
Contribute to the Windows forum! Click here to learn more 💡
April 9, 2024

Contribute to the Windows forum!
Click here to learn more 💡
- Search the community and support articles
- Search Community member
Ask a new question
Russian speech recognition
Could you please tell me where can I download Russian speech recognition pack?
Report abuse
Replies (3) .
- Independent Advisor
4 people found this reply helpful
Was this reply helpful? Yes No
Sorry this didn't help.
Great! Thanks for your feedback.
How satisfied are you with this reply?
Thanks for your feedback, it helps us improve the site.
Thanks for your feedback.
thank you for the answer, do you know if it will be available sometime?
2 people found this reply helpful
Question Info
- Norsk Bokmål
- Ελληνικά
- Русский
- עברית
- العربية
- ไทย
- 한국어
- 中文(简体)
- 中文(繁體)
- 日本語
Russian Speech to Text in Murf
While Murf doesn’t support a standalone Russian speech to text feature, using Murf voice changer, you can convert your voiceover into text in Russian. Upload, confirm, and transcribe.

Accurate Transcription in Russian

Download your Script in Multiple Formats

Beyond Russian Speech to Text

How to Convert Russian Speech to Text in Murf ?
Open Murf Studio. Click on ‘Voice Changer’ to upload your existing audio or video file to Murf.
You’ll see a pop up asking you to choose the language used in the audio to start transcription. Choose the target language from the drop down.
The voiceover is automatically and accurately transcribed into text in the source language.
You can download the transcription as a single file or split it into manageable blocks in the format of your choice by simply clicking on ‘Export.’
Russian Speech to Text Conversion for Effortless Communication
How russian voice to text works, advantages of russian speech to text conversion, use cases of speech recognition, bottom line, frequently asked questions, murf supports text to speech in.

Important Links
How to create.

Mobile Navigation
Introducing whisper.

Illustration: Ruby Chen
We’ve trained and are open-sourcing a neural net called Whisper that approaches human level robustness and accuracy on English speech recognition.
More resources
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. We show that the use of such a large and diverse dataset leads to improved robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages, as well as translation from those languages into English. We are open-sourcing models and inference code to serve as a foundation for building useful applications and for further research on robust speech processing.
The Whisper architecture is a simple end-to-end approach, implemented as an encoder-decoder Transformer. Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and then passed into an encoder. A decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
Other existing approaches frequently use smaller, more closely paired audio-text training datasets, [^reference-1] [^reference-2] [^reference-3] or use broad but unsupervised audio pretraining. [^reference-4] [^reference-5] [^reference-6] Because Whisper was trained on a large and diverse dataset and was not fine-tuned to any specific one, it does not beat models that specialize in LibriSpeech performance, a famously competitive benchmark in speech recognition. However, when we measure Whisper’s zero-shot performance across many diverse datasets we find it is much more robust and makes 50% fewer errors than those models.
About a third of Whisper’s audio dataset is non-English, and it is alternately given the task of transcribing in the original language or translating to English. We find this approach is particularly effective at learning speech to text translation and outperforms the supervised SOTA on CoVoST2 to English translation zero-shot.
We hope Whisper’s high accuracy and ease of use will allow developers to add voice interfaces to a much wider set of applications. Check out the paper , model card , and code to learn more details and to try out Whisper.
Discover the 10 Best Speech to Text Apps in 2023
How speech to text from audio file changes business and everyday life
Russian speech recognition
Leveraging sophisticated algorithms, SpeechFlow provides a rapid and precise Russian speech recognition solution, revolutionizing the approach to managing voice data.
How to transcribe Russian speech recognition

Upload Media Files
To utilize SpeechFlow for transcribe Russian speech recognition, either choose the local audio file you wish to transcribe or input the YouTube link you intend to transcribe.

Select Language
SpeechFlow provides transcription support for 14 languages, transcribing Russian speech recognition; just select the language corresponding to your audio file.

Submit Transcription
Click the "Transcribe" button, and within moments, you'll see both the audio and transcription results displayed.
Why Select SpeechFlow for transcribing Russian speech recognition
The unparalleled advantages of SpeechFlow
SpeechFlow showcases six essential advantages for optimizing transcription efficiency
With unrivaled precision
Multilingual
Support multilingual transcription
Multiple formats supported
Fast processing of audio/video
Affordable and flexible pricing
Online and API transcription mode
We have full confidence in SpeechFlow's unmatched precision, and the outcomes speak for themselves.
SpeechFlow facilitates speech recognition in 14 languages, with additional languages currently in development.
SpeechFlow is compatible with audio and video files in nearly all formats for speech recognition.
SpeechFlow efficiently transcribes a 1-hour audio file in less than 3 minutes, providing both businesses and individuals with accurate and swift transcription.
Get started with up to 5 free hours per month,no credit card require.
- 30 mins online transcription per month
- 5 hours API transcription per month
- All 14 languages available
- Time aligned transcription
- 1 audio file concurrency limit
No credit card required to sign up
For professional users with growing volumes
- Everything included in Free Tier
- 10 audio file concurrency limit
- Pay-as-you-go by seconds
For businesses with custom integrations or large volumes
- Volume transcription pricing
- Higher concurrency limit
- VPC deployments
- On-prem deployments
- Dedicated support
Introduced API-based services and online file speech recognition solutions for both businesses and individuals.
Effortlessly accomplish speech recognition in Russian
This advanced speech recognition tool can accurately and swiftly assist you in converting your Russian audio and video files into text
Offers multilanguage support in a unified platform
At SpeechFlow, we pride ourselves on our capability to provide transcriptions in 14 distinct languages, ensuring that we cater to a diverse spectrum of linguistic needs crucial for global communication. Recognizing the varied requirements of our audience, we have crafted an all-encompassing solution that is apt for both large-scale enterprises and individual users. Our esteemed clients have the flexibility to seamlessly integrate with our state-of-the-art speech recognition API. Alternatively, for those seeking a more straightforward approach, our intuitive online platform has been designed to simplify the transcription process, ensuring a hassle-free experience for every user. Join us in revolutionizing global communication.

Ensures precise transcriptions tailored to diverse sectors
SpeechFlow stands at the forefront of transcription technology, distinguished by its unparalleled accuracy derived from state-of-the-art AI capabilities. This advanced AI not only grasps general lingual nuances but also dives deep into the intricacies of industry-specific terminology and contextual meanings. Recognizing the diverse needs of various sectors, SpeechFlow has meticulously crafted its speech recognition models. Whether it's the intricate jargon of healthcare, the specific terminologies of finance, the detailed lexicon of the legal world, the dynamic language of customer service, or the specialized vocabulary of education, SpeechFlow's models are attuned to deliver. By doing so, they not only ensure precise transcriptions but also empower professionals to enhance their documentation processes, making them more efficient and contextually relevant.
Delivers fast transcriptions, affordable rates, and flexible setup options
SpeechFlow stands out with its unparalleled transcription speed, processing up to an hour of content in under three minutes. Beyond its rapid capabilities, SpeechFlow offers a competitive pay-as-you-go pricing structure, starting at just $0.0002 per second. Catering to the diverse and evolving needs of businesses, clients can choose between cloud-based and on-premises deployment options. This flexibility ensures optimal data protection and seamless integration into varied workflows. With SpeechFlow, experience transcription efficiency like never before.
Enhances content reach while constantly innovating
SpeechFlow is more than just transcription; it's a transformative approach to communication. Enhance accessibility by connecting with broader audiences through meticulous video transcriptions. Uphold accessibility standards, championing both inclusivity and effectiveness. In the landscape of speech-to-text solutions, SpeechFlow is the pinnacle of accuracy, innovation, and accessibility. Partner with us to elevate the conversion of spoken content into text, boosting efficiency and bridging communication gaps across various industries and languages.
Sign up for free trial
Accurate speech-to-text API for Russian. Join SpeechFlow community and access more features!
Require clarification? Explore our frequently asked questions.
How to transcribe Russian speech using online speech recognition?
Executing online speech recognition has been simplified with SpeechFlow.io. Here's a comprehensive step-by-step guide to performing speech recognition online:
1. Upload your audio/video file or paste the youtube URL to SpeechFlow's workspace. Supported audio format: aac, amr, ape, flac, m4a, mp3, ogg, opus, wav, wma; video format: 3gp, asf, avi, flv, mkv, mov, mp4, mpeg, mpg, webm, wmv, rm, rmvb;
2. Choose the Russian as your original file. Right now SpeechFlow supports various languages: English, Mandarin, Spanish, Portuguese, French, German, Italian, Russian, Turkish, Japanese, Korean, Vietnamese, Indonesian, and more;
3. Click "Transcribe" to start analyzing the audio and convert it into written text.SpeechFlow can process up to 1 hour of audio files in less than 3 minutes;
4. Review and download the transcription.
How to Use Speechflow API for Russian speech recognition?
By following these three simple steps, you can effortlessly and precisely transcribe your media files into text.
1. Create API Key
After completing registration, please login to your account and generate your API Key at Dashboard-API. At 'Quick Test' of Dashboard-API, we offer a variety of programming languages (C#, Go, Java, Node.js, Php, Python, Ruby, Rust, TypeScript) to help you easily and quickly transcribe media files.
Note: for the security of your API Key Secret, the API Key Secret can only be seen once, so please be sure to save your API Key somewhere else.
2. Create Transcription Task
SpeechFlow can transcribe local files and remote files, both of which use the same Rest API.
3. Query Transcription Result
The 'query transcription result' Rest API can be polled until the transcription result is obtained.
More details on using the API can be found at Docs > Transcription API.
What input and export file formats does SpeechFlow support?
SpeechFlow supports the import and export of nearly all audio and video files; simply convert your audio and video files to text using the SpeechFlow API or online speech recognition.
Audio format:
aac, amr, ape, flac, m4a, mp3, ogg, opus, wav, wma;
Video Format:
3gp, asf, avi, flv, mkv, mov, mp4, mpeg, mpg, webm, wmv, rm, rmvb;
Who can benefit from speech recognition of the SpeechFlow ?
SpeechFlow has emerged as an indispensable tool for an extensive spectrum of users. This includes not just businesses but also individual content creators, dedicated educators, diligent journalists, and meticulous researchers. Each of these diverse user groups finds immense value in what SpeechFlow offers. At the core of its appeal is the platform's commitment to delivering accurate and efficient transcription services for both audio and video content. Whether it's a business aiming to document meetings, a content creator desiring to make their content more accessible, an educator enhancing their teaching materials, a journalist ensuring precise reporting, or a researcher meticulously documenting their findings, SpeechFlow stands as the go-to solution for all their transcription needs.
- Speech-to-Text
- Speech recognition
- Transcribe audio to text
- Transcribe video to text
- English speech recognition
- French speech recognition
- German speech recognition
- Indonesian speech recognition
- Italian speech recognition
- Japanese speech recognition
- Korean speech recognition
- Mandarin speech recognition
- Portuguese speech recognition
- Spanish speech recognition
- Traditional Chinese speech recognition
- Turkish speech recognition
- Vietnamese speech recognition
Transcribe the world with precision
Some Approaches for Russian Speech Recognition
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Speech to Text Russian
Get accurate conversions from speech to text in Russian online with VEED’s audio-to-text tool

Transcribe speech to text in Russian accurately
Instantly transcribe Russian and 100 languages audio and video files to text straight from your browser. Transcribe spoken words in Russian accurately in one click. Transform your voice recordings into editable text, streamlining communication and saving you valuable time. You can also auto-generate subtitles !
How to convert speech to text in Russian with AI:
1 upload or record.
Upload your audio or video to VEED or record one using our online audio recorder .
2 Auto-transcribe and translate
Auto-transcribe your video from the Subtitles menu. You can also translate your transcript to over 120 languages. Select a language and translate the transcript instantly.
3 Review and export
Review and edit the transcription if necessary. Just click on a line of text and start typing. Download your transcript in VTT, SRT, or TXT format.
Learn more about our Russian speech-to-text tool:

Accurate AI voice-to-text transcriptions in Russian
No more manually transcribing Russian audio to text. Embrace the ease of effortless speech-to-text conversion. Our cutting-edge speech recognition lets you record and watch your words magically transform into text in real-time. Our premium subscribers get unlimited transcription downloads. Check our pricing page for more info.
Automatic transcription tools and AI-powered translations
Let VEED convert your audio, video, or any spoken audio with a Russian accent—and translate your videos to/from English and 100 other languages. You can even use VEED to record your content. Record your audio, transcribe, and translate to go global!
Your one-stop AI suite for all types of content creation
Our speech recognition and AI voiceover generation are just some of VEED’s state-of-the-art AI features. With VEED, you have access to a powerful AI video generator. Create professional videos with the help of AI - automatically add subtitles, remove background noise from your recordings, and a full range of other AI video editing tools.
Frequently Asked Questions
You can transcribe your Russian audio files to text instantly with VEED. Upload your audio or video file to VEED, and our software will transcribe the original file, which you can download as a TXT, VTT, or SRT file.
You can do it automatically with VEED! No need to type manually. VEED is your go-to app if you want to convert voice to text in Russian—or instantly generate an Russian voiceover in various male and female AI voice profiles. VEED’s AI can also convert text to speech!
Depending on how the speech or recording is spaced out through the video, VEED will separate the transcriptions into different boxes. Just click on each box and start typing or editing the text.
Yes—but only the subtitles appearing on the video and not the TXT file. You can choose from a wide range of fonts and styles. Change its size, color, and opacity.
Discover more:
- Assamese Speech to Text
- Audio Transcription
- Bengali Speech to Text
- Cantonese Speech to Text
- Chinese Speech to Text
- Dictation Transcription
- German Speech to Text
- Japanese Speech to Text
- Kannada Speech to Text
- Korean Speech to Text
- M4A to Text
- MP3 to Text
- Music Transcription
- Sinhala Speech to Text
- Speech to Text Arabic
- Speech to Text Bulgarian
- Speech to Text Danish
- Speech to Text Dutch
- Speech to Text Finnish
- Speech to Text in Marathi
- Speech to Text Italian
- Speech to Text Portuguese
- Speech to Text Serbian
- Speech to Text Slovak
- Speech to Text Swedish
- Speech to Text Thai
- Speech to Text Turkish
- Speech to Text Vietnamese
- Tamil Audio to Text
- Telugu Audio to Text Converter
- Transcribe Recordings to Text
- Verbatim Transcription
- Voice Memo Transcription
- Voice Message to Text
- WAV to Text
What they say about VEED
Veed is a great piece of browser software with the best team I've ever seen. Veed allows for subtitling, editing, effect/text encoding, and many more advanced features that other editors just can't compete with. The free version is wonderful, but the Pro version is beyond perfect. Keep in mind that this a browser editor we're talking about and the level of quality that Veed allows is stunning and a complete game changer at worst.
I love using VEED as the speech to subtitles transcription is the most accurate I've seen on the market. It has enabled me to edit my videos in just a few minutes and bring my video content to the next level
Laura Haleydt - Brand Marketing Manager, Carlsberg Importers
The Best & Most Easy to Use Simple Video Editing Software! I had tried tons of other online editors on the market and been disappointed. With VEED I haven't experienced any issues with the videos I create on there. It has everything I need in one place such as the progress bar for my 1-minute clips, auto transcriptions for all my video content, and custom fonts for consistency in my visual branding.
Diana B - Social Media Strategist, Self Employed
More from VEED

How to Get the Transcript of a YouTube Video [Fast & Easy]
The easiest way to get the transcript of a YouTube video without jumping through a million hoops. Here's how.

Subtitling 101: How to automatically add and customize subtitles with VEED
Everything you need to automatically add, customize, translate, and download subtitles like a pro using VEED.
More than a Russian speech-to-text software
VEED is a comprehensive and intuitive AI video editing software that allows you to do much more than just transcribe Russian audio files to text. You can also transcribe the original recording of a video. Add subtitles to your videos to make them more accessible for everyone. It also has all the video editing tools you need. All tools are accessible online, so you don’t need to install any software. Try our transcription and video editing app today!

You are using an outdated browser. Please upgrade your browser or activate Google Chrome Frame to improve your experience.
How to Learn Languages with Speech Recognition Tools
I’ve got all the right books and tons of vocabulary flashcards… but I can’t find anyone to actually speak with!
Luckily, technology provides a solution.
Thanks to increasingly advanced speech recognition, there are apps that can give you instant feedback on your speaking and pronunciation skills .
Let’s dive into how exactly speech recognition can help with language learning, along with the seven best apps for this!
Why Use Speech Recognition for Language Learning?
Improve pronunciation, less intimidating, personalized learning, flexible studying, speech recognition apps for language learning, 4. audionote, 6. rocket languages, 7. rosetta stone.
Download: This blog post is available as a convenient and portable PDF that you can take anywhere. Click here to get a copy. (Download)
First of all, using speech recognition can help you fine-tune your pronunciation . One of the trickiest aspects of learning to speak a language is getting your pronunciation right , especially if you’re mostly learning on your own. Even native speakers can sometimes have a hard time pinpointing which part of your pronunciation needs correcting.
With speech recognition, you can practice speaking using your phone and know right away what you need to improve. Some apps even check your intonation and break down which syllables you pronounced wrong.
Additionally, speech recognition isn’t intimidating . One thing that holds back many learners from practicing their speaking skills more is being afraid to make mistakes with native speakers.
Since you aren’t working with an actual person, you won’t be embarrassed if you make a mistake with speech recognition. Practicing with an app can make you more confident in your skills and eventually take away some of the intimidation factor of talking with actual native speakers .
Speech recognition gives you specific feedback about your accent and speaking skills. As technology gets more advanced, many apps with speech recognition can give very detailed reports about your language skills and plan your next lessons based on these.
You can even practice two-way dialogues now, with some AI apps coming up with their own responses and setting up different scenarios.
Finally, speech recognition apps provide a flexible study option . You can get speaking practice whenever you want, without needing to schedule time with a conversation partner.
That means you can cram in a little extra speech practice whether you’re waiting in line at the store, relaxing in bed or even in the shower (just make sure your phone is waterproof first).

Need some conversation practice? Mondly might be the supportive, non-judgmental conversation partner you’re looking for.
Mondly’s main focus is on helping you learn common words and phrases that you can use in real-world situations you’re likely to encounter.
After helping you remember key words and start putting together phrases, Mondly will put your speaking skills to the test with a simulated conversation . You’ll hear a prompt spoken by a native speaker. The words and their translations will also appear on the screen. From there, you’ll have a list of options for replies you can actually say into your device.
Mondly’s speech recognition aims to improve your pronunciation by listening to your words and phrases and giving you feedback for correct, clear speaking.
Mondly offers more than 40 languages , including common options like Arabic, Chinese, French, German, Italian, Japanese, Korean, Portuguese, Russian and Spanish. However, Mondly also offers less common options, like Afrikaans, Bulgarian, Croatian, Hungarian, Indonesian, Persian and more.
Click here for an in-depth review on Mondly.

Immersive learning (surrounding yourself with the real spoken and written language) is the key to FluentU’s language learning program. In fact, it is best used for at-home immersion to round out the speaking skills.
FluentU uses authentic video clips to bring the language you’re learning right to your computer or phone screen. Each video comes with interactive captions —click any word for an instant definition, native pronunciation and visual learning aid. This allows you to learn vocabulary in context, so you can be better prepared to understand and participate in native-level speech.
Since all the videos are organized by genre and learning level, you can easily find the content that suits your needs. You can then test your knowledge of the material with personalized quizzes. These quizzes can be completed through written input as well as speech recognition input , so you can master your accent in tandem with building your vocabulary.
Babbel aims to teach you a language in 10- to 15-minute daily lessons . It covers popular topics, like business, travel, shopping, dining and transportation, to ensure that the skills you learn are likely to be usable in the real world.
Babbel’s speech recognition feature appears during vocabulary review. You’ll see the written word and its English meaning and you can also play an audio pronunciation. From there, you have the option of speaking the word yourself. Your goal is to emulate the pronunciation you heard .
If your pronunciation is good, you’ll get a new word. If not, you have four more chances before the app moves on regardless of your pronunciation.
Babbel offers 14 languages , including Spanish , French , German , Russian , Italian and English .
You can find out more about Babbel with this detailed review .
While AudioNote isn’t designed for language learners, it could be your secret weapon for perfecting your pronunciation.
AudioNote’s main focus is (you guessed it) taking audio notes. This means that you speak into your device while the app jots down what you said.
For language learners, this provides a quick way to see if your pronunciation is clear enough for the app to understand what you’re saying. If the transcription isn’t accurate, you may not be speaking clearly enough.
One of the features that’s perhaps most useful for language learners is the linking of audio and text . You can play back the audio you spoke as the app highlights the transcription to show where you’re at. This makes it easy to pinpoint which (if any) words you mispronounced. You can also tap your notes if you want to hear specific words you said.
AudioNote is available in English, French, German, Italian and Spanish.
Got an extra 10 minutes today? Busuu can help fill it with language learning goodness.
Not only will Busuu provide you with grammar lessons, vocabulary practice and conversations with native speakers, but it can also help you improve your accent with speech recognition exercises .
In these exercises, you hear a native speaker and repeat after him/her. Then, the app will tell you if you pronounced the prompts correctly .
Levels range from beginner to fluent. Busuu offers 14 languages , including Arabic, Chinese, English, French, German, Italian, Japanese, Polish, Portuguese, Russian, Spanish and Turkish.
For more on Busuu, check out this review .

Sure, Rocket Languages offers plenty of interactive materials to help you learn a language. Sure, it’s designed to be flexible so you can learn at your pace in whatever time you have available. But let’s get to the juicy stuff: the speech recognition activities.
Rocket Languages offers speech recognition for thousands of phrases . You’ll be presented with a written word or phrase and its English translation. For languages that don’t use the Latin alphabet, there’ll also be a transliteration listed to make things a little easier for you.
Then, you can speak that word or phrase and the app will give you feedback on your pronunciation.
Rocket Languages offers 14 foreign languages , including Spanish , Portuguese , French , Italian , German , Chinese , Korean , Russian , Arabic and Japanese .
Click here for a full review of Rocket Languages .

If you’re into language apps and/or software, chances are you’ve heard of Rosetta Stone. Probably a lot. But don’t stop reading just yet!
Rosetta Stone has a lot to offer for language learners, so it should come as no surprise that their app offers some top-notch speech recognition. In fact, their speech recognition comes complete with its own registered trademark name: “TruAccent™.”
It aims to help you perfect your accent by practicing common words and phrases and reading short stories aloud .
This technology not only checks to make sure the words and phrases you used are correct, but it also compares your speech to that of a native speaker to provide you with an instant assessment of which words you pronounced well and which could use some more work.
You can even compare the wavelengths of your audio to that of the native speaker, for super-precise adjustments. Plus, Rosetta Stone will track your progress and let you see how your pronunciation has improved over time .
Rosetta Stone offers over 20 languages , including Chinese , Japanese , Korean , Portuguese , Arabic , Spanish , Italian , French and German .
Here’s an in-depth review of Rosetta Stone .
So speak up with these seven apps with speech recognition!
Enter your e-mail address to get your free PDF!
We hate SPAM and promise to keep your email address safe

Russian Speech Dataset For Speech and Voice Recognition Models
We provide Russian Speech Dataset for training and testing Russian speech/voice recognition algorithms and ASR models. Our transcribed NLP Dataset is perfect for speech-to-text and ASR models for Russian language. We have multiple datasets that you can choose from: transcribed spontaneous speech data with one or two people speaking or scripted monologues.
Datasets for your speech recognition solution in Russian
Improve your Russian automatic speech recognition models or deploy new models in days using our speech and voice recognition dataset. The Russian datasets you can choose from are scripted and non scripted recordings with one or two people speaking. Tell us what data you need and we will include only the data that fits your use case and needs, whether that is specific background noise levels, speakers from certain regions, speakers of specific age groups, gender, or nativitiy. We can provide you with thousands of hours of speech recorded by tens of thousands unique speakers. With our high-quality training datasets, you can gain competitive advantage over your competitors, reduce time to market, and improve word error rate of your models.
Our speech recognition datasets in Russian consists of native and non-native speakers from the following regions: Russian language: native and non-native RU.
Speech recognition data specifications
The Russian The datasets contain transcribed and segmented audio clips of people talking about various topics or reading sentences, with up to two hours of speech per person. The speech is captured using mobile phones and laptops from a diverse crowd of speakers representing all ages and backgrounds. Because of that, the dataset is perfect for ASR and voice assistant use cases using mobile devices. Recordings vary in length depending on type of recording. Scripted speech recordings are up to 30 seconds while two people conversations are of up to one hour long. The recordings are transcribed and segmented by speaker, noise, music, and overlapping speech. Automatic speech recognition (ASR) is also known as speech-to-text and voice recognition.
What use cases is the data for?
The speech recognition datasets are perfect for: - Building a speech recognition AI. - Building a speaker recognition AI. - Speech recognition solutions for call centers.
Dataset license
Our data licenses agreement covers commercial use, and the datasets can be reused for multiple cases. However, they are not for reselling.
Speech recognition sample collected through our service.
How is data relevant to speech recognition?
Quality guarantee.
We are confident in our data, and all customers can review a sample batch of data before buying. Additionally, we offer a quality guarantee. If you wish to review more samples before buy, state so when filling in the order form.
Russian speech data starting from
Demographics.

Custom training data collection for speech and NLP.
- Security and Defense
- Authoritarian Threats
- Technology and Innovation
- Our Fellows
- State of the Alliance
- Transcripts
- Latest Commentary
- Comprehensive Reports
- Europe’s Edge
- Transatlantic Tech Policy Tracker
- Behind the Lines
- Work With Us
Russia Exports Digital Surveillance, Despite Sanctions
Despite Western sanctions and its overall technological backwardness, Russia continues to export digital surveillance technology - and to find willing buyers.
Russian surveillance systems are supplied not only to foreign companies but also to foreign governments, including law enforcement agencies. Russian suppliers often partner with Western technology giants, avoiding sanctions imposed because of the Ukraine war.
Here’s a guide to the main producers of Russian surveillance and facial and speech recognition tools:
Surveillance
Systems for Operative Investigative Activities (SORM) are hardware and software for monitoring information passing through telephone operators.
This company develops SORM hardware and software. It supplies IT solutions for the Defense and Interior Ministries. Protei operates in 35 countries , including Mexico, Cuba, Colombia, Italy, and the United Arab Emirates. It has offices in Jordan and Estonia and partners with Western firms including Nokia and Oracle. After the Ukraine invasion, Protei has continued to operate outside of Russia. In March 2022, the company signed a contract with the Pakistani mobile operator CMPAK.
Nexign, formerly known as Peter-Service, is another SORM supplier. The company is part of Kremlin insider Alisher Usmanov’s USM Telecom holding. Usmanov was put on the US sanctions list after the invasion of Ukraine, but not his company. Nexign’s products have been delivered to 14 countries . Its partners include Microsoft and Oracle. Representative offices are open in the Dominican Republic and the United Arab Emirates.
Nexign said that it does not offer SORM products or DPI solutions and has not done so in the past.
According to various estimates , Citadel holds between 60% to 80% of the Russian SORM market. The company’s owner has close ties with the security forces – the company employs generals from the Russian FSB Secret Service and the Ministry of Interior. Citadel supplies equipment for the implementation of the Yarovaya Law, which obliges Russian telecom operators to collect and store user traffic. Its subsidiary MFI Soft supplies solutions for tracking user traffic to the countries of the former Soviet Union, and through the Canadian company ALOE Systems, has exported to Canada, the USA, Mexico, Argentina, Brazil, Costa Rica, El Salvador, Peru, and Uruguay.
Facial and Speech Recognition
Russian facial and speech recognition systems are popular around the world. At home, the Kremlin uses them to carry out mass detentions of political activists.
NtechLab leads the Russian market in producing facial recognition systems and video analytics. In 2017, the fund of oligarch Roman Abramovich took a stake; the next year, state corporation Rostec invested . Ten Russian cities and 26 countries deploy the technology. NtechLab’s main foreign office is located in Cyprus.
Clients include US companies Intel, SpaceX, Dell, and Philip Morris, according to a leaked document . Police and military agencies, including Interpol, the Brazilian Federal Police, and the Royal Thai Army also use NtechLab products.
US authorities acknowledge the technology’s effectiveness. In 2017, the US Intelligence Advanced Research Projects Activity (IARPA), together with the US National Institute of Standards and Technology (NIST), held a competition for facial recognition algorithms. NtechLab won .
Despite the Ukraine invasion, NtechLab continues to grow around the globe. In March 2022, it announced , a partnership with Bangladeshi software company Ribat Metatech. In May 2022, the company delivered a facial recognition system to Sri Lanka. In June, 2022, NtechLab announced an expansion in Mexico.
VisionLabs built Moscow’s facial recognition system. Its technology is used in 60 countries , including the US, Canada, France, and Germany. The company even received an award from the US magazine Financial Services Review.
In December 2021, Kremlin-connected businessman Vladimir Yevtushenko acquired VisionLabs. Yevtushenko has been included in the UK sanctions list .
Speech Technology Center
The Speech Technology Center (STC) develops facial, voice, and biometric recognition systems. Originally a public institution, state-owned bank Sberbank became the majority shareholder, only to sell out to an unknown new company after the start of the Ukraine war. According to media reports , the deal was designed to avoid Western sanctions against Sberbank.
STC gained worldwide infamy in December 2011, when Wikileaks, in its The Spy Files project, included it in the list of manufacturers of surveillance technologies. The company acknowledges its cooperation with the Russian Federal Security Service, the Ministry of Interior, and the Federal Protective Service. Its products have been shipped to more than 75 countries. Foreign partners include Oracle and Cisco.
Russian-made digital surveillance continues to spread around the world. Clients include democracies, whose leaders often declare opposition to the tools of digital authoritarianism. Instead of buying Russian-made systems, they should stop using them.
Alena Popova is the Galina Starovoitova Fellow at the Wilson Center and founder of the Ethics and Technology think tank
Europe’s Edge is CEPA’s online journal covering critical topics on the foreign policy docket across Europe and North America. All opinions are those of the author and do not necessarily represent the position or views of the institutions they represent or the Center for European Policy Analysis.

Securing NATO’s Tomorrow
Related Articles
Related issue tags.
Hyperkinetic Dysarthria voice abnormalities: a neural network solution for text translation
- Published: 03 April 2024
Cite this article
- Antor Mahamudul Hashan ORCID: orcid.org/0000-0001-7926-9245 1 ,
- Chaganov Roman Dmitrievich 2 ,
- Melnikov Alexander Valerievich ORCID: orcid.org/0009-0004-6929-5473 2 ,
- Dorokh Danila Vasilyevich 2 ,
- Khlebnikov Nikolai Alexandrovich ORCID: orcid.org/0000-0003-3662-1039 1 &
- Boris Andreevich Bredikhin ORCID: orcid.org/0009-0005-7370-9947 3
37 Accesses
Explore all metrics
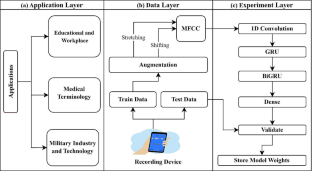
The implementation of a defect speech recognition (DSR) system has the opportunity to significantly improve the lifestyle of people with speech disorders. In this paper, we developed a novel ConvGRUSpeechNet model for recognizing and understanding hyperkinetic dysarthria disorder (HDD) speech. The proposed model uniquely combines convolutional layers, recurrent layers (GRU and BiGRU), and dense layers with a LogSoftmax function to effectively recognize and translate HDD speech into text. To prevent overfitting and handling imbalances, we employed data augmentation and splitting functions during the training process. Also, the Mel-frequency cepstral coefficients (MFCC) were employed to reduce the issue of vanishing gradients. In addition, a dataset of Russian speech has been created, comprising 2000 recordings of HDD speech. The primary objective of this research is to improve speech recognition for individuals with HDD by employing the ConvGRUSpeechNet model. The proposed DSR system outperformed the recognition character error rate (CER) of 12.35% using the test dataset. Under the same conditions, the experimental findings show that the proposed solution exhibits superior performance in comparison to existing state-of-the-art CBNs and TDNN-F LF-MMI models. Furthermore, we implemented the TensorFlow model on a flask server, making it accessible for use in a web application.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

Variable STFT Layered CNN Model for Automated Dysarthria Detection and Severity Assessment Using Raw Speech
Kodali Radha, Mohan Bansal & Venkata Rao Dulipalla

Parkinson’s Disease Assessment from Speech Data Using Recurrence Plot

Author information
Authors and affiliations.
Institute of Fundamental Education (InFO), Ural Federal University, 620002, Yekaterinburg, Russia
Antor Mahamudul Hashan & Khlebnikov Nikolai Alexandrovich
Institute of Radio Electronics and Information Technology-RTF, Ural Federal University, 620002, Yekaterinburg, Russia
Chaganov Roman Dmitrievich, Melnikov Alexander Valerievich & Dorokh Danila Vasilyevich
Boris Andreevich Bredikhin
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Antor Mahamudul Hashan .
Ethics declarations
Conflicts of interest.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Hashan, A.M., Dmitrievich, C.R., Valerievich, M.A. et al. Hyperkinetic Dysarthria voice abnormalities: a neural network solution for text translation. Int J Speech Technol (2024). https://doi.org/10.1007/s10772-024-10098-5
Download citation
Received : 09 January 2024
Accepted : 18 March 2024
Published : 03 April 2024
DOI : https://doi.org/10.1007/s10772-024-10098-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Deep learning
- Voice assistant system
- Speech disorder
- Hyperkinetic dysarthria
- Data augmentation
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO
COMMENTS
Speech Recognition is only available for the following languages: English (United States, United Kingdom, Canada, India, and Australia), French, German, Japanese, Mandarin (Chinese Simplified and Chinese Traditional), and Spanish. Hope the information provided is useful. If the issue persists, reply here and we will be glad to help you. Angel. AN.
Russian speech to text is a process that involves converting spoken Russian words into verbatim written text. Also known as speech recognition, it uses machine learning algorithms to analyze verbal speech and process it into a transcript.
Rosetta Stone has a fantastic speech recognition engine and reading section. They are very focused on immersion, so lessons are entirely in Russian. Rosetta Stone is a good app for beginner Russian learners who already know the basics and want to learn some extra vocabulary while listening to native Russian speakers. Pros: Speech recognition
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. We show that the use of such a large and diverse dataset leads to improved robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages ...
End-to-end speech recognition systems incorporating deep neural networks (DNNs) have achieved good results. We propose applying CTC (Connectionist Temporal Classification) models and attention-based encoder-decoder in automatic recognition of the Russian continuous speech. We used different neural network models such Long short-term memory ...
Effortlessly accomplish speech recognition in Russian. This advanced speech recognition tool can accurately and swiftly assist you in converting your Russian audio and video files into text. Offers multilanguage support in a unified platform At SpeechFlow, we pride ourselves on our capability to provide transcriptions in 14 distinct languages ...
Russian speech recognition. Although the authors pro-vided a broad view of works related to ASR for Russian, they did not describe the ASR development methods. They focused on systems and their performance. Russian No [Zaykovskiy, 2006] To detail approaches for pro-viding ASR technology to mobile users Only interested in ASR ar-chitecture. No ...
The developed speech recognition system SIRIUS has one additional level of Russian language representation - morphemic level. As a result the size of vocabulary and time for speech processing are ...
Some Approaches for Russian Speech Recognition. Abstract: In this paper we present an overview of the state-of-the-art approaches for speech recognition of the Russian language. Since Russian is a highly inflective language with a complex mechanism of word formation, the main approaches for English speech recognition are not optimally ...
Automatic speech recognition (ASR) is a process of converting speech to text. It can be performed using both acoustic model (AM) and language model (LM) as shown in [ 1 ]. In this paper, we consider building and learning of acoustic models only. Acoustic models are traditionally built using hidden Markov models (HMM) with the Gaussian mixture ...
For instance, one of the first ASR systems was developed in 1960s by T. Vintsyuk, who is considered as one of the Russian speech recognition pioneers (Vintsyuk, 1968). He proposed the use of dynamic programming methods for time alignment of speech utterances. However, there are only a few systems for large vocabulary tasks.
The aim of this research was to explore multi-head attention in end-to-end Russian speech recognition system, combining encoder-decoder and CTC models. The rest of the paper is organized as follows. In Sect. 2 we present our CTC/encoder-decoder end-to-end speech recognition model, in Sect. 3 we describe multi-head attention mechanism, the ...
Abstract. The paper examines the practical issues in developing a speech-to-text system using deep neural networks. The development of a Russian-language speech recognition system based on ...
Accurate AI voice-to-text transcriptions in Russian. No more manually transcribing Russian audio to text. Embrace the ease of effortless speech-to-text conversion. Our cutting-edge speech recognition lets you record and watch your words magically transform into text in real-time. Our premium subscribers get unlimited transcription downloads.
The development of a Russian-language speech recognition system based on DeepSpeech architecture is described. The Mozilla company's open source implementation of DeepSpeech for the English language was used as a starting point. The system was trained in a containerized environment using the Docker technology.
3. Babbel. Babbel aims to teach you a language in 10- to 15-minute daily lessons. It covers popular topics, like business, travel, shopping, dining and transportation, to ensure that the skills you learn are likely to be usable in the real world. Babbel's speech recognition feature appears during vocabulary review.
Datasets for your speech recognition solution in Russian. Improve your Russian automatic speech recognition models or deploy new models in days using our speech and voice recognition dataset. The Russian datasets you can choose from are scripted and non scripted recordings with one or two people speaking. Tell us what data you need and we will include only the data that fits your use case and ...
In order to improve the effect of continuous speech recognition, this paper combines the DTW algorithm to construct a continuous Russian speech recognition system and proposes a continuous Russian speech detection method based on VGDTW-MPCA with an unequal interval process.
Facial and Speech Recognition. Russian facial and speech recognition systems are popular around the world. At home, the Kremlin uses them to carry out mass detentions of political activists. NtechLab . NtechLab leads the Russian market in producing facial recognition systems and video analytics.
You would need a Russian language speech recognizer. Microsoft doesn't ship one, and as far as I know, no such recognition engine exists. - Eric Brown. Mar 25, 2019 at 22:02 | Show 1 more comment. 3 Answers Sorted by: Reset to default 2 Windows 10 does not ship a SAPI-compatible Russian recognizer as part of the OS. ...
13 May 2020, Moscow - Speaker diarisation and speech recognition technology created by Speech Technology Center (part of the Sberbank ecosystem) was named the best at the international CHiME Speech Separation and Recognition Challenge ().The technology was highly acclaimed for its ability to recognise English speech from multiple microphones in a natural environment.
Russian Text Normalization for STT and TTS. Many speech related problems including STT (Speech-To-Text) and TTS (Text-To-Speech) require transcripts to be converted into a real " spoken " form, i.e the exact words that speaker said. This means that before some written expression becomes our transcript it needs to be normalized.
Also, the Mel-frequency cepstral coefficients (MFCC) were employed to reduce the issue of vanishing gradients. In addition, a dataset of Russian speech has been created, comprising 2000 recordings of HDD speech. The primary objective of this research is to improve speech recognition for individuals with HDD by employing the ConvGRUSpeechNet model.