other words, if one variable increases, does the other variable also increase, decrease or stay the same. For example, if the average temperature goes up, do average ice creams sales increase too? We’d expect some sort of relationship between these two variables intuitively , but correlation analysis allows us to measure that relationship scientifically .
Lastly, we have regression analysis – this is quite similar to correlation in that it assesses the relationship between variables, but it goes a step further to understand cause and effect between variables, not just whether they move together. In other words, does the one variable actually cause the other one to move, or do they just happen to move together naturally thanks to another force? Just because two variables correlate doesn’t necessarily mean that one causes the other.
Stats overload…
I hear you. To make this all a little more tangible, let’s take a look at an example of a correlation in action.
Here’s a scatter plot demonstrating the correlation (relationship) between weight and height. Intuitively, we’d expect there to be some relationship between these two variables, which is what we see in this scatter plot. In other words, the results tend to cluster together in a diagonal line from bottom left to top right.

As I mentioned, these are are just a handful of inferential techniques – there are many, many more. Importantly, each statistical method has its own assumptions and limitations.
For example, some methods only work with normally distributed (parametric) data, while other methods are designed specifically for non-parametric data. And that’s exactly why descriptive statistics are so important – they’re the first step to knowing which inferential techniques you can and can’t use.

How to choose the right analysis method
To choose the right statistical methods, you need to think about two important factors :
- The type of quantitative data you have (specifically, level of measurement and the shape of the data). And,
- Your research questions and hypotheses
Let’s take a closer look at each of these.
Factor 1 – Data type
The first thing you need to consider is the type of data you’ve collected (or the type of data you will collect). By data types, I’m referring to the four levels of measurement – namely, nominal, ordinal, interval and ratio. If you’re not familiar with this lingo, check out the video below.
Why does this matter?
Well, because different statistical methods and techniques require different types of data. This is one of the “assumptions” I mentioned earlier – every method has its assumptions regarding the type of data.
For example, some techniques work with categorical data (for example, yes/no type questions, or gender or ethnicity), while others work with continuous numerical data (for example, age, weight or income) – and, of course, some work with multiple data types.
If you try to use a statistical method that doesn’t support the data type you have, your results will be largely meaningless . So, make sure that you have a clear understanding of what types of data you’ve collected (or will collect). Once you have this, you can then check which statistical methods would support your data types here .
If you haven’t collected your data yet, you can work in reverse and look at which statistical method would give you the most useful insights, and then design your data collection strategy to collect the correct data types.
Another important factor to consider is the shape of your data . Specifically, does it have a normal distribution (in other words, is it a bell-shaped curve, centred in the middle) or is it very skewed to the left or the right? Again, different statistical techniques work for different shapes of data – some are designed for symmetrical data while others are designed for skewed data.
This is another reminder of why descriptive statistics are so important – they tell you all about the shape of your data.
Factor 2: Your research questions
The next thing you need to consider is your specific research questions, as well as your hypotheses (if you have some). The nature of your research questions and research hypotheses will heavily influence which statistical methods and techniques you should use.
If you’re just interested in understanding the attributes of your sample (as opposed to the entire population), then descriptive statistics are probably all you need. For example, if you just want to assess the means (averages) and medians (centre points) of variables in a group of people.
On the other hand, if you aim to understand differences between groups or relationships between variables and to infer or predict outcomes in the population, then you’ll likely need both descriptive statistics and inferential statistics.
So, it’s really important to get very clear about your research aims and research questions, as well your hypotheses – before you start looking at which statistical techniques to use.
Never shoehorn a specific statistical technique into your research just because you like it or have some experience with it. Your choice of methods must align with all the factors we’ve covered here.
Time to recap…
You’re still with me? That’s impressive. We’ve covered a lot of ground here, so let’s recap on the key points:
- Quantitative data analysis is all about analysing number-based data (which includes categorical and numerical data) using various statistical techniques.
- The two main branches of statistics are descriptive statistics and inferential statistics . Descriptives describe your sample, whereas inferentials make predictions about what you’ll find in the population.
- Common descriptive statistical methods include mean (average), median , standard deviation and skewness .
- Common inferential statistical methods include t-tests , ANOVA , correlation and regression analysis.
- To choose the right statistical methods and techniques, you need to consider the type of data you’re working with , as well as your research questions and hypotheses.

Psst… there’s more (for free)
This post is part of our dissertation mini-course, which covers everything you need to get started with your dissertation, thesis or research project.
You Might Also Like:
")
74 Comments

Hi, I have read your article. Such a brilliant post you have created.

Thank you for the feedback. Good luck with your quantitative analysis.

Thank you so much.

Thank you so much. I learnt much well. I love your summaries of the concepts. I had love you to explain how to input data using SPSS

Amazing and simple way of breaking down quantitative methods.

This is beautiful….especially for non-statisticians. I have skimmed through but I wish to read again. and please include me in other articles of the same nature when you do post. I am interested. I am sure, I could easily learn from you and get off the fear that I have had in the past. Thank you sincerely.

Send me every new information you might have.

i need every new information

Thank you for the blog. It is quite informative. Dr Peter Nemaenzhe PhD

It is wonderful. l’ve understood some of the concepts in a more compréhensive manner

Your article is so good! However, I am still a bit lost. I am doing a secondary research on Gun control in the US and increase in crime rates and I am not sure which analysis method I should use?

Based on the given learning points, this is inferential analysis, thus, use ‘t-tests, ANOVA, correlation and regression analysis’

Well explained notes. Am an MPH student and currently working on my thesis proposal, this has really helped me understand some of the things I didn’t know.

I like your page..helpful

wonderful i got my concept crystal clear. thankyou!!

This is really helpful , thank you

Thank you so much this helped

Wonderfully explained

thank u so much, it was so informative

THANKYOU, this was very informative and very helpful

This is great GRADACOACH I am not a statistician but I require more of this in my thesis
Include me in your posts.

This is so great and fully useful. I would like to thank you again and again.

Glad to read this article. I’ve read lot of articles but this article is clear on all concepts. Thanks for sharing.

Thank you so much. This is a very good foundation and intro into quantitative data analysis. Appreciate!

You have a very impressive, simple but concise explanation of data analysis for Quantitative Research here. This is a God-send link for me to appreciate research more. Thank you so much!

Avery good presentation followed by the write up. yes you simplified statistics to make sense even to a layman like me. Thank so much keep it up. The presenter did ell too. i would like more of this for Qualitative and exhaust more of the test example like the Anova.

This is a very helpful article, couldn’t have been clearer. Thank you.

Awesome and phenomenal information.Well done

The video with the accompanying article is super helpful to demystify this topic. Very well done. Thank you so much.

thank you so much, your presentation helped me a lot

I don’t know how should I express that ur article is saviour for me 🥺😍

It is well defined information and thanks for sharing. It helps me a lot in understanding the statistical data.

I gain a lot and thanks for sharing brilliant ideas, so wish to be linked on your email update.

Very helpful and clear .Thank you Gradcoach.

Thank for sharing this article, well organized and information presented are very clear.

VERY INTERESTING AND SUPPORTIVE TO NEW RESEARCHERS LIKE ME. AT LEAST SOME BASICS ABOUT QUANTITATIVE.

An outstanding, well explained and helpful article. This will help me so much with my data analysis for my research project. Thank you!

wow this has just simplified everything i was scared of how i am gonna analyse my data but thanks to you i will be able to do so

simple and constant direction to research. thanks

This is helpful

Great writing!! Comprehensive and very helpful.

Do you provide any assistance for other steps of research methodology like making research problem testing hypothesis report and thesis writing?

Thank you so much for such useful article!

Amazing article. So nicely explained. Wow

Very insightfull. Thanks

I am doing a quality improvement project to determine if the implementation of a protocol will change prescribing habits. Would this be a t-test?

The is a very helpful blog, however, I’m still not sure how to analyze my data collected. I’m doing a research on “Free Education at the University of Guyana”

tnx. fruitful blog!

So I am writing exams and would like to know how do establish which method of data analysis to use from the below research questions: I am a bit lost as to how I determine the data analysis method from the research questions.
Do female employees report higher job satisfaction than male employees with similar job descriptions across the South African telecommunications sector? – I though that maybe Chi Square could be used here. – Is there a gender difference in talented employees’ actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – Is there a gender difference in the cost of actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – What practical recommendations can be made to the management of South African telecommunications companies on leveraging gender to mitigate employee turnover decisions?
Your assistance will be appreciated if I could get a response as early as possible tomorrow

This was quite helpful. Thank you so much.

wow I got a lot from this article, thank you very much, keep it up

Thanks for yhe guidance. Can you send me this guidance on my email? To enable offline reading?

Thank you very much, this service is very helpful.

Every novice researcher needs to read this article as it puts things so clear and easy to follow. Its been very helpful.

Wonderful!!!! you explained everything in a way that anyone can learn. Thank you!!

I really enjoyed reading though this. Very easy to follow. Thank you

Many thanks for your useful lecture, I would be really appreciated if you could possibly share with me the PPT of presentation related to Data type?

Thank you very much for sharing, I got much from this article

This is a very informative write-up. Kindly include me in your latest posts.

Very interesting mostly for social scientists

Thank you so much, very helpfull
You’re welcome 🙂

woow, its great, its very informative and well understood because of your way of writing like teaching in front of me in simple languages.

I have been struggling to understand a lot of these concepts. Thank you for the informative piece which is written with outstanding clarity.

very informative article. Easy to understand

Beautiful read, much needed.

Always greet intro and summary. I learn so much from GradCoach

Quite informative. Simple and clear summary.

I thoroughly enjoyed reading your informative and inspiring piece. Your profound insights into this topic truly provide a better understanding of its complexity. I agree with the points you raised, especially when you delved into the specifics of the article. In my opinion, that aspect is often overlooked and deserves further attention.

Absolutely!!! Thank you

Thank you very much for this post. It made me to understand how to do my data analysis.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
8 Types of Data Analysis

Data analysis is an aspect of data science and data analytics that is all about analyzing data for different kinds of purposes. The data analysis process involves inspecting, cleaning, transforming and modeling data to draw useful insights from it.
What Are the Different Types of Data Analysis?
- Descriptive analysis
- Diagnostic analysis
- Exploratory analysis
- Inferential analysis
- Predictive analysis
- Causal analysis
- Mechanistic analysis
- Prescriptive analysis
With its multiple facets, methodologies and techniques, data analysis is used in a variety of fields, including business, science and social science, among others. As businesses thrive under the influence of technological advancements in data analytics, data analysis plays a huge role in decision-making , providing a better, faster and more efficacious system that minimizes risks and reduces human biases .
That said, there are different kinds of data analysis catered with different goals. We’ll examine each one below.
Two Camps of Data Analysis
Data analysis can be divided into two camps, according to the book R for Data Science :
- Hypothesis Generation — This involves looking deeply at the data and combining your domain knowledge to generate hypotheses about why the data behaves the way it does.
- Hypothesis Confirmation — This involves using a precise mathematical model to generate falsifiable predictions with statistical sophistication to confirm your prior hypotheses.
Types of Data Analysis
Data analysis can be separated and organized into types, arranged in an increasing order of complexity.
1. Descriptive Analysis
The goal of descriptive analysis is to describe or summarize a set of data. Here’s what you need to know:
- Descriptive analysis is the very first analysis performed in the data analysis process.
- It generates simple summaries about samples and measurements.
- It involves common, descriptive statistics like measures of central tendency, variability, frequency and position.
Descriptive Analysis Example
Take the Covid-19 statistics page on Google, for example. The line graph is a pure summary of the cases/deaths, a presentation and description of the population of a particular country infected by the virus.
Descriptive analysis is the first step in analysis where you summarize and describe the data you have using descriptive statistics, and the result is a simple presentation of your data.
More on Data Analysis: Data Analyst vs. Data Scientist: Similarities and Differences Explained
2. Diagnostic Analysis
Diagnostic analysis seeks to answer the question “Why did this happen?” by taking a more in-depth look at data to uncover subtle patterns. Here’s what you need to know:
- Diagnostic analysis typically comes after descriptive analysis, taking initial findings and investigating why certain patterns in data happen.
- Diagnostic analysis may involve analyzing other related data sources, including past data, to reveal more insights into current data trends.
- Diagnostic analysis is ideal for further exploring patterns in data to explain anomalies.
Diagnostic Analysis Example
A footwear store wants to review its website traffic levels over the previous 12 months. Upon compiling and assessing the data, the company’s marketing team finds that June experienced above-average levels of traffic while July and August witnessed slightly lower levels of traffic.
To find out why this difference occurred, the marketing team takes a deeper look. Team members break down the data to focus on specific categories of footwear. In the month of June, they discovered that pages featuring sandals and other beach-related footwear received a high number of views while these numbers dropped in July and August.
Marketers may also review other factors like seasonal changes and company sales events to see if other variables could have contributed to this trend.
3. Exploratory Analysis (EDA)
Exploratory analysis involves examining or exploring data and finding relationships between variables that were previously unknown. Here’s what you need to know:
- EDA helps you discover relationships between measures in your data, which are not evidence for the existence of the correlation, as denoted by the phrase, “ Correlation doesn’t imply causation .”
- It’s useful for discovering new connections and forming hypotheses. It drives design planning and data collection.
Exploratory Analysis Example
Climate change is an increasingly important topic as the global temperature has gradually risen over the years. One example of an exploratory data analysis on climate change involves taking the rise in temperature over the years from 1950 to 2020 and the increase of human activities and industrialization to find relationships from the data. For example, you may increase the number of factories, cars on the road and airplane flights to see how that correlates with the rise in temperature.
Exploratory analysis explores data to find relationships between measures without identifying the cause. It’s most useful when formulating hypotheses.
4. Inferential Analysis
Inferential analysis involves using a small sample of data to infer information about a larger population of data.
The goal of statistical modeling itself is all about using a small amount of information to extrapolate and generalize information to a larger group. Here’s what you need to know:
- Inferential analysis involves using estimated data that is representative of a population and gives a measure of uncertainty or standard deviation to your estimation.
- The accuracy of inference depends heavily on your sampling scheme. If the sample isn’t representative of the population, the generalization will be inaccurate. This is known as the central limit theorem .
Inferential Analysis Example
The idea of drawing an inference about the population at large with a smaller sample size is intuitive. Many statistics you see on the media and the internet are inferential; a prediction of an event based on a small sample. For example, a psychological study on the benefits of sleep might have a total of 500 people involved. When they followed up with the candidates, the candidates reported to have better overall attention spans and well-being with seven-to-nine hours of sleep, while those with less sleep and more sleep than the given range suffered from reduced attention spans and energy. This study drawn from 500 people was just a tiny portion of the 7 billion people in the world, and is thus an inference of the larger population.
Inferential analysis extrapolates and generalizes the information of the larger group with a smaller sample to generate analysis and predictions.
5. Predictive Analysis
Predictive analysis involves using historical or current data to find patterns and make predictions about the future. Here’s what you need to know:
- The accuracy of the predictions depends on the input variables.
- Accuracy also depends on the types of models. A linear model might work well in some cases, and in other cases it might not.
- Using a variable to predict another one doesn’t denote a causal relationship.
Predictive Analysis Example
The 2020 US election is a popular topic and many prediction models are built to predict the winning candidate. FiveThirtyEight did this to forecast the 2016 and 2020 elections. Prediction analysis for an election would require input variables such as historical polling data, trends and current polling data in order to return a good prediction. Something as large as an election wouldn’t just be using a linear model, but a complex model with certain tunings to best serve its purpose.
Predictive analysis takes data from the past and present to make predictions about the future.
More on Data: Explaining the Empirical for Normal Distribution
6. Causal Analysis
Causal analysis looks at the cause and effect of relationships between variables and is focused on finding the cause of a correlation. Here’s what you need to know:
- To find the cause, you have to question whether the observed correlations driving your conclusion are valid. Just looking at the surface data won’t help you discover the hidden mechanisms underlying the correlations.
- Causal analysis is applied in randomized studies focused on identifying causation.
- Causal analysis is the gold standard in data analysis and scientific studies where the cause of phenomenon is to be extracted and singled out, like separating wheat from chaff.
- Good data is hard to find and requires expensive research and studies. These studies are analyzed in aggregate (multiple groups), and the observed relationships are just average effects (mean) of the whole population. This means the results might not apply to everyone.
Causal Analysis Example
Say you want to test out whether a new drug improves human strength and focus. To do that, you perform randomized control trials for the drug to test its effect. You compare the sample of candidates for your new drug against the candidates receiving a mock control drug through a few tests focused on strength and overall focus and attention. This will allow you to observe how the drug affects the outcome.
Causal analysis is about finding out the causal relationship between variables, and examining how a change in one variable affects another.
7. Mechanistic Analysis
Mechanistic analysis is used to understand exact changes in variables that lead to other changes in other variables. Here’s what you need to know:
- It’s applied in physical or engineering sciences, situations that require high precision and little room for error, only noise in data is measurement error.
- It’s designed to understand a biological or behavioral process, the pathophysiology of a disease or the mechanism of action of an intervention.
Mechanistic Analysis Example
Many graduate-level research and complex topics are suitable examples, but to put it in simple terms, let’s say an experiment is done to simulate safe and effective nuclear fusion to power the world. A mechanistic analysis of the study would entail a precise balance of controlling and manipulating variables with highly accurate measures of both variables and the desired outcomes. It’s this intricate and meticulous modus operandi toward these big topics that allows for scientific breakthroughs and advancement of society.
Mechanistic analysis is in some ways a predictive analysis, but modified to tackle studies that require high precision and meticulous methodologies for physical or engineering science .
8. Prescriptive Analysis
Prescriptive analysis compiles insights from other previous data analyses and determines actions that teams or companies can take to prepare for predicted trends. Here’s what you need to know:
- Prescriptive analysis may come right after predictive analysis, but it may involve combining many different data analyses.
- Companies need advanced technology and plenty of resources to conduct prescriptive analysis. AI systems that process data and adjust automated tasks are an example of the technology required to perform prescriptive analysis.
Prescriptive Analysis Example
Prescriptive analysis is pervasive in everyday life, driving the curated content users consume on social media. On platforms like TikTok and Instagram, algorithms can apply prescriptive analysis to review past content a user has engaged with and the kinds of behaviors they exhibited with specific posts. Based on these factors, an algorithm seeks out similar content that is likely to elicit the same response and recommends it on a user’s personal feed.
When to Use the Different Types of Data Analysis
- Descriptive analysis summarizes the data at hand and presents your data in a comprehensible way.
- Diagnostic analysis takes a more detailed look at data to reveal why certain patterns occur, making it a good method for explaining anomalies.
- Exploratory data analysis helps you discover correlations and relationships between variables in your data.
- Inferential analysis is for generalizing the larger population with a smaller sample size of data.
- Predictive analysis helps you make predictions about the future with data.
- Causal analysis emphasizes finding the cause of a correlation between variables.
- Mechanistic analysis is for measuring the exact changes in variables that lead to other changes in other variables.
- Prescriptive analysis combines insights from different data analyses to develop a course of action teams and companies can take to capitalize on predicted outcomes.
A few important tips to remember about data analysis include:
- Correlation doesn’t imply causation.
- EDA helps discover new connections and form hypotheses.
- Accuracy of inference depends on the sampling scheme.
- A good prediction depends on the right input variables.
- A simple linear model with enough data usually does the trick.
- Using a variable to predict another doesn’t denote causal relationships.
- Good data is hard to find, and to produce it requires expensive research.
- Results from studies are done in aggregate and are average effects and might not apply to everyone.
Built In’s expert contributor network publishes thoughtful, solutions-oriented stories written by innovative tech professionals. It is the tech industry’s definitive destination for sharing compelling, first-person accounts of problem-solving on the road to innovation.
Great Companies Need Great People. That's Where We Come In.
Learn / Guides / Quantitative data analysis guide
Back to guides
8 quantitative data analysis methods to turn numbers into insights
Setting up a few new customer surveys or creating a fresh Google Analytics dashboard feels exciting…until the numbers start rolling in. You want to turn responses into a plan to present to your team and leaders—but which quantitative data analysis method do you use to make sense of the facts and figures?
Last updated
Reading time.

This guide lists eight quantitative research data analysis techniques to help you turn numeric feedback into actionable insights to share with your team and make customer-centric decisions.
To pick the right technique that helps you bridge the gap between data and decision-making, you first need to collect quantitative data from sources like:
Google Analytics
Survey results
On-page feedback scores
Fuel your quantitative analysis with real-time data
Use Hotjar’s tools to collect quantitative data that helps you stay close to customers.
Then, choose an analysis method based on the type of data and how you want to use it.
Descriptive data analysis summarizes results—like measuring website traffic—that help you learn about a problem or opportunity. The descriptive analysis methods we’ll review are:
Multiple choice response rates
Response volume over time
Net Promoter Score®
Inferential data analyzes the relationship between data—like which customer segment has the highest average order value—to help you make hypotheses about product decisions. Inferential analysis methods include:
Cross-tabulation
Weighted customer feedback
You don’t need to worry too much about these specific terms since each quantitative data analysis method listed below explains when and how to use them. Let’s dive in!
1. Compare multiple-choice response rates
The simplest way to analyze survey data is by comparing the percentage of your users who chose each response, which summarizes opinions within your audience.
To do this, divide the number of people who chose a specific response by the total respondents for your multiple-choice survey. Imagine 100 customers respond to a survey about what product category they want to see. If 25 people said ‘snacks’, 25% of your audience favors that category, so you know that adding a snacks category to your list of filters or drop-down menu will make the purchasing process easier for them.
💡Pro tip: ask open-ended survey questions to dig deeper into customer motivations.
A multiple-choice survey measures your audience’s opinions, but numbers don’t tell you why they think the way they do—you need to combine quantitative and qualitative data to learn that.
One research method to learn about customer motivations is through an open-ended survey question. Giving customers space to express their thoughts in their own words—unrestricted by your pre-written multiple-choice questions—prevents you from making assumptions.
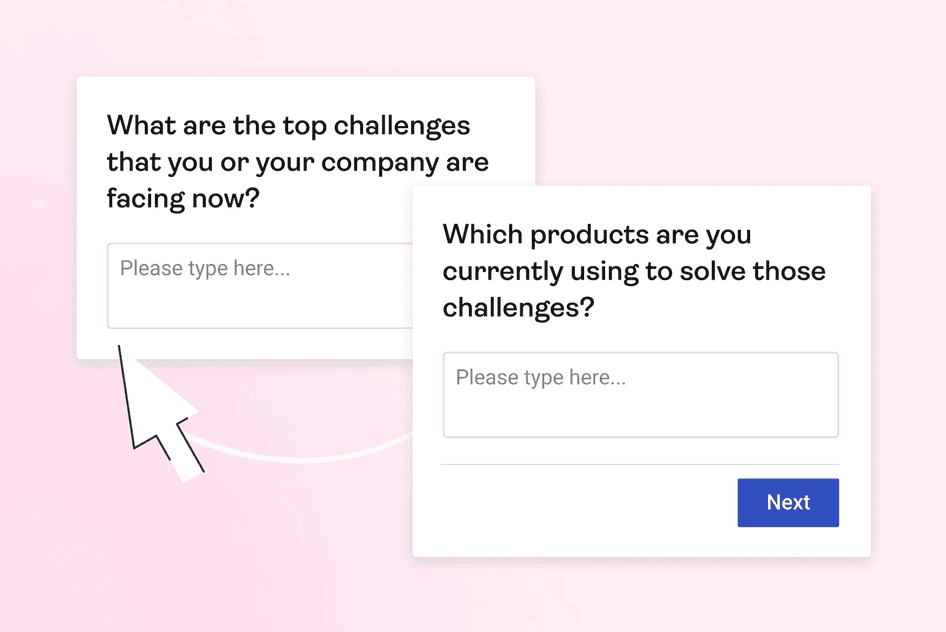
Hotjar’s open-ended surveys have a text box for customers to type a response
2. Cross-tabulate to compare responses between groups
To understand how responses and behavior vary within your audience, compare your quantitative data by group. Use raw numbers, like the number of website visitors, or percentages, like questionnaire responses, across categories like traffic sources or customer segments.

Let’s say you ask your audience what their most-used feature is because you want to know what to highlight on your pricing page. Comparing the most common response for free trial users vs. established customers lets you strategically introduce features at the right point in the customer journey .
💡Pro tip: get some face-to-face time to discover nuances in customer feedback.
Rather than treating your customers as a monolith, use Hotjar to conduct interviews to learn about individuals and subgroups. If you aren’t sure what to ask, start with your quantitative data results. If you notice competing trends between customer segments, have a few conversations with individuals from each group to dig into their unique motivations.
Hotjar Engage lets you identify specific customer segments you want to talk to
Mode is the most common answer in a data set, which means you use it to discover the most popular response for questions with numeric answer options. Mode and median (that's next on the list) are useful to compare to the average in case responses on extreme ends of the scale (outliers) skew the outcome.
Let’s say you want to know how most customers feel about your website, so you use an on-page feedback widget to collect ratings on a scale of one to five.

If the mode, or most common response, is a three, you can assume most people feel somewhat positive. But suppose the second-most common response is a one (which would bring the average down). In that case, you need to investigate why so many customers are unhappy.
💡Pro tip: watch recordings to understand how customers interact with your website.
So you used on-page feedback to learn how customers feel about your website, and the mode was two out of five. Ouch. Use Hotjar Recordings to see how customers move around on and interact with your pages to find the source of frustration.
Hotjar Recordings lets you watch individual visitors interact with your site, like how they scroll, hover, and click
Median reveals the middle of the road of your quantitative data by lining up all numeric values in ascending order and then looking at the data point in the middle. Use the median method when you notice a few outliers that bring the average up or down and compare the analysis outcomes.
For example, if your price sensitivity survey has outlandish responses and you want to identify a reasonable middle ground of what customers are willing to pay—calculate the median.
💡Pro-tip: review and clean your data before analysis.
Take a few minutes to familiarize yourself with quantitative data results before you push them through analysis methods. Inaccurate or missing information can complicate your calculations, and it’s less frustrating to resolve issues at the start instead of problem-solving later.
Here are a few data-cleaning tips to keep in mind:
Remove or separate irrelevant data, like responses from a customer segment or time frame you aren’t reviewing right now
Standardize data from multiple sources, like a survey that let customers indicate they use your product ‘daily’ vs. on-page feedback that used the phrasing ‘more than once a week’
Acknowledge missing data, like some customers not answering every question. Just note that your totals between research questions might not match.
Ensure you have enough responses to have a statistically significant result
Decide if you want to keep or remove outlying data. For example, maybe there’s evidence to support a high-price tier, and you shouldn’t dismiss less price-sensitive respondents. Other times, you might want to get rid of obviously trolling responses.
5. Mean (AKA average)
Finding the average of a dataset is an essential quantitative data analysis method and an easy task. First, add all your quantitative data points, like numeric survey responses or daily sales revenue. Then, divide the sum of your data points by the number of responses to get a single number representing the entire dataset.
Use the average of your quant data when you want a summary, like the average order value of your transactions between different sales pages. Then, use your average to benchmark performance, compare over time, or uncover winners across segments—like which sales page design produces the most value.
💡Pro tip: use heatmaps to find attention-catching details numbers can’t give you.
Calculating the average of your quant data set reveals the outcome of customer interactions. However, you need qualitative data like a heatmap to learn about everything that led to that moment. A heatmap uses colors to illustrate where most customers look and click on a page to reveal what drives (or drops) momentum.
Hotjar Heatmaps uses color to visualize what most visitors see, ignore, and click on
6. Measure the volume of responses over time
Some quantitative data analysis methods are an ongoing project, like comparing top website referral sources by month to gauge the effectiveness of new channels. Analyzing the same metric at regular intervals lets you compare trends and changes.
Look at quantitative survey results, website sessions, sales, cart abandons, or clicks regularly to spot trouble early or monitor the impact of a new initiative.
Here are a few areas you can measure over time (and how to use qualitative research methods listed above to add context to your results):
7. Net Promoter Score®
Net Promoter Score® ( NPS ®) is a popular customer loyalty and satisfaction measurement that also serves as a quantitative data analysis method.
NPS surveys ask customers to rate how likely they are to recommend you on a scale of zero to ten. Calculate it by subtracting the percentage of customers who answer the NPS question with a six or lower (known as ‘detractors’) from those who respond with a nine or ten (known as ‘promoters’). Your NPS score will fall between -100 and 100, and you want a positive number indicating more promoters than detractors.

💡Pro tip : like other quantitative data analysis methods, you can review NPS scores over time as a satisfaction benchmark. You can also use it to understand which customer segment is most satisfied or which customers may be willing to share their stories for promotional materials.
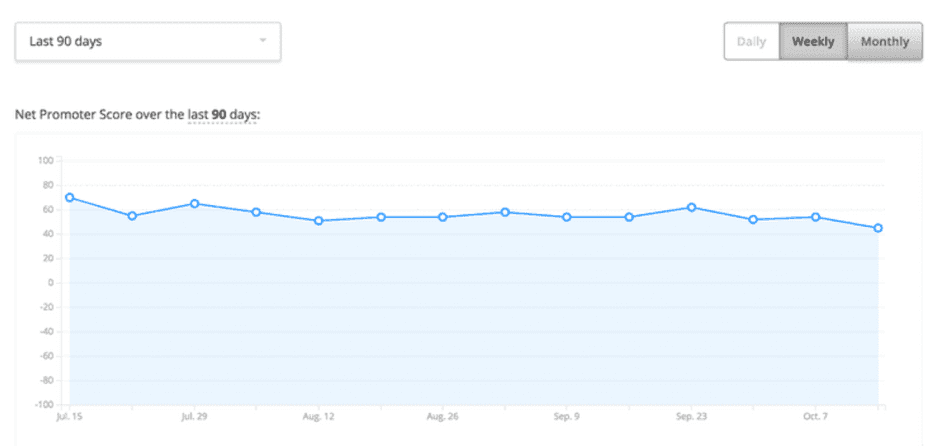
Review NPS score trends with Hotjar to spot any sudden spikes and benchmark performance over time
8. Weight customer feedback
So far, the quantitative data analysis methods on this list have leveraged numeric data only. However, there are ways to turn qualitative data into quantifiable feedback and to mix and match data sources. For example, you might need to analyze user feedback from multiple surveys.
To leverage multiple data points, create a prioritization matrix that assigns ‘weight’ to customer feedback data and company priorities and then multiply them to reveal the highest-scoring option.
Let’s say you identify the top four responses to your churn survey . Rate the most common issue as a four and work down the list until one—these are your customer priorities. Then, rate the ease of fixing each problem with a maximum score of four for the easy wins down to one for difficult tasks—these are your company priorities. Finally, multiply the score of each customer priority with its coordinating company priority scores and lead with the highest scoring idea.
💡Pro-tip: use a product prioritization framework to make decisions.
Try a product prioritization framework when the pressure is on to make high-impact decisions with limited time and budget. These repeatable decision-making tools take the guesswork out of balancing goals, customer priorities, and team resources. Four popular frameworks are:
RICE: weighs four factors—reach, impact, confidence, and effort—to weigh initiatives differently
MoSCoW: considers stakeholder opinions on 'must-have', 'should-have', 'could-have', and 'won't-have' criteria
Kano: ranks ideas based on how likely they are to satisfy customer needs
Cost of delay analysis: determines potential revenue loss by not working on a product or initiative
Share what you learn with data visuals
Data visualization through charts and graphs gives you a new perspective on your results. Plus, removing the clutter of the analysis process helps you and stakeholders focus on the insight over the method.
Data visualization helps you:
Get buy-in with impactful charts that summarize your results
Increase customer empathy and awareness across your company with digestible insights
Use these four data visualization types to illustrate what you learned from your quantitative data analysis:
Bar charts reveal response distribution across multiple options
Line graphs compare data points over time
Scatter plots showcase how two variables interact
Matrices contrast data between categories like customer segments, product types, or traffic source

Use a variety of customer feedback types to get the whole picture
Quantitative data analysis pulls the story out of raw numbers—but you shouldn’t take a single result from your data collection and run with it. Instead, combine numbers-based quantitative data with descriptive qualitative research to learn the what, why, and how of customer experiences.
Looking at an opportunity from multiple angles helps you make more customer-centric decisions with less guesswork.
Stay close to customers with Hotjar
Hotjar’s tools offer quantitative and qualitative insights you can use to make customer-centric decisions, get buy-in, and highlight your team’s impact.
Frequently asked questions about quantitative data analysis
What is quantitative data.
Quantitative data is numeric feedback and information that you can count and measure. For example, you can calculate multiple-choice response rates, but you can’t tally a customer’s open-ended product feedback response. You have to use qualitative data analysis methods for non-numeric feedback.
What are quantitative data analysis methods?
Quantitative data analysis either summarizes or finds connections between numerical data feedback. Here are eight ways to analyze your online business’s quantitative data:
Compare multiple-choice response rates
Cross-tabulate to compare responses between groups
Measure the volume of response over time
Net Promoter Score
Weight customer feedback
How do you visualize quantitative data?
Data visualization makes it easier to spot trends and share your analysis with stakeholders. Bar charts, line graphs, scatter plots, and matrices are ways to visualize quantitative data.
What are the two types of statistical analysis for online businesses?
Quantitative data analysis is broken down into two analysis technique types:
Descriptive statistics summarize your collected data, like the number of website visitors this month
Inferential statistics compare relationships between multiple types of quantitative data, like survey responses between different customer segments
Quantitative data analysis process
Previous chapter
Quantitative data analysis software
Next chapter
- Privacy Policy
Buy Me a Coffee
Home » Quantitative Data – Types, Methods and Examples
Quantitative Data – Types, Methods and Examples
Table of Contents

Quantitative Data
Definition:
Quantitative data refers to numerical data that can be measured or counted. This type of data is often used in scientific research and is typically collected through methods such as surveys, experiments, and statistical analysis.
Quantitative Data Types
There are two main types of quantitative data: discrete and continuous.
- Discrete data: Discrete data refers to numerical values that can only take on specific, distinct values. This type of data is typically represented as whole numbers and cannot be broken down into smaller units. Examples of discrete data include the number of students in a class, the number of cars in a parking lot, and the number of children in a family.
- Continuous data: Continuous data refers to numerical values that can take on any value within a certain range or interval. This type of data is typically represented as decimal or fractional values and can be broken down into smaller units. Examples of continuous data include measurements of height, weight, temperature, and time.
Quantitative Data Collection Methods
There are several common methods for collecting quantitative data. Some of these methods include:
- Surveys : Surveys involve asking a set of standardized questions to a large number of people. Surveys can be conducted in person, over the phone, via email or online, and can be used to collect data on a wide range of topics.
- Experiments : Experiments involve manipulating one or more variables and observing the effects on a specific outcome. Experiments can be conducted in a controlled laboratory setting or in the real world.
- Observational studies : Observational studies involve observing and collecting data on a specific phenomenon without intervening or manipulating any variables. Observational studies can be conducted in a natural setting or in a laboratory.
- Secondary data analysis : Secondary data analysis involves using existing data that was collected for a different purpose to answer a new research question. This method can be cost-effective and efficient, but it is important to ensure that the data is appropriate for the research question being studied.
- Physiological measures: Physiological measures involve collecting data on biological or physiological processes, such as heart rate, blood pressure, or brain activity.
- Computerized tracking: Computerized tracking involves collecting data automatically from electronic sources, such as social media, online purchases, or website analytics.
Quantitative Data Analysis Methods
There are several methods for analyzing quantitative data, including:
- Descriptive statistics: Descriptive statistics are used to summarize and describe the basic features of the data, such as the mean, median, mode, standard deviation, and range.
- Inferential statistics : Inferential statistics are used to make generalizations about a population based on a sample of data. These methods include hypothesis testing, confidence intervals, and regression analysis.
- Data visualization: Data visualization involves creating charts, graphs, and other visual representations of the data to help identify patterns and trends. Common types of data visualization include histograms, scatterplots, and bar charts.
- Time series analysis: Time series analysis involves analyzing data that is collected over time to identify patterns and trends in the data.
- Multivariate analysis : Multivariate analysis involves analyzing data with multiple variables to identify relationships between the variables.
- Factor analysis : Factor analysis involves identifying underlying factors or dimensions that explain the variation in the data.
- Cluster analysis: Cluster analysis involves identifying groups or clusters of observations that are similar to each other based on multiple variables.
Quantitative Data Formats
Quantitative data can be represented in different formats, depending on the nature of the data and the purpose of the analysis. Here are some common formats:
- Tables : Tables are a common way to present quantitative data, particularly when the data involves multiple variables. Tables can be used to show the frequency or percentage of data in different categories or to display summary statistics.
- Charts and graphs: Charts and graphs are useful for visualizing quantitative data and can be used to highlight patterns and trends in the data. Some common types of charts and graphs include line charts, bar charts, scatterplots, and pie charts.
- Databases : Quantitative data can be stored in databases, which allow for easy sorting, filtering, and analysis of large amounts of data.
- Spreadsheets : Spreadsheets can be used to organize and analyze quantitative data, particularly when the data is relatively small in size. Spreadsheets allow for calculations and data manipulation, as well as the creation of charts and graphs.
- Statistical software : Statistical software, such as SPSS, R, and SAS, can be used to analyze quantitative data. These programs allow for more advanced statistical analyses and data modeling, as well as the creation of charts and graphs.
Quantitative Data Gathering Guide
Here is a basic guide for gathering quantitative data:
- Define the research question: The first step in gathering quantitative data is to clearly define the research question. This will help determine the type of data to be collected, the sample size, and the methods of data analysis.
- Choose the data collection method: Select the appropriate method for collecting data based on the research question and available resources. This could include surveys, experiments, observational studies, or other methods.
- Determine the sample size: Determine the appropriate sample size for the research question. This will depend on the level of precision needed and the variability of the population being studied.
- Develop the data collection instrument: Develop a questionnaire or survey instrument that will be used to collect the data. The instrument should be designed to gather the specific information needed to answer the research question.
- Pilot test the data collection instrument : Before collecting data from the entire sample, pilot test the instrument on a small group to identify any potential problems or issues.
- Collect the data: Collect the data from the selected sample using the chosen data collection method.
- Clean and organize the data : Organize the data into a format that can be easily analyzed. This may involve checking for missing data, outliers, or errors.
- Analyze the data: Analyze the data using appropriate statistical methods. This may involve descriptive statistics, inferential statistics, or other types of analysis.
- Interpret the results: Interpret the results of the analysis in the context of the research question. Identify any patterns, trends, or relationships in the data and draw conclusions based on the findings.
- Communicate the findings: Communicate the findings of the analysis in a clear and concise manner, using appropriate tables, graphs, and other visual aids as necessary. The results should be presented in a way that is accessible to the intended audience.
Examples of Quantitative Data
Here are some examples of quantitative data:
- Height of a person (measured in inches or centimeters)
- Weight of a person (measured in pounds or kilograms)
- Temperature (measured in Fahrenheit or Celsius)
- Age of a person (measured in years)
- Number of cars sold in a month
- Amount of rainfall in a specific area (measured in inches or millimeters)
- Number of hours worked in a week
- GPA (grade point average) of a student
- Sales figures for a product
- Time taken to complete a task.
- Distance traveled (measured in miles or kilometers)
- Speed of an object (measured in miles per hour or kilometers per hour)
- Number of people attending an event
- Price of a product (measured in dollars or other currency)
- Blood pressure (measured in millimeters of mercury)
- Amount of sugar in a food item (measured in grams)
- Test scores (measured on a numerical scale)
- Number of website visitors per day
- Stock prices (measured in dollars)
- Crime rates (measured by the number of crimes per 100,000 people)
Applications of Quantitative Data
Quantitative data has a wide range of applications across various fields, including:
- Scientific research: Quantitative data is used extensively in scientific research to test hypotheses and draw conclusions. For example, in biology, researchers might use quantitative data to measure the growth rate of cells or the effectiveness of a drug treatment.
- Business and economics: Quantitative data is used to analyze business and economic trends, forecast future performance, and make data-driven decisions. For example, a company might use quantitative data to analyze sales figures and customer demographics to determine which products are most popular among which segments of their customer base.
- Education: Quantitative data is used in education to measure student performance, evaluate teaching methods, and identify areas where improvement is needed. For example, a teacher might use quantitative data to track the progress of their students over the course of a semester and adjust their teaching methods accordingly.
- Public policy: Quantitative data is used in public policy to evaluate the effectiveness of policies and programs, identify areas where improvement is needed, and develop evidence-based solutions. For example, a government agency might use quantitative data to evaluate the impact of a social welfare program on poverty rates.
- Healthcare : Quantitative data is used in healthcare to evaluate the effectiveness of medical treatments, track the spread of diseases, and identify risk factors for various health conditions. For example, a doctor might use quantitative data to monitor the blood pressure levels of their patients over time and adjust their treatment plan accordingly.
Purpose of Quantitative Data
The purpose of quantitative data is to provide a numerical representation of a phenomenon or observation. Quantitative data is used to measure and describe the characteristics of a population or sample, and to test hypotheses and draw conclusions based on statistical analysis. Some of the key purposes of quantitative data include:
- Measuring and describing : Quantitative data is used to measure and describe the characteristics of a population or sample, such as age, income, or education level. This allows researchers to better understand the population they are studying.
- Testing hypotheses: Quantitative data is often used to test hypotheses and theories by collecting numerical data and analyzing it using statistical methods. This can help researchers determine whether there is a statistically significant relationship between variables or whether there is support for a particular theory.
- Making predictions : Quantitative data can be used to make predictions about future events or trends based on past data. This is often done through statistical modeling or time series analysis.
- Evaluating programs and policies: Quantitative data is often used to evaluate the effectiveness of programs and policies. This can help policymakers and program managers identify areas where improvements can be made and make evidence-based decisions about future programs and policies.
When to use Quantitative Data
Quantitative data is appropriate to use when you want to collect and analyze numerical data that can be measured and analyzed using statistical methods. Here are some situations where quantitative data is typically used:
- When you want to measure a characteristic or behavior : If you want to measure something like the height or weight of a population or the number of people who smoke, you would use quantitative data to collect this information.
- When you want to compare groups: If you want to compare two or more groups, such as comparing the effectiveness of two different medical treatments, you would use quantitative data to collect and analyze the data.
- When you want to test a hypothesis : If you have a hypothesis or theory that you want to test, you would use quantitative data to collect data that can be analyzed statistically to determine whether your hypothesis is supported by the data.
- When you want to make predictions: If you want to make predictions about future trends or events, such as predicting sales for a new product, you would use quantitative data to collect and analyze data from past trends to make your prediction.
- When you want to evaluate a program or policy : If you want to evaluate the effectiveness of a program or policy, you would use quantitative data to collect data about the program or policy and analyze it statistically to determine whether it has had the intended effect.
Characteristics of Quantitative Data
Quantitative data is characterized by several key features, including:
- Numerical values : Quantitative data consists of numerical values that can be measured and counted. These values are often expressed in terms of units, such as dollars, centimeters, or kilograms.
- Continuous or discrete : Quantitative data can be either continuous or discrete. Continuous data can take on any value within a certain range, while discrete data can only take on certain values.
- Objective: Quantitative data is objective, meaning that it is not influenced by personal biases or opinions. It is based on empirical evidence that can be measured and analyzed using statistical methods.
- Large sample size: Quantitative data is often collected from a large sample size in order to ensure that the results are statistically significant and representative of the population being studied.
- Statistical analysis: Quantitative data is typically analyzed using statistical methods to determine patterns, relationships, and other characteristics of the data. This allows researchers to make more objective conclusions based on empirical evidence.
- Precision : Quantitative data is often very precise, with measurements taken to multiple decimal points or significant figures. This precision allows for more accurate analysis and interpretation of the data.
Advantages of Quantitative Data
Some advantages of quantitative data are:
- Objectivity : Quantitative data is usually objective because it is based on measurable and observable variables. This means that different people who collect the same data will generally get the same results.
- Precision : Quantitative data provides precise measurements of variables. This means that it is easier to make comparisons and draw conclusions from quantitative data.
- Replicability : Since quantitative data is based on objective measurements, it is often easier to replicate research studies using the same or similar data.
- Generalizability : Quantitative data allows researchers to generalize findings to a larger population. This is because quantitative data is often collected using random sampling methods, which help to ensure that the data is representative of the population being studied.
- Statistical analysis : Quantitative data can be analyzed using statistical methods, which allows researchers to test hypotheses and draw conclusions about the relationships between variables.
- Efficiency : Quantitative data can often be collected quickly and efficiently using surveys or other standardized instruments, which makes it a cost-effective way to gather large amounts of data.
Limitations of Quantitative Data
Some Limitations of Quantitative Data are as follows:
- Limited context: Quantitative data does not provide information about the context in which the data was collected. This can make it difficult to understand the meaning behind the numbers.
- Limited depth: Quantitative data is often limited to predetermined variables and questions, which may not capture the complexity of the phenomenon being studied.
- Difficulty in capturing qualitative aspects: Quantitative data is unable to capture the subjective experiences and qualitative aspects of human behavior, such as emotions, attitudes, and motivations.
- Possibility of bias: The collection and interpretation of quantitative data can be influenced by biases, such as sampling bias, measurement bias, or researcher bias.
- Simplification of complex phenomena: Quantitative data may oversimplify complex phenomena by reducing them to numerical measurements and statistical analyses.
- Lack of flexibility: Quantitative data collection methods may not allow for changes or adaptations in the research process, which can limit the ability to respond to unexpected findings or new insights.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Primary Data – Types, Methods and Examples

Qualitative Data – Types, Methods and Examples

Research Data – Types Methods and Examples

Secondary Data – Types, Methods and Examples

Information in Research – Types and Examples
Part II: Data Analysis Methods in Quantitative Research
Data analysis methods in quantitative research.
We started this module with levels of measurement as a way to categorize our data. Data analysis is directed toward answering the original research question and achieving the study purpose (or aim). Now, we are going to delve into two main statistical analyses to describe our data and make inferences about our data:
Descriptive Statistics and Inferential Statistics.
Descriptive Statistics:
Before you panic, we will not be going into statistical analyses very deeply. We want to simply get a good overview of some of the types of general statistical analyses so that it makes some sense to us when we read results in published research articles.
Descriptive statistics summarize or describe the characteristics of a data set. This is a method of simply organizing and describing our data. Why? Because data that are not organized in some fashion are super difficult to interpret.
Let’s say our sample is golden retrievers (population “canines”). Our descriptive statistics tell us more about the same.
- 37% of our sample is male, 43% female
- The mean age is 4 years
- Mode is 6 years
- Median age is 5.5 years

Let’s explore some of the types of descriptive statistics.
Frequency Distributions : A frequency distribution describes the number of observations for each possible value of a measured variable. The numbers are arranged from lowest to highest and features a count of how many times each value occurred.
For example, if 18 students have pet dogs, dog ownership has a frequency of 18.
We might see what other types of pets that students have. Maybe cats, fish, and hamsters. We find that 2 students have hamsters, 9 have fish, 1 has a cat.
You can see that it is very difficult to interpret the various pets into any meaningful interpretation, yes?
Now, let’s take those same pets and place them in a frequency distribution table.
As we can now see, this is much easier to interpret.
Let’s say that we want to know how many books our sample population of students have read in the last year. We collect our data and find this:
We can then take that table and plot it out on a frequency distribution graph. This makes it much easier to see how the numbers are disbursed. Easier on the eyes, yes?

Here’s another example of symmetrical, positive skew, and negative skew:

Correlation : Relationships between two research variables are called correlations . Remember, correlation is not cause-and-effect. Correlations simply measure the extent of relationship between two variables. To measure correlation in descriptive statistics, the statistical analysis called Pearson’s correlation coefficient I is often used. You do not need to know how to calculate this for this course. But, do remember that analysis test because you will often see this in published research articles. There really are no set guidelines on what measurement constitutes a “strong” or “weak” correlation, as it really depends on the variables being measured.
However, possible values for correlation coefficients range from -1.00 through .00 to +1.00. A value of +1 means that the two variables are positively correlated, as one variable goes up, the other goes up. A value of r = 0 means that the two variables are not linearly related.
Often, the data will be presented on a scatter plot. Here, we can view the data and there appears to be a straight line (linear) trend between height and weight. The association (or correlation) is positive. That means, that there is a weight increase with height. The Pearson correlation coefficient in this case was r = 0.56.

A type I error is made by rejecting a null hypothesis that is true. This means that there was no difference but the researcher concluded that the hypothesis was true.
A type II error is made by accepting that the null hypothesis is true when, in fact, it was false. Meaning there was actually a difference but the researcher did not think their hypothesis was supported.
Hypothesis Testing Procedures : In a general sense, the overall testing of a hypothesis has a systematic methodology. Remember, a hypothesis is an educated guess about the outcome. If we guess wrong, we might set up the tests incorrectly and might get results that are invalid. Sometimes, this is super difficult to get right. The main purpose of statistics is to test a hypothesis.
- Selecting a statistical test. Lots of factors go into this, including levels of measurement of the variables.
- Specifying the level of significance. Usually 0.05 is chosen.
- Computing a test statistic. Lots of software programs to help with this.
- Determining degrees of freedom ( df ). This refers to the number of observations free to vary about a parameter. Computing this is easy (but you don’t need to know how for this course).
- Comparing the test statistic to a theoretical value. Theoretical values exist for all test statistics, which is compared to the study statistics to help establish significance.
Some of the common inferential statistics you will see include:
Comparison tests: Comparison tests look for differences among group means. They can be used to test the effect of a categorical variable on the mean value of some other characteristic.
T-tests are used when comparing the means of precisely two groups (e.g., the average heights of men and women). ANOVA and MANOVA tests are used when comparing the means of more than two groups (e.g., the average heights of children, teenagers, and adults).
- t -tests (compares differences in two groups) – either paired t-test (example: What is the effect of two different test prep programs on the average exam scores for students from the same class?) or independent t-test (example: What is the difference in average exam scores for students from two different schools?)
- analysis of variance (ANOVA, which compares differences in three or more groups) (example: What is the difference in average pain levels among post-surgical patients given three different painkillers?) or MANOVA (compares differences in three or more groups, and 2 or more outcomes) (example: What is the effect of flower species on petal length, petal width, and stem length?)
Correlation tests: Correlation tests check whether variables are related without hypothesizing a cause-and-effect relationship.
- Pearson r (measures the strength and direction of the relationship between two variables) (example: How are latitude and temperature related?)
Nonparametric tests: Non-parametric tests don’t make as many assumptions about the data, and are useful when one or more of the common statistical assumptions are violated. However, the inferences they make aren’t as strong as with parametric tests.
- chi-squared ( X 2 ) test (measures differences in proportions). Chi-square tests are often used to test hypotheses. The chi-square statistic compares the size of any discrepancies between the expected results and the actual results, given the size of the sample and the number of variables in the relationship. For example, the results of tossing a fair coin meet these criteria. We can apply a chi-square test to determine which type of candy is most popular and make sure that our shelves are well stocked. Or maybe you’re a scientist studying the offspring of cats to determine the likelihood of certain genetic traits being passed to a litter of kittens.
Inferential Versus Descriptive Statistics Summary Table
Statistical Significance Versus Clinical Significance
Finally, when it comes to statistical significance in hypothesis testing, the normal probability value in nursing is <0.05. A p=value (probability) is a statistical measurement used to validate a hypothesis against measured data in the study. Meaning, it measures the likelihood that the results were actually observed due to the intervention, or if the results were just due by chance. The p-value, in measuring the probability of obtaining the observed results, assumes the null hypothesis is true.
The lower the p-value, the greater the statistical significance of the observed difference.
In the example earlier about our diabetic patients receiving online diet education, let’s say we had p = 0.05. Would that be a statistically significant result?
If you answered yes, you are correct!
What if our result was p = 0.8?
Not significant. Good job!
That’s pretty straightforward, right? Below 0.05, significant. Over 0.05 not significant.
Could we have significance clinically even if we do not have statistically significant results? Yes. Let’s explore this a bit.
Statistical hypothesis testing provides little information for interpretation purposes. It’s pretty mathematical and we can still get it wrong. Additionally, attaining statistical significance does not really state whether a finding is clinically meaningful. With a large enough sample, even a small very tiny relationship may be statistically significant. But, clinical significance is the practical importance of research. Meaning, we need to ask what the palpable effects may be on the lives of patients or healthcare decisions.
Remember, hypothesis testing cannot prove. It also cannot tell us much other than “yeah, it’s probably likely that there would be some change with this intervention”. Hypothesis testing tells us the likelihood that the outcome was due to an intervention or influence and not just by chance. Also, as nurses and clinicians, we are not concerned with a group of people – we are concerned at the individual, holistic level. The goal of evidence-based practice is to use best evidence for decisions about specific individual needs.
Additionally, begin your Discussion section. What are the implications to practice? Is there little evidence or a lot? Would you recommend additional studies? If so, what type of study would you recommend, and why?
- Were all the important results discussed?
- Did the researchers discuss any study limitations and their possible effects on the credibility of the findings? In discussing limitations, were key threats to the study’s validity and possible biases reviewed? Did the interpretations take limitations into account?
- What types of evidence were offered in support of the interpretation, and was that evidence persuasive? Were results interpreted in light of findings from other studies?
- Did the researchers make any unjustifiable causal inferences? Were alternative explanations for the findings considered? Were the rationales for rejecting these alternatives convincing?
- Did the interpretation consider the precision of the results and/or the magnitude of effects?
- Did the researchers draw any unwarranted conclusions about the generalizability of the results?
- Did the researchers discuss the study’s implications for clinical practice or future nursing research? Did they make specific recommendations?
- If yes, are the stated implications appropriate, given the study’s limitations and the magnitude of the effects as well as evidence from other studies? Are there important implications that the report neglected to include?
- Did the researchers mention or assess clinical significance? Did they make a distinction between statistical and clinical significance?
- If clinical significance was examined, was it assessed in terms of group-level information (e.g., effect sizes) or individual-level results? How was clinical significance operationalized?
References & Attribution
“ Green check mark ” by rawpixel licensed CC0 .
“ Magnifying glass ” by rawpixel licensed CC0
“ Orange flame ” by rawpixel licensed CC0 .
Polit, D. & Beck, C. (2021). Lippincott CoursePoint Enhanced for Polit’s Essentials of Nursing Research (10th ed.). Wolters Kluwer Health
Vaid, N. K. (2019) Statistical performance measures. Medium. https://neeraj-kumar-vaid.medium.com/statistical-performance-measures-12bad66694b7
Evidence-Based Practice & Research Methodologies Copyright © by Tracy Fawns is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
What Are The Primary Methods Used In Quantitative Data Analysis For Research?

What are the primary methods used in quantitative data analysis for research?
Quantitative data analysis in research primarily employs statistical and computational techniques to interpret numerical data. This includes methods like cross-tabulation, which draws inferences between datasets in a tabular format, and MaxDiff Analysis, aimed at understanding respondent preferences by identifying the most and least preferred options. Descriptive statistics summarize data through measures like percentages or means, while inferential statistics predict characteristics for a larger population based on summarized data.
Examples of these methods in action include using cross-tabulation to analyze consumer behavior across different demographics or employing descriptive statistics to calculate the average sales revenue of a product. The choice of method depends on the research question and the nature of the data.
How does quantitative data analysis differ from qualitative analysis in research?
Quantitative data analysis differs from qualitative analysis primarily in its focus on numerical data and statistical methods to answer questions of "how many" and "how much". It seeks to quantify variables and generalize results from a sample to a population. In contrast, qualitative analysis focuses on non-numerical data, aiming to understand concepts, thoughts, or experiences through methods such as interviews or observations. Quantitative analysis uses metrics and numerical figures, while qualitative analysis explores the depth and complexity of data without quantifying.
For instance, while quantitative analysis might calculate the percentage of people who prefer a certain product, qualitative analysis might explore why people prefer that product through open-ended survey responses or interviews.
What are the four main types of quantitative research, and how do they differ?
The four main types of quantitative research are Descriptive, Correlational, Causal-Comparative/Quasi-Experimental, and Experimental Research. Descriptive research aims to describe characteristics of a population or phenomenon. Correlational research investigates the relationship between two or more variables without implying causation. Causal-Comparative/Quasi-Experimental research looks at cause-and-effect relationships between variables when controlled experiments are not feasible. Experimental Research, the most rigorous form, manipulates one variable to determine its effect on another, allowing for control over the research environment.
- Descriptive research might involve surveying a population to gather data on current trends.
- Correlational research could analyze the relationship between study habits and academic performance.
- Causal-Comparative studies may explore the impact of a new teaching method on student learning outcomes.
- Experimental research often involves controlled trials to test the efficacy of a new drug.
How do researchers choose the appropriate quantitative analysis method for their study?
Choosing the appropriate quantitative analysis method involves considering the research question, the nature of the data, and the research design. Descriptive statistics are suitable for summarizing data, while inferential statistics are used for making predictions about a population from a sample. Cross-tabulation is effective for exploring relationships between categorical variables, and MaxDiff Analysis is useful for preference ranking. The choice also depends on the type of quantitative research being conducted, whether it's descriptive, correlational, causal-comparative, or experimental.
Researchers must also consider the data's scale of measurement and the assumptions underlying different statistical tests to ensure the validity of their findings.
What challenges do researchers face in quantitative data analysis?
Researchers face several challenges in quantitative data analysis, including data quality issues, such as missing or inaccurate data, and the complexity of statistical methods. Ensuring the representativeness of the sample and dealing with confounding variables that may affect the results are also significant challenges. Additionally, interpreting the results correctly and avoiding misinterpretation or overgeneralization of data is crucial.
Addressing these challenges requires careful planning, rigorous methodology, and a deep understanding of statistical principles.
How has technology impacted quantitative data analysis in research?
Technology has significantly impacted quantitative data analysis by enabling more sophisticated statistical analysis, automating data collection and processing, and facilitating the visualization of complex data. Software tools and platforms allow researchers to handle large datasets and perform complex analyses more efficiently. AI and machine learning algorithms have also enhanced the ability to identify patterns and predict outcomes in large datasets.
Technological advancements have made quantitative data analysis more accessible and powerful, expanding the possibilities for research across various fields.
How can data management platforms enhance efficiency in quantitative research?
Data management platforms play a crucial role in enhancing efficiency in quantitative research by streamlining data discovery, centralization, and documentation. These platforms automate the process of finding and organizing data, which significantly reduces the time researchers spend on data preparation. By providing a centralized repository for all incoming data and metadata, researchers can easily access and analyze the data they need without navigating through disparate sources.
For example, a data management platform can automate the documentation of datasets, ensuring that researchers have up-to-date metadata for their analysis, which is essential for accurate and reliable research outcomes.
What is the significance of AI in automating data discovery and documentation for research?
AI plays a transformative role in automating data discovery and documentation, significantly benefiting quantitative research. AI-powered tools can automatically categorize, tag, and document data, making it easier for researchers to find relevant datasets for their analysis. This automation not only saves time but also enhances the accuracy of data documentation, reducing the risk of errors that could compromise research integrity.
AI-driven data management platforms can also provide predictive insights, suggesting relevant datasets based on the research context, which streamlines the research process and fosters more informed decision-making.
How do no-code integrations in data platforms facilitate quantitative research?
No-code integrations in data platforms facilitate quantitative research by enabling researchers to connect various data sources and tools without the need for complex coding. This democratizes data analysis, allowing researchers with limited programming skills to perform sophisticated analyses. By simplifying the integration process, researchers can quickly combine datasets, apply statistical models, and visualize results, accelerating the research cycle.
- For instance, a researcher can integrate survey data with sales figures to analyze consumer behavior without writing a single line of code.
- No-code integrations also allow for seamless updates and modifications to the research setup, adapting to evolving research needs.
What role does collaboration play in enhancing the outcomes of quantitative research?
Collaboration is pivotal in enhancing the outcomes of quantitative research, as it brings together diverse expertise and perspectives. Data management platforms that support collaboration, such as through integrated communication tools, enable researchers to share insights, discuss findings, and refine methodologies in real-time. This collaborative environment fosters a more comprehensive analysis, as researchers can pool their knowledge and skills to tackle complex research questions more effectively.
Moreover, collaboration facilitated by these platforms can lead to more innovative approaches to data analysis, leveraging collective intelligence to push the boundaries of what is possible in quantitative research.
How does the integration of communication tools in data platforms streamline research workflows?
The integration of communication tools in data platforms streamlines research workflows by enabling seamless interaction among team members. This integration allows researchers to discuss data, share insights, and make decisions without leaving the data environment. It reduces the need for external communication tools, minimizing disruptions and ensuring that all discussions are contextualized within the relevant data.
Such streamlined communication enhances efficiency, as decisions can be made quickly and implemented directly within the research workflow, ensuring that projects move forward smoothly and cohesively.
In what ways do data management platforms support data governance in quantitative research?
Data management platforms support data governance in quantitative research by providing tools and features that ensure data quality, security, and compliance. These platforms offer centralized control over data access, enabling researchers to define who can view or modify data. They also automate documentation and metadata management, ensuring that data usage is transparent and traceable.
By facilitating data governance, these platforms help maintain the integrity and reliability of research data, which is essential for producing valid and credible research outcomes.

Keep reading

Move fast without breaking (too many) things: Secoda Wrap 21
Secoda Wrap #21 is here! Catch up on a new episode of the Women Lead Data Podcast with Lindsay Murphy and Michelle Yi, get tickets for the MDS Fest conference and more!
.jpg)
Data governance 🤝 Business intelligence: Secoda Wrap 20
Read Secoda Wrap #20 for a recap of this week at Secoda: a new webinar on data governance, 2 new integrations, lessons on leadership with the Women Lead Data podcast and more!

How Does Continuous Integration and Deployment Aid Data Pipeline Reliability?
Learn how CI/CD can significantly improve the reliability of your data pipelines.
Get started in minutes
Built for data teams, designed for everyone so you can get more from your data stack.
Get the newsletter for the latest updates, events, and best practices from modern data teams.
© 2024 Secoda, Inc. All rights reserved. By using this website, you accept our Terms of Use and Privacy Policy .

- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Quantitative Data: What It Is, Types & Examples

When we’re asking questions like “ How many? “, “ How often? ” or “ How much? ” we’re talking about the kind of hard-hitting, verifiable data that can be analyzed with mathematical techniques. It’s the kind of stuff that would make a statistician’s heart skip a beat. Let’s discuss quantitative data.
Thankfully, online surveys are the go-to tool for collecting this kind of data in the internet age. With the ability to reach more people in less time and gather honest responses for later analysis, online surveys are the ultimate quantitative data-gathering machine. Plus, let’s be real: who doesn’t love taking a good survey?
What is Quantitative Data?
Quantitative data is the value of data in the form of counts or numbers where each data set has a unique numerical value. This data is any quantifiable information that researchers can use for mathematical calculations and statistical analysis to make real-life decisions based on these mathematical derivations.
For example, there are quantities corresponding to various parameters. For instance, “How much did that laptop cost?” is a question that will collect quantitative data. Values are associated with most measuring parameters, such as pounds or kilograms for weight, dollars for cost, etc.
It makes measuring various parameters controllable due to the ease of mathematical derivations they come with. It is usually collected for statistical analysis plans using surveys , polls, or questionnaires sent across to a specific section of a population. Researches can establish the retrieved results across a population.
Types of Quantitative Data with Examples
Quantitative data is integral to the research process, providing valuable insights into various phenomena. Let’s explore the most common types of quantitative data and their applications in various fields. The most common types are listed below:

- Counter: Count equated with entities—for example, the number of people downloading a particular application from the App Store.
- Measurement of physical objects: Calculating measurement of any physical thing. For example, the HR executive carefully measures the size of each cubicle assigned to the newly joined employees.
- Sensory calculation: Mechanism to naturally “sense” the measured parameters to create a constant source of information. For example, a digital camera converts electromagnetic information to a string of numerical data.
- Projection of data: Future data projections can be made using algorithms and other mathematical analysis tools. For example, a marketer will predict an increase in sales after launching a new product with a thorough analysis.
- Quantification of qualitative entities: Identify numbers to qualitative information. For example, asking respondents of an online survey to share the likelihood of recommendation on a scale of 0-10.
Quantitative Data: Collection Methods
As quantitative data is in the form of numbers, mathematical and statistical analysis of these numbers can lead to establishing some conclusive results.
There are two main Quantitative Data Collection Methods :
01. Surveys
Traditionally, surveys were conducted using paper-based methods and have gradually evolved into online mediums. Closed-ended questions form a major part of these surveys as they are more effective in collecting data.
The survey includes answer options they think are the most appropriate for a particular question. Surveys are integral in collecting feedback from an audience larger than the conventional size. A critical factor about surveys is that the responses collected should be such that they can be generalized to the entire population without significant discrepancies.
Based on the time involved in completing surveys, they are classified into the following:
- Longitudinal Studies: A type of observational research in which the market researcher conducts surveys from one time period to another, i.e., over a considerable course of time, is called a longitudinal survey . This survey is often implemented for trend analysis or studies where the primary objective is to collect and analyze a pattern in data.
- Cross-sectional Studies: A type of observational research in which market research conducts surveys at a particular time period across the target sample is known as a cross-sectional survey . This survey type implements a questionnaire to understand a specific subject from the sample at a definite time period.
To administer a survey to collect quantitative data, the following principles are to be followed.
- Fundamental Levels of Measurement – Nominal, Ordinal, Interval, and Ratio Scales: Four measurement scales are fundamental to creating a multiple-choice question in a survey in collecting quantitative data. They are nominal, ordinal, interval, and ratio measurement scales without the fundamentals of which no multiple-choice questions can be created.
- Use of Different Question Types: To collect quantitative data, close-ended questions have to be used in a survey. They can be a mix of multiple question types , including multiple-choice questions like semantic differential scale questions , rating scale questions , etc., that can help collect data that can be analyzed and made sense of.
- Email: Sending a survey via email is the most commonly used and most effective survey distribution method. You can use the QuestionPro email management feature to send out and collect survey responses.
- Buy respondents: Another effective way to distribute a survey and collect quantitative data is to use a sample. Since the respondents are knowledgeable and also are open to participating in research studies, the responses are much higher.
- Embed survey in a website: Embedding a survey in a website increases the number of responses as the respondent is already near the brand when the survey pops up.
- Social distribution: Using social media to distribute the survey aids in collecting a higher number of responses from the people who are aware of the brand.
- QR code: QuestionPro QR codes store the URL for the survey. You can print/publish this code in magazines, signs, business cards, or on just about any object/medium.
- SMS survey: A quick and time-effective way of conducting a survey to collect a high number of responses is the SMS survey .
- QuestionPro app: The QuestionPro App allows the quick creation of surveys, and the responses can be collected both online and offline .
- API integration: You can use the API integration of the QuestionPro platform for potential respondents to take your survey.
02. One-on-one Interviews
This quantitative data collection method was also traditionally conducted face-to-face but has shifted to telephonic and online platforms. Interviews offer a marketer the opportunity to gather extensive data from the participants. Quantitative interviews are immensely structured and play a key role in collecting information. There are three major sections of these online interviews:
- Face-to-Face Interviews: An interviewer can prepare a list of important interview questions in addition to the already asked survey questions . This way, interviewees provide exhaustive details about the topic under discussion. An interviewer can manage to bond with the interviewee on a personal level which will help him/her to collect more details about the topic due to which the responses also improve. Interviewers can also ask for an explanation from the interviewees about unclear answers.
- Online/Telephonic Interviews: Telephone-based interviews are no more a novelty but these quantitative interviews have also moved to online mediums such as Skype or Zoom. Irrespective of the distance between the interviewer and the interviewee and their corresponding time zones, communication becomes one-click away with online interviews. In case of telephone interviews, the interview is merely a phone call away.
- Computer Assisted Personal Interview: This is a one-on-one interview technique where the interviewer enters all the collected data directly into a laptop or any other similar device. The processing time is reduced and also the interviewers don’t have to carry physical questionnaires and merely enter the answers in the laptop.
All of the above quantitative data collection methods can be achieved by using surveys , questionnaires and online polls .
Quantitative Data: Analysis Methods
Data collection forms a major part of the research process. This data, however, has to be analyzed to make sense of. There are multiple methods of analyzing quantitative data collected in surveys . They are:

- Cross-tabulation: Cross-tabulation is the most widely used quantitative data analysis methods. It is a preferred method since it uses a basic tabular form to draw inferences between different data-sets in the research study. It contains data that is mutually exclusive or have some connection with each other.
- Trend analysis: Trend analysis is a statistical analysis method that provides the ability to look at quantitative data that has been collected over a long period of time. This data analysis method helps collect feedback about data changes over time and if aims to understand the change in variables considering one variable remains unchanged.
- MaxDiff analysis: The MaxDiff analysis is a quantitative data analysis method that is used to gauge customer preferences for a purchase and what parameters rank higher than the others in this process. In a simplistic form, this method is also called the “best-worst” method. This method is very similar to conjoint analysis but is much easier to implement and can be interchangeably used.
- Conjoint analysis: Like in the above method, conjoint analysis is a similar quantitative data analysis method that analyzes parameters behind a purchasing decision. This method possesses the ability to collect and analyze advanced metrics which provide an in-depth insight into purchasing decisions as well as the parameters that rank the most important.
- TURF analysis: TURF analysis or Total Unduplicated Reach and Basic Frequency Analysis, is a quantitative data analysis methodology that assesses the total market reach of a product or service or a mix of both. This method is used by organizations to understand the frequency and the avenues at which their messaging reaches customers and prospective customers which helps them tweak their go-to-market strategies.
- Gap analysis: Gap analysis uses a side-by-side matrix to depict data that helps measure the difference between expected performance and actual performance. This data gap analysis helps measure gaps in performance and the things that are required to be done to bridge this gap.
- SWOT analysis: SWOT analysis , is a quantitative data analysis methods that assigns numerical values to indicate strength, weaknesses, opportunities and threats of an organization or product or service which in turn provides a holistic picture about competition. This method helps to create effective business strategies.
- Text analysis: Text analysis is an advanced statistical method where intelligent tools make sense of and quantify or fashion qualitative observation and open-ended data into easily understandable data. This method is used when the raw survey data is unstructured but has to be brought into a structure that makes sense.
Steps to conduct Quantitative Data Analysis
For Quantitative Data, raw information has to presented in a meaningful manner using data analysis methods. This data should be analyzed to find evidential data that would help in the research process. Data analytics and data analysis are closely related processes that involve extracting insights from data to make informed decisions.
- Relate measurement scales with variables: Associate measurement scales such as Nominal, Ordinal, Interval and Ratio with the variables. This step is important to arrange the data in proper order. Data can be entered into an excel sheet to organize it in a specific format.
- Mean- An average of values for a specific variable
- Median- A midpoint of the value scale for a variable
- Mode- For a variable, the most common value
- Frequency- Number of times a particular value is observed in the scale
- Minimum and Maximum Values- Lowest and highest values for a scale
- Percentages- Format to express scores and set of values for variables
- Decide a measurement scale: It is important to decide the measurement scale to conclude descriptive statistics for the variable. For instance, a nominal data variable score will never have a mean or median, so the descriptive statistics will correspondingly vary. Descriptive statistics suffice in situations where the results are not to be generalized to the population.
- Select appropriate tables to represent data and analyze collected data: After deciding on a suitable measurement scale, researchers can use a tabular format to represent data. This data can be analyzed using various techniques such as Cross-tabulation or TURF .
Quantitative Data Examples
Listed below are some examples of quantitative data that can help understand exactly what this pertains:
- I updated my phone 6 times in a quarter.
- My teenager grew by 3 inches last year.
- 83 people downloaded the latest mobile application.
- My aunt lost 18 pounds last year.
- 150 respondents were of the opinion that the new product feature will fail to be successful.
- There will be 30% increase in revenue with the inclusion of a new product.
- 500 people attended the seminar.
- 54% people prefer shopping online instead of going to the mall.
- She has 10 holidays in this year.
- Product X costs $1000 .
As you can see in the above 10 examples, there is a numerical value assigned to each parameter and this is known as, quantitative data.
Advantages of Quantitative Data
Some of the advantages of quantitative data are:
- Conduct in-depth research: Since quantitative data can be statistically analyzed, it is highly likely that the research will be detailed.
- Minimum bias: There are instances in research, where personal bias is involved which leads to incorrect results. Due to the numerical nature of quantitative data, personal bias is reduced to a great extent.
- Accurate results: As the results obtained are objective in nature, they are extremely accurate.
Disadvantages of Quantitative Data
Some of disadvantages of quantitative data, are:
- Restricted information: Because quantitative data is not descriptive, it becomes difficult for researchers to make decisions based solely on the collected information.
- Depends on question types: Bias in results is dependent on the question types included to collect quantitative data. The researcher’s knowledge of questions and the objective of research are exceedingly important while collecting quantitative data.
Differences between Quantitative and Qualitative Data
There are some stark differences between quantitative data and qualitative data . While quantitative data deals with numbers and measures and quantifies a specific phenomenon, qualitative data focuses on non-numerical information, such as opinions and observations.
The two types of data have different purposes, strengths, and limitations, which are important in understanding a given subject completely. Understanding the differences between these two forms of data is crucial in choosing the right research methods, analyzing the results, and making informed decisions. Let’s explore the differences:
Using quantitative data in an investigation is one of the best strategies to guarantee reliable results that allow better decisions. In summary, quantitative data is the basis of statistical analysis.
Data that can be measured and verified gives us information about quantities; that is, information that can be measured and written with numbers. Quantitative data defines a number, while qualitative data collection is descriptive. You can also get quantitative data from qualitative by using semantic analysis .
QuestionPro is a software created to collect quantitative data using a powerful platform with preloaded questionnaires. In addition, you will be able to analyze your data with advanced analysis tools such as cross tables, Likert scales, infographics, and much more.
Start using our platform now!
LEARN MORE SIGN UP FREE
MORE LIKE THIS

Employee Engagement App: Top 11 For Workforce Improvement
Apr 10, 2024

Top 15 Employee Evaluation Software to Enhance Performance

Event Feedback Software: Top 11 Best in 2024
Apr 9, 2024

Top 10 Free Market Research Tools to Boost Your Business
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Data Analysis Techniques for Quantitative Study
- First Online: 27 October 2022
Cite this chapter

- Md. Mahsin 4
2083 Accesses
1 Citations
This chapter describes the types of data analysis techniques in quantitative research and sampling strategies suitable for quantitative studies, particularly probability sampling, to produce credible and trustworthy explanations of a phenomenon. Initially, it briefly describes the measurement levels of variables. It then provides some statistical analysis techniques for quantitative study with examples using tables and graphs, making it easier for the readers to understand the data presentation techniques in quantitative research. In summary, it will be a beneficial resource for those interested in using quantitative design for their data analysis.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
It is called the “Pearson correlation coefficient” in honour of Karl Pearson, a British mathematician who developed the method.
Agresti, A., & Kateri, M. (2011). Categorical data analysis . Springer.
Google Scholar
Argyrous, G. (1997). Statistics for social research . Macmillan Education Australia Printery Limited.
Aron, A., Coups, E., & Aron, E. N. (2013). Statistics for the behavioral and social sciences: A brief course: Pearson new international edition. Pearson Higher Ed.
Bailey, K. (2008). Methods of social research . Simon and Schuster.
Babbie, E. R. (2015). The practice of social research . Nelson Education.
Bernard, H. R., & Bernard, H. R. (2012). Social research methods: Qualitative and quantitative approaches . Sage Publications.
Bickman, L., & Rog, D. J. (Eds.). (2008). The sage handbook of applied social research methods . Sage Publications.
Bryman, A. (2015). Social research methods . Oxford University Press.
Field, A. (2009). Discovering statistics using SPSS . Sage Publications.
Gorard, S. (2003). Quantitative methods in social science research . A&C Black.
Hosmer, D. W., Jr., & Lemeshow, S. (2004). Applied logistic regression . John Wiley & Sons.
Islam, M. R. (Ed.). (2019). Social research methodology and new techniques in analysis, interpretation and writing . IGI Global.
Klecka, W. R. (1980). Discriminant analysis (No. 19). Sage Populations.
Lampard, R., & Pole, C. (2015). Practical social investigation: Qualitative and quantitative methods in social research . Routledge.
McLachlan, G. (2004). Discriminant analysis and statistical pattern recognition (Vol. 544). John Wiley & Sons.
Montgomery, D. C. (2012). Design and analysis of experiments . John Wiley & Sons.
Muijs, D. (2010). Doing quantitative research in education with SPSS . Sage Publications.
Neuman, L. W. (2002). Social research methods: Qualitative and quantitative approaches .
Population & Housing Census, Bangladesh. (2011). Preliminary results
Population Division of the Department of Economic and Social Affairs of the United Nations Secretariat, World Population Prospects: The 2010 Revision
Punch, K. F. (2013). Introduction to social research: Quantitative and qualitative approaches . Sage Publications.
Stevens, J. P. (2012). Applied multivariate statistics for the social sciences . Routledge.
Book Google Scholar
Wilcox, R. R. (1996). Statistics for the social sciences . Academic Press.
Download references
Author information
Authors and affiliations.
Department of Mathematics and Statistics, University of Calgary, 2500 University Drive NW, Calgary, Canada
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Md. Mahsin .
Editor information
Editors and affiliations.
Centre for Family and Child Studies, Research Institute of Humanities and Social Sciences, University of Sharjah, Sharjah, United Arab Emirates
M. Rezaul Islam
Department of Development Studies, University of Dhaka, Dhaka, Bangladesh
Niaz Ahmed Khan
Department of Social Work, School of Humanities, University of Johannesburg, Johannesburg, South Africa
Rajendra Baikady
Rights and permissions
Reprints and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter
Mahsin, M. (2022). Data Analysis Techniques for Quantitative Study. In: Islam, M.R., Khan, N.A., Baikady, R. (eds) Principles of Social Research Methodology. Springer, Singapore. https://doi.org/10.1007/978-981-19-5441-2_16
Download citation
DOI : https://doi.org/10.1007/978-981-19-5441-2_16
Published : 27 October 2022
Publisher Name : Springer, Singapore
Print ISBN : 978-981-19-5219-7
Online ISBN : 978-981-19-5441-2
eBook Packages : Social Sciences
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Data & Finance for Work & Life

Data Analysis: Types, Methods & Techniques (a Complete List)
( Updated Version )
While the term sounds intimidating, “data analysis” is nothing more than making sense of information in a table. It consists of filtering, sorting, grouping, and manipulating data tables with basic algebra and statistics.
In fact, you don’t need experience to understand the basics. You have already worked with data extensively in your life, and “analysis” is nothing more than a fancy word for good sense and basic logic.
Over time, people have intuitively categorized the best logical practices for treating data. These categories are what we call today types , methods , and techniques .
This article provides a comprehensive list of types, methods, and techniques, and explains the difference between them.
For a practical intro to data analysis (including types, methods, & techniques), check out our Intro to Data Analysis eBook for free.
Descriptive, Diagnostic, Predictive, & Prescriptive Analysis
If you Google “types of data analysis,” the first few results will explore descriptive , diagnostic , predictive , and prescriptive analysis. Why? Because these names are easy to understand and are used a lot in “the real world.”
Descriptive analysis is an informational method, diagnostic analysis explains “why” a phenomenon occurs, predictive analysis seeks to forecast the result of an action, and prescriptive analysis identifies solutions to a specific problem.
That said, these are only four branches of a larger analytical tree.
Good data analysts know how to position these four types within other analytical methods and tactics, allowing them to leverage strengths and weaknesses in each to uproot the most valuable insights.
Let’s explore the full analytical tree to understand how to appropriately assess and apply these four traditional types.
Tree diagram of Data Analysis Types, Methods, and Techniques
Here’s a picture to visualize the structure and hierarchy of data analysis types, methods, and techniques.
If it’s too small you can view the picture in a new tab . Open it to follow along!

Note: basic descriptive statistics such as mean , median , and mode , as well as standard deviation , are not shown because most people are already familiar with them. In the diagram, they would fall under the “descriptive” analysis type.
Tree Diagram Explained
The highest-level classification of data analysis is quantitative vs qualitative . Quantitative implies numbers while qualitative implies information other than numbers.
Quantitative data analysis then splits into mathematical analysis and artificial intelligence (AI) analysis . Mathematical types then branch into descriptive , diagnostic , predictive , and prescriptive .
Methods falling under mathematical analysis include clustering , classification , forecasting , and optimization . Qualitative data analysis methods include content analysis , narrative analysis , discourse analysis , framework analysis , and/or grounded theory .
Moreover, mathematical techniques include regression , Nïave Bayes , Simple Exponential Smoothing , cohorts , factors , linear discriminants , and more, whereas techniques falling under the AI type include artificial neural networks , decision trees , evolutionary programming , and fuzzy logic . Techniques under qualitative analysis include text analysis , coding , idea pattern analysis , and word frequency .
It’s a lot to remember! Don’t worry, once you understand the relationship and motive behind all these terms, it’ll be like riding a bike.
We’ll move down the list from top to bottom and I encourage you to open the tree diagram above in a new tab so you can follow along .
But first, let’s just address the elephant in the room: what’s the difference between methods and techniques anyway?
Difference between methods and techniques
Though often used interchangeably, methods ands techniques are not the same. By definition, methods are the process by which techniques are applied, and techniques are the practical application of those methods.
For example, consider driving. Methods include staying in your lane, stopping at a red light, and parking in a spot. Techniques include turning the steering wheel, braking, and pushing the gas pedal.
Data sets: observations and fields
It’s important to understand the basic structure of data tables to comprehend the rest of the article. A data set consists of one far-left column containing observations, then a series of columns containing the fields (aka “traits” or “characteristics”) that describe each observations. For example, imagine we want a data table for fruit. It might look like this:
Now let’s turn to types, methods, and techniques. Each heading below consists of a description, relative importance, the nature of data it explores, and the motivation for using it.
Quantitative Analysis
- It accounts for more than 50% of all data analysis and is by far the most widespread and well-known type of data analysis.
- As you have seen, it holds descriptive, diagnostic, predictive, and prescriptive methods, which in turn hold some of the most important techniques available today, such as clustering and forecasting.
- It can be broken down into mathematical and AI analysis.
- Importance : Very high . Quantitative analysis is a must for anyone interesting in becoming or improving as a data analyst.
- Nature of Data: data treated under quantitative analysis is, quite simply, quantitative. It encompasses all numeric data.
- Motive: to extract insights. (Note: we’re at the top of the pyramid, this gets more insightful as we move down.)
Qualitative Analysis
- It accounts for less than 30% of all data analysis and is common in social sciences .
- It can refer to the simple recognition of qualitative elements, which is not analytic in any way, but most often refers to methods that assign numeric values to non-numeric data for analysis.
- Because of this, some argue that it’s ultimately a quantitative type.
- Importance: Medium. In general, knowing qualitative data analysis is not common or even necessary for corporate roles. However, for researchers working in social sciences, its importance is very high .
- Nature of Data: data treated under qualitative analysis is non-numeric. However, as part of the analysis, analysts turn non-numeric data into numbers, at which point many argue it is no longer qualitative analysis.
- Motive: to extract insights. (This will be more important as we move down the pyramid.)
Mathematical Analysis
- Description: mathematical data analysis is a subtype of qualitative data analysis that designates methods and techniques based on statistics, algebra, and logical reasoning to extract insights. It stands in opposition to artificial intelligence analysis.
- Importance: Very High. The most widespread methods and techniques fall under mathematical analysis. In fact, it’s so common that many people use “quantitative” and “mathematical” analysis interchangeably.
- Nature of Data: numeric. By definition, all data under mathematical analysis are numbers.
- Motive: to extract measurable insights that can be used to act upon.
Artificial Intelligence & Machine Learning Analysis
- Description: artificial intelligence and machine learning analyses designate techniques based on the titular skills. They are not traditionally mathematical, but they are quantitative since they use numbers. Applications of AI & ML analysis techniques are developing, but they’re not yet mainstream enough to show promise across the field.
- Importance: Medium . As of today (September 2020), you don’t need to be fluent in AI & ML data analysis to be a great analyst. BUT, if it’s a field that interests you, learn it. Many believe that in 10 year’s time its importance will be very high .
- Nature of Data: numeric.
- Motive: to create calculations that build on themselves in order and extract insights without direct input from a human.
Descriptive Analysis
- Description: descriptive analysis is a subtype of mathematical data analysis that uses methods and techniques to provide information about the size, dispersion, groupings, and behavior of data sets. This may sounds complicated, but just think about mean, median, and mode: all three are types of descriptive analysis. They provide information about the data set. We’ll look at specific techniques below.
- Importance: Very high. Descriptive analysis is among the most commonly used data analyses in both corporations and research today.
- Nature of Data: the nature of data under descriptive statistics is sets. A set is simply a collection of numbers that behaves in predictable ways. Data reflects real life, and there are patterns everywhere to be found. Descriptive analysis describes those patterns.
- Motive: the motive behind descriptive analysis is to understand how numbers in a set group together, how far apart they are from each other, and how often they occur. As with most statistical analysis, the more data points there are, the easier it is to describe the set.
Diagnostic Analysis
- Description: diagnostic analysis answers the question “why did it happen?” It is an advanced type of mathematical data analysis that manipulates multiple techniques, but does not own any single one. Analysts engage in diagnostic analysis when they try to explain why.
- Importance: Very high. Diagnostics are probably the most important type of data analysis for people who don’t do analysis because they’re valuable to anyone who’s curious. They’re most common in corporations, as managers often only want to know the “why.”
- Nature of Data : data under diagnostic analysis are data sets. These sets in themselves are not enough under diagnostic analysis. Instead, the analyst must know what’s behind the numbers in order to explain “why.” That’s what makes diagnostics so challenging yet so valuable.
- Motive: the motive behind diagnostics is to diagnose — to understand why.
Predictive Analysis
- Description: predictive analysis uses past data to project future data. It’s very often one of the first kinds of analysis new researchers and corporate analysts use because it is intuitive. It is a subtype of the mathematical type of data analysis, and its three notable techniques are regression, moving average, and exponential smoothing.
- Importance: Very high. Predictive analysis is critical for any data analyst working in a corporate environment. Companies always want to know what the future will hold — especially for their revenue.
- Nature of Data: Because past and future imply time, predictive data always includes an element of time. Whether it’s minutes, hours, days, months, or years, we call this time series data . In fact, this data is so important that I’ll mention it twice so you don’t forget: predictive analysis uses time series data .
- Motive: the motive for investigating time series data with predictive analysis is to predict the future in the most analytical way possible.
Prescriptive Analysis
- Description: prescriptive analysis is a subtype of mathematical analysis that answers the question “what will happen if we do X?” It’s largely underestimated in the data analysis world because it requires diagnostic and descriptive analyses to be done before it even starts. More than simple predictive analysis, prescriptive analysis builds entire data models to show how a simple change could impact the ensemble.
- Importance: High. Prescriptive analysis is most common under the finance function in many companies. Financial analysts use it to build a financial model of the financial statements that show how that data will change given alternative inputs.
- Nature of Data: the nature of data in prescriptive analysis is data sets. These data sets contain patterns that respond differently to various inputs. Data that is useful for prescriptive analysis contains correlations between different variables. It’s through these correlations that we establish patterns and prescribe action on this basis. This analysis cannot be performed on data that exists in a vacuum — it must be viewed on the backdrop of the tangibles behind it.
- Motive: the motive for prescriptive analysis is to establish, with an acceptable degree of certainty, what results we can expect given a certain action. As you might expect, this necessitates that the analyst or researcher be aware of the world behind the data, not just the data itself.
Clustering Method
- Description: the clustering method groups data points together based on their relativeness closeness to further explore and treat them based on these groupings. There are two ways to group clusters: intuitively and statistically (or K-means).
- Importance: Very high. Though most corporate roles group clusters intuitively based on management criteria, a solid understanding of how to group them mathematically is an excellent descriptive and diagnostic approach to allow for prescriptive analysis thereafter.
- Nature of Data : the nature of data useful for clustering is sets with 1 or more data fields. While most people are used to looking at only two dimensions (x and y), clustering becomes more accurate the more fields there are.
- Motive: the motive for clustering is to understand how data sets group and to explore them further based on those groups.
- Here’s an example set:

Classification Method
- Description: the classification method aims to separate and group data points based on common characteristics . This can be done intuitively or statistically.
- Importance: High. While simple on the surface, classification can become quite complex. It’s very valuable in corporate and research environments, but can feel like its not worth the work. A good analyst can execute it quickly to deliver results.
- Nature of Data: the nature of data useful for classification is data sets. As we will see, it can be used on qualitative data as well as quantitative. This method requires knowledge of the substance behind the data, not just the numbers themselves.
- Motive: the motive for classification is group data not based on mathematical relationships (which would be clustering), but by predetermined outputs. This is why it’s less useful for diagnostic analysis, and more useful for prescriptive analysis.
Forecasting Method
- Description: the forecasting method uses time past series data to forecast the future.
- Importance: Very high. Forecasting falls under predictive analysis and is arguably the most common and most important method in the corporate world. It is less useful in research, which prefers to understand the known rather than speculate about the future.
- Nature of Data: data useful for forecasting is time series data, which, as we’ve noted, always includes a variable of time.
- Motive: the motive for the forecasting method is the same as that of prescriptive analysis: the confidently estimate future values.
Optimization Method
- Description: the optimization method maximized or minimizes values in a set given a set of criteria. It is arguably most common in prescriptive analysis. In mathematical terms, it is maximizing or minimizing a function given certain constraints.
- Importance: Very high. The idea of optimization applies to more analysis types than any other method. In fact, some argue that it is the fundamental driver behind data analysis. You would use it everywhere in research and in a corporation.
- Nature of Data: the nature of optimizable data is a data set of at least two points.
- Motive: the motive behind optimization is to achieve the best result possible given certain conditions.
Content Analysis Method
- Description: content analysis is a method of qualitative analysis that quantifies textual data to track themes across a document. It’s most common in academic fields and in social sciences, where written content is the subject of inquiry.
- Importance: High. In a corporate setting, content analysis as such is less common. If anything Nïave Bayes (a technique we’ll look at below) is the closest corporations come to text. However, it is of the utmost importance for researchers. If you’re a researcher, check out this article on content analysis .
- Nature of Data: data useful for content analysis is textual data.
- Motive: the motive behind content analysis is to understand themes expressed in a large text
Narrative Analysis Method
- Description: narrative analysis is a method of qualitative analysis that quantifies stories to trace themes in them. It’s differs from content analysis because it focuses on stories rather than research documents, and the techniques used are slightly different from those in content analysis (very nuances and outside the scope of this article).
- Importance: Low. Unless you are highly specialized in working with stories, narrative analysis rare.
- Nature of Data: the nature of the data useful for the narrative analysis method is narrative text.
- Motive: the motive for narrative analysis is to uncover hidden patterns in narrative text.
Discourse Analysis Method
- Description: the discourse analysis method falls under qualitative analysis and uses thematic coding to trace patterns in real-life discourse. That said, real-life discourse is oral, so it must first be transcribed into text.
- Importance: Low. Unless you are focused on understand real-world idea sharing in a research setting, this kind of analysis is less common than the others on this list.
- Nature of Data: the nature of data useful in discourse analysis is first audio files, then transcriptions of those audio files.
- Motive: the motive behind discourse analysis is to trace patterns of real-world discussions. (As a spooky sidenote, have you ever felt like your phone microphone was listening to you and making reading suggestions? If it was, the method was discourse analysis.)
Framework Analysis Method
- Description: the framework analysis method falls under qualitative analysis and uses similar thematic coding techniques to content analysis. However, where content analysis aims to discover themes, framework analysis starts with a framework and only considers elements that fall in its purview.
- Importance: Low. As with the other textual analysis methods, framework analysis is less common in corporate settings. Even in the world of research, only some use it. Strangely, it’s very common for legislative and political research.
- Nature of Data: the nature of data useful for framework analysis is textual.
- Motive: the motive behind framework analysis is to understand what themes and parts of a text match your search criteria.
Grounded Theory Method
- Description: the grounded theory method falls under qualitative analysis and uses thematic coding to build theories around those themes.
- Importance: Low. Like other qualitative analysis techniques, grounded theory is less common in the corporate world. Even among researchers, you would be hard pressed to find many using it. Though powerful, it’s simply too rare to spend time learning.
- Nature of Data: the nature of data useful in the grounded theory method is textual.
- Motive: the motive of grounded theory method is to establish a series of theories based on themes uncovered from a text.
Clustering Technique: K-Means
- Description: k-means is a clustering technique in which data points are grouped in clusters that have the closest means. Though not considered AI or ML, it inherently requires the use of supervised learning to reevaluate clusters as data points are added. Clustering techniques can be used in diagnostic, descriptive, & prescriptive data analyses.
- Importance: Very important. If you only take 3 things from this article, k-means clustering should be part of it. It is useful in any situation where n observations have multiple characteristics and we want to put them in groups.
- Nature of Data: the nature of data is at least one characteristic per observation, but the more the merrier.
- Motive: the motive for clustering techniques such as k-means is to group observations together and either understand or react to them.
Regression Technique
- Description: simple and multivariable regressions use either one independent variable or combination of multiple independent variables to calculate a correlation to a single dependent variable using constants. Regressions are almost synonymous with correlation today.
- Importance: Very high. Along with clustering, if you only take 3 things from this article, regression techniques should be part of it. They’re everywhere in corporate and research fields alike.
- Nature of Data: the nature of data used is regressions is data sets with “n” number of observations and as many variables as are reasonable. It’s important, however, to distinguish between time series data and regression data. You cannot use regressions or time series data without accounting for time. The easier way is to use techniques under the forecasting method.
- Motive: The motive behind regression techniques is to understand correlations between independent variable(s) and a dependent one.
Nïave Bayes Technique
- Description: Nïave Bayes is a classification technique that uses simple probability to classify items based previous classifications. In plain English, the formula would be “the chance that thing with trait x belongs to class c depends on (=) the overall chance of trait x belonging to class c, multiplied by the overall chance of class c, divided by the overall chance of getting trait x.” As a formula, it’s P(c|x) = P(x|c) * P(c) / P(x).
- Importance: High. Nïave Bayes is a very common, simplistic classification techniques because it’s effective with large data sets and it can be applied to any instant in which there is a class. Google, for example, might use it to group webpages into groups for certain search engine queries.
- Nature of Data: the nature of data for Nïave Bayes is at least one class and at least two traits in a data set.
- Motive: the motive behind Nïave Bayes is to classify observations based on previous data. It’s thus considered part of predictive analysis.
Cohorts Technique
- Description: cohorts technique is a type of clustering method used in behavioral sciences to separate users by common traits. As with clustering, it can be done intuitively or mathematically, the latter of which would simply be k-means.
- Importance: Very high. With regard to resembles k-means, the cohort technique is more of a high-level counterpart. In fact, most people are familiar with it as a part of Google Analytics. It’s most common in marketing departments in corporations, rather than in research.
- Nature of Data: the nature of cohort data is data sets in which users are the observation and other fields are used as defining traits for each cohort.
- Motive: the motive for cohort analysis techniques is to group similar users and analyze how you retain them and how the churn.
Factor Technique
- Description: the factor analysis technique is a way of grouping many traits into a single factor to expedite analysis. For example, factors can be used as traits for Nïave Bayes classifications instead of more general fields.
- Importance: High. While not commonly employed in corporations, factor analysis is hugely valuable. Good data analysts use it to simplify their projects and communicate them more clearly.
- Nature of Data: the nature of data useful in factor analysis techniques is data sets with a large number of fields on its observations.
- Motive: the motive for using factor analysis techniques is to reduce the number of fields in order to more quickly analyze and communicate findings.
Linear Discriminants Technique
- Description: linear discriminant analysis techniques are similar to regressions in that they use one or more independent variable to determine a dependent variable; however, the linear discriminant technique falls under a classifier method since it uses traits as independent variables and class as a dependent variable. In this way, it becomes a classifying method AND a predictive method.
- Importance: High. Though the analyst world speaks of and uses linear discriminants less commonly, it’s a highly valuable technique to keep in mind as you progress in data analysis.
- Nature of Data: the nature of data useful for the linear discriminant technique is data sets with many fields.
- Motive: the motive for using linear discriminants is to classify observations that would be otherwise too complex for simple techniques like Nïave Bayes.
Exponential Smoothing Technique
- Description: exponential smoothing is a technique falling under the forecasting method that uses a smoothing factor on prior data in order to predict future values. It can be linear or adjusted for seasonality. The basic principle behind exponential smoothing is to use a percent weight (value between 0 and 1 called alpha) on more recent values in a series and a smaller percent weight on less recent values. The formula is f(x) = current period value * alpha + previous period value * 1-alpha.
- Importance: High. Most analysts still use the moving average technique (covered next) for forecasting, though it is less efficient than exponential moving, because it’s easy to understand. However, good analysts will have exponential smoothing techniques in their pocket to increase the value of their forecasts.
- Nature of Data: the nature of data useful for exponential smoothing is time series data . Time series data has time as part of its fields .
- Motive: the motive for exponential smoothing is to forecast future values with a smoothing variable.
Moving Average Technique
- Description: the moving average technique falls under the forecasting method and uses an average of recent values to predict future ones. For example, to predict rainfall in April, you would take the average of rainfall from January to March. It’s simple, yet highly effective.
- Importance: Very high. While I’m personally not a huge fan of moving averages due to their simplistic nature and lack of consideration for seasonality, they’re the most common forecasting technique and therefore very important.
- Nature of Data: the nature of data useful for moving averages is time series data .
- Motive: the motive for moving averages is to predict future values is a simple, easy-to-communicate way.
Neural Networks Technique
- Description: neural networks are a highly complex artificial intelligence technique that replicate a human’s neural analysis through a series of hyper-rapid computations and comparisons that evolve in real time. This technique is so complex that an analyst must use computer programs to perform it.
- Importance: Medium. While the potential for neural networks is theoretically unlimited, it’s still little understood and therefore uncommon. You do not need to know it by any means in order to be a data analyst.
- Nature of Data: the nature of data useful for neural networks is data sets of astronomical size, meaning with 100s of 1000s of fields and the same number of row at a minimum .
- Motive: the motive for neural networks is to understand wildly complex phenomenon and data to thereafter act on it.
Decision Tree Technique
- Description: the decision tree technique uses artificial intelligence algorithms to rapidly calculate possible decision pathways and their outcomes on a real-time basis. It’s so complex that computer programs are needed to perform it.
- Importance: Medium. As with neural networks, decision trees with AI are too little understood and are therefore uncommon in corporate and research settings alike.
- Nature of Data: the nature of data useful for the decision tree technique is hierarchical data sets that show multiple optional fields for each preceding field.
- Motive: the motive for decision tree techniques is to compute the optimal choices to make in order to achieve a desired result.
Evolutionary Programming Technique
- Description: the evolutionary programming technique uses a series of neural networks, sees how well each one fits a desired outcome, and selects only the best to test and retest. It’s called evolutionary because is resembles the process of natural selection by weeding out weaker options.
- Importance: Medium. As with the other AI techniques, evolutionary programming just isn’t well-understood enough to be usable in many cases. It’s complexity also makes it hard to explain in corporate settings and difficult to defend in research settings.
- Nature of Data: the nature of data in evolutionary programming is data sets of neural networks, or data sets of data sets.
- Motive: the motive for using evolutionary programming is similar to decision trees: understanding the best possible option from complex data.
- Video example :
Fuzzy Logic Technique
- Description: fuzzy logic is a type of computing based on “approximate truths” rather than simple truths such as “true” and “false.” It is essentially two tiers of classification. For example, to say whether “Apples are good,” you need to first classify that “Good is x, y, z.” Only then can you say apples are good. Another way to see it helping a computer see truth like humans do: “definitely true, probably true, maybe true, probably false, definitely false.”
- Importance: Medium. Like the other AI techniques, fuzzy logic is uncommon in both research and corporate settings, which means it’s less important in today’s world.
- Nature of Data: the nature of fuzzy logic data is huge data tables that include other huge data tables with a hierarchy including multiple subfields for each preceding field.
- Motive: the motive of fuzzy logic to replicate human truth valuations in a computer is to model human decisions based on past data. The obvious possible application is marketing.
Text Analysis Technique
- Description: text analysis techniques fall under the qualitative data analysis type and use text to extract insights.
- Importance: Medium. Text analysis techniques, like all the qualitative analysis type, are most valuable for researchers.
- Nature of Data: the nature of data useful in text analysis is words.
- Motive: the motive for text analysis is to trace themes in a text across sets of very long documents, such as books.
Coding Technique
- Description: the coding technique is used in textual analysis to turn ideas into uniform phrases and analyze the number of times and the ways in which those ideas appear. For this reason, some consider it a quantitative technique as well. You can learn more about coding and the other qualitative techniques here .
- Importance: Very high. If you’re a researcher working in social sciences, coding is THE analysis techniques, and for good reason. It’s a great way to add rigor to analysis. That said, it’s less common in corporate settings.
- Nature of Data: the nature of data useful for coding is long text documents.
- Motive: the motive for coding is to make tracing ideas on paper more than an exercise of the mind by quantifying it and understanding is through descriptive methods.
Idea Pattern Technique
- Description: the idea pattern analysis technique fits into coding as the second step of the process. Once themes and ideas are coded, simple descriptive analysis tests may be run. Some people even cluster the ideas!
- Importance: Very high. If you’re a researcher, idea pattern analysis is as important as the coding itself.
- Nature of Data: the nature of data useful for idea pattern analysis is already coded themes.
- Motive: the motive for the idea pattern technique is to trace ideas in otherwise unmanageably-large documents.
Word Frequency Technique
- Description: word frequency is a qualitative technique that stands in opposition to coding and uses an inductive approach to locate specific words in a document in order to understand its relevance. Word frequency is essentially the descriptive analysis of qualitative data because it uses stats like mean, median, and mode to gather insights.
- Importance: High. As with the other qualitative approaches, word frequency is very important in social science research, but less so in corporate settings.
- Nature of Data: the nature of data useful for word frequency is long, informative documents.
- Motive: the motive for word frequency is to locate target words to determine the relevance of a document in question.
Types of data analysis in research
Types of data analysis in research methodology include every item discussed in this article. As a list, they are:
- Quantitative
- Qualitative
- Mathematical
- Machine Learning and AI
- Descriptive
- Prescriptive
- Classification
- Forecasting
- Optimization
- Grounded theory
- Artificial Neural Networks
- Decision Trees
- Evolutionary Programming
- Fuzzy Logic
- Text analysis
- Idea Pattern Analysis
- Word Frequency Analysis
- Nïave Bayes
- Exponential smoothing
- Moving average
- Linear discriminant
Types of data analysis in qualitative research
As a list, the types of data analysis in qualitative research are the following methods:
Types of data analysis in quantitative research
As a list, the types of data analysis in quantitative research are:
Data analysis methods
As a list, data analysis methods are:
- Content (qualitative)
- Narrative (qualitative)
- Discourse (qualitative)
- Framework (qualitative)
- Grounded theory (qualitative)
Quantitative data analysis methods
As a list, quantitative data analysis methods are:
Tabular View of Data Analysis Types, Methods, and Techniques
About the author.
Noah is the founder & Editor-in-Chief at AnalystAnswers. He is a transatlantic professional and entrepreneur with 5+ years of corporate finance and data analytics experience, as well as 3+ years in consumer financial products and business software. He started AnalystAnswers to provide aspiring professionals with accessible explanations of otherwise dense finance and data concepts. Noah believes everyone can benefit from an analytical mindset in growing digital world. When he's not busy at work, Noah likes to explore new European cities, exercise, and spend time with friends and family.
File available immediately.

Notice: JavaScript is required for this content.

Quantitative Data Analysis: Types, Analysis & Examples

Varun Saharawat is a seasoned professional in the fields of SEO and content writing. With a profound knowledge of the intricate aspects of these disciplines, Varun has established himself as a valuable asset in the world of digital marketing and online content creation.

Analysis of Quantitative data enables you to transform raw data points, typically organised in spreadsheets, into actionable insights. Refer to the article to know more!
Analysis of Quantitative Data : Data, data everywhere — it’s impossible to escape it in today’s digitally connected world. With business and personal activities leaving digital footprints, vast amounts of quantitative data are being generated every second of every day. While data on its own may seem impersonal and cold, in the right hands it can be transformed into valuable insights that drive meaningful decision-making. In this article, we will discuss analysis of quantitative data types and examples!

If you are looking to acquire hands-on experience in quantitative data analysis, look no further than Physics Wallah’s Data Analytics Course . And as a token of appreciation for reading this blog post until the end, use our exclusive coupon code “READER” to get a discount on the course fee.
Table of Contents
What is the Quantitative Analysis Method?
Quantitative Analysis refers to a mathematical approach that gathers and evaluates measurable and verifiable data. This method is utilized to assess performance and various aspects of a business or research. It involves the use of mathematical and statistical techniques to analyze data. Quantitative methods emphasize objective measurements, focusing on statistical, analytical, or numerical analysis of data. It collects data and studies it to derive insights or conclusions.
In a business context, it helps in evaluating the performance and efficiency of operations. Quantitative analysis can be applied across various domains, including finance, research, and chemistry, where data can be converted into numbers for analysis.
Also Read: Analysis vs. Analytics: How Are They Different?
What is the Best Analysis for Quantitative Data?
The “best” analysis for quantitative data largely depends on the specific research objectives, the nature of the data collected, the research questions posed, and the context in which the analysis is conducted. Quantitative data analysis encompasses a wide range of techniques, each suited for different purposes. Here are some commonly employed methods, along with scenarios where they might be considered most appropriate:
1) Descriptive Statistics:
- When to Use: To summarize and describe the basic features of the dataset, providing simple summaries about the sample and measures of central tendency and variability.
- Example: Calculating means, medians, standard deviations, and ranges to describe a dataset.
2) Inferential Statistics:
- When to Use: When you want to make predictions or inferences about a population based on a sample, testing hypotheses, or determining relationships between variables.
- Example: Conducting t-tests to compare means between two groups or performing regression analysis to understand the relationship between an independent variable and a dependent variable.
3) Correlation and Regression Analysis:
- When to Use: To examine relationships between variables, determining the strength and direction of associations, or predicting one variable based on another.
- Example: Assessing the correlation between customer satisfaction scores and sales revenue or predicting house prices based on variables like location, size, and amenities.
4) Factor Analysis:
- When to Use: When dealing with a large set of variables and aiming to identify underlying relationships or latent factors that explain patterns of correlations within the data.
- Example: Exploring underlying constructs influencing employee engagement using survey responses across multiple indicators.
5) Time Series Analysis:
- When to Use: When analyzing data points collected or recorded at successive time intervals to identify patterns, trends, seasonality, or forecast future values.
- Example: Analyzing monthly sales data over several years to detect seasonal trends or forecasting stock prices based on historical data patterns.
6) Cluster Analysis:
- When to Use: To segment a dataset into distinct groups or clusters based on similarities, enabling pattern recognition, customer segmentation, or data reduction.
- Example: Segmenting customers into distinct groups based on purchasing behavior, demographic factors, or preferences.
The “best” analysis for quantitative data is not one-size-fits-all but rather depends on the research objectives, hypotheses, data characteristics, and contextual factors. Often, a combination of analytical techniques may be employed to derive comprehensive insights and address multifaceted research questions effectively. Therefore, selecting the appropriate analysis requires careful consideration of the research goals, methodological rigor, and interpretative relevance to ensure valid, reliable, and actionable outcomes.
Analysis of Quantitative Data in Quantitative Research
Analyzing quantitative data in quantitative research involves a systematic process of examining numerical information to uncover patterns, relationships, and insights that address specific research questions or objectives. Here’s a structured overview of the analysis process:
1) Data Preparation:
- Data Cleaning: Identify and address errors, inconsistencies, missing values, and outliers in the dataset to ensure its integrity and reliability.
- Variable Transformation: Convert variables into appropriate formats or scales, if necessary, for analysis (e.g., normalization, standardization).
2) Descriptive Statistics:
- Central Tendency: Calculate measures like mean, median, and mode to describe the central position of the data.
- Variability: Assess the spread or dispersion of data using measures such as range, variance, standard deviation, and interquartile range.
- Frequency Distribution: Create tables, histograms, or bar charts to display the distribution of values for categorical or discrete variables.
3) Exploratory Data Analysis (EDA):
- Data Visualization: Generate graphical representations like scatter plots, box plots, histograms, or heatmaps to visualize relationships, distributions, and patterns in the data.
- Correlation Analysis: Examine the strength and direction of relationships between variables using correlation coefficients.
4) Inferential Statistics:
- Hypothesis Testing: Formulate null and alternative hypotheses based on research questions, selecting appropriate statistical tests (e.g., t-tests, ANOVA, chi-square tests) to assess differences, associations, or effects.
- Confidence Intervals: Estimate population parameters using sample statistics and determine the range within which the true parameter is likely to fall.
5) Regression Analysis:
- Linear Regression: Identify and quantify relationships between an outcome variable and one or more predictor variables, assessing the strength, direction, and significance of associations.
- Multiple Regression: Evaluate the combined effect of multiple independent variables on a dependent variable, controlling for confounding factors.
6) Factor Analysis and Structural Equation Modeling:
- Factor Analysis: Identify underlying dimensions or constructs that explain patterns of correlations among observed variables, reducing data complexity.
- Structural Equation Modeling (SEM): Examine complex relationships between observed and latent variables, assessing direct and indirect effects within a hypothesized model.
7) Time Series Analysis and Forecasting:
- Trend Analysis: Analyze patterns, trends, and seasonality in time-ordered data to understand historical patterns and predict future values.
- Forecasting Models: Develop predictive models (e.g., ARIMA, exponential smoothing) to anticipate future trends, demand, or outcomes based on historical data patterns.
8) Interpretation and Reporting:
- Interpret Results: Translate statistical findings into meaningful insights, discussing implications, limitations, and conclusions in the context of the research objectives.
- Documentation: Document the analysis process, methodologies, assumptions, and findings systematically for transparency, reproducibility, and peer review.
Also Read: Learning Path to Become a Data Analyst in 2024
Analysis of Quantitative Data Examples
Analyzing quantitative data involves various statistical methods and techniques to derive meaningful insights from numerical data. Here are some examples illustrating the analysis of quantitative data across different contexts:
How to Write Data Analysis in Quantitative Research Proposal?
Writing the data analysis section in a quantitative research proposal requires careful planning and organization to convey a clear, concise, and methodologically sound approach to analyzing the collected data. Here’s a step-by-step guide on how to write the data analysis section effectively:
Step 1: Begin with an Introduction
- Contextualize : Briefly reintroduce the research objectives, questions, and the significance of the study.
- Purpose Statement : Clearly state the purpose of the data analysis section, outlining what readers can expect in this part of the proposal.
Step 2: Describe Data Collection Methods
- Detail Collection Techniques : Provide a concise overview of the methods used for data collection (e.g., surveys, experiments, observations).
- Instrumentation : Mention any tools, instruments, or software employed for data gathering and its relevance.
Step 3 : Discuss Data Cleaning Procedures
- Data Cleaning : Describe the procedures for cleaning and pre-processing the data.
- Handling Outliers & Missing Data : Explain how outliers, missing values, and other inconsistencies will be managed to ensure data quality.
Step 4 : Present Analytical Techniques
- Descriptive Statistics : Outline the descriptive statistics that will be calculated to summarize the data (e.g., mean, median, mode, standard deviation).
- Inferential Statistics : Specify the inferential statistical tests or models planned for deeper analysis (e.g., t-tests, ANOVA, regression).
Step 5: State Hypotheses & Testing Procedures
- Hypothesis Formulation : Clearly state the null and alternative hypotheses based on the research questions or objectives.
- Testing Strategy : Detail the procedures for hypothesis testing, including the chosen significance level (e.g., α = 0.05) and statistical criteria.
Step 6 : Provide a Sample Analysis Plan
- Step-by-Step Plan : Offer a sample plan detailing the sequence of steps involved in the data analysis process.
- Software & Tools : Mention any specific statistical software or tools that will be utilized for analysis.
Step 7 : Address Validity & Reliability
- Validity : Discuss how you will ensure the validity of the data analysis methods and results.
- Reliability : Explain measures taken to enhance the reliability and replicability of the study findings.
Step 8 : Discuss Ethical Considerations
- Ethical Compliance : Address ethical considerations related to data privacy, confidentiality, and informed consent.
- Compliance with Guidelines : Ensure that your data analysis methods align with ethical guidelines and institutional policies.
Step 9 : Acknowledge Limitations
- Limitations : Acknowledge potential limitations in the data analysis methods or data set.
- Mitigation Strategies : Offer strategies or alternative approaches to mitigate identified limitations.
Step 10 : Conclude the Section
- Summary : Summarize the key points discussed in the data analysis section.
- Transition : Provide a smooth transition to subsequent sections of the research proposal, such as the conclusion or references.
Step 11 : Proofread & Revise
- Review : Carefully review the data analysis section for clarity, coherence, and consistency.
- Feedback : Seek feedback from peers, advisors, or mentors to refine your approach and ensure methodological rigor.
What are the 4 Types of Quantitative Analysis?
Quantitative analysis encompasses various methods to evaluate and interpret numerical data. While the specific categorization can vary based on context, here are four broad types of quantitative analysis commonly recognized:
- Descriptive Analysis: This involves summarizing and presenting data to describe its main features, such as mean, median, mode, standard deviation, and range. Descriptive statistics provide a straightforward overview of the dataset’s characteristics.
- Inferential Analysis: This type of analysis uses sample data to make predictions or inferences about a larger population. Techniques like hypothesis testing, regression analysis, and confidence intervals fall under this category. The goal is to draw conclusions that extend beyond the immediate data collected.
- Time-Series Analysis: In this method, data points are collected, recorded, and analyzed over successive time intervals. Time-series analysis helps identify patterns, trends, and seasonal variations within the data. It’s particularly useful in forecasting future values based on historical trends.
- Causal or Experimental Research: This involves establishing a cause-and-effect relationship between variables. Through experimental designs, researchers manipulate one variable to observe the effect on another variable while controlling for external factors. Randomized controlled trials are a common method within this type of quantitative analysis.
Each type of quantitative analysis serves specific purposes and is applied based on the nature of the data and the research objectives.
Also Read: AI and Predictive Analytics: Examples, Tools, Uses, Ai Vs Predictive Analytics
Steps to Effective Quantitative Data Analysis
Quantitative data analysis need not be daunting; it’s a systematic process that anyone can master. To harness actionable insights from your company’s data, follow these structured steps:
Step 1 : Gather Data Strategically
Initiating the analysis journey requires a foundation of relevant data. Employ quantitative research methods to accumulate numerical insights from diverse channels such as:
- Interviews or Focus Groups: Engage directly with stakeholders or customers to gather specific numerical feedback.
- Digital Analytics: Utilize tools like Google Analytics to extract metrics related to website traffic, user behavior, and conversions.
- Observational Tools: Leverage heatmaps, click-through rates, or session recordings to capture user interactions and preferences.
- Structured Questionnaires: Deploy surveys or feedback mechanisms that employ close-ended questions for precise responses.
Ensure that your data collection methods align with your research objectives, focusing on granularity and accuracy.
Step 2 : Refine and Cleanse Your Data
Raw data often comes with imperfections. Scrutinize your dataset to identify and rectify:
- Errors and Inconsistencies: Address any inaccuracies or discrepancies that could mislead your analysis.
- Duplicates: Eliminate repeated data points that can skew results.
- Outliers: Identify and assess outliers, determining whether they should be adjusted or excluded based on contextual relevance.
Cleaning your dataset ensures that subsequent analyses are based on reliable and consistent information, enhancing the credibility of your findings.
Step 3 : Delve into Analysis with Precision
With a refined dataset at your disposal, transition into the analytical phase. Employ both descriptive and inferential analysis techniques:
- Descriptive Analysis: Summarize key attributes of your dataset, computing metrics like averages, distributions, and frequencies.
- Inferential Analysis: Leverage statistical methodologies to derive insights, explore relationships between variables, or formulate predictions.
The objective is not just number crunching but deriving actionable insights. Interpret your findings to discern underlying patterns, correlations, or trends that inform strategic decision-making. For instance, if data indicates a notable relationship between user engagement metrics and specific website features, consider optimizing those features for enhanced user experience.
Step 4 : Visual Representation and Communication
Transforming your analytical outcomes into comprehensible narratives is crucial for organizational alignment and decision-making. Leverage visualization tools and techniques to:
- Craft Engaging Visuals: Develop charts, graphs, or dashboards that encapsulate key findings and insights.
- Highlight Insights: Use visual elements to emphasize critical data points, trends, or comparative metrics effectively.
- Facilitate Stakeholder Engagement: Share your visual representations with relevant stakeholders, ensuring clarity and fostering informed discussions.
Tools like Tableau, Power BI, or specialized platforms like Hotjar can simplify the visualization process, enabling seamless representation and dissemination of your quantitative insights.
Also Read: Top 10 Must Use AI Tools for Data Analysis [2024 Edition]
Statistical Analysis in Quantitative Research
Statistical analysis is a cornerstone of quantitative research, providing the tools and techniques to interpret numerical data systematically. By applying statistical methods, researchers can identify patterns, relationships, and trends within datasets, enabling evidence-based conclusions and informed decision-making. Here’s an overview of the key aspects and methodologies involved in statistical analysis within quantitative research:
- Mean, Median, Mode: Measures of central tendency that summarize the average, middle, and most frequent values in a dataset, respectively.
- Standard Deviation, Variance: Indicators of data dispersion or variability around the mean.
- Frequency Distributions: Tabular or graphical representations that display the distribution of data values or categories.
- Hypothesis Testing: Formal methodologies to test hypotheses or assumptions about population parameters using sample data. Common tests include t-tests, chi-square tests, ANOVA, and regression analysis.
- Confidence Intervals: Estimation techniques that provide a range of values within which a population parameter is likely to lie, based on sample data.
- Correlation and Regression Analysis: Techniques to explore relationships between variables, determining the strength and direction of associations. Regression analysis further enables prediction and modeling based on observed data patterns.
3) Probability Distributions:
- Normal Distribution: A bell-shaped distribution often observed in naturally occurring phenomena, forming the basis for many statistical tests.
- Binomial, Poisson, and Exponential Distributions: Specific probability distributions applicable to discrete or continuous random variables, depending on the nature of the research data.
4) Multivariate Analysis:
- Factor Analysis: A technique to identify underlying relationships between observed variables, often used in survey research or data reduction scenarios.
- Cluster Analysis: Methodologies that group similar objects or individuals based on predefined criteria, enabling segmentation or pattern recognition within datasets.
- Multivariate Regression: Extending regression analysis to multiple independent variables, assessing their collective impact on a dependent variable.
5) Data Modeling and Forecasting:
- Time Series Analysis: Analyzing data points collected or recorded at specific time intervals to identify patterns, trends, or seasonality.
- Predictive Analytics: Leveraging statistical models and machine learning algorithms to forecast future trends, outcomes, or behaviors based on historical data.
If this blog post has piqued your interest in the field of data analytics, then we highly recommend checking out Physics Wallah’s Data Analytics Course . This course covers all the fundamental concepts of quantitative data analysis and provides hands-on training for various tools and software used in the industry.
With a team of experienced instructors from different backgrounds and industries, you will gain a comprehensive understanding of a wide range of topics related to data analytics. And as an added bonus for being one of our dedicated readers, use the coupon code “ READER ” to get an exclusive discount on this course!
For Latest Tech Related Information, Join Our Official Free Telegram Group : PW Skills Telegram Group
Analysis of Quantitative Data FAQs
What is quantitative data analysis.
Quantitative data analysis involves the systematic process of collecting, cleaning, interpreting, and presenting numerical data to identify patterns, trends, and relationships through statistical methods and mathematical calculations.
What are the main steps involved in quantitative data analysis?
The primary steps include data collection, data cleaning, statistical analysis (descriptive and inferential), interpretation of results, and visualization of findings using graphs or charts.
What is the difference between descriptive and inferential analysis?
Descriptive analysis summarizes and describes the main aspects of the dataset (e.g., mean, median, mode), while inferential analysis draws conclusions or predictions about a population based on a sample, using statistical tests and models.
How do I handle outliers in my quantitative data?
Outliers can be managed by identifying them through statistical methods, understanding their nature (error or valid data), and deciding whether to remove them, transform them, or conduct separate analyses to understand their impact.
Which statistical tests should I use for my quantitative research?
The choice of statistical tests depends on your research design, data type, and research questions. Common tests include t-tests, ANOVA, regression analysis, chi-square tests, and correlation analysis, among others.
- Big Data Defined: Examples and Benefits

Big data is a tremendous volume of complex data collected from various sources, such as text, videos, audio, email, etc.…
- The 11 Best Analytical Tools For Data Analysis in 2024

Data Analytical tools help to extract important insights from raw and unstructured data. Read this article to get a list…
- Top 20 Big Data Tools Used By Professionals

There are plenty of big data tools available online for free. However, some of the handpicked big data tools used…
Related Articles
- Best Courses For Data Analytics: Top 10 Courses For Your Career in Trend
- 10 Most Popular Big Data Analytics Tools
- Top Best Big Data Analytics Classes 2024
- Big Data and Analytics – Definition, Benefits, and More
- Best 5 Unique Strategies to Use Artificial Intelligence Data Analytics
- Best BI Tool: Top 15 Business Intelligence Tools (BI Tools)
- Applications of Big Data
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Qualitative vs. Quantitative Research | Differences, Examples & Methods
Qualitative vs. Quantitative Research | Differences, Examples & Methods
Published on April 12, 2019 by Raimo Streefkerk . Revised on June 22, 2023.
When collecting and analyzing data, quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Both are important for gaining different kinds of knowledge.
Common quantitative methods include experiments, observations recorded as numbers, and surveys with closed-ended questions.
Quantitative research is at risk for research biases including information bias , omitted variable bias , sampling bias , or selection bias . Qualitative research Qualitative research is expressed in words . It is used to understand concepts, thoughts or experiences. This type of research enables you to gather in-depth insights on topics that are not well understood.
Common qualitative methods include interviews with open-ended questions, observations described in words, and literature reviews that explore concepts and theories.
Table of contents
The differences between quantitative and qualitative research, data collection methods, when to use qualitative vs. quantitative research, how to analyze qualitative and quantitative data, other interesting articles, frequently asked questions about qualitative and quantitative research.
Quantitative and qualitative research use different research methods to collect and analyze data, and they allow you to answer different kinds of research questions.

Quantitative and qualitative data can be collected using various methods. It is important to use a data collection method that will help answer your research question(s).
Many data collection methods can be either qualitative or quantitative. For example, in surveys, observational studies or case studies , your data can be represented as numbers (e.g., using rating scales or counting frequencies) or as words (e.g., with open-ended questions or descriptions of what you observe).
However, some methods are more commonly used in one type or the other.
Quantitative data collection methods
- Surveys : List of closed or multiple choice questions that is distributed to a sample (online, in person, or over the phone).
- Experiments : Situation in which different types of variables are controlled and manipulated to establish cause-and-effect relationships.
- Observations : Observing subjects in a natural environment where variables can’t be controlled.
Qualitative data collection methods
- Interviews : Asking open-ended questions verbally to respondents.
- Focus groups : Discussion among a group of people about a topic to gather opinions that can be used for further research.
- Ethnography : Participating in a community or organization for an extended period of time to closely observe culture and behavior.
- Literature review : Survey of published works by other authors.
A rule of thumb for deciding whether to use qualitative or quantitative data is:
- Use quantitative research if you want to confirm or test something (a theory or hypothesis )
- Use qualitative research if you want to understand something (concepts, thoughts, experiences)
For most research topics you can choose a qualitative, quantitative or mixed methods approach . Which type you choose depends on, among other things, whether you’re taking an inductive vs. deductive research approach ; your research question(s) ; whether you’re doing experimental , correlational , or descriptive research ; and practical considerations such as time, money, availability of data, and access to respondents.
Quantitative research approach
You survey 300 students at your university and ask them questions such as: “on a scale from 1-5, how satisfied are your with your professors?”
You can perform statistical analysis on the data and draw conclusions such as: “on average students rated their professors 4.4”.
Qualitative research approach
You conduct in-depth interviews with 15 students and ask them open-ended questions such as: “How satisfied are you with your studies?”, “What is the most positive aspect of your study program?” and “What can be done to improve the study program?”
Based on the answers you get you can ask follow-up questions to clarify things. You transcribe all interviews using transcription software and try to find commonalities and patterns.
Mixed methods approach
You conduct interviews to find out how satisfied students are with their studies. Through open-ended questions you learn things you never thought about before and gain new insights. Later, you use a survey to test these insights on a larger scale.
It’s also possible to start with a survey to find out the overall trends, followed by interviews to better understand the reasons behind the trends.
Qualitative or quantitative data by itself can’t prove or demonstrate anything, but has to be analyzed to show its meaning in relation to the research questions. The method of analysis differs for each type of data.
Analyzing quantitative data
Quantitative data is based on numbers. Simple math or more advanced statistical analysis is used to discover commonalities or patterns in the data. The results are often reported in graphs and tables.
Applications such as Excel, SPSS, or R can be used to calculate things like:
- Average scores ( means )
- The number of times a particular answer was given
- The correlation or causation between two or more variables
- The reliability and validity of the results
Analyzing qualitative data
Qualitative data is more difficult to analyze than quantitative data. It consists of text, images or videos instead of numbers.
Some common approaches to analyzing qualitative data include:
- Qualitative content analysis : Tracking the occurrence, position and meaning of words or phrases
- Thematic analysis : Closely examining the data to identify the main themes and patterns
- Discourse analysis : Studying how communication works in social contexts
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Chi square goodness of fit test
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Inclusion and exclusion criteria
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
A research project is an academic, scientific, or professional undertaking to answer a research question . Research projects can take many forms, such as qualitative or quantitative , descriptive , longitudinal , experimental , or correlational . What kind of research approach you choose will depend on your topic.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Streefkerk, R. (2023, June 22). Qualitative vs. Quantitative Research | Differences, Examples & Methods. Scribbr. Retrieved April 9, 2024, from https://www.scribbr.com/methodology/qualitative-quantitative-research/
Is this article helpful?

Raimo Streefkerk
Other students also liked, what is quantitative research | definition, uses & methods, what is qualitative research | methods & examples, mixed methods research | definition, guide & examples, unlimited academic ai-proofreading.
✔ Document error-free in 5minutes ✔ Unlimited document corrections ✔ Specialized in correcting academic texts
Qualitative vs Quantitative Research Methods & Data Analysis
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
What is the difference between quantitative and qualitative?
The main difference between quantitative and qualitative research is the type of data they collect and analyze.
Quantitative research collects numerical data and analyzes it using statistical methods. The aim is to produce objective, empirical data that can be measured and expressed in numerical terms. Quantitative research is often used to test hypotheses, identify patterns, and make predictions.
Qualitative research , on the other hand, collects non-numerical data such as words, images, and sounds. The focus is on exploring subjective experiences, opinions, and attitudes, often through observation and interviews.
Qualitative research aims to produce rich and detailed descriptions of the phenomenon being studied, and to uncover new insights and meanings.
Quantitative data is information about quantities, and therefore numbers, and qualitative data is descriptive, and regards phenomenon which can be observed but not measured, such as language.
What Is Qualitative Research?
Qualitative research is the process of collecting, analyzing, and interpreting non-numerical data, such as language. Qualitative research can be used to understand how an individual subjectively perceives and gives meaning to their social reality.
Qualitative data is non-numerical data, such as text, video, photographs, or audio recordings. This type of data can be collected using diary accounts or in-depth interviews and analyzed using grounded theory or thematic analysis.
Qualitative research is multimethod in focus, involving an interpretive, naturalistic approach to its subject matter. This means that qualitative researchers study things in their natural settings, attempting to make sense of, or interpret, phenomena in terms of the meanings people bring to them. Denzin and Lincoln (1994, p. 2)
Interest in qualitative data came about as the result of the dissatisfaction of some psychologists (e.g., Carl Rogers) with the scientific study of psychologists such as behaviorists (e.g., Skinner ).
Since psychologists study people, the traditional approach to science is not seen as an appropriate way of carrying out research since it fails to capture the totality of human experience and the essence of being human. Exploring participants’ experiences is known as a phenomenological approach (re: Humanism ).
Qualitative research is primarily concerned with meaning, subjectivity, and lived experience. The goal is to understand the quality and texture of people’s experiences, how they make sense of them, and the implications for their lives.
Qualitative research aims to understand the social reality of individuals, groups, and cultures as nearly as possible as participants feel or live it. Thus, people and groups are studied in their natural setting.
Some examples of qualitative research questions are provided, such as what an experience feels like, how people talk about something, how they make sense of an experience, and how events unfold for people.
Research following a qualitative approach is exploratory and seeks to explain ‘how’ and ‘why’ a particular phenomenon, or behavior, operates as it does in a particular context. It can be used to generate hypotheses and theories from the data.
Qualitative Methods
There are different types of qualitative research methods, including diary accounts, in-depth interviews , documents, focus groups , case study research , and ethnography.
The results of qualitative methods provide a deep understanding of how people perceive their social realities and in consequence, how they act within the social world.
The researcher has several methods for collecting empirical materials, ranging from the interview to direct observation, to the analysis of artifacts, documents, and cultural records, to the use of visual materials or personal experience. Denzin and Lincoln (1994, p. 14)
Here are some examples of qualitative data:
Interview transcripts : Verbatim records of what participants said during an interview or focus group. They allow researchers to identify common themes and patterns, and draw conclusions based on the data. Interview transcripts can also be useful in providing direct quotes and examples to support research findings.
Observations : The researcher typically takes detailed notes on what they observe, including any contextual information, nonverbal cues, or other relevant details. The resulting observational data can be analyzed to gain insights into social phenomena, such as human behavior, social interactions, and cultural practices.
Unstructured interviews : generate qualitative data through the use of open questions. This allows the respondent to talk in some depth, choosing their own words. This helps the researcher develop a real sense of a person’s understanding of a situation.
Diaries or journals : Written accounts of personal experiences or reflections.
Notice that qualitative data could be much more than just words or text. Photographs, videos, sound recordings, and so on, can be considered qualitative data. Visual data can be used to understand behaviors, environments, and social interactions.
Qualitative Data Analysis
Qualitative research is endlessly creative and interpretive. The researcher does not just leave the field with mountains of empirical data and then easily write up his or her findings.
Qualitative interpretations are constructed, and various techniques can be used to make sense of the data, such as content analysis, grounded theory (Glaser & Strauss, 1967), thematic analysis (Braun & Clarke, 2006), or discourse analysis.
For example, thematic analysis is a qualitative approach that involves identifying implicit or explicit ideas within the data. Themes will often emerge once the data has been coded.

Key Features
- Events can be understood adequately only if they are seen in context. Therefore, a qualitative researcher immerses her/himself in the field, in natural surroundings. The contexts of inquiry are not contrived; they are natural. Nothing is predefined or taken for granted.
- Qualitative researchers want those who are studied to speak for themselves, to provide their perspectives in words and other actions. Therefore, qualitative research is an interactive process in which the persons studied teach the researcher about their lives.
- The qualitative researcher is an integral part of the data; without the active participation of the researcher, no data exists.
- The study’s design evolves during the research and can be adjusted or changed as it progresses. For the qualitative researcher, there is no single reality. It is subjective and exists only in reference to the observer.
- The theory is data-driven and emerges as part of the research process, evolving from the data as they are collected.
Limitations of Qualitative Research
- Because of the time and costs involved, qualitative designs do not generally draw samples from large-scale data sets.
- The problem of adequate validity or reliability is a major criticism. Because of the subjective nature of qualitative data and its origin in single contexts, it is difficult to apply conventional standards of reliability and validity. For example, because of the central role played by the researcher in the generation of data, it is not possible to replicate qualitative studies.
- Also, contexts, situations, events, conditions, and interactions cannot be replicated to any extent, nor can generalizations be made to a wider context than the one studied with confidence.
- The time required for data collection, analysis, and interpretation is lengthy. Analysis of qualitative data is difficult, and expert knowledge of an area is necessary to interpret qualitative data. Great care must be taken when doing so, for example, looking for mental illness symptoms.
Advantages of Qualitative Research
- Because of close researcher involvement, the researcher gains an insider’s view of the field. This allows the researcher to find issues that are often missed (such as subtleties and complexities) by the scientific, more positivistic inquiries.
- Qualitative descriptions can be important in suggesting possible relationships, causes, effects, and dynamic processes.
- Qualitative analysis allows for ambiguities/contradictions in the data, which reflect social reality (Denscombe, 2010).
- Qualitative research uses a descriptive, narrative style; this research might be of particular benefit to the practitioner as she or he could turn to qualitative reports to examine forms of knowledge that might otherwise be unavailable, thereby gaining new insight.
What Is Quantitative Research?
Quantitative research involves the process of objectively collecting and analyzing numerical data to describe, predict, or control variables of interest.
The goals of quantitative research are to test causal relationships between variables , make predictions, and generalize results to wider populations.
Quantitative researchers aim to establish general laws of behavior and phenomenon across different settings/contexts. Research is used to test a theory and ultimately support or reject it.
Quantitative Methods
Experiments typically yield quantitative data, as they are concerned with measuring things. However, other research methods, such as controlled observations and questionnaires , can produce both quantitative information.
For example, a rating scale or closed questions on a questionnaire would generate quantitative data as these produce either numerical data or data that can be put into categories (e.g., “yes,” “no” answers).
Experimental methods limit how research participants react to and express appropriate social behavior.
Findings are, therefore, likely to be context-bound and simply a reflection of the assumptions that the researcher brings to the investigation.
There are numerous examples of quantitative data in psychological research, including mental health. Here are a few examples:
Another example is the Experience in Close Relationships Scale (ECR), a self-report questionnaire widely used to assess adult attachment styles .
The ECR provides quantitative data that can be used to assess attachment styles and predict relationship outcomes.
Neuroimaging data : Neuroimaging techniques, such as MRI and fMRI, provide quantitative data on brain structure and function.
This data can be analyzed to identify brain regions involved in specific mental processes or disorders.
For example, the Beck Depression Inventory (BDI) is a clinician-administered questionnaire widely used to assess the severity of depressive symptoms in individuals.
The BDI consists of 21 questions, each scored on a scale of 0 to 3, with higher scores indicating more severe depressive symptoms.
Quantitative Data Analysis
Statistics help us turn quantitative data into useful information to help with decision-making. We can use statistics to summarize our data, describing patterns, relationships, and connections. Statistics can be descriptive or inferential.
Descriptive statistics help us to summarize our data. In contrast, inferential statistics are used to identify statistically significant differences between groups of data (such as intervention and control groups in a randomized control study).
- Quantitative researchers try to control extraneous variables by conducting their studies in the lab.
- The research aims for objectivity (i.e., without bias) and is separated from the data.
- The design of the study is determined before it begins.
- For the quantitative researcher, the reality is objective, exists separately from the researcher, and can be seen by anyone.
- Research is used to test a theory and ultimately support or reject it.
Limitations of Quantitative Research
- Context: Quantitative experiments do not take place in natural settings. In addition, they do not allow participants to explain their choices or the meaning of the questions they may have for those participants (Carr, 1994).
- Researcher expertise: Poor knowledge of the application of statistical analysis may negatively affect analysis and subsequent interpretation (Black, 1999).
- Variability of data quantity: Large sample sizes are needed for more accurate analysis. Small-scale quantitative studies may be less reliable because of the low quantity of data (Denscombe, 2010). This also affects the ability to generalize study findings to wider populations.
- Confirmation bias: The researcher might miss observing phenomena because of focus on theory or hypothesis testing rather than on the theory of hypothesis generation.
Advantages of Quantitative Research
- Scientific objectivity: Quantitative data can be interpreted with statistical analysis, and since statistics are based on the principles of mathematics, the quantitative approach is viewed as scientifically objective and rational (Carr, 1994; Denscombe, 2010).
- Useful for testing and validating already constructed theories.
- Rapid analysis: Sophisticated software removes much of the need for prolonged data analysis, especially with large volumes of data involved (Antonius, 2003).
- Replication: Quantitative data is based on measured values and can be checked by others because numerical data is less open to ambiguities of interpretation.
- Hypotheses can also be tested because of statistical analysis (Antonius, 2003).
Antonius, R. (2003). Interpreting quantitative data with SPSS . Sage.
Black, T. R. (1999). Doing quantitative research in the social sciences: An integrated approach to research design, measurement and statistics . Sage.
Braun, V. & Clarke, V. (2006). Using thematic analysis in psychology . Qualitative Research in Psychology , 3, 77–101.
Carr, L. T. (1994). The strengths and weaknesses of quantitative and qualitative research : what method for nursing? Journal of advanced nursing, 20(4) , 716-721.
Denscombe, M. (2010). The Good Research Guide: for small-scale social research. McGraw Hill.
Denzin, N., & Lincoln. Y. (1994). Handbook of Qualitative Research. Thousand Oaks, CA, US: Sage Publications Inc.
Glaser, B. G., Strauss, A. L., & Strutzel, E. (1968). The discovery of grounded theory; strategies for qualitative research. Nursing research, 17(4) , 364.
Minichiello, V. (1990). In-Depth Interviewing: Researching People. Longman Cheshire.
Punch, K. (1998). Introduction to Social Research: Quantitative and Qualitative Approaches. London: Sage
Further Information
- Designing qualitative research
- Methods of data collection and analysis
- Introduction to quantitative and qualitative research
- Checklists for improving rigour in qualitative research: a case of the tail wagging the dog?
- Qualitative research in health care: Analysing qualitative data
- Qualitative data analysis: the framework approach
- Using the framework method for the analysis of
- Qualitative data in multi-disciplinary health research
- Content Analysis
- Grounded Theory
- Thematic Analysis

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.37(16); 2022 Apr 25
A Practical Guide to Writing Quantitative and Qualitative Research Questions and Hypotheses in Scholarly Articles
Edward barroga.
1 Department of General Education, Graduate School of Nursing Science, St. Luke’s International University, Tokyo, Japan.
Glafera Janet Matanguihan
2 Department of Biological Sciences, Messiah University, Mechanicsburg, PA, USA.
The development of research questions and the subsequent hypotheses are prerequisites to defining the main research purpose and specific objectives of a study. Consequently, these objectives determine the study design and research outcome. The development of research questions is a process based on knowledge of current trends, cutting-edge studies, and technological advances in the research field. Excellent research questions are focused and require a comprehensive literature search and in-depth understanding of the problem being investigated. Initially, research questions may be written as descriptive questions which could be developed into inferential questions. These questions must be specific and concise to provide a clear foundation for developing hypotheses. Hypotheses are more formal predictions about the research outcomes. These specify the possible results that may or may not be expected regarding the relationship between groups. Thus, research questions and hypotheses clarify the main purpose and specific objectives of the study, which in turn dictate the design of the study, its direction, and outcome. Studies developed from good research questions and hypotheses will have trustworthy outcomes with wide-ranging social and health implications.
INTRODUCTION
Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses. 1 , 2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results. 3 , 4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the inception of novel studies and the ethical testing of ideas. 5 , 6
It is crucial to have knowledge of both quantitative and qualitative research 2 as both types of research involve writing research questions and hypotheses. 7 However, these crucial elements of research are sometimes overlooked; if not overlooked, then framed without the forethought and meticulous attention it needs. Planning and careful consideration are needed when developing quantitative or qualitative research, particularly when conceptualizing research questions and hypotheses. 4
There is a continuing need to support researchers in the creation of innovative research questions and hypotheses, as well as for journal articles that carefully review these elements. 1 When research questions and hypotheses are not carefully thought of, unethical studies and poor outcomes usually ensue. Carefully formulated research questions and hypotheses define well-founded objectives, which in turn determine the appropriate design, course, and outcome of the study. This article then aims to discuss in detail the various aspects of crafting research questions and hypotheses, with the goal of guiding researchers as they develop their own. Examples from the authors and peer-reviewed scientific articles in the healthcare field are provided to illustrate key points.
DEFINITIONS AND RELATIONSHIP OF RESEARCH QUESTIONS AND HYPOTHESES
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. Thus, the research question gives a preview of the different parts and variables of the study meant to address the problem posed in the research question. 1 An excellent research question clarifies the research writing while facilitating understanding of the research topic, objective, scope, and limitations of the study. 5
On the other hand, a research hypothesis is an educated statement of an expected outcome. This statement is based on background research and current knowledge. 8 , 9 The research hypothesis makes a specific prediction about a new phenomenon 10 or a formal statement on the expected relationship between an independent variable and a dependent variable. 3 , 11 It provides a tentative answer to the research question to be tested or explored. 4
Hypotheses employ reasoning to predict a theory-based outcome. 10 These can also be developed from theories by focusing on components of theories that have not yet been observed. 10 The validity of hypotheses is often based on the testability of the prediction made in a reproducible experiment. 8
Conversely, hypotheses can also be rephrased as research questions. Several hypotheses based on existing theories and knowledge may be needed to answer a research question. Developing ethical research questions and hypotheses creates a research design that has logical relationships among variables. These relationships serve as a solid foundation for the conduct of the study. 4 , 11 Haphazardly constructed research questions can result in poorly formulated hypotheses and improper study designs, leading to unreliable results. Thus, the formulations of relevant research questions and verifiable hypotheses are crucial when beginning research. 12
CHARACTERISTICS OF GOOD RESEARCH QUESTIONS AND HYPOTHESES
Excellent research questions are specific and focused. These integrate collective data and observations to confirm or refute the subsequent hypotheses. Well-constructed hypotheses are based on previous reports and verify the research context. These are realistic, in-depth, sufficiently complex, and reproducible. More importantly, these hypotheses can be addressed and tested. 13
There are several characteristics of well-developed hypotheses. Good hypotheses are 1) empirically testable 7 , 10 , 11 , 13 ; 2) backed by preliminary evidence 9 ; 3) testable by ethical research 7 , 9 ; 4) based on original ideas 9 ; 5) have evidenced-based logical reasoning 10 ; and 6) can be predicted. 11 Good hypotheses can infer ethical and positive implications, indicating the presence of a relationship or effect relevant to the research theme. 7 , 11 These are initially developed from a general theory and branch into specific hypotheses by deductive reasoning. In the absence of a theory to base the hypotheses, inductive reasoning based on specific observations or findings form more general hypotheses. 10
TYPES OF RESEARCH QUESTIONS AND HYPOTHESES
Research questions and hypotheses are developed according to the type of research, which can be broadly classified into quantitative and qualitative research. We provide a summary of the types of research questions and hypotheses under quantitative and qualitative research categories in Table 1 .
Research questions in quantitative research
In quantitative research, research questions inquire about the relationships among variables being investigated and are usually framed at the start of the study. These are precise and typically linked to the subject population, dependent and independent variables, and research design. 1 Research questions may also attempt to describe the behavior of a population in relation to one or more variables, or describe the characteristics of variables to be measured ( descriptive research questions ). 1 , 5 , 14 These questions may also aim to discover differences between groups within the context of an outcome variable ( comparative research questions ), 1 , 5 , 14 or elucidate trends and interactions among variables ( relationship research questions ). 1 , 5 We provide examples of descriptive, comparative, and relationship research questions in quantitative research in Table 2 .
Hypotheses in quantitative research
In quantitative research, hypotheses predict the expected relationships among variables. 15 Relationships among variables that can be predicted include 1) between a single dependent variable and a single independent variable ( simple hypothesis ) or 2) between two or more independent and dependent variables ( complex hypothesis ). 4 , 11 Hypotheses may also specify the expected direction to be followed and imply an intellectual commitment to a particular outcome ( directional hypothesis ) 4 . On the other hand, hypotheses may not predict the exact direction and are used in the absence of a theory, or when findings contradict previous studies ( non-directional hypothesis ). 4 In addition, hypotheses can 1) define interdependency between variables ( associative hypothesis ), 4 2) propose an effect on the dependent variable from manipulation of the independent variable ( causal hypothesis ), 4 3) state a negative relationship between two variables ( null hypothesis ), 4 , 11 , 15 4) replace the working hypothesis if rejected ( alternative hypothesis ), 15 explain the relationship of phenomena to possibly generate a theory ( working hypothesis ), 11 5) involve quantifiable variables that can be tested statistically ( statistical hypothesis ), 11 6) or express a relationship whose interlinks can be verified logically ( logical hypothesis ). 11 We provide examples of simple, complex, directional, non-directional, associative, causal, null, alternative, working, statistical, and logical hypotheses in quantitative research, as well as the definition of quantitative hypothesis-testing research in Table 3 .
Research questions in qualitative research
Unlike research questions in quantitative research, research questions in qualitative research are usually continuously reviewed and reformulated. The central question and associated subquestions are stated more than the hypotheses. 15 The central question broadly explores a complex set of factors surrounding the central phenomenon, aiming to present the varied perspectives of participants. 15
There are varied goals for which qualitative research questions are developed. These questions can function in several ways, such as to 1) identify and describe existing conditions ( contextual research question s); 2) describe a phenomenon ( descriptive research questions ); 3) assess the effectiveness of existing methods, protocols, theories, or procedures ( evaluation research questions ); 4) examine a phenomenon or analyze the reasons or relationships between subjects or phenomena ( explanatory research questions ); or 5) focus on unknown aspects of a particular topic ( exploratory research questions ). 5 In addition, some qualitative research questions provide new ideas for the development of theories and actions ( generative research questions ) or advance specific ideologies of a position ( ideological research questions ). 1 Other qualitative research questions may build on a body of existing literature and become working guidelines ( ethnographic research questions ). Research questions may also be broadly stated without specific reference to the existing literature or a typology of questions ( phenomenological research questions ), may be directed towards generating a theory of some process ( grounded theory questions ), or may address a description of the case and the emerging themes ( qualitative case study questions ). 15 We provide examples of contextual, descriptive, evaluation, explanatory, exploratory, generative, ideological, ethnographic, phenomenological, grounded theory, and qualitative case study research questions in qualitative research in Table 4 , and the definition of qualitative hypothesis-generating research in Table 5 .
Qualitative studies usually pose at least one central research question and several subquestions starting with How or What . These research questions use exploratory verbs such as explore or describe . These also focus on one central phenomenon of interest, and may mention the participants and research site. 15
Hypotheses in qualitative research
Hypotheses in qualitative research are stated in the form of a clear statement concerning the problem to be investigated. Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes. 2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed-methods research question can be developed. 1
FRAMEWORKS FOR DEVELOPING RESEARCH QUESTIONS AND HYPOTHESES
Research questions followed by hypotheses should be developed before the start of the study. 1 , 12 , 14 It is crucial to develop feasible research questions on a topic that is interesting to both the researcher and the scientific community. This can be achieved by a meticulous review of previous and current studies to establish a novel topic. Specific areas are subsequently focused on to generate ethical research questions. The relevance of the research questions is evaluated in terms of clarity of the resulting data, specificity of the methodology, objectivity of the outcome, depth of the research, and impact of the study. 1 , 5 These aspects constitute the FINER criteria (i.e., Feasible, Interesting, Novel, Ethical, and Relevant). 1 Clarity and effectiveness are achieved if research questions meet the FINER criteria. In addition to the FINER criteria, Ratan et al. described focus, complexity, novelty, feasibility, and measurability for evaluating the effectiveness of research questions. 14
The PICOT and PEO frameworks are also used when developing research questions. 1 The following elements are addressed in these frameworks, PICOT: P-population/patients/problem, I-intervention or indicator being studied, C-comparison group, O-outcome of interest, and T-timeframe of the study; PEO: P-population being studied, E-exposure to preexisting conditions, and O-outcome of interest. 1 Research questions are also considered good if these meet the “FINERMAPS” framework: Feasible, Interesting, Novel, Ethical, Relevant, Manageable, Appropriate, Potential value/publishable, and Systematic. 14
As we indicated earlier, research questions and hypotheses that are not carefully formulated result in unethical studies or poor outcomes. To illustrate this, we provide some examples of ambiguous research question and hypotheses that result in unclear and weak research objectives in quantitative research ( Table 6 ) 16 and qualitative research ( Table 7 ) 17 , and how to transform these ambiguous research question(s) and hypothesis(es) into clear and good statements.
a These statements were composed for comparison and illustrative purposes only.
b These statements are direct quotes from Higashihara and Horiuchi. 16
a This statement is a direct quote from Shimoda et al. 17
The other statements were composed for comparison and illustrative purposes only.
CONSTRUCTING RESEARCH QUESTIONS AND HYPOTHESES
To construct effective research questions and hypotheses, it is very important to 1) clarify the background and 2) identify the research problem at the outset of the research, within a specific timeframe. 9 Then, 3) review or conduct preliminary research to collect all available knowledge about the possible research questions by studying theories and previous studies. 18 Afterwards, 4) construct research questions to investigate the research problem. Identify variables to be accessed from the research questions 4 and make operational definitions of constructs from the research problem and questions. Thereafter, 5) construct specific deductive or inductive predictions in the form of hypotheses. 4 Finally, 6) state the study aims . This general flow for constructing effective research questions and hypotheses prior to conducting research is shown in Fig. 1 .

Research questions are used more frequently in qualitative research than objectives or hypotheses. 3 These questions seek to discover, understand, explore or describe experiences by asking “What” or “How.” The questions are open-ended to elicit a description rather than to relate variables or compare groups. The questions are continually reviewed, reformulated, and changed during the qualitative study. 3 Research questions are also used more frequently in survey projects than hypotheses in experiments in quantitative research to compare variables and their relationships.
Hypotheses are constructed based on the variables identified and as an if-then statement, following the template, ‘If a specific action is taken, then a certain outcome is expected.’ At this stage, some ideas regarding expectations from the research to be conducted must be drawn. 18 Then, the variables to be manipulated (independent) and influenced (dependent) are defined. 4 Thereafter, the hypothesis is stated and refined, and reproducible data tailored to the hypothesis are identified, collected, and analyzed. 4 The hypotheses must be testable and specific, 18 and should describe the variables and their relationships, the specific group being studied, and the predicted research outcome. 18 Hypotheses construction involves a testable proposition to be deduced from theory, and independent and dependent variables to be separated and measured separately. 3 Therefore, good hypotheses must be based on good research questions constructed at the start of a study or trial. 12
In summary, research questions are constructed after establishing the background of the study. Hypotheses are then developed based on the research questions. Thus, it is crucial to have excellent research questions to generate superior hypotheses. In turn, these would determine the research objectives and the design of the study, and ultimately, the outcome of the research. 12 Algorithms for building research questions and hypotheses are shown in Fig. 2 for quantitative research and in Fig. 3 for qualitative research.

EXAMPLES OF RESEARCH QUESTIONS FROM PUBLISHED ARTICLES
- EXAMPLE 1. Descriptive research question (quantitative research)
- - Presents research variables to be assessed (distinct phenotypes and subphenotypes)
- “BACKGROUND: Since COVID-19 was identified, its clinical and biological heterogeneity has been recognized. Identifying COVID-19 phenotypes might help guide basic, clinical, and translational research efforts.
- RESEARCH QUESTION: Does the clinical spectrum of patients with COVID-19 contain distinct phenotypes and subphenotypes? ” 19
- EXAMPLE 2. Relationship research question (quantitative research)
- - Shows interactions between dependent variable (static postural control) and independent variable (peripheral visual field loss)
- “Background: Integration of visual, vestibular, and proprioceptive sensations contributes to postural control. People with peripheral visual field loss have serious postural instability. However, the directional specificity of postural stability and sensory reweighting caused by gradual peripheral visual field loss remain unclear.
- Research question: What are the effects of peripheral visual field loss on static postural control ?” 20
- EXAMPLE 3. Comparative research question (quantitative research)
- - Clarifies the difference among groups with an outcome variable (patients enrolled in COMPERA with moderate PH or severe PH in COPD) and another group without the outcome variable (patients with idiopathic pulmonary arterial hypertension (IPAH))
- “BACKGROUND: Pulmonary hypertension (PH) in COPD is a poorly investigated clinical condition.
- RESEARCH QUESTION: Which factors determine the outcome of PH in COPD?
- STUDY DESIGN AND METHODS: We analyzed the characteristics and outcome of patients enrolled in the Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension (COMPERA) with moderate or severe PH in COPD as defined during the 6th PH World Symposium who received medical therapy for PH and compared them with patients with idiopathic pulmonary arterial hypertension (IPAH) .” 21
- EXAMPLE 4. Exploratory research question (qualitative research)
- - Explores areas that have not been fully investigated (perspectives of families and children who receive care in clinic-based child obesity treatment) to have a deeper understanding of the research problem
- “Problem: Interventions for children with obesity lead to only modest improvements in BMI and long-term outcomes, and data are limited on the perspectives of families of children with obesity in clinic-based treatment. This scoping review seeks to answer the question: What is known about the perspectives of families and children who receive care in clinic-based child obesity treatment? This review aims to explore the scope of perspectives reported by families of children with obesity who have received individualized outpatient clinic-based obesity treatment.” 22
- EXAMPLE 5. Relationship research question (quantitative research)
- - Defines interactions between dependent variable (use of ankle strategies) and independent variable (changes in muscle tone)
- “Background: To maintain an upright standing posture against external disturbances, the human body mainly employs two types of postural control strategies: “ankle strategy” and “hip strategy.” While it has been reported that the magnitude of the disturbance alters the use of postural control strategies, it has not been elucidated how the level of muscle tone, one of the crucial parameters of bodily function, determines the use of each strategy. We have previously confirmed using forward dynamics simulations of human musculoskeletal models that an increased muscle tone promotes the use of ankle strategies. The objective of the present study was to experimentally evaluate a hypothesis: an increased muscle tone promotes the use of ankle strategies. Research question: Do changes in the muscle tone affect the use of ankle strategies ?” 23
EXAMPLES OF HYPOTHESES IN PUBLISHED ARTICLES
- EXAMPLE 1. Working hypothesis (quantitative research)
- - A hypothesis that is initially accepted for further research to produce a feasible theory
- “As fever may have benefit in shortening the duration of viral illness, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response when taken during the early stages of COVID-19 illness .” 24
- “In conclusion, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response . The difference in perceived safety of these agents in COVID-19 illness could be related to the more potent efficacy to reduce fever with ibuprofen compared to acetaminophen. Compelling data on the benefit of fever warrant further research and review to determine when to treat or withhold ibuprofen for early stage fever for COVID-19 and other related viral illnesses .” 24
- EXAMPLE 2. Exploratory hypothesis (qualitative research)
- - Explores particular areas deeper to clarify subjective experience and develop a formal hypothesis potentially testable in a future quantitative approach
- “We hypothesized that when thinking about a past experience of help-seeking, a self distancing prompt would cause increased help-seeking intentions and more favorable help-seeking outcome expectations .” 25
- “Conclusion
- Although a priori hypotheses were not supported, further research is warranted as results indicate the potential for using self-distancing approaches to increasing help-seeking among some people with depressive symptomatology.” 25
- EXAMPLE 3. Hypothesis-generating research to establish a framework for hypothesis testing (qualitative research)
- “We hypothesize that compassionate care is beneficial for patients (better outcomes), healthcare systems and payers (lower costs), and healthcare providers (lower burnout). ” 26
- Compassionomics is the branch of knowledge and scientific study of the effects of compassionate healthcare. Our main hypotheses are that compassionate healthcare is beneficial for (1) patients, by improving clinical outcomes, (2) healthcare systems and payers, by supporting financial sustainability, and (3) HCPs, by lowering burnout and promoting resilience and well-being. The purpose of this paper is to establish a scientific framework for testing the hypotheses above . If these hypotheses are confirmed through rigorous research, compassionomics will belong in the science of evidence-based medicine, with major implications for all healthcare domains.” 26
- EXAMPLE 4. Statistical hypothesis (quantitative research)
- - An assumption is made about the relationship among several population characteristics ( gender differences in sociodemographic and clinical characteristics of adults with ADHD ). Validity is tested by statistical experiment or analysis ( chi-square test, Students t-test, and logistic regression analysis)
- “Our research investigated gender differences in sociodemographic and clinical characteristics of adults with ADHD in a Japanese clinical sample. Due to unique Japanese cultural ideals and expectations of women's behavior that are in opposition to ADHD symptoms, we hypothesized that women with ADHD experience more difficulties and present more dysfunctions than men . We tested the following hypotheses: first, women with ADHD have more comorbidities than men with ADHD; second, women with ADHD experience more social hardships than men, such as having less full-time employment and being more likely to be divorced.” 27
- “Statistical Analysis
- ( text omitted ) Between-gender comparisons were made using the chi-squared test for categorical variables and Students t-test for continuous variables…( text omitted ). A logistic regression analysis was performed for employment status, marital status, and comorbidity to evaluate the independent effects of gender on these dependent variables.” 27
EXAMPLES OF HYPOTHESIS AS WRITTEN IN PUBLISHED ARTICLES IN RELATION TO OTHER PARTS
- EXAMPLE 1. Background, hypotheses, and aims are provided
- “Pregnant women need skilled care during pregnancy and childbirth, but that skilled care is often delayed in some countries …( text omitted ). The focused antenatal care (FANC) model of WHO recommends that nurses provide information or counseling to all pregnant women …( text omitted ). Job aids are visual support materials that provide the right kind of information using graphics and words in a simple and yet effective manner. When nurses are not highly trained or have many work details to attend to, these job aids can serve as a content reminder for the nurses and can be used for educating their patients (Jennings, Yebadokpo, Affo, & Agbogbe, 2010) ( text omitted ). Importantly, additional evidence is needed to confirm how job aids can further improve the quality of ANC counseling by health workers in maternal care …( text omitted )” 28
- “ This has led us to hypothesize that the quality of ANC counseling would be better if supported by job aids. Consequently, a better quality of ANC counseling is expected to produce higher levels of awareness concerning the danger signs of pregnancy and a more favorable impression of the caring behavior of nurses .” 28
- “This study aimed to examine the differences in the responses of pregnant women to a job aid-supported intervention during ANC visit in terms of 1) their understanding of the danger signs of pregnancy and 2) their impression of the caring behaviors of nurses to pregnant women in rural Tanzania.” 28
- EXAMPLE 2. Background, hypotheses, and aims are provided
- “We conducted a two-arm randomized controlled trial (RCT) to evaluate and compare changes in salivary cortisol and oxytocin levels of first-time pregnant women between experimental and control groups. The women in the experimental group touched and held an infant for 30 min (experimental intervention protocol), whereas those in the control group watched a DVD movie of an infant (control intervention protocol). The primary outcome was salivary cortisol level and the secondary outcome was salivary oxytocin level.” 29
- “ We hypothesize that at 30 min after touching and holding an infant, the salivary cortisol level will significantly decrease and the salivary oxytocin level will increase in the experimental group compared with the control group .” 29
- EXAMPLE 3. Background, aim, and hypothesis are provided
- “In countries where the maternal mortality ratio remains high, antenatal education to increase Birth Preparedness and Complication Readiness (BPCR) is considered one of the top priorities [1]. BPCR includes birth plans during the antenatal period, such as the birthplace, birth attendant, transportation, health facility for complications, expenses, and birth materials, as well as family coordination to achieve such birth plans. In Tanzania, although increasing, only about half of all pregnant women attend an antenatal clinic more than four times [4]. Moreover, the information provided during antenatal care (ANC) is insufficient. In the resource-poor settings, antenatal group education is a potential approach because of the limited time for individual counseling at antenatal clinics.” 30
- “This study aimed to evaluate an antenatal group education program among pregnant women and their families with respect to birth-preparedness and maternal and infant outcomes in rural villages of Tanzania.” 30
- “ The study hypothesis was if Tanzanian pregnant women and their families received a family-oriented antenatal group education, they would (1) have a higher level of BPCR, (2) attend antenatal clinic four or more times, (3) give birth in a health facility, (4) have less complications of women at birth, and (5) have less complications and deaths of infants than those who did not receive the education .” 30
Research questions and hypotheses are crucial components to any type of research, whether quantitative or qualitative. These questions should be developed at the very beginning of the study. Excellent research questions lead to superior hypotheses, which, like a compass, set the direction of research, and can often determine the successful conduct of the study. Many research studies have floundered because the development of research questions and subsequent hypotheses was not given the thought and meticulous attention needed. The development of research questions and hypotheses is an iterative process based on extensive knowledge of the literature and insightful grasp of the knowledge gap. Focused, concise, and specific research questions provide a strong foundation for constructing hypotheses which serve as formal predictions about the research outcomes. Research questions and hypotheses are crucial elements of research that should not be overlooked. They should be carefully thought of and constructed when planning research. This avoids unethical studies and poor outcomes by defining well-founded objectives that determine the design, course, and outcome of the study.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Conceptualization: Barroga E, Matanguihan GJ.
- Methodology: Barroga E, Matanguihan GJ.
- Writing - original draft: Barroga E, Matanguihan GJ.
- Writing - review & editing: Barroga E, Matanguihan GJ.
- Open access
- Published: 11 April 2024
METTL3 recruiting M2-type immunosuppressed macrophages by targeting m6A-SNAIL-CXCL2 axis to promote colorectal cancer pulmonary metastasis
- Peng Ouyang 1 na1 ,
- Kang Li 1 na1 ,
- Wei Xu 1 na1 ,
- Caiyun Chen 1 ,
- Yangdong Shi 1 ,
- Yao Tian 1 ,
- Jin Gong 1 &
- Zhen Bao 1
Journal of Experimental & Clinical Cancer Research volume 43 , Article number: 111 ( 2024 ) Cite this article
Metrics details
The regulatory role of N6-methyladenosine (m6A) modification in the onset and progression of cancer has garnered increasing attention in recent years. However, the specific role of m6A modification in pulmonary metastasis of colorectal cancer remains unclear.
This study identified differential m6A gene expression between primary colorectal cancer and its pulmonary metastases using transcriptome sequencing and immunohistochemistry. We investigated the biological function of METTL3 gene both in vitro and in vivo using assays such as CCK-8, colony formation, wound healing, EDU, transwell, and apoptosis, along with a BALB/c nude mouse model. The regulatory mechanisms of METTL3 in colorectal cancer pulmonary metastasis were studied using methods like methylated RNA immunoprecipitation quantitative reverse transcription PCR, RNA stability analysis, luciferase reporter gene assay, Enzyme-Linked Immunosorbent Assay, and quantitative reverse transcription PCR.
The study revealed high expression of METTL3 and YTHDF1 in the tumors of patients with pulmonary metastasis of colorectal cancer. METTL3 promotes epithelial-mesenchymal transition in colorectal cancer by m6A modification of SNAIL mRNA, where SNAIL enhances the secretion of CXCL2 through the NF-κB pathway. Additionally, colorectal cancer cells expressing METTL3 recruit M2-type macrophages by secreting CXCL2.
METTL3 facilitates pulmonary metastasis of colorectal cancer by targeting the m6A-Snail-CXCL2 axis to recruit M2-type immunosuppressive macrophages. This finding offers new research directions and potential therapeutic targets for colorectal cancer treatment.
In patients with colorectal cancer (CRC), cancer metastasis is the primary cause of cancer-related deaths, with the liver and lungs being the most common target organs for metastasis [ 1 , 2 ]. While the majority of research has traditionally focused on liver metastases, colorectal cancer pulmonary metastasis (CRPM) has received relatively less attention. This gap in research is particularly significant given that the lungs are the second most common site of metastasis for CRC. Epidemiological studies estimate that pulmonary metastases occur in approximately 10–18% of rectal cancer patients and 5–6% of colon cancer patients [ 3 ]. The mechanisms of CRPM are multifaceted, encompassing intracellular factors such as genetic and epigenetic abnormalities, tumor cell heterogeneity, and the process of epithelial-mesenchymal transition (EMT). Furthermore, the influence of the tumor microenvironment cannot be underestimated [ 4 ]. Given its significance in cancer progression and treatment, in-depth research on CRPM is imperative. This not only contributes to a better understanding of the metastatic mechanisms in CRC but is also crucial for the development of novel therapeutic strategies.
In the formation process of CRPM, the EMT plays a crucial role [ 3 ]. EMT is a critical mechanism in the process of tumor initiation and development, and its activation is typically regulated by transcription factors that induce EMT. These factors include Snail family transcriptional repressor 1 (SNAIL) protein, Zinc finger E-box-binding homeobox 1 (ZEB) protein, and Twist family bHLH transcription factor 1 (TWIST1) protein [ 5 , 6 , 7 , 8 ]. This activation process leads to a series of changes in cells, including the loss of cell apical-basal polarity, disruption of cell–cell junctions, degradation of the basement membrane, and remodeling of the extracellular matrix (ECM) [ 9 , 10 ]. These changes transform epithelial cells from their original cobblestone-like appearance into spindle-shaped mesenchymal cells [ 11 ]. At the molecular level, the characteristics of EMT include a decrease in epithelial markers such as E-cadherin and an increase in mesenchymal markers such as vimentin, N-cadherin, and fibronectin [ 12 ]. Clinically, these changes enhance the mobility and invasive capacity of tumor cells, thereby promoting the distant metastasis of colorectal cancer cells [ 13 ]. Therefore, in-depth research into the EMT process is crucial for understanding the progression mechanisms of colorectal cancer and developing effective personalized treatment strategies.
Epigenetic abnormalities play a crucial role in the occurrence of CRPM [ 3 ]. Indeed, N6-methyladenosine (m6A) modification is one of the most common forms of epigenetic modifications found in messenger RNA (mRNA) [ 14 , 15 ]. Recent research has indicated that m6A plays a crucial role in various aspects of mRNA, including splicing, nuclear export, translation, and stability. Its significance extends to the development of many human diseases, including cancer [ 16 , 17 ]. This modification is controlled by a group of specialized enzymes, including "writers" that add methyl groups and "erasers" that remove methyl groups [ 18 ]. In this context, the 'writers' complex comprises enzymes such as methyltransferase-like 3 (METTL3) and methyltransferase-like 14 (METTL14), which are responsible for transferring methyl groups onto RNA [ 19 , 20 , 21 , 22 ]. The demethylation of m6A is facilitated by enzymes such as obesity-related protein (FTO) and alkB homologue 5 (ALKBH5) [ 23 , 24 ]. These modifications are recognized and interpreted by a group of proteins known as 'readers,' which include YTH domain family proteins and insulin-like growth factor 2 mRNA-binding proteins (IGF2BP) [ 25 , 26 ]. These intricate interactions influence the behavior and function of RNA, thereby playing crucial roles in the development of CRPM.
During the development of tumors, m6A often exerts its influence on the expression of key genes associated with EMT, either directly or indirectly, leading to the promotion of tumor cell EMT and facilitating their progression and metastasis. [ 27 , 28 , 29 , 30 ]. The relationship between m6A and EMT in cancer cells has been extensively studied, but its role in CRPM remains unclear. In our study, we conducted transcriptome sequencing, quantitative PCR (qPCR), Western blotting (WB), and immunohistochemical (IHC) analysis on clinical specimens of colorectal primary tumors and their lung metastatic tumors. Additionally, we integrated data from The Cancer Genome Atlas (TCGA) database and observed an increased expression of m6A-related genes, such as METTL3 and YTHDF1. These observations prompted us to further explore the potential link between these changes and colorectal cancer lung metastasis. Through in vivo and in vitro experiments, we found that METTL3 could enhance the expression of SNAIL protein through m6A modification, thereby promoting EMT in tumor cells. Furthermore, we observed that tumor cells overexpressing SNAIL could promote the secretion of CXCL2 by activating the NF-κB pathway. Secreted CXCL2, upon binding to CXCR2 on the surface of M2-type macrophages, facilitated the infiltration of these immune cells into the tumor center. These findings provide a new perspective on understanding the molecular mechanisms underlying colorectal cancer lung metastasis and may have significant implications for the development of novel therapeutic strategies.
Materials and methods
Specimens, cell culture and treatment.
The transcriptome sequencing data for CRC in this study were sourced from The Cancer Genome Atlas (TCGA) data portal (accessible at https://portal.gdc.cancer.gov/ ). Chromatin immunoprecipitation (ChIP) sequencing data were obtained from the Gene Expression Omnibus (GEO) database (see https://www.ncbi.nlm.nih.gov/gds/ ). In situ carcinoma and lung metastatic carcinoma tissue specimens from colorectal cancer lung metastasis patients were provided by the First Affiliated Hospital of Jinan University. Collection of all specimens received approval from the ethics committee of the First Affiliated Hospital of Jinan University, and written informed consent was obtained from the patients before collection.
CRC cell lines used in this study, including RKO and SW480, as well as the human monocytic cell line THP-1, were all obtained from the American Type Culture Collection (ATCC, Manassas, USA) (details available at https://www.atcc.org/ ). THP-1 cells were treated with 100 ng/ml phorbol 12-myristate 13-acetate (PMA, Sigma, Darmstadt, Germany) for 48 h to induce their differentiation into mature macrophages. Subsequently, the cells were incubated for over 48 h under conditions containing 20 ng/ml interleukin-4 (IL-4, Sigma, Darmstadt, Germany) and 20 ng/ml interleukin-13 (IL-13, Sigma, Darmstadt, Germany) to promote their polarization towards the M2 phenotype. All cell lines were cultured following the guidelines recommended by ATCC.
Production of lentiviruses
The lentiviral transfection vectors used in this study were obtained from GenePharma (Shanghai, China). Experimental groups included sh-METTL3 (METTL3 knockdown group), sh-YTHDF1 (YTHDF1 knockdown group), sh-SNAIL (SNAIL knockdown group), and Ov-SNAIL (SNAIL overexpression group), along with their corresponding negative control group sh-NC. To establish stable colorectal cancer cell lines, cell selection was performed using 400 μg/ml of neomycin.
Wound-healing assays
In this experiment, cells were initially seeded in 6-well plates. When the cells reached approximately 80% confluence, sterile 200 μl pipette tips were gently used to create scratches in the cell monolayer. Subsequently, these treated cells were incubated for an additional 48 h in serum-free culture medium. The healing process of cell injuries was observed using an inverted microscope produced by Olympus Corporation, Japan. Finally, quantitative analysis of the wound area was performed using ImageJ software to assess cell migration and healing ability.
Transwell invasion assay
In our cell invasion experiments, we utilized Transwell chambers and Matrigel from Corning, USA. Initially, a layer of extracellular matrix gel was coated in the upper chamber of the Transwell, and medium containing 20% FBS was added to the lower chamber. Once the gel had completely solidified, we added 200 µL of medium containing 1 × 10^5 cells to the upper chamber. Subsequently, the cells were incubated at 37 °C with 5% CO2 for 48 h. After the incubation period, we fixed the cells in the upper chamber with 4% paraformaldehyde and then stained them with 1% crystal violet. Finally, we observed the cells that had invaded from the upper chamber to the lower chamber using an inverted microscope produced by Olympus Corporation, Japan, and conducted quantitative analysis using ImageJ software.
Cell counting kit-8 (CCK-8) and EDU assay
In the CCK-8 experiment, cells were evenly distributed in a 96-well plate and cultured for 1, 2, 3, 4, and 5 days. Subsequently, 10 µL of CCK-8 solution was added to each well. To assess cell viability, the optical density (OD450) of each well was measured using a microplate reader from Thermo Fisher, USA.
For the EDU experiment, cell suspensions were evenly distributed in a 96-well plate to achieve a cell count of 1 × 10^4 cells per well. The culture dishes were then incubated overnight in a CO2 incubator to allow the cells to adhere to the surface. After a 2-h incubation with 10 µM EDU (Beyotime, Shanghai, China), the culture medium was removed, and 1 mL of fixation solution (Beyotime, Shanghai, China) was added to each well. The fixation solution was left at room temperature for 15 min and then removed. The cells were subsequently washed three times with 1 mL of washing solution. After removing the washing solution, 1 mL of Triton X-100 (Beyotime, Shanghai, China) was added to each well and incubated at room temperature for 10–15 min. Next, the Click reaction solution (Beyotime, Shanghai, China) was added and incubated in the dark at room temperature for 30 min. Finally, Hoechst 33,342 (Beyotime, Shanghai, China) was used for nuclear staining. Cell counting and photography were performed using a fluorescence inverted microscope, and quantitative analysis was conducted using ImageJ software.
Clone formation assays
To collect cells during the logarithmic growth phase, a cell suspension was prepared using standard digestion and centrifugation methods. After cell counting, the cells were seeded into a 6-well plate at a concentration of 500 cells per well. Once the cells reached the 6th generation, culturing was stopped. The culture medium was discarded, and cells were washed twice with PBS solution. Subsequently, the cells were fixed in methanol for 15 min and stained with 1% crystal violet solution for 10 min. After capturing photographs with a camera, quantitative analysis was performed using ImageJ software.
Apoptosis assays
In the apoptosis experiment, the detection of cell apoptosis was performed using the FITC Annexin V Cell Apoptosis Detection Kit (provided by BD Biosciences). The experimental steps were as follows: After 48 h of shRNA viral infection, the cells were seeded into 6 cm culture dishes. Cells were then cultured in medium containing 1% fetal bovine serum for 5 days. Following this, cells were digested using trypsin and mixed with the culture supernatant. After digestion was completed, cells were centrifuged, and the cell pellet was washed with PBS buffer to remove trypsin. Subsequently, the cells were resuspended and subjected to Annexin V/PI double staining. Finally, flow cytometry analysis of the samples was performed using the BD LSRII flow cytometer (BD Biosciences). Throughout the entire experiment, precautions should be taken to avoid exposure to light, and strict adherence to laboratory safety regulations is essential.
M2-type macrophage migration assay
M2-type macrophage (1 × 10^5 cells per well) were plated in the upper compartment of a transwell with a pore size of 0.8 mm, in 100 mL of 1640 medium. The lower compartment was filled with 600 mL of conditioned medium collected from RKO or SW480 cells, excluding fetal bovine serum. Following a 4-h incubation period, the migrated cells in the lower chamber were quantified.
RNA stability
Add Act-D to the cell culture medium at a concentration of 5 µg/mL when the cells have reached a confluence of 70–80%. Collect cell samples at different time points after Act-D treatment. Use TRIzol reagent (Invitrogen) to extract total RNA from the collected samples. Quantify the RNA and assess its purity using a NanoDrop spectrophotometer. Convert the extracted total RNA into cDNA using a reverse transcription reagent kit (Vazyme, Nanjing, China) following the manufacturer's instructions. Perform quantitative reverse transcription-polymerase chain reaction (qRT-PCR) analysis to detect the mRNA levels of specific genes (please specify the genes of interest). Normalize the data using GAPDH as the reference gene. Calculate the relative expression levels using the 2^-ΔΔCT method. Create line graphs illustrating the change in RNA levels over time to reflect RNA stability. Ensure that you follow the manufacturer's protocols for reagent usage and experimental procedures.
Western blotting and immunohistochemistry
Cell and tissue samples were processed using RIPA buffer from Servicebio Technology, Wuhan, China. Protein extraction was carried out following the instructions provided in the radio-immunoprecipitation assay (RIPA) kit. Protein concentrations were quantified using the bicinchoninic acid (BCA) assay kit also provided by Servicebio Technology, Wuhan, China. The protein samples were subsequently separated by electrophoresis and transferred onto membranes. After washing the membranes three times with tris-buffered saline containing Tween (TBST), they were incubated with the primary antibody overnight at 4 °C. Following incubation, the membranes were washed again and incubated with the secondary antibody. Finally, protein bands were visualized using the enhanced chemiluminescence (ECL) assay kit provided by Servicebio Technology, Wuhan, China.
Immunohistochemistry and immunofluorescence as previously described [ 31 ]. In our study, immunohistochemistry was conducted using a range of primary antibodies with the following detailed information: 1. METTL3, Vimentin, E-Cadherin, YTHDF1, YTHDF2, SNAIL, and ARG1 antibodies were all obtained from Abcam (Cambridge, UK), each with the following product codes: METTL3 (ab195352), Vimentin (ab92547), E-Cadherin (ab40772), YTHDF1 (ab252346), SNAIL (ab180714), and CD163 (ab316218). 2. P65, Phospho-P65, GAPDH, and Tubulin antibodies were sourced from Proteintech Group (Chicago, USA) and were identified by the specific product codes: P65 (80,979–1-RR), Phospho-P65 (82,335–1-RR), GAPDH (10,494–1-AP), and Tubulin (11,224–1-AP). 3. Goat anti-rabbit IgG was purchased from Biosharp Life Sciences (Beijing, China) and had the product code BL052A. The quantification of all proteins and determination of average optical density were performed using Image J software.
Luciferase reporter assays
The dual-luciferase reporter gene assay was conducted using the Dual-Luciferase® Reporter Gene Assay System provided by Promega Corporation. To standardize transfection efficiency, a co-transfection approach with the pRL-TK reporter gene (also supplied by Promega) was employed. Relative luciferase activity was calculated based on the activity of Renilla luciferase.
mRNA-sequencing and methylated RNA immunoprecipitation quantitative reverse transcription polymerase chain reaction (MeRIP qRT-PCR)
Total RNA was extracted from colorectal cancer cell lines using the TRIzol reagent provided by Invitrogen Corporation (Carlsbad, CA, USA). Subsequently, mRNA sequencing and analysis were carried out by the HaploX Genomics Center in Shenzhen, China.
For RNA immunoprecipitation (MeRIP) analysis of m6A modification, we initially subjected the RNA to fragmentation using the riboMIP™ m6A Transcriptome Analysis Kit (Ribobio, Guangzhou, China) and then performed immunoprecipitation with m6A antibodies. The RNA isolated after immunoprecipitation was analyzed using qRT-PCR to investigate the m6A modification status of RNA.
RNA Extraction and quantitative reverse transcription polymerase chain reaction (qRT-PCR)
Total RNA was extracted using TRIzol (Invitrogen, Carlsbad, USA), while cytoplasmic and nuclear RNA were extracted using cytoplasmic & nuclear RNA purification (Amyjet Scientific, Wuhan, China). qRT-PCR was performed following the protocol (Vazyme, Nanjing, China).
The cell culture medium was transferred to a sterile centrifuge tube and centrifuged at 1000 × g for 10 min at 4 °C. Aliquots of the supernatant were then dispensed into EP tubes for further use. The CXCL2 protein was detected using the manufacturer's protocols for the CXCL2 ELISA kit (Solarbio, Beijing, China).
Animal studies
The experiments conducted in this study received ethical approval from the Ethics Committee of South China Agricultural University. Female nude mice aged 4 to 5 weeks were procured from the Animal Experiment Center of Southern Medical University for the experimental procedures. During the experimentation, a total of 10 nude mice were randomly divided into two groups, each consisting of 5 mice (n = 5). they were subcutaneous injected with 2 × 10^6 RKO/SW480 cells stably silencing METTL3 or control cells. Additionally, six nude mice were randomly assigned to two groups (n = 3), and they were intravenously injected with 2 × 10^6 RKO/SW480 cells stably silencing METTL3 or control cells. These nude mice were housed under standard laboratory conditions with access to ample food and water. Tumor size and volume were monitored weekly throughout the study. Before sample collection, humane euthanasia was administered to all mice using a 2% pentobarbital sodium solution at a dose of 150 mg/kg. After a 2-week interval, mice from the subcutaneous tumor group were euthanized due to tumor development. Similarly, mice from the intravenous tumor group were euthanized at the 4-week mark. The tumors were documented through photographic imaging and weighed. Subsequently, all collected tumor specimens were stored either in liquid nitrogen or fixed using a 4% formaldehyde solution for subsequent analysis.
Statistical analysis
In this study, all statistical analyses were performed using SPSS 19.0 software and R language (version 4.2.1). Graphs and data visualization were carried out using GraphPad Prism 9.5 software. We defined a p -value of less than 0.05 as indicating statistically significant differences.
METTL3 and YTHDF1 are highly expressed in CRPM
To assess the expression profiles of m6A WERs (writers, erasers, and readers) in colon adenocarcinoma (COAD), this study analyzed data from The Cancer Genome Atlas (TCGA) database. The analysis results revealed that several m6A WERs exhibited abnormal expression in CRC (Fig. 1 a). To further investigate the status of these differentially expressed genes in colorectal cancer in situ and lung metastatic cancer, we conducted sequencing on both types of cancer samples. The sequencing results indicated a significant increase in the expression of METTL3, wilms tumor 1 associated protein (WTAP), METTL14, and YTHDF1 in lung metastatic cancer. It's noteworthy that METTL14 did not show expression differences in the TCGA database (Fig. 1 b).

METTL3 and YTHDF1 are highly expressed in CRPM. a Expression profile of WERs in COAD based on TCGA database. b Volcano plot of differential gene sequencing WERs in colorectal cancer in situ and lung metastatic cancer. c qPCR Analysis of METTL3, WTAP, METTL14, and YTHDF1 Gene Expression in colorectal In Situ Carcinoma and Pulmonary Metastatic Carcinoma. d-e Western blotting analysis of METTL3 and YTHDF1 protein expression in colorectal in situ carcinoma and pulmonary metastatic carcinoma. T: colorectal In Situ Carcinoma. M: colorectal pulmonary metastatic carcinoma. f Immunohistochemical Analysis of METTL3 and YTHDF1 Protein Expression in colorectal In Situ Carcinoma and Pulmonary Metastatic Carcinoma. * P < 0.05, ** P < 0.01, *** P < 0.001, **** P < 0.0001
To further validate these findings, we conducted qPCR analysis on colorectal cancer in situ and lung metastatic cancer samples. The qPCR results demonstrated that the expression of METTL3 and YTHDF1 was significantly higher in colorectal cancer lung metastases compared to in situ cancer, while WTAP expression showed no significant difference (Fig. 1 c). Additionally, through WB and IHC experiments, we further confirmed the high expression of METTL3 and YTHDF1 in colorectal cancer lung metastases (Fig. 1 d-f).
Silencing the METTL3 gene inhibited the proliferation, invasion, and migration abilities of CRC cells while promoting apoptosis
In the initial stages of this study, we successfully silenced the METTL3 gene in RKO and SW480 cell lines using lentiviral infection technology. To assess the silencing effect, we performed Western blot analysis (Fig. 2 g). Subsequent cell proliferation experiments, including CCK-8, EDU staining, and plate colony assays, showed that after METTL3 knockdown, the OD450 values significantly decreased, the number of EDU-positive cells and cell colony formation were reduced (Fig. 2 c-e). These results indicate that downregulation of METTL3 weakened the proliferation ability of RKO and SW480 cells. We further investigated the impact of METTL3 on apoptosis in CRC cells. Through Annexin V-APC/PI staining experiments, we observed a significant increase in cell apoptosis rate after METTL3 inhibition (Fig. 2 f). Additionally, in vivo experiments using a nude mouse model showed that silencing METTL3 significantly reduced the size of subcutaneous tumors (Fig. 3 l). In wound healing and Transwell experiments, we found that METTL3 knockdown in CRC cell lines resulted in weakened migration and invasion abilities (Fig. 2 a-b). Another in vivo experiment also confirmed that inhibiting METTL3 significantly reduced the number of lung metastases in nude mice (Fig. 3 b). To assess whether cells underwent EMT, we conducted Western blot analysis, which revealed that after METTL3 knockdown, the expression of VIM and Snail proteins significantly decreased, while E-cadherin protein expression significantly increased (Fig. 2 g). Immunohistochemistry on tumor specimens from in vivo experiments also suggested that in the low-expression METTL3 group, both subcutaneous tumors and lung metastases showed significantly reduced expression of VIM and SNAIL proteins (Fig. 3 c-d).

Silencing the METTL3 gene inhibited the proliferation, invasion, and migration abilities of CRC cells while promoting apoptosis. a Representative images and quantitative analysis of CRC cell migration based on wound healing assay. b Decreased expression of METTL3 restrained CRC cell invasion ability based on transwell assay. c The colony formation ability of CRC cells silencing METTL3 or not was measured by colony formation assay. d EDU assay in CRC cells was performed the to measure the proliferation level. e CCK-8 assay was applied to measure the proliferation level of CRC cells after transfected with sh-METTL3 or not. f Flow cytometry analysis the proportion of apoptosis. g Western blotting analysis was applied to measure the protein expression level of E-cadherin, METTL3, SNAIL and Vimentin. GAPDH was used as a loading control. * P < 0.05, ** P < 0.01, *** P < 0.001, **** P < 0.0001

Decreased expression of METTL3 inhibits tumor growth in vivo. a Comparison of subcutaneous tumor size in nude mice after injecting RKO/SW480 CRC cells stably transfected with Sh-NC/Sh-METTL3. b The tail vein-lung metastasis model. Cells were injected into the tail vein to produce tumor cell lung metastasis. c-d IHC analysis of METTL3, SNAIL and Vimentin for tissues of subcutaneous tumor and lung metastasis tumor. * P < 0.05, ** P < 0.01, *** P < 0.001, **** P < 0.0001
METTL3 regulates tumor EMT process via m6A-Snail
According to previous studies, SNAIL plays a crucial role in the tumor microenvironment [ 31 ]. Furthermore, existing research suggests a mutual regulatory relationship between METTL3 and Snail in various types of cancer [ 28 ]. Based on this background, our study aimed to investigate whether METTL3 in colorectal cancer (CRC) exhibits a similar regulatory relationship with Snail. Our hypothesis is that METTL3 controls epithelial-mesenchymal transition (EMT) in tumors through the m6A-Snail pathway. To validate this hypothesis, we conducted Snail overexpression experiments (ov-Snail) in sh-NC (control group) and sh-METTL3 (METTL3 silenced group) cells. Western blot analysis showed that silencing METTL3 attenuated Snail expression, and the EMT process could be reversed, while overexpressing Snail could restore EMT (Fig. 4 a). This finding strongly supports the hypothesis that METTL3 regulates the EMT process through Snail. Additionally, we conducted SNAIL overexpression experiments in sh-METTL3 RKO and SW480 cell lines. The results showed that SNAIL overexpression reversed the inhibitory effect of silenced METTL3 on the proliferation, migration and invasion of CRC cells and its promotion of apoptosis (Fig. 4 b-g).

METTL3 regulates tumor process via Snail. a Western blotting analysis was applied to measure the protein expression level of E-cadherin, METTL3, SNAIL and Vimentin. GAPDH was used as a loading control. b Representative images and quantitative analysis of CRC cell migration based on wound healing assay. c Increased expression of SNAIL in sh-METTL3 CRC cell promoted CRC cell invasion ability based on transwell assay. d The colony formation ability of CRC cells overexpressing SNAIL or not was measured by colony formation assay in sh-METTL3 CRC cell. e EDU assay in CRC cells was performed the to measure the proliferation level. f CCK-8 assay was applied to measure the proliferation level of CRC cells after transfected with ov-SNAIL or not in sh-METTL3 CRC cell. g Flow cytometry analysis the proportion of apoptosis. * P < 0.05, ** P < 0.01, *** P < 0.001, **** P < 0.0001
To further explore how METTL3 regulates Snail, we first observed that silencing METTL3 led to a decrease in m6A modification levels on SNAIL mRNA using m6A qPCR technology (Fig. 5 a). Subsequently, to investigate the impact of m6A modification on SNAIL RNA, we detected the expression levels of SNAIL precursor mRNA (pre-mRNA) and mature mRNA in sh-METTL3-treated cells. The results showed that both pre-mRNA and mature mRNA levels of SNAI1 were significantly higher in the sh-METTL3 group than in the control group (Fig. 5 b). Furthermore, subcellular localization analysis of SNAI1 mRNA in sh-METTL3 and sh-NC cells revealed no significant differences between the two groups (Fig. 5 c).

METTL3 regulates tumor EMT process via m6A-Snail. a The MeRIP qRT-PCR analysis of SNAIL mRNA in sh-NC and sh-METTL3 CRC cells. b Precursor and mature mRNA of SNAI1 in sh-NC and sh-METTL3 CRC cells. c The relative levels of the nuclear versus cytoplasmic SNAI1 mRNA in sh-NC and sh-METTL3 CRC cells. d sh-NC and sh-METTL3 CRC cells were pretreated with Act-D for 90 min, then precursor (right) or mature (left) SNAIL mRNA were analyzed at indicated times. e sh-NC and sh-YTHDF2 CRC cells were pretreated with Act-D for 90 min, then mature SNAI1 mRNA were analyzed at indicated times. f Western blotting analysis was applied to measure the protein expression level of SNAIL and YTHDF1. GAPDH was used as a loading control. g GSEA analysis of SNAIL high-expression and low-expression groups utilizing TCGA COAD data. h Western blotting analysis was applied to measure the protein expression level of SNAIL, P65 and P-P65. Tubulin was used as a loading control. * P < 0.05, ** P < 0.01, *** P < 0.001, **** P < 0.0001
To assess the stability of SNAI1 pre-mRNA and mature mRNA, we used Act-D to inhibit new RNA transcription. The experimental results showed that the half-life of pre-mRNA and mature mRNA in the sh-METTL3 group was significantly longer than that in the control group (Fig. 5 d). Given that YTHDF2 is known to mediate the degradation of m6A-modified mRNA, we hypothesized that the observed phenomenon might be related to YTHDF2-mediated mRNA degradation. Therefore, we silenced YTHDF2 in colorectal cancer cell lines and observed an increase in the stability of SNAIL mRNA (Fig. 5 e).
However, we also found some contradictory phenomena. Despite the increased expression of SNAIL mRNA in the sh-METTL3 group, previous research indicated a decrease in SNAIL protein expression in this group. We speculated that this difference might be due to the influence of m6A on SNAIL mRNA translation efficiency. Therefore, we investigated YTHDF1, which serves as a "reader" of m6A and can recognize m6A-modified mRNA, enhancing its translation [ 32 ]. To further explore this mechanism, we conducted experiments with si-YTHDF1 in colorectal cancer cell lines. The results showed that knocking down YTHDF1 significantly reduced SNAIL protein expression (Fig. 5 f).
SNAIL induces CXCL2 expression via the NF-κΒ pathway
Our previous research has revealed a regulatory relationship between SNAIL and CXCL2, but the specific regulatory mechanism remains unclear. In previous sequencing analyses, we noticed significant changes in the NF-κB pathway in the context of lung metastasis cancer (CRPM) compared to colorectal cancer (CRC). Furthermore, through gene set enrichment analysis (GSEA) of CRC data from the TCGA database, we found that in samples with high SNAIL expression, the NF-κB pathway and chemokine signaling pathway were activated, accompanied by epithelial-mesenchymal transition (EMT) (Fig. 5 g). Based on these preliminary findings, we proposed a hypothesis: Snail may regulate the expression of CXCL2 through the NF-κB pathway. To validate this hypothesis, we conducted silencing experiments using sh-Snail in SW480 and RKO cell lines and observed a significant decrease in phosphorylated P65 (Phospho-P65) levels (Fig. 5 h). Additionally, we treated control group cells with the NF-κB inhibitor BAY11-7082 and found that CXCL2 expression also significantly decreased (Fig. 6 c). Furthermore, we analyzed CHIP-seq data (GSE61198) from the Gene Expression Omnibus (GEO) database and found that Snail could bind to the transcription start site (TSS) upstream of CXCL2 (Fig. 6 a). To further explore the direct regulatory relationship between SNAIL and CXCL2, we constructed luciferase reporter gene vectors for different lengths of the CXCL2 promoter (pGL-CXCL2-1606 bp, 942 bp, and 457 bp, respectively). The experimental results showed that silencing Snail significantly reduced the activity of the CXCL2-1606 bp promoter, while it had no significant effect on the activity of the CXCL2-942 bp and CXCL2-457 bp promoters (Fig. 6 b).

METTL3-expressing CRC Cells Recruits M2-type macrophage Via Secreting CXCL2. a Chromatin immunoprecipitation sequence data show that Snail might directly bind to Cxcl2 proximal promoters. b (Left) Schematic representation of CXCL2 promoter organization, and the luciferase reporter constructs pGL-CXCL2 (1606 bp: − 1606 to + 104 bp, 942 bp: − 942 to + 104 bp, 457 bp: − 457 to + 104 bp). TSS: transcriptional start site, E1: exon1, and Luc: luciferase. The green bars indicate E-boxes (CANNTG), which are the binding sites of Snail. (Right) Relative luciferase activities are shown. c ELISA to analyze the expression of CXCL2 in sh-NC/sh-SNAIL RKO cells (left), and the expression of CXCL2 in sh-NC/sh-SNAIL RKO cells (right), treated with or without BAY11-7082 (NF-κB inhibitor) at 10 μM for 24 h. d M2-type macrophage were seeded in the top chamber of the transwell containing 100 mL 1640 medium with or without CXCR2 inhibitor (SB265610, 10 mM). On the other hand, the bottom chamber contained 600 mL of CRC cell conditioned medium (no fetal bovine serum) with or without recombinant CXCL2 protein (1 ng/mL). After 4-h incubation, cells that have completely migrated to the bottom chamber were counted. e Immunofluorescence analysis of CD163 protein expression in colorectal in nude mice specimen. f Immunofluorescence analysis of CD163 protein expression in colorectal in situ carcinoma and pulmonary metastatic carcinoma. * P < 0.05, ** P < 0.01, *** P < 0.001, **** P < 0.0001
METTL3-expressing CRC cells recruits M2-type macrophage via secreting CXCL2
Immunohistochemical analysis of subcutaneous tumors and lung metastatic tumors in mice from the sh-METTL3 and sh-NC groups indicated that silencing METTL3 significantly reduced the expression of the M2 macrophage marker CD163 protein (Fig. 6 e). Similarly, in clinical samples, the protein expression of the M2 macrophage marker CD163 was significantly higher in lung metastatic tumors compared to primary tumors (Fig. 6 f). Next, we evaluated the role of the METTL3-CXCL2 axis in the chemotaxis of M2 macrophages in an in vitro M2 macrophage migration assay. METTL3 knockout significantly reduced the migration of M2 macrophages toward conditioned media derived from RKO and SW480 cells. The addition of recombinant CXCL2 protein rescued M2 macrophage migration in METTL3 knockout cells. On the other hand, blocking the CXCL2 receptor CXCR2 eliminated the difference in mediating M2 macrophage migration between the control and METTL3 knockout conditioned media (Fig. 6 d).
METTL3, as a core component of the multifaceted m6A methyltransferase complex (MTC), has been reported to play critical roles in various cancer types [ 33 , 34 , 35 , 36 , 37 , 38 ]. While alternative views have been proposed by other studies [ 39 , 40 , 41 , 42 , 43 ], our research findings reveal a significant oncogenic role for METTL3 in the process of tumorigenesis. Previous research has suggested that in certain cancers, METTL3 may function as a tumor suppressor gene. Given the controversies surrounding the roles of m6A modification and METTL3 in different cancer types, our study underscores the potential involvement of METTL3 in colorectal cancer. Our findings demonstrate that METTL3 promotes proliferation, invasion, migration, and inhibits apoptosis in colorectal cancer, highlighting its oncogenic potential. This further emphasizes the widespread impact of METTL3 and m6A methylation in cancer development and precision therapy.
In the field of oncology, epithelial-mesenchymal transition transcription factors (EMT-TFs) such as SNAIL play pivotal roles. SNAIL suppresses the expression of E-cadherin by binding to the e-boxes in the CDH1 promoter and recruiting the multisubunit repressor complex, a crucial process in tumor cells [ 44 , 45 ]. Aberrant Snail expression is closely associated with EMT, which, in turn, is linked to the invasion, migration, metastasis, settlement, and growth capabilities of tumors, ultimately promoting the formation of CRPM [ 46 ]. In the field of colorectal cancer research, prior investigations have already elucidated the regulatory relationship between METTL3 and SNAIL [ 47 ]. However, these studies were limited to in vitro research, leaving unanswered the question of whether METTL3 continues to exert a similar influence in the context of colorectal cancer lung metastasis. Consequently, our study is focused on elucidating the m6A modification of SNAIL mRNA by METTL3 and its subsequent ramifications in this specific context. We found that m6A modification enhances the degradation of SNAIL mRNA, which may be related to YTHDF2 specifically recognizing m6A-modified SNAIL mRNA and promoting its degradation [ 48 ]. However, this finding contradicts our experimental results, where m6A modification of SNAIL is associated with increased protein expression, raising our concern. Additionally, through sequencing and clinical sample testing, we observed elevated expression levels of METTL3 and YTHDF1 in samples of colorectal cancer lung metastasis. YTHDF1, another m6A "reader," has been found to recognize m6A-modified mRNA and enhance the translation of its targets [ 32 ]. To validate the role of YTHDF1, we silenced YTHDF1, and the results showed a significant reduction in SNAIL protein expression, suggesting that m6A methylation regulation of SNAIL is a dynamic process involving multiple factors that require further discussion. Furthermore, our research has also revealed the role of SNAIL in regulating the tumor microenvironment [ 31 ]. SNAIL not only recruits M2 macrophages to infiltrate the tumor center by promoting the secretion of CXCL2 but also indirectly regulates the expression of CXCL2 through the NF-κB pathway and directly modulates CXCL2 expression by binding to its promoter region. Moreover, colorectal cancer cells expressing METTL3 recruit M2 macrophages by secreting CXCL2, a finding confirmed through in vitro experiments and in vivo experiments with METTL3-silenced colorectal cancer cells. These findings provide a new perspective for clinical treatment, such as disrupting this malignant cycle using CXCR2 inhibitors.
In summary, our study aimed to elucidate the role and mechanism of RNA m6A methyltransferase METTL3 in CRPM. The results indicate that METTL3 plays a critical role in promoting the development of CRPM by targeting the m6A-Snail-CXCL2 axis, which is involved in recruiting M2 immunosuppressive macrophages. It is worth noting that we also observed a significant reduction in tumor migration upon inhibiting METTL3, suggesting that therapeutic strategies targeting METTL3 may be an effective approach for treating CRPM.
Availability of data and materials
The analyzed data sets generated during the present study are available from the corresponding author on reasonable request.
Abbreviations
AlkB homologue 5
American Type Culture Collection
Chromatin immunoprecipitation
Colon adenocarcinoma
Colorectal cancer
Colorectal cancer pulmonary metastasis
Extracellular matrix
Enzyme linked immunosorbent assay
Epithelial-mesenchymal transition
Fat mass and obesity-related protein
Gene Expression Omnibus
Heterogeneous nuclear ribonucleoprotein
Insulin-like growth factor 2 mRNA-binding proteins
Immunohistochemistry
Methyltransferase-like 3
Methylated RNA immunoprecipitation quantitative reverse transcription polymerase chain reaction
Messenger RNA
N6-methyladenosine
Phorbol 12-myristate 13-acetate
Quantitative reverse transcription PCR
Snail family transcriptional repressor 1
The Cancer Genome Atlas
Twist family bHLH transcription factor 1
Western blotting
Writers, erasers, and readers
Wilms tumor 1 associated protein
Zinc finger E-box-binding homeobox 1
Biller LH, Schrag D. Diagnosis and treatment of metastatic colorectal cancer: a review. JAMA-J AM MED ASSOC. 2021;325(7):669–85.
Article CAS Google Scholar
Zhou H, Liu Z, Wang Y, Wen X, Amador EH, Yuan L, Ran X, Xiong L, Ran Y, Chen W, et al. Colorectal liver metastasis: molecular mechanism and interventional therapy. Signal Transduct Tar. 2022;7(1):70.
Article Google Scholar
Chandra R, Karalis JD, Liu C, Murimwa GZ, Voth PJ, Heid CA, Reznik SI, Huang E, Minna JD, Brekken RA. The colorectal cancer tumor microenvironment and its impact on liver and lung metastasis. Cancers. 2021;13(24):6206.
Shin AE, Giancotti FG, Rustgi AK. Metastatic colorectal cancer: mechanisms and emerging therapeutics. Trends Pharmacol Sci. 2023;44(4):222–36.
Article CAS PubMed PubMed Central Google Scholar
Verstappe J, Berx G. A role for partial epithelial-to-mesenchymal transition in enabling stemness in homeostasis and cancer. Semin Cancer Biol. 2023;90:15–28.
Article CAS PubMed Google Scholar
Pastushenko I, Blanpain C. EMT Transition States during Tumor Progression and Metastasis. Trends Cell Biol. 2019;29(3):212–26.
Goossens S, Vandamme N, Van Vlierberghe P, Berx G. EMT transcription factors in cancer development re-evaluated: Beyond EMT and MET. BBA-REV Cancer. 2017;1868(2):584–91.
CAS Google Scholar
Wang Y, Shi J, Chai K, Ying X, Zhou BP. The role of snail in EMT and tumorigenesis. Curr Cancer Drug Tar. 2013;13(9):963–72.
Bakir B, Chiarella AM, Pitarresi JR, Rustgi AK. EMT, MET, plasticity, and tumor metastasis. Trends Cell Biol. 2020;30(10):764–76.
Article PubMed PubMed Central Google Scholar
Lu W, Kang Y. Epithelial-mesenchymal plasticity in cancer progression and metastasis. Dev Cell. 2019;49(3):361–74.
Huang Y, Hong W, Wei X. The molecular mechanisms and therapeutic strategies of EMT in tumor progression and metastasis. J Hematol Oncol. 2022;15(1):129.
Dongre A, Weinberg RA. New insights into the mechanisms of epithelial-mesenchymal transition and implications for cancer. Nat Rev Mol Cell Bio. 2019;20(2):69–84.
Vu T, Datta PK. Regulation of EMT in colorectal cancer: a culprit in metastasis. Cancers. 2017;9(12):171.
Wiener D, Schwartz S. The epitranscriptome beyond m(6)A. Nat Rev Genet. 2021;22(2):119–31.
He L, Li H, Wu A, Peng Y, Shu G, Yin G. Functions of N6-methyladenosine and its role in cancer. Mol Cancer. 2019;18(1):176.
He PC, He C. m(6) A RNA methylation: from mechanisms to therapeutic potential. EMBO J. 2021;40(3):e105977.
Wang T, Kong S, Tao M, Ju S. The potential role of RNA N6-methyladenosine in cancer progression. Mol Cancer. 2020;19(1):88.
Fang Z, Mei W, Qu C, Lu J, Shang L, Cao F, Li F. Role of m6A writers, erasers and readers in cancer. Exp Hematol Oncol. 2022;11(1):45.
Deng LJ, Deng WQ, Fan SR, Chen MF, Qi M, Lyu WY, Qi Q, Tiwari AK, Chen JX, Zhang DM, et al. m6A modification: recent advances, anticancer targeted drug discovery and beyond. Mol Cancer. 2022;21(1):52.
Jiang X, Liu B, Nie Z, Duan L, Xiong Q, Jin Z, Yang C, Chen Y. The role of m6A modification in the biological functions and diseases. Signal Transduct Tar. 2021;6(1):74.
Zhang Y, Chen W, Zheng X, Guo Y, Cao J, Zhang Y, Wen S, Gao W, Wu Y. Regulatory role and mechanism of m(6)A RNA modification in human metabolic diseases. Mol Ther-Oncolytics. 2021;22:52–63.
Oerum S, Meynier V, Catala M, Tisné C. A comprehensive review of m6A/m6Am RNA methyltransferase structures. Nucleic Acids Res. 2021;49(13):7239–55.
Zhao Y, Shi Y, Shen H, Xie W. m(6)A-binding proteins: the emerging crucial performers in epigenetics. J Hematol Oncol. 2020;13(1):35.
Azzam SK, Alsafar H, Sajini AA. FTO m6A demethylase in obesity and cancer: implications and underlying molecular mechanisms. Int J Mol Sci. 2022;23(7):3800.
An Y, Duan H. The role of m6A RNA methylation in cancer metabolism. Mol Cancer. 2022;21(1):14.
Sun T, Wu R, Ming L. The role of m6A RNA methylation in cancer. Biomed Pharmacother. 2019;112:108613.
Yue B, Song C, Yang L, Cui R, Cheng X, Zhang Z, Zhao G. METTL3-mediated N6-methyladenosine modification is critical for epithelial-mesenchymal transition and metastasis of gastric cancer. Mol Cancer. 2019;18(1):142.
Lin X, Chai G, Wu Y, Li J, Chen F, Liu J, Luo G, Tauler J, Du J, Lin S, et al. RNA m(6)A methylation regulates the epithelial mesenchymal transition of cancer cells and translation of Snail. Nat Commun. 2019;10(1):2065.
Chen H, Pan Y, Zhou Q, Liang C, Wong CC, Zhou Y, Huang D, Liu W, Zhai J, Gou H, et al. METTL3 inhibits antitumor immunity by targeting m(6)A-BHLHE41-CXCL1/CXCR2 axis to promote colorectal cancer. Gastroenterology. 2022;163(4):891–907.
Li T, Hu PS, Zuo Z, Lin JF, Li X, Wu QN, Chen ZH, Zeng ZL, Wang F, Zheng J, et al. METTL3 facilitates tumor progression via an m(6)A-IGF2BP2-dependent mechanism in colorectal carcinoma. Mol Cancer. 2019;18(1):112.
Bao Z, Zeng W, Zhang D, Wang L, Deng X, Lai J, Li J, Gong J, Xiang G. SNAIL induces EMT and lung metastasis of tumours secreting CXCL2 to promote the invasion of M2-type immunosuppressed macrophages in colorectal cancer. Int J Biol Sci. 2022;18(7):2867–81.
Wang X, Zhao BS, Roundtree IA, Lu Z, Han D, Ma H, Weng X, Chen K, Shi H, He C. N(6)-methyladenosine modulates messenger RNA translation efficiency. Cell. 2015;161(6):1388–99.
Vu LP, Pickering BF, Cheng Y, Zaccara S, Nguyen D, Minuesa G, Chou T, Chow A, Saletore Y, MacKay M, et al. The N(6)-methyladenosine (m(6)A)-forming enzyme METTL3 controls myeloid differentiation of normal hematopoietic and leukemia cells. Nat Med. 2017;23(11):1369–76.
Barbieri I, Tzelepis K, Pandolfini L, Shi J, Millán-Zambrano G, Robson SC, Aspris D, Migliori V, Bannister AJ, Han N, et al. Promoter-bound METTL3 maintains myeloid leukaemia by m(6)A-dependent translation control. Nature. 2017;552(7683):126–31.
Wang H, Xu B, Shi J. N6-methyladenosine METTL3 promotes the breast cancer progression via targeting Bcl-2. Gene. 2020;722:144076.
Chen M, Wei L, Law CT, Tsang FH, Shen J, Cheng CL, Tsang LH, Ho DW, Chiu DK, Lee JM, et al. RNA N6-methyladenosine methyltransferase-like 3 promotes liver cancer progression through YTHDF2-dependent posttranscriptional silencing of SOCS2. Hepatology. 2018;67(6):2254–70.
Zuo X, Chen Z, Gao W, Zhang Y, Wang J, Wang J, Cao M, Cai J, Wu J, Wang X. M6A-mediated upregulation of LINC00958 increases lipogenesis and acts as a nanotherapeutic target in hepatocellular carcinoma. J Hematol Oncol. 2020;13(1):5.
Xu H, Wang H, Zhao W, Fu S, Li Y, Ni W, Xin Y, Li W, Yang C, Bai Y, et al. SUMO1 modification of methyltransferase-like 3 promotes tumor progression via regulating Snail mRNA homeostasis in hepatocellular carcinoma. Theranostics. 2020;10(13):5671–86.
Cui Q, Shi H, Ye P, Li L, Qu Q, Sun G, Sun G, Lu Z, Huang Y, Yang CG, et al. m(6)A RNA methylation regulates the self-renewal and tumorigenesis of glioblastoma stem cells. Cell Rep. 2017;18(11):2622–34.
Liu J, Eckert MA, Harada BT, Liu SM, Lu Z, Yu K, Tienda SM, Chryplewicz A, Zhu AC, Yang Y, et al. m(6)A mRNA methylation regulates AKT activity to promote the proliferation and tumorigenicity of endometrial cancer. Nat Cell Biol. 2018;20(9):1074–83.
Jia R, Chai P, Wang S, Sun B, Xu Y, Yang Y, Ge S, Jia R, Yang YG, Fan X. m(6)A modification suppresses ocular melanoma through modulating HINT2 mRNA translation. Mol Cancer. 2019;18(1):161.
Deng R, Cheng Y, Ye S, Zhang J, Huang R, Li P, Liu H, Deng Q, Wu X, Lan P, et al. m(6)A methyltransferase METTL3 suppresses colorectal cancer proliferation and migration through p38/ERK pathways. Oncotargets Ther. 2019;12:4391–402.
Zhao S, Liu J, Nanga P, Liu Y, Cicek AE, Knoblauch N, He C, Stephens M, He X. Detailed modeling of positive selection improves detection of cancer driver genes. Nat Commun. 2019;10(1):3399.
Batlle E, Sancho E, Francí C, Domínguez D, Monfar M, Baulida J, García DHA. The transcription factor snail is a repressor of E-cadherin gene expression in epithelial tumour cells. Nat Cell Biol. 2000;2(2):84–9.
Cano A, Pérez-Moreno MA, Rodrigo I, Locascio A, Blanco MJ, Del BM, Portillo F, Nieto MA. The transcription factor snail controls epithelial-mesenchymal transitions by repressing E-cadherin expression. Nat Cell Biol. 2000;2(2):76–83.
Brabletz S, Schuhwerk H, Brabletz T, Stemmler MP. Dynamic EMT: a multi-tool for tumor progression. Embo J. 2021;40(18):e108647.
Wen J, Zhang G, Meng Y, Zhang L, Jiang M, Yu Z. RNA m(6)A methyltransferase METTL3 promotes colorectal cancer cell proliferation and invasion by regulating snail expression. Oncol Lett. 2021;22(4):711.
Wang X, Lu Z, Gomez A, Hon GC, Yue Y, Han D, Fu Y, Parisien M, Dai Q, Jia G, et al. N6-methyladenosine-dependent regulation of messenger RNA stability. Nature. 2014;505(7481):117–20.
Article PubMed Google Scholar
Download references
This study was supported by the Fundamental Research Funds for the Central Universities (21623305,21623409), Guangdong Medical Science and Technology Research Fund Project(A2023398), Guangzhou Science and Technology Plan Basic and Applied Basic Research Funding Project(2024A04J3707) and Guangzhou Science and Technology Plan City-School Joint Funding Project (202201020304).
Author information
Peng Ouyang, Kang Li and Wei Xu contributed equally to this work.
Authors and Affiliations
Department of General Surgery, The First Affiliated Hospital of Jinan University, Guangzhou, 510632, Guangdong, China
Peng Ouyang, Kang Li, Wei Xu, Caiyun Chen, Yangdong Shi, Yao Tian, Jin Gong & Zhen Bao
You can also search for this author in PubMed Google Scholar
Contributions
POY: As the first author, POY was responsible for the primary study design, experimental procedures, data collection and analysis, as well as the writing and revision of the manuscript. KL (co-first author): KL collaborated with the first author in study design, experimental procedures, participated in data analysis, and contributed to the writing of the manuscript. WX (co-first author): WX worked in collaboration with the first author on experimental design and data analysis, making significant contributions to the writing of the manuscript. CYC, YDS, YT: These three authors were involved in some experimental procedures, contributed to the collection and preliminary analysis of experimental data. JG (co-corresponding author): Jin Gong, as a co-corresponding author, participated in guiding the research, contributed to the writing, and provided final review to ensure the quality and accuracy of the study. ZB (corresponding author): As the corresponding author, Zhen Bao was responsible for overseeing the entire research project, obtaining funding, and overseeing the final review and submission of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Correspondence to Jin Gong or Zhen Bao .
Ethics declarations
Ethics approval and consent to participate.
All experiments were performed in compliance with the relevant regulations, and all patients provided written informed consent. Besides, the animal studies were approved by the Animal Ethics Committee of South China Agricultural University (2023d045). The experiments followed the Guidelines for the Care and Use of Laboratory Animals issued by the Chinese Council on Animal Research.
Consent for publication
All the authors agree to the content of the paper.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Ouyang, P., Li, K., Xu, W. et al. METTL3 recruiting M2-type immunosuppressed macrophages by targeting m6A-SNAIL-CXCL2 axis to promote colorectal cancer pulmonary metastasis. J Exp Clin Cancer Res 43 , 111 (2024). https://doi.org/10.1186/s13046-024-03035-6
Download citation
Received : 20 December 2023
Accepted : 29 March 2024
Published : 11 April 2024
DOI : https://doi.org/10.1186/s13046-024-03035-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- N6-Methyladenosine
- Epithelial–mesenchymal transition
- Colorectal cancer pulmonary metastases
- M2-type macrophages
Journal of Experimental & Clinical Cancer Research
ISSN: 1756-9966
- Submission enquiries: Access here and click Contact Us
- General enquiries: [email protected]
IMAGES
VIDEO
COMMENTS
Quantitative data has to be gathered and cleaned before proceeding to the stage of analyzing it. Below are the steps to prepare a data before quantitative research analysis: Step 1: Data Collection. Before beginning the analysis process, you need data. Data can be collected through rigorous quantitative research, which includes methods such as ...
The type of quantitative data you have (specifically, level of measurement and the shape of the data). And, Your research questions and hypotheses; Let's take a closer look at each of these. Factor 1 - Data type. The first thing you need to consider is the type of data you've collected (or the type of data you will collect).
Revised on June 22, 2023. Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and analyzing ...
Quantitative Research. Quantitative research is a type of research that collects and analyzes numerical data to test hypotheses and answer research questions.This research typically involves a large sample size and uses statistical analysis to make inferences about a population based on the data collected.
Quantitative data analysis serves as part of an essential process of evidence-making in health and social sciences. It is adopted for any types of research question and design whether it is descriptive, explanatory, or causal. However, compared with qualitative counterpart, quantitative data analysis has less flexibility.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
Statistical analysis techniques for quantitative studies can describe data, generate hypotheses, or test hypotheses. Figure 16.3 shows the schematic representation of the data analysis process for quantitative study design. Descriptive statistics summarize and describe a group's characteristics or compare groups and are described in the next ...
A tutorial on the different types of data analysis. | Video: Shiram Vasudevan When to Use the Different Types of Data Analysis Descriptive analysis summarizes the data at hand and presents your data in a comprehensible way.; Diagnostic analysis takes a more detailed look at data to reveal why certain patterns occur, making it a good method for explaining anomalies.
8. Weight customer feedback. So far, the quantitative data analysis methods on this list have leveraged numeric data only. However, there are ways to turn qualitative data into quantifiable feedback and to mix and match data sources. For example, you might need to analyze user feedback from multiple surveys.
Quantitative data refers to numerical data that can be measured or counted. This type of data is often used in scientific research and is typically collected through methods such as surveys, experiments, and statistical analysis. Quantitative Data Types. There are two main types of quantitative data: discrete and continuous.
Data Analysis Methods in Quantitative Research We started this module with levels of measurement as a way to categorize our data. Data analysis is directed toward answering the original research question and achieving the study purpose (or aim).
When conducting data analysis, it is important to choose appropriate techniques based on the research objectives, type of data, and research questions. It is also crucial to consider the assumptions and limitations associated with each technique to ensure accurate and meaningful interpretation of the results. a.
nominal. It is important to know w hat kind of data you are planning to collect or analyse as this w ill. affect your analysis method. A 12 step approach to quantitative data analysis. Step 1 ...
Quantitative data analysis differs from qualitative analysis primarily in its focus on numerical data and statistical methods to answer questions of "how many" and "how much". It seeks to quantify variables and generalize results from a sample to a population. In contrast, qualitative analysis focuses on non-numerical data, aiming to understand ...
Cross-tabulation: Cross-tabulation is the most widely used quantitative data analysis methods. It is a preferred method since it uses a basic tabular form to draw inferences between different data-sets in the research study. It contains data that is mutually exclusive or have some connection with each other.
Abstract. This chapter describes the types of data analysis techniques in quantitative research and sampling strategies suitable for quantitative studies, particularly probability sampling, to produce credible and trustworthy explanations of a phenomenon. Initially, it briefly describes the measurement levels of variables.
Quantitative research is the process of collecting and analyzing numerical data to describe, predict, or control variables of interest. This type of research helps in testing the causal relationships between variables, making predictions, and generalizing results to wider populations. The purpose of quantitative research is to test a predefined ...
Quantitative Analysis. Description: Quantitative data analysis is a high-level branch of data analysis that designates methods and techniques concerned with numbers instead of words. It accounts for more than 50% of all data analysis and is by far the most widespread and well-known type of data analysis.
Analysis of Quantitative data enables you to transform raw data points, typically organised in spreadsheets, into actionable insights. Refer to the article to know more! Analysis of Quantitative Data: Data, data everywhere — it's impossible to escape it in today's digitally connected world.With business and personal activities leaving digital footprints, vast amounts of quantitative data ...
To analyze data collected in a statistically valid manner (e.g. from experiments, surveys, and observations). Meta-analysis. Quantitative. To statistically analyze the results of a large collection of studies. Can only be applied to studies that collected data in a statistically valid manner.
How to analyze qualitative and quantitative data. Qualitative or quantitative data by itself can't prove or demonstrate anything, but has to be analyzed to show its meaning in relation to the research questions. The method of analysis differs for each type of data. Analyzing quantitative data. Quantitative data is based on numbers.
The main difference between quantitative and qualitative research is the type of data they collect and analyze. ... Large sample sizes are needed for more accurate analysis. Small-scale quantitative studies may be less reliable because of the low quantity of data (Denscombe, 2010). This also affects the ability to generalize study findings to ...
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. ... Research questions and hypotheses are crucial components to any type of research, whether quantitative or qualitative. These questions should be developed at the very beginning of ...
This finding offers new research directions and potential therapeutic targets for colorectal cancer treatment. ... Japan. Finally, quantitative analysis of the wound area was performed using ImageJ software to assess cell migration and healing ability. ... WX worked in collaboration with the first author on experimental design and data analysis ...